Interpretable Adversarial Training for Text
Generating high-quality and interpretable adversarial examples in the text domain is a much more daunting task than it is in the image domain. This is due partly to the discrete nature of text, partly to the problem of ensuring that the adversarial examples are still probable and interpretable, and partly to the problem of maintaining label invariance under input perturbations. In order to address some of these challenges, we introduce sparse projected gradient descent (SPGD), a new approach to crafting interpretable adversarial examples for text. SPGD imposes a directional regularization constraint on input perturbations by projecting them onto the directions to nearby word embeddings with highest cosine similarities. This constraint ensures that perturbations move each word embedding in an interpretable direction (i.e., towards another nearby word embedding). Moreover, SPGD imposes a sparsity constraint on perturbations at the sentence level by ignoring word-embedding perturbations whose norms are below a certain threshold. This constraint ensures that our method changes only a few words per sequence, leading to higher quality adversarial examples. Our experiments with the IMDB movie review dataset show that the proposed SPGD method improves adversarial example interpretability and likelihood (evaluated by average per-word perplexity) compared to state-of-the-art methods, while suffering little to no loss in training performance.
A Trainable Multiplication Layer for Auto-correlation and Co-occurrence Extraction
In this paper, we propose a trainable multiplication layer (TML) for a neural network that can be used to calculate the multiplication between the input features. Taking an image as an input, the TML raises each pixel value to the power of a weight and then multiplies them, thereby extracting the higher-order local auto-correlation from the input image. The TML can also be used to extract co-occurrence from the feature map of a convolutional network. The training of the TML is formulated based on backpropagation with constraints to the weights, enabling us to learn discriminative multiplication patterns in an end-to-end manner. In the experiments, the characteristics of the TML are investigated by visualizing learned kernels and the corresponding output features. The applicability of the TML for classification and neural network interpretation is also evaluated using public datasets.
Information theoretic learning of robust deep representations
We propose a novel objective function for learning robust deep representations of data based on information theory. Data is projected into a feature-vector space such that the mutual information of all subsets of features relative to the supervising signal is maximized. This objective function gives rise to robust representations by conserving available information relative to supervision in the face of noisy or unavailable features. Although the objective function is not directly tractable, we are able to derive a surrogate objective function. Minimizing this surrogate loss encourages features to be non-redundant and conditionally independent relative to the supervising signal. To evaluate the quality of obtained solutions, we have performed a set of preliminary experiments that show promising results.
Function approximation by deep networks
We show that deep networks are better than shallow networks at approximating functions that can be expressed as a composition of functions described by a directed acyclic graph, because the deep networks can be designed to have the same compositional structure, while a shallow network cannot exploit this knowledge. Thus, the blessing of compositionality mitigates the curse of dimensionality. On the other hand, a theorem called good propagation of errors allows to `lift’ theorems about shallow networks to those about deep networks with an appropriate choice of norms, smoothness, etc. We illustrate this in three contexts where each channel in the deep network calculates a spherical polynomial, a non-smooth ReLU network, or another zonal function network related closely with the ReLU network.
Particle Filter Recurrent Neural Networks
Recurrent neural networks (RNNs) have been extraordinarily successful for prediction with sequential data. To tackle highly variable and noisy real-world data, we introduce Particle Filter Recurrent Neural Networks (PF-RNNs), a new RNN family that explicitly models uncertainty in its internal structure: while an RNN relies on a long, deterministic latent state vector, a PF-RNN maintains a latent state distribution, approximated as a set of particles. For effective learning, we provide a fully differentiable particle filter algorithm that updates the PF-RNN latent state distribution according to the Bayes rule. Experiments demonstrate that the proposed PF-RNNs outperform the corresponding standard gated RNNs on a synthetic robot localization dataset and 10 real-world sequence prediction datasets for text classification, stock price prediction, etc.
AlignFlow: Cycle Consistent Learning from Multiple Domains via Normalizing Flows
Given unpaired data from multiple domains, a key challenge is to efficiently exploit these data sources for modeling a target domain. Variants of this problem have been studied in many contexts, such as cross-domain translation and domain adaptation. We propose AlignFlow, a generative modeling framework for learning from multiple domains via normalizing flows. The use of normalizing flows in AlignFlow allows for a) flexibility in specifying learning objectives via adversarial training, maximum likelihood estimation, or a hybrid of the two methods; and b) exact inference of the shared latent factors across domains at test time. We derive theoretical results for the conditions under which AlignFlow guarantees marginal consistency for the different learning objectives. Furthermore, we show that AlignFlow guarantees exact cycle consistency in mapping datapoints from one domain to another. Empirically, AlignFlow can be used for data-efficient density estimation given multiple data sources and shows significant improvements over relevant baselines on unsupervised domain adaptation.
A General Optimization Framework for Dynamic Time Warping
Dynamic time warping (DTW) is a method that inputs two time-domain signals and outputs a function that warps time in order to approximately align the two signals together. Despite its popularity, DTW has a problem that has eluded researchers for decades: so-called ‘singularities,’ which are sharp irregularities in the time warp function that cause many time points of one signal to be erroneously mapped onto a single point in the other signal. We solve this long-standing problem by reformulating DTW entirely. Here we pose DTW as an optimization problem with several penalty terms in the objective. The first term concerns the time-warped signals, penalizing misalignments, while two additional terms concern the time warping function itself. A penalty on the cumulative amount of warping limits over-fitting, which is similar to ‘ridge’ or ‘lasso’ regularization, and a penalty on the instantaneous slope limits roughness in the time warp function. Different choices of the three objective terms yield different time warping functions that trade off signal fit or alignment and properties of the warping function. The optimization problem we formulate is a classical optimal control problem, with initial and terminal constraints, and a state dimension of one. We describe an effective general method that minimizes the objective by discretizing the values of the original and warped time, and using standard dynamic programming to compute the (globally) optimal warping function with the discretized values. Iterated refinement of this scheme yields a high accuracy warping function in just a few iterations. We include a single, efficient algorithm with linear time complexity and an average runtime that’s 50x faster than the state-of-the-art methods on typical problem sizes. Our method and example data are available in an open-source Python package called GDTW.
Separating an Outlier from a Change
We study the quickest change detection problem with an unknown post-change distribution. In this scenario, the unknown change in the distribution of observations may occur in many ways without much structure, while, before change, an outlier (a false alarm event) is highly structured, following a particular sample path. We first characterize these likely events for the deviation of finite strings and propose a method to test the deviation, relative to the most likely way for it to occur as an outlier. Our method works along with other change detection schemes to substantially reduce the false positive rates associated with the plain scheme used without the heavy computation associated with the generalized likelihood ratio test. Finally, we apply our method on economic market indicators and climate data. Our method successfully captures the regime shifts during times of historical significance and identifies the current climate change phenomenon to be a highly likely regime shift.
Sequential no-Substitution k-Median-Clustering
We study the sample-based

-median clustering objective under a sequential setting without substitutions. In this setting, the goal is to select k centers that approximate the optimal clustering on an unknown distribution from a finite sequence of i.i.d. samples, where any selection of a center must be done immediately after the center is observed and centers cannot be substituted after selection. We provide an efficient algorithm for this setting, and show that its multiplicative approximation factor is twice the approximation factor of an efficient offline algorithm. In addition, we show that if efficiency requirements are removed, there is an algorithm that can obtain the same approximation factor as the best offline algorithm.
One-element Batch Training by Moving Window
Several deep models, esp. the generative, compare the samples from two distributions (e.g. WAE like AutoEncoder models, set-processing deep networks, etc) in their cost functions. Using all these methods one cannot train the model directly taking small size (in extreme — one element) batches, due to the fact that samples are to be compared. We propose a generic approach to training such models using one-element mini-batches. The idea is based on splitting the batch in latent into parts: previous, i.e. historical, elements used for latent space distribution matching and the current ones, used both for latent distribution computation and the minimization process. Due to the smaller memory requirements, this allows to train networks on higher resolution images then in the classical approach.
Learning Nonsymmetric Determinantal Point Processes
Determinantal point processes (DPPs) have attracted substantial attention as an elegant probabilistic model that captures the balance between quality and diversity within sets. DPPs are conventionally parameterized by a positive semi-definite kernel matrix, and this symmetric kernel encodes only repulsive interactions between items. These so-called symmetric DPPs have significant expressive power, and have been successfully applied to a variety of machine learning tasks, including recommendation systems, information retrieval, and automatic summarization, among many others. Efficient algorithms for learning symmetric DPPs and sampling from these models have been reasonably well studied. However, relatively little attention has been given to nonsymmetric DPPs, which relax the symmetric constraint on the kernel. Nonsymmetric DPPs allow for both repulsive and attractive item interactions, which can significantly improve modeling power, resulting in a model that may better fit for some applications. We present a method that enables a tractable algorithm, based on maximum likelihood estimation, for learning nonsymmetric DPPs from data composed of observed subsets. Our method imposes a particular decomposition of the nonsymmetric kernel that enables such tractable learning algorithms, which we analyze both theoretically and experimentally. We evaluate our model on synthetic and real-world datasets, demonstrating improved predictive performance compared to symmetric DPPs, which have previously shown strong performance on modeling tasks associated with these datasets.
Generalized Separable Nonnegative Matrix Factorization
Nonnegative matrix factorization (NMF) is a linear dimensionality technique for nonnegative data with applications such as image analysis, text mining, audio source separation and hyperspectral unmixing. Given a data matrix

and a factorization rank

, NMF looks for a nonnegative matrix

with
columns and a nonnegative matrix

with
rows such that
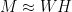
. NMF is NP-hard to solve in general. However, it can be computed efficiently under the separability assumption which requires that the basis vectors appear as data points, that is, that there exists an index set
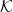
such that
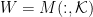
. In this paper, we generalize the separability assumption: We only require that for each rank-one factor

for
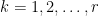
, either
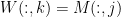
for some

or
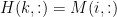
for some

. We refer to the corresponding problem as generalized separable NMF (GS-NMF). We discuss some properties of GS-NMF and propose a convex optimization model which we solve using a fast gradient method. We also propose a heuristic algorithm inspired by the successive projection algorithm. To verify the effectiveness of our methods, we compare them with several state-of-the-art separable NMF algorithms on synthetic, document and image data sets.
Neural Consciousness Flow
The ability of reasoning beyond data fitting is substantial to deep learning systems in order to make a leap forward towards artificial general intelligence. A lot of efforts have been made to model neural-based reasoning as an iterative decision-making process based on recurrent networks and reinforcement learning. Instead, inspired by the consciousness prior proposed by Yoshua Bengio, we explore reasoning with the notion of attentive awareness from a cognitive perspective, and formulate it in the form of attentive message passing on graphs, called neural consciousness flow (NeuCFlow). Aiming to bridge the gap between deep learning systems and reasoning, we propose an attentive computation framework with a three-layer architecture, which consists of an unconsciousness flow layer, a consciousness flow layer, and an attention flow layer. We implement the NeuCFlow model with graph neural networks (GNNs) and conditional transition matrices. Our attentive computation greatly reduces the complexity of vanilla GNN-based methods, capable of running on large-scale graphs. We validate our model for knowledge graph reasoning by solving a series of knowledge base completion (KBC) tasks. The experimental results show NeuCFlow significantly outperforms previous state-of-the-art KBC methods, including the embedding-based and the path-based. The reproducible code can be found by the link below.
The Bloom Clock
The bloom clock is a space-efficient, probabilistic data structure designed to determine the partial order of events in highly distributed systems. The bloom clock, like the vector clock, can autonomously detect causality violations by comparing its logical timestamps. Unlike the vector clock, the space complexity of the bloom clock does not depend on the number of nodes in a system. Instead it depends on a set of chosen parameters that determine its confidence interval, i.e. false positive rate. To reduce the space complexity from which the vector clock suffers, the bloom clock uses a ‘moving window’ in which the partial order of events can be inferred with high confidence. If two clocks are not comparable, the bloom clock can always deduce it, i.e. false negatives are not possible. If two clocks are comparable, the bloom clock can calculate the confidence of that statement, i.e. it can compute the false positive rate between comparable pairs of clocks. By choosing an acceptable threshold for the false positive rate, the bloom clock can properly compare the order of its timestamps, with that of other nodes in a highly accurate and space efficient way.
Visualizing a Moving Target: A Design Study on Task Parallel Programs in the Presence of Evolving Data and Concerns
Common pitfalls in visualization projects include lack of data availability and the domain users’ needs and focus changing too rapidly for the design process to complete. While it is often prudent to avoid such projects, we argue it can be beneficial to engage them in some cases as the visualization process can help refine data collection, solving a `chicken and egg’ problem of having the data and tools to analyze it. We found this to be the case in the domain of task parallel computing. Parallel and distributed programs orchestrate the cooperation of many computation resources to produce results that would be impossible to collect on a single machine. The complexity of orchestrating and fine-tuning the execution of these parallel and distributed computations requires careful consideration from the programmer. However, few performance data collection and analysis tools are geared towards the specifics of task parallel paradigms. What changes need to be made are an open area of research. Despite these hurdles, we conducted a design study. Through a tightly-coupled iterative design process, we built Atria, a multi-view execution graph visualization to support performance analysis. Atria simplifies the initial representation of the execution graph by aggregating nodes as related to their line of code. We deployed Atria on multiple platforms, some requiring design alteration. Our evaluation is augmented with user interviews. We further describe how we adapted the design study methodology to the `moving target’ of both the data and the domain experts’ concerns and how this movement kept both the visualization and programming project healthy. We reflect on our process and discuss what factors allow the project to be successful in the presence of changing data and user needs.
Deep Adversarial Social Recommendation
Recent years have witnessed rapid developments on social recommendation techniques for improving the performance of recommender systems due to the growing influence of social networks to our daily life. The majority of existing social recommendation methods unify user representation for the user-item interactions (item domain) and user-user connections (social domain). However, it may restrain user representation learning in each respective domain, since users behave and interact differently in the two domains, which makes their representations to be heterogeneous. In addition, most of traditional recommender systems can not efficiently optimize these objectives, since they utilize negative sampling technique which is unable to provide enough informative guidance towards the training during the optimization process. In this paper, to address the aforementioned challenges, we propose a novel deep adversarial social recommendation framework DASO. It adopts a bidirectional mapping method to transfer users’ information between social domain and item domain using adversarial learning. Comprehensive experiments on two real-world datasets show the effectiveness of the proposed framework.
Confirmatory Bayesian Online Change Point Detection in the Covariance Structure of Gaussian Processes
In the analysis of sequential data, the detection of abrupt changes is important in predicting future changes. In this paper, we propose statistical hypothesis tests for detecting covariance structure changes in locally smooth time series modeled by Gaussian Processes (GPs). We provide theoretically justified thresholds for the tests, and use them to improve Bayesian Online Change Point Detection (BOCPD) by confirming statistically significant changes and non-changes. Our Confirmatory BOCPD (CBOCPD) algorithm finds multiple structural breaks in GPs even when hyperparameters are not tuned precisely. We also provide conditions under which CBOCPD provides the lower prediction error compared to BOCPD. Experimental results on synthetic and real-world datasets show that our new tests correctly detect changes in the covariance structure in GPs. The proposed algorithm also outperforms existing methods for the prediction of nonstationarity in terms of both regression error and log likelihood.
Graph Normalizing Flows
We introduce graph normalizing flows: a new, reversible graph neural network model for prediction and generation. On supervised tasks, graph normalizing flows perform similarly to message passing neural networks, but at a significantly reduced memory footprint, allowing them to scale to larger graphs. In the unsupervised case, we combine graph normalizing flows with a novel graph auto-encoder to create a generative model of graph structures. Our model is permutation-invariant, generating entire graphs with a single feed-forward pass, and achieves competitive results with the state-of-the art auto-regressive models, while being better suited to parallel computing architectures.
AssembleNet: Searching for Multi-Stream Neural Connectivity in Video Architectures
Learning to represent videos is a very challenging task both algorithmically and computationally. Standard video CNN architectures have been designed by directly extending architectures devised for image understanding to a third dimension (using a limited number of space-time modules such as 3D convolutions) or by introducing a handcrafted two-stream design to capture both appearance and motion in videos. We interpret a video CNN as a collection of multi-stream space-time convolutional blocks connected to each other, and propose the approach of automatically finding neural architectures with better connectivity for video understanding. This is done by evolving a population of overly-connected architectures guided by connection weight learning. Architectures combining representations that abstract different input types (i.e., RGB and optical flow) at multiple temporal resolutions are searched for, allowing different types or sources of information to interact with each other. Our method, referred to as AssembleNet, outperforms prior approaches on public video datasets, in some cases by a great margin.
What Can Neural Networks Reason About?
Neural networks have successfully been applied to solving reasoning tasks, ranging from learning simple concepts like ‘close to’, to intricate questions whose reasoning procedures resemble algorithms. Empirically, not all network structures work equally well for reasoning. For example, Graph Neural Networks have achieved impressive empirical results, while less structured neural networks may fail to learn to reason. Theoretically, there is currently limited understanding of the interplay between reasoning tasks and network learning. In this paper, we develop a framework to characterize which tasks a neural network can learn well, by studying how well its structure aligns with the algorithmic structure of the relevant reasoning procedure. This suggests that Graph Neural Networks can learn dynamic programming, a powerful algorithmic strategy that solves a broad class of reasoning problems, such as relational question answering, sorting, intuitive physics, and shortest paths. Our perspective also implies strategies to design neural architectures for complex reasoning. On several abstract reasoning tasks, we see empirically that our theory aligns well with practice.
On Network Design Spaces for Visual Recognition
Over the past several years progress in designing better neural network architectures for visual recognition has been substantial. To help sustain this rate of progress, in this work we propose to reexamine the methodology for comparing network architectures. In particular, we introduce a new comparison paradigm of distribution estimates, in which network design spaces are compared by applying statistical techniques to populations of sampled models, while controlling for confounding factors like network complexity. Compared to current methodologies of comparing point and curve estimates of model families, distribution estimates paint a more complete picture of the entire design landscape. As a case study, we examine design spaces used in neural architecture search (NAS). We find significant statistical differences between recent NAS design space variants that have been largely overlooked. Furthermore, our analysis reveals that the design spaces for standard model families like ResNeXt can be comparable to the more complex ones used in recent NAS work. We hope these insights into distribution analysis will enable more robust progress toward discovering better networks for visual recognition.
Like this:
Like Loading...