CompactNet: Platform-Aware Automatic Optimization for Convolutional Neural Networks
Convolutional Neural Network (CNN) based Deep Learning (DL) has achieved great progress in many real-life applications. Meanwhile, due to the complex model structures against strict latency and memory restriction, the implementation of CNN models on the resource-limited platforms is becoming more challenging. This work proposes a solution, called CompactNet\footnote{Project URL: \url{
https://…/CompactNet}}, which automatically optimizes a pre-trained CNN model on a specific resource-limited platform given a specific target of inference speedup. Guided by a simulator of the target platform, CompactNet progressively trims a pre-trained network by removing certain redundant filters until the target speedup is reached and generates an optimal platform-specific model while maintaining the accuracy. We evaluate our work on two platforms of a mobile ARM CPU and a machine learning accelerator NPU (Cambricon-1A ISA) on a Huawei Mate10 smartphone. For the state-of-the-art slim CNN model made for the embedded platform, MobileNetV2, CompactNet achieves up to a 1.8x kernel computation speedup with equal or even higher accuracy for image classification tasks on the Cifar-10 dataset.
On Measuring Gender Bias in Translation of Gender-neutral Pronouns
Ethics regarding social bias has recently thrown striking issues in natural language processing. Especially for gender-related topics, the need for a system that reduces the model bias has grown in areas such as image captioning, content recommendation, and automated employment. However, detection and evaluation of gender bias in the machine translation systems are not yet thoroughly investigated, for the task being cross-lingual and challenging to define. In this paper, we propose a scheme for making up a test set that evaluates the gender bias in a machine translation system, with Korean, a language with gender-neutral pronouns. Three word/phrase sets are primarily constructed, each incorporating positive/negative expressions or occupations; all the terms are gender-independent or at least not biased to one side severely. Then, additional sentence lists are constructed concerning formality of the pronouns and politeness of the sentences. With the generated sentence set of size 4,236 in total, we evaluate gender bias in conventional machine translation systems utilizing the proposed measure, which is termed here as translation gender bias index (TGBI). The corpus and the code for evaluation is available on-line.
Triple2Vec: Learning Triple Embeddings from Knowledge Graphs
Graph embedding techniques allow to learn high-quality feature vectors from graph structures and are useful in a variety of tasks, from node classification to clustering. Existing approaches have only focused on learning feature vectors for the nodes in a (knowledge) graph. To the best of our knowledge, none of them has tackled the problem of embedding of graph edges, that is, knowledge graph triples. The approaches that are closer to this task have focused on homogeneous graphs involving only one type of edge and obtain edge embeddings by applying some operation (e.g., average) on the embeddings of the endpoint nodes. The goal of this paper is to introduce Triple2Vec, a new technique to directly embed edges in (knowledge) graphs. Trple2Vec builds upon three main ingredients. The first is the notion of line graph. The line graph of a graph is another graph representing the adjacency between edges of the original graph. In particular, the nodes of the line graph are the edges of the original graph. We show that directly applying existing embedding techniques on the nodes of the line graph to learn edge embeddings is not enough in the context of knowledge graphs. Thus, we introduce the notion of triple line graph. The second is an edge weighting mechanism both for line graphs derived from knowledge graphs and homogeneous graphs. The third is a strategy based on graph walks on the weighted triple line graph that can preserve proximity between nodes. Embeddings are finally generated by adopting the SkipGram model, where sentences are replaced with graph walks. We evaluate our approach on different real world (knowledge) graphs and compared it with related work.
Evaluating time series forecasting models: An empirical study on performance estimation methods
Performance estimation aims at estimating the loss that a predictive model will incur on unseen data. These procedures are part of the pipeline in every machine learning project and are used for assessing the overall generalisation ability of predictive models. In this paper we address the application of these methods to time series forecasting tasks. For independent and identically distributed data the most common approach is cross-validation. However, the dependency among observations in time series raises some caveats about the most appropriate way to estimate performance in this type of data and currently there is no settled way to do so. We compare different variants of cross-validation and of out-of-sample approaches using two case studies: One with 62 real-world time series and another with three synthetic time series. Results show noticeable differences in the performance estimation methods in the two scenarios. In particular, empirical experiments suggest that cross-validation approaches can be applied to stationary time series. However, in real-world scenarios, when different sources of non-stationary variation are at play, the most accurate estimates are produced by out-of-sample methods that preserve the temporal order of observations.
Evaluation of Machine Learning-based Anomaly Detection Algorithms on an Industrial Modbus/TCP Data Set
In the context of the Industrial Internet of Things, communication technology, originally used in home and office environments, is introduced into industrial applications. Commercial off-the-shelf products, as well as unified and well-established communication protocols make this technology easy to integrate and use. Furthermore, productivity is increased in comparison to classic industrial control by making systems easier to manage, set up and configure. Unfortunately, most attack surfaces of home and office environments are introduced into industrial applications as well, which usually have very few security mechanisms in place. Over the last years, several technologies tackling that issue have been researched. In this work, machine learning-based anomaly detection algorithms are employed to find malicious traffic in a synthetically generated data set of Modbus/TCP communication of a fictitious industrial scenario. The applied algorithms are Support Vector Machine (SVM), Random Forest, k-nearest neighbour and k-means clustering. Due to the synthetic data set, supervised learning is possible. Support Vector Machine and k-nearest neighbour perform well with different data sets, while k-nearest neighbour and k-means clustering do not perform satisfactorily.
Progressive Learning of Low-Precision Networks
Recent years have witnessed the great advance of deep learning in a variety of vision tasks. Many state-of-the-art deep neural networks suffer from large size and high complexity, which makes it difficult to deploy in resource-limited platforms such as mobile devices. To this end, low-precision neural networks are widely studied which quantize weights or activations into the low-bit format. Though being efficient, low-precision networks are usually hard to train and encounter severe accuracy degradation. In this paper, we propose a new training strategy through expanding low-precision networks during training and removing the expanded parts for network inference. First, we equip each low-precision convolutional layer with an ancillary full-precision convolutional layer based on a low-precision network structure, which could guide the network to good local minima. Second, a decay method is introduced to reduce the output of the added full-precision convolution gradually, which keeps the resulted topology structure the same to the original low-precision one. Experiments on SVHN, CIFAR and ILSVRC-2012 datasets prove that the proposed method can bring faster convergence and higher accuracy for low-precision neural networks.
Greedy InfoMax for Biologically Plausible Self-Supervised Representation Learning
We propose a novel deep learning method for local self-supervised representation learning that does not require labels nor end-to-end backpropagation but exploits the natural order in data instead. Inspired by the observation that biological neural networks appear to learn without backpropagating a global error signal, we split a deep neural network into a stack of gradient-isolated modules. Each module is trained to maximize the mutual information between its consecutive outputs using the InfoNCE bound from Oord et al. [2018]. Despite this greedy training, we demonstrate that each module improves upon the output of its predecessor, and that the representations created by the top module yield highly competitive results on downstream classification tasks in the audio and visual domain. The proposal enables optimizing modules asynchronously, allowing large-scale distributed training of very deep neural networks on unlabelled datasets.
Repeated A/B Testing
We study a setting in which a learner faces a sequence of A/B tests and has to make as many good decisions as possible within a given amount of time. Each A/B test

is associated with an unknown (and potentially negative) reward
![\mu_n \in [-1,1]](https://s0.wp.com/latex.php?latex=%5Cmu_n+%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)
, drawn i.i.d. from an unknown and fixed distribution. For each A/B test
, the learner sequentially draws i.i.d. samples of a
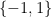
-valued random variable with mean

until a halting criterion is met. The learner then decides to either accept the reward
or to reject it and get zero instead. We measure the learner’s performance as the sum of the expected rewards of the accepted
divided by the total expected number of used time steps (which is different from the expected ratio between the total reward and the total number of used time steps). We design an algorithm and prove a data-dependent regret bound against any set of policies based on an arbitrary halting criterion and decision rule. Though our algorithm borrows ideas from multiarmed bandits, the two settings are significantly different and not directly comparable. In fact, the value of
is never observed directly in our setting—unlike rewards in stochastic bandits. Moreover, the particular structure of our problem allows our regret bounds to be independent of the number of policies.
Interpreting and improving natural-language processing (in machines) with natural language-processing (in the brain)
Neural network models for NLP are typically implemented without the explicit encoding of language rules and yet they are able to break one performance record after another. Despite much work, it is still unclear what the representations learned by these networks correspond to. We propose here a novel approach for interpreting neural networks that relies on the only processing system we have that does understand language: the human brain. We use brain imaging recordings of subjects reading complex natural text to interpret word and sequence embeddings from 4 recent NLP models – ELMo, USE, BERT and Transformer-XL. We study how their representations differ across layer depth, context length, and attention type. Our results reveal differences in the context-related representations across these models. Further, in the transformer models, we find an interaction between layer depth and context length, and between layer depth and attention type. We finally use the insights from the attention experiments to alter BERT: we remove the learned attention at shallow layers, and show that this manipulation improves performance on a wide range of syntactic tasks. Cognitive neuroscientists have already begun using NLP networks to study the brain, and this work closes the loop to allow the interaction between NLP and cognitive neuroscience to be a true cross-pollination.
When can unlabeled data improve the learning rate?
In semi-supervised classification, one is given access both to labeled and unlabeled data. As unlabeled data is typically cheaper to acquire than labeled data, this setup becomes advantageous as soon as one can exploit the unlabeled data in order to produce a better classifier than with labeled data alone. However, the conditions under which such an improvement is possible are not fully understood yet. Our analysis focuses on improvements in the minimax learning rate in terms of the number of labeled examples (with the number of unlabeled examples being allowed to depend on the number of labeled ones). We argue that for such improvements to be realistic and indisputable, certain specific conditions should be satisfied and previous analyses have failed to meet those conditions. We then demonstrate examples where these conditions can be met, in particular showing rate changes from
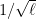
to
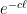
and from
to
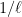
. These results improve our understanding of what is and isn’t possible in semi-supervised learning.
Interactive Teaching Algorithms for Inverse Reinforcement Learning
We study the problem of inverse reinforcement learning (IRL) with the added twist that the learner is assisted by a helpful teacher. More formally, we tackle the following algorithmic question: How could a teacher provide an informative sequence of demonstrations to an IRL learner to speed up the learning process? We present an interactive teaching framework where a teacher adaptively chooses the next demonstration based on learner’s current policy. In particular, we design teaching algorithms for two concrete settings: an omniscient setting where a teacher has full knowledge about the learner’s dynamics and a blackbox setting where the teacher has minimal knowledge. Then, we study a sequential variant of the popular MCE-IRL learner and prove convergence guarantees of our teaching algorithm in the omniscient setting. Extensive experiments with a car driving simulator environment show that the learning progress can be speeded up drastically as compared to an uninformative teacher.
CGPOPS: A C++ Software for Solving Multiple-Phase Optimal Control Problems Using Adaptive Gaussian Quadrature Collocation and Sparse Nonlinear Programming
A general-purpose C++ software program called

is described for solving multiple-phase optimal control problems using adaptive Gaussian quadrature collocation. The software employs a Legendre-Gauss-Radau direct orthogonal collocation method to transcribe the continuous-time optimal control problem into a large sparse nonlinear programming problem. A class of

mesh refinement methods are implemented which determine the number of mesh intervals and the degree of the approximating polynomial within each mesh interval to achieve a specified accuracy tolerance. The software is interfaced with the open source Newton NLP solver IPOPT. All derivatives required by the NLP solver are computed using either central finite differencing, bicomplex-step derivative approximation, hyper-dual derivative approximation, or automatic differentiation. The key components of the software are described in detail and the utility of the software is demonstrated on five optimal control problems of varying complexity. The software described in this article provides a computationally efficient and accurate approach for solving a wide variety of complex constrained optimal control problems.
Beyond Personalization: Social Content Recommendation for Creator Equality and Consumer Satisfaction
An effective content recommendation in modern social media platforms should benefit both creators to bring genuine benefits to them and consumers to help them get really interesting content. In this paper, we propose a model called Social Explorative Attention Network (SEAN) for content recommendation. SEAN uses a personalized content recommendation model to encourage personal interests driven recommendation. Moreover, SEAN allows the personalization factors to attend to users’ higher-order friends on the social network to improve the accuracy and diversity of recommendation results. Constructing two datasets from a popular decentralized content distribution platform, Steemit, we compare SEAN with state-of-the-art CF and content based recommendation approaches. Experimental results demonstrate the effectiveness of SEAN in terms of both Gini coefficients for recommendation equality and F1 scores for recommendation performance.
RecNets: Channel-wise Recurrent Convolutional Neural Networks
In this paper, we introduce Channel-wise recurrent convolutional neural networks (RecNets), a family of novel, compact neural network architectures for computer vision tasks inspired by recurrent neural networks (RNNs). RecNets build upon Channel-wise recurrent convolutional (CRC) layers, a novel type of convolutional layer that splits the input channels into disjoint segments and processes them in a recurrent fashion. In this way, we simulate wide, yet compact models, since the number of parameters is vastly reduced via the parameter sharing of the RNN formulation. Experimental results on the CIFAR-10 and CIFAR-100 image classification tasks demonstrate the superior size-accuracy trade-off of RecNets compared to other compact state-of-the-art architectures.
Network Deconvolution
Convolution is a central operation in Convolutional Neural Networks (CNNs), which applies a kernel or mask to overlapping regions shifted across the image. In this work we show that the underlying kernels are trained with highly correlated data, which leads to co-adaptation of model weights. To address this issue we propose what we call network deconvolution, a procedure that aims to remove pixel-wise and channel-wise correlations before the data is fed into each layer. We show that by removing this correlation we are able to achieve better convergence rates during model training with superior results without the use of batch normalization on the CIFAR-10, CIFAR-100, MNIST, Fashion-MNIST datasets, as well as against reference models from ‘model zoo’ on the ImageNet standard benchmark.
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet. To go even further, we use neural architecture search to design a new baseline network and scale it up to obtain a family of models, called EfficientNets, which achieve much better accuracy and efficiency than previous ConvNets. In particular, our EfficientNet-B7 achieves state-of-the-art 84.4% top-1 / 97.1% top-5 accuracy on ImageNet, while being 8.4x smaller and 6.1x faster on inference than the best existing ConvNet. Our EfficientNets also transfer well and achieve state-of-the-art accuracy on CIFAR-100 (91.7%), Flowers (98.8%), and 3 other transfer learning datasets, with an order of magnitude fewer parameters. Source code is at
https://…/efficientnet.
Causal Confusion in Imitation Learning
Behavioral cloning reduces policy learning to supervised learning by training a discriminative model to predict expert actions given observations. Such discriminative models are non-causal: the training procedure is unaware of the causal structure of the interaction between the expert and the environment. We point out that ignoring causality is particularly damaging because of the distributional shift in imitation learning. In particular, it leads to a counter-intuitive ‘causal confusion’ phenomenon: access to more information can yield worse performance. We investigate how this problem arises, and propose a solution to combat it through targeted interventions—either environment interaction or expert queries—to determine the correct causal model. We show that causal confusion occurs in several benchmark control domains as well as realistic driving settings, and validate our solution against DAgger and other baselines and ablations.
Like this:
Like Loading...