Clustering of Medical Free-Text Records Based on Word Embeddings
Is it true that patients with similar conditions get similar diagnoses? In this paper we show NLP methods and a unique corpus of documents to validate this claim. We (1) introduce a method for representation of medical visits based on free-text descriptions recorded by doctors, (2) introduce a new method for clustering of patients’ visits and (3) present an~application of the proposed method on a corpus of 100,000 visits. With the proposed method we obtained stable and separated segments of visits which were positively validated against final medical diagnoses. We show how the presented algorithm may be used to aid doctors during their practice.
Multiple membership multilevel models
Multiple membership multilevel models are an extension of standard multilevel models for non-hierarchical data that have multiple membership structures. Traditional multilevel models involve hierarchical data structures whereby lower-level units such as students are nested within higher-level units such as schools and where these higher-level units may in turn be nested within further groupings or clusters such as school districts, regions, and countries. With hierarchical data structures, there is an exact nesting of each lower-level unit in one and only one higher-level unit. For example, each student attends one school, each school is located within one school district, and so on. However, social reality is more complicated than this, and so social and behavioural data often do not follow pure or strict hierarchies. Two types of non-hierarchical data structures which often appear in practice are cross-classified and multiple membership structures. In this article, we describe multiple membership data structures and multiple membership models which can be used to analyse them.
The Game of Poker Chips, Dominoes and Survival
The Game of Poker Chips, Dominoes and Survival was created to foster cohesion in a group setting. Given two colored poker chips, each player needs to secure a domino before time is called in order to `survive’, and can make exchanges according to two simple rules. Analysis reveals that the group will be forced to cooperate at a high level in order to succeed, and a simple time complexity computation shows how the game coordinator can choose the initial distribution of poker chips to the players in order to fine tune the game’s difficulty. A simple criteria is given for determining if the game is `solvable’ for any given initial chip distribution, that is, if all players can survive if given sufficient time to make exchanges. The best strategies for group survival, that is, those taking the least amount of time, are provided as consequences of simple complexity arguments. In addition to being a lively game to play in management training or classroom settings, the analysis of the game after play can make for an engaging exercise in any basic discrete mathematics course to give a basic introduction to elements of game theory, logical reasoning, induction, recursion, number theory and the computation of algorithmic complexities.
Entropic Regularization of Markov Decision Processes
An optimal feedback controller for a given Markov decision process (MDP) can in principle be synthesized by value or policy iteration. However, if the system dynamics and the reward function are unknown, a learning agent has to discover an optimal controller via direct interaction with the environment. Such interactive data gathering commonly leads to divergence towards dangerous or uninformative regions of the state space unless additional regularization measures are taken. Prior works proposed to bound the information loss measured by the Kullback-Leibler (KL) divergence at every policy improvement step to eliminate instability in the learning dynamics. In this paper, we consider a broader family of

-divergences, and more concretely

-divergences, which inherit the beneficial property of providing the policy improvement step in closed form at the same time yielding a corresponding dual objective for policy evaluation. Such entropic proximal policy optimization view gives a unified perspective on compatible actor-critic architectures. In particular, common least squares value function estimation coupled with advantage-weighted maximum likelihood policy improvement is shown to correspond to the Pearson
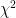
-divergence penalty. Other actor-critic pairs arise for various choices of the penalty generating function
. On a concrete instantiation of our framework with the
-divergence, we carry out asymptotic analysis of the solutions for different values of~
and demonstrate the effects of the divergence function choice on common standard reinforcement learning problems.
A Human-Grounded Evaluation of SHAP for Alert Processing
In the past years, many new explanation methods have been proposed to achieve interpretability of machine learning predictions. However, the utility of these methods in practical applications has not been researched extensively. In this paper we present the results of a human-grounded evaluation of SHAP, an explanation method that has been well-received in the XAI and related communities. In particular, we study whether this local model-agnostic explanation method can be useful for real human domain experts to assess the correctness of positive predictions, i.e. alerts generated by a classifier. We performed experimentation with three different groups of participants (159 in total), who had basic knowledge of explainable machine learning. We performed a qualitative analysis of recorded reflections of experiment participants performing alert processing with and without SHAP information. The results suggest that the SHAP explanations do impact the decision-making process, although the model’s confidence score remains to be a leading source of evidence. We statistically test whether there is a significant difference in task utility metrics between tasks for which an explanation was available and tasks in which it was not provided. As opposed to common intuitions, we did not find a significant difference in alert processing performance when a SHAP explanation is available compared to when it is not.
Improving short text classification through global augmentation methods
We study the effect of different approaches to text augmentation. To do this we use 3 datasets that include social media and formal text in the form of news articles. Our goal is to provide insights for practitioners and researchers on making choices for augmentation for classification use cases. We observe that Word2vec-based augmentation is a viable option when one does not have access to a formal synonym model (like WordNet-based augmentation). The use of \emph{mixup} further improves performance of all text based augmentations and reduces the effects of overfitting on a tested deep learning model. Round-trip translation with a translation service proves to be harder to use due to cost and as such is less accessible for both normal and low resource use-cases.
Case-Based Reasoning for Assisting Domain Experts in Processing Fraud Alerts of Black-Box Machine Learning Models
In many contexts, it can be useful for domain experts to understand to what extent predictions made by a machine learning model can be trusted. In particular, estimates of trustworthiness can be useful for fraud analysts who process machine learning-generated alerts of fraudulent transactions. In this work, we present a case-based reasoning (CBR) approach that provides evidence on the trustworthiness of a prediction in the form of a visualization of similar previous instances. Different from previous works, we consider similarity of local post-hoc explanations of predictions and show empirically that our visualization can be useful for processing alerts. Furthermore, our approach is perceived useful and easy to use by fraud analysts at a major Dutch bank.
QUOTIENT: Two-Party Secure Neural Network Training and Prediction
Recently, there has been a wealth of effort devoted to the design of secure protocols for machine learning tasks. Much of this is aimed at enabling secure prediction from highly-accurate Deep Neural Networks (DNNs). However, as DNNs are trained on data, a key question is how such models can be also trained securely. The few prior works on secure DNN training have focused either on designing custom protocols for existing training algorithms, or on developing tailored training algorithms and then applying generic secure protocols. In this work, we investigate the advantages of designing training algorithms alongside a novel secure protocol, incorporating optimizations on both fronts. We present QUOTIENT, a new method for discretized training of DNNs, along with a customized secure two-party protocol for it. QUOTIENT incorporates key components of state-of-the-art DNN training such as layer normalization and adaptive gradient methods, and improves upon the state-of-the-art in DNN training in two-party computation. Compared to prior work, we obtain an improvement of 50X in WAN time and 6% in absolute accuracy.
Privacy-Preserving Classification with Secret Vector Machines
Today, large amounts of valuable data are distributed among millions of user-held devices, such as personal computers, phones, or Internet-of-things devices. Many companies collect such data with the goal of using it for training machine learning models allowing them to improve their services. However, user-held data is often sensitive, and collecting it is problematic in terms of privacy. We address this issue by proposing a novel way of training a supervised classifier in a distributed setting akin to the recently proposed federated learning paradigm (McMahan et al. 2017), but under the stricter privacy requirement that the server that trains the model is assumed to be untrusted and potentially malicious; we thus preserve user privacy by design, rather than by trust. In particular, our framework, called secret vector machine (SecVM), provides an algorithm for training linear support vector machines (SVM) in a setting in which data-holding clients communicate with an untrusted server by exchanging messages designed to not reveal any personally identifiable information. We evaluate our model in two ways. First, in an offline evaluation, we train SecVM to predict user gender from tweets, showing that we can preserve user privacy without sacrificing classification performance. Second, we implement SecVM’s distributed framework for the Cliqz web browser and deploy it for predicting user gender in a large-scale online evaluation with thousands of clients, outperforming baselines by a large margin and thus showcasing that SecVM is practicable in production environments. Overall, this work demonstrates the feasibility of machine learning on data from thousands of users without collecting any personal data. We believe this is an innovative approach that will help reconcile machine learning with data privacy.
The Price of Interpretability
When quantitative models are used to support decision-making on complex and important topics, understanding a model’s “reasoning” can increase trust in its predictions, expose hidden biases, or reduce vulnerability to adversarial attacks. However, the concept of interpretability remains loosely defined and application-specific. In this paper, we introduce a mathematical framework in which machine learning models are constructed in a sequence of interpretable steps. We show that for a variety of models, a natural choice of interpretable steps recovers standard interpretability proxies (e.g., sparsity in linear models). We then generalize these proxies to yield a parametrized family of consistent measures of model interpretability. This formal definition allows us to quantify the “price” of interpretability, i.e., the tradeoff with predictive accuracy. We demonstrate practical algorithms to apply our framework on real and synthetic datasets.
Guidelines for benchmarking of optimization approaches for fitting mathematical models
Insufficient performance of optimization approaches for fitting of mathematical models is still a major bottleneck in systems biology. In this manuscript, the reasons and methodological challenges are summarized as well as their impact in benchmark studies. Important aspects for increasing evidence of outcomes of benchmark analyses are discussed. Based on general guidelines for benchmarking in computational biology, a collection of tailored guidelines is presented for performing informative and unbiased benchmarking of optimization-based fitting approaches. Comprehensive benchmark studies based on these recommendations are urgently required for establishing of a robust and reliable methodology for the systems biology community.
The GDPR & Speech Data: Reflections of Legal and Technology Communities, First Steps towards a Common Understanding
Privacy preservation and the protection of speech data is in high demand, not least as a result of recent regulation, e.g. the General Data Protection Regulation (GDPR) in the EU. While there has been a period with which to prepare for its implementation, its implications for speech data is poorly understood. This assertion applies to both the legal and technology communities, and is hardly surprising since there is no universal definition of ‘privacy’, let alone a clear understanding of when or how the GDPR applies to the capture, storage and processing of speech data. In aiming to initiate the discussion that is needed to establish a level of harmonisation that is thus far lacking, this contribution presents some reflections of both legal and technology communities on the implications of the GDPR as regards speech data. The article outlines the need for taxonomies at the intersection of speech technology and data privacy – a discussion that is still very much in its infancy – and describes the ways to safeguards and priorities for future research. In being agnostic to any specific application, the treatment should be of interest to the speech communication community at large.
Joint Neural Collaborative Filtering for Recommender Systems
We propose a J-NCF method for recommender systems. The J-NCF model applies a joint neural network that couples deep feature learning and deep interaction modeling with a rating matrix. Deep feature learning extracts feature representations of users and items with a deep learning architecture based on a user-item rating matrix. Deep interaction modeling captures non-linear user-item interactions with a deep neural network using the feature representations generated by the deep feature learning process as input. J-NCF enables the deep feature learning and deep interaction modeling processes to optimize each other through joint training, which leads to improved recommendation performance. In addition, we design a new loss function for optimization, which takes both implicit and explicit feedback, point-wise and pair-wise loss into account. Experiments on several real-word datasets show significant improvements of J-NCF over state-of-the-art methods, with improvements of up to 8.24% on the MovieLens 100K dataset, 10.81% on the MovieLens 1M dataset, and 10.21% on the Amazon Movies dataset in terms of HR@10. NDCG@10 improvements are 12.42%, 14.24% and 15.06%, respectively. We also conduct experiments to evaluate the scalability and sensitivity of J-NCF. Our experiments show that the J-NCF model has a competitive recommendation performance with inactive users and different degrees of data sparsity when compared to state-of-the-art baselines.
Graph Signal Processing — Part I: Graphs, Graph Spectra, and Spectral Clustering
The area of Data Analytics on graphs promises a paradigm shift as we approach information processing of classes of data, which are typically acquired on irregular but structured domains (social networks, various ad-hoc sensor networks). Yet, despite its long history, current approaches mostly focus on the optimization of graphs themselves, rather than on directly inferring learning strategies, such as detection, estimation, statistical and probabilistic inference, clustering and separation from signals and data acquired on graphs. To fill this void, we first revisit graph topologies from a Data Analytics point of view, and establish a taxonomy of graph networks through a linear algebraic formalism of graph topology (vertices, connections, directivity). This serves as a basis for spectral analysis of graphs, whereby the eigenvalues and eigenvectors of graph Laplacian and adjacency matrices are shown to convey physical meaning related to both graph topology and higher-order graph properties, such as cuts, walks, paths, and neighborhoods. Next, to illustrate estimation strategies performed on graph signals, spectral analysis of graphs is introduced through eigenanalysis of mathematical descriptors of graphs and in a generic way. Finally, a framework for vertex clustering and graph segmentation is established based on graph spectral representation (eigenanalysis) which illustrates the power of graphs in various data association tasks. The supporting examples demonstrate the promise of Graph Data Analytics in modeling structural and functional/semantic inferences. At the same time, Part I serves as a basis for Part II and Part III which deal with theory, methods and applications of processing Data on Graphs and Graph Topology Learning from data.
Foundations for conditional probability
We analyze several formalizations of conditional probability and find a new one that encompasses all. Our main result is that a preference relation on random quantities called a plausible preorder induces a coherent conditional expectation; and vice versa, that every coherent function can be extended to a conditional expectation induced by a plausible preorder. The advantages of our approach include a convenient justification of probability laws by the properties of plausible preorders, independence on probability interpretations, or the ability to extend conditional probability to any nonzero condition. In particular, if C is a nonzero condition and \Prob is coherent, then it can be extended so that \Prob(0|C)=0, \Prob(C|C)=1 and \Prob(1|C)=1, no matter whether \Prob(C) is zero or whether it is defined.
Searching for Effective Neural Extractive Summarization: What Works and What’s Next
The recent years have seen remarkable success in the use of deep neural networks on text summarization. However, there is no clear understanding of \textit{why} they perform so well, or \textit{how} they might be improved. In this paper, we seek to better understand how neural extractive summarization systems could benefit from different types of model architectures, transferable knowledge and learning schemas. Additionally, we find an effective way to improve current frameworks and achieve the state-of-the-art result on CNN/DailyMail by a large margin based on our observations and analyses. Hopefully, our work could provide more clues for future research on extractive summarization.
Mean field models for large data-clustering problems
We consider mean-field models for data–clustering problems starting from a generalization of the bounded confidence model for opinion dynamics. The microscopic model includes information on the position as well as on additional features of the particles in order to develop specific clustering effects. The corresponding mean–field limit is derived and properties of the model are investigated analytically. In particular, the mean–field formulation allows the use of a random subsets algorithm for efficient computations of the clusters. Applications to shape detection and image segmentation on standard test images are presented and discussed.
Like this:
Like Loading...