SHREWD: Semantic Hierarchy-based Relational Embeddings for Weakly-supervised Deep Hashing
Using class labels to represent class similarity is a typical approach to training deep hashing systems for retrieval; samples from the same or different classes take binary 1 or 0 similarity values. This similarity does not model the full rich knowledge of semantic relations that may be present between data points. In this work we build upon the idea of using semantic hierarchies to form distance metrics between all available sample labels; for example cat to dog has a smaller distance than cat to guitar. We combine this type of semantic distance into a loss function to promote similar distances between the deep neural network embeddings. We also introduce an empirical Kullback-Leibler divergence loss term to promote binarization and uniformity of the embeddings. We test the resulting SHREWD method and demonstrate improvements in hierarchical retrieval scores using compact, binary hash codes instead of real valued ones, and show that in a weakly supervised hashing setting we are able to learn competitively without explicitly relying on class labels, but instead on similarities between labels.
Distributionally Robust Optimization: A Review
The concepts of risk-aversion, chance-constrained optimization, and robust optimization have developed significantly over the last decade. Statistical learning community has also witnessed a rapid theoretical and applied growth by relying on these concepts. A modeling framework, called distributionally robust optimization (DRO), has recently received significant attention in both the operations research and statistical learning communities. This paper surveys main concepts and contributions to DRO, and its relationships with robust optimization, risk-aversion, chance-constrained optimization, and function regularization.
GraphSW: a training protocol based on stage-wise training for GNN-based Recommender Model
Recently, researchers utilize Knowledge Graph (KG) as side information in recommendation system to address cold start and sparsity issue and improve the recommendation performance. Existing KG-aware recommendation model use the feature of neighboring entities and structural information to update the embedding of currently located entity. Although the fruitful information is beneficial to the following task, the cost of exploring the entire graph is massive and impractical. In order to reduce the computational cost and maintain the pattern of extracting features, KG-aware recommendation model usually utilize fixed-size and random set of neighbors rather than complete information in KG. Nonetheless, there are two critical issues in these approaches: First of all, fixed-size and randomly selected neighbors restrict the view of graph. In addition, as the order of graph feature increases, the growth of parameter dimensionality of the model may lead the training process hard to converge. To solve the aforementioned limitations, we propose GraphSW, a strategy based on stage-wise training framework which would only access to a subset of the entities in KG in every stage. During the following stages, the learned embedding from previous stages is provided to the network in the next stage and the model can learn the information gradually from the KG. We apply stage-wise training on two SOTA recommendation models, RippleNet and Knowledge Graph Convolutional Networks (KGCN). Moreover, we evaluate the performance on six real world datasets, Last.FM 2011, Book-Crossing,movie, LFM-1b 2015, Amazon-book and Yelp 2018. The result of our experiments shows that proposed strategy can help both models to collect more information from the KG and improve the performance. Furthermore, it is observed that GraphSW can assist KGCN to converge effectively in high-order graph feature.
CUPCF: Combining Users Preferences in Collaborative Filtering for Better Recommendation
How to make the best decision between the opinions and tastes of your friends and acquaintances? Therefore, recommender systems are used to solve such issues. The common algorithms use a similarity measure to predict active users’ tastes over a particular item. According to the cold start and data sparsity problems, these systems cannot predict and suggest particular items to users. In this paper, we introduce a new recommender system is able to find user preferences and based on it, provides the recommendations. Our proposed system called CUPCF is a combination of two similarity measures in collaborative filtering to solve the data sparsity problem and poor prediction (high prediction error rate) problems for better recommendation. The experimental results based on MovieLens dataset show that, combined with the preferences of the user’s nearest neighbor, the proposed system error rate compared to a number of state-of-the-art recommendation methods improved. Furthermore, the results indicate the efficiency of CUPCF. The maximum improved error rate of the system is 15.5% and the maximum values of Accuracy, Precision and Recall of CUPCF are 0.91402, 0.91436 and 0.9974 respectively.
On Separating Points for Ensemble Controllability
Recent years have witnessed a wave of research activities in systems science toward the study of population systems. The driving force behind this shift was geared by numerous emerging and ever-changing technologies in life and physical sciences and engineering, from neuroscience, biology, and quantum physics to robotics, where many control-enabled applications involve manipulating a large ensemble of structurally identical dynamic units, or agents. Analyzing fundamental properties of ensemble control systems in turn plays a foundational and critical role in enabling and, further, advancing these applications, and the analysis is largely beyond the capability of classical control techniques. In this paper, we consider an ensemble of time-invariant linear systems evolving on an infinite-dimensional space of continuous functions. We exploit the notion of separating points and techniques of polynomial approximation to develop necessary and sufficient ensemble controllability conditions. In particular, we introduce an extended notion of controllability matrix, called Ensemble Controllability Gramian. This means enables the characterization of ensemble controllability through evaluating controllability of each individual system in the ensemble. As a result, the work provides a unified framework with a systematic procedure for analyzing control systems defined on an infinite-dimensional space by a finite-dimensional approach.
End-to-End Learning from Complex Multigraphs with Latent Graph Convolutional Networks
We study the problem of end-to-end learning from complex multigraphs with potentially very large numbers of edges between two vertices, each edge labeled with rich information. Examples of such graphs include financial transactions, communication networks, or flights between airports. We propose Latent-Graph Convolutional Networks (L-GCNs), which can successfully propagate information from these edge labels to a latent adjacency tensor, after which further propagation and downstream tasks can be performed, such as node classification. We evaluate the performance of several variations of the model on two synthetic datasets simulating fraud in financial transaction networks, to ensure that the model must make use of edge labels in order to achieve good classification performance. We find that allowing for nonlinear interactions on a per-neighbor basis enhances performance significantly, while also showing promising results in an inductive setting.
Maximum Relevance and Minimum Redundancy Feature Selection Methods for a Marketing Machine Learning Platform
In machine learning applications for online product offerings and marketing strategies, there are often hundreds or thousands of features available to build such models. Feature selection is one essential method in such applications for multiple objectives: improving the prediction accuracy by eliminating irrelevant features, accelerating the model training and prediction speed, reducing the monitoring and maintenance workload for feature data pipeline, and providing better model interpretation and diagnosis capability. However, selecting an optimal feature subset from a large feature space is considered as an NP-complete problem. The mRMR (Minimum Redundancy and Maximum Relevance) feature selection framework solves this problem by selecting the relevant features while controlling for the redundancy within the selected features. This paper describes the approach to extend, evaluate, and implement the mRMR feature selection methods for classification problem in a marketing machine learning platform at Uber that automates creation and deployment of targeting and personalization models at scale. This study first extends the existing mRMR methods by introducing a non-linear feature redundancy measure and a model-based feature relevance measure. Then an extensive empirical evaluation is performed for eight different feature selection methods, using one synthetic dataset and three real-world marketing datasets at Uber to cover different use cases. Based on the empirical results, the selected mRMR method is implemented in production for the marketing machine learning platform. A description of the production implementation is provided and an online experiment deployed through the platform is discussed.
Towards Knowledge-Based Recommender Dialog System
In this paper, we propose a novel end-to-end framework called KBRD, which stands for Knowledge-Based Recommender Dialog System. It integrates the recommender system and the dialog generation system. The dialog system can enhance the performance of the recommendation system by introducing knowledge-grounded information about users’ preferences, and the recommender system can improve that of the dialog generation system by providing recommendation-aware vocabulary bias. Experimental results demonstrate that our proposed model has significant advantages over the baselines in both the evaluation of dialog generation and recommendation. A series of analyses show that the two systems can bring mutual benefits to each other, and the introduced knowledge bridges the gap between the two systems.
Connected Fair Allocation of Indivisible Goods
We study the fair allocation of indivisible goods under the assumption that the goods form an undirected graph and each agent must receive a connected subgraph. Our focus is on well-studied fairness notions including envy-freeness and maximin share fairness. We establish graph-specific maximin share guarantees, which are tight for large classes of graphs in the case of two agents and for paths and stars in the general case. Unlike in previous work, our guarantees are with respect to the complete-graph maximin share, which allows us to compare possible guarantees for different graphs. For instance, we show that for biconnected graphs it is possible to obtain at least
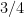
of the maximin share, while for the remaining graphs the guarantee is at most
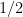
. In addition, we determine the optimal relaxation of envy-freeness that can be obtained with each graph for two agents, and characterize the set of trees and complete bipartite graphs that always admit an allocation satisfying envy-freeness up to one good (EF1) for three agents. Our work demonstrates several applications of graph-theoretical tools and concepts to fair division problems.
Playing a Strategy Game with Knowledge-Based Reinforcement Learning
This paper presents Knowledge-Based Reinforcement Learning (KB-RL) as a method that combines a knowledge-based approach and a reinforcement learning (RL) technique into one method for intelligent problem solving. The proposed approach focuses on multi-expert knowledge acquisition, with the reinforcement learning being applied as a conflict resolution strategy aimed at integrating the knowledge of multiple exerts into one knowledge base. The article describes the KB-RL approach in detail and applies the reported method to one of the most challenging problems of current Artificial Intelligence (AI) research, namely playing a strategy game. The results show that the KB-RL system is able to play and complete the full FreeCiv game, and to win against the computer players in various game settings. Moreover, with more games played, the system improves the gameplay by shortening the number of rounds that it takes to win the game. Overall, the reported experiment supports the idea that, based on human knowledge and empowered by reinforcement learning, the KB-RL system can deliver a strong solution to the complex, multi-strategic problems, and, mainly, to improve the solution with increased experience.
Adaptive Regularization of Labels
Recently, a variety of regularization techniques have been widely applied in deep neural networks, such as dropout, batch normalization, data augmentation, and so on. These methods mainly focus on the regularization of weight parameters to prevent overfitting effectively. In addition, label regularization techniques such as label smoothing and label disturbance have also been proposed with the motivation of adding a stochastic perturbation to labels. In this paper, we propose a novel adaptive label regularization method, which enables the neural network to learn from the erroneous experience and update the optimal label representation online. On the other hand, compared with knowledge distillation, which learns the correlation of categories using teacher network, our proposed method requires only a minuscule increase in parameters without cumbersome teacher network. Furthermore, we evaluate our method on CIFAR-10/CIFAR-100/ImageNet datasets for image recognition tasks and AGNews/Yahoo/Yelp-Full datasets for text classification tasks. The empirical results show significant improvement under all experimental settings.
Towards Automated Machine Learning: Evaluation and Comparison of AutoML Approaches and Tools
There has been considerable growth and interest in industrial applications of machine learning (ML) in recent years. ML engineers, as a consequence, are in high demand across the industry, yet improving the efficiency of ML engineers remains a fundamental challenge. Automated machine learning (AutoML) has emerged as a way to save time and effort on repetitive tasks in ML pipelines, such as data pre-processing, feature engineering, model selection, hyperparameter optimization, and prediction result analysis. In this paper, we investigate the current state of AutoML tools aiming to automate these tasks. We conduct various evaluations of the tools on many datasets, in different data segments, to examine their performance, and compare their advantages and disadvantages on different test cases.
Visualizing and Understanding the Effectiveness of BERT
Language model pre-training, such as BERT, has achieved remarkable results in many NLP tasks. However, it is unclear why the pre-training-then-fine-tuning paradigm can improve performance and generalization capability across different tasks. In this paper, we propose to visualize loss landscapes and optimization trajectories of fine-tuning BERT on specific datasets. First, we find that pre-training reaches a good initial point across downstream tasks, which leads to wider optima and easier optimization compared with training from scratch. We also demonstrate that the fine-tuning procedure is robust to overfitting, even though BERT is highly over-parameterized for downstream tasks. Second, the visualization results indicate that fine-tuning BERT tends to generalize better because of the flat and wide optima, and the consistency between the training loss surface and the generalization error surface. Third, the lower layers of BERT are more invariant during fine-tuning, which suggests that the layers that are close to input learn more transferable representations of language.
SenseBERT: Driving Some Sense into BERT
Self-supervision techniques have allowed neural language models to advance the frontier in Natural Language Understanding. However, existing self-supervision techniques operate at the word-form level, which serves as a surrogate for the underlying semantic content. This paper proposes a method to employ self-supervision directly at the word-sense level. Our model, named SenseBERT, is pre-trained to predict not only the masked words but also their WordNet supersenses. Accordingly, we attain a lexical-semantic level language model, without the use of human annotation. SenseBERT achieves significantly improved lexical understanding, as we demonstrate by experimenting on SemEval, and by attaining a state of the art result on the Word in Context (WiC) task. Our approach is extendable to other linguistic signals, which can be similarly integrated into the pre-training process, leading to increasingly semantically informed language models.
Like this:
Like Loading...