Forecasting Weakly Correlated Time Series in Tasks of Electronic Commerce
Forecasting of weakly correlated time series of conversion rate by methods of exponential smoothing, neural network and decision tree on the example of conversion percent series for an electronic store is considered in the paper. The advantages and disadvantages of each method are considered.
Data Cleaning for Accurate, Fair, and Robust Models: A Big Data – AI Integration Approach
The wide use of machine learning is fundamentally changing the software development paradigm (a.k.a. Software 2.0) where data becomes a first-class citizen, on par with code. As machine learning is used in sensitive applications, it becomes imperative that the trained model is accurate, fair, and robust to attacks. While many techniques have been proposed to improve the model training process (in-processing approach) or the trained model itself (post-processing), we argue that the most effective method is to clean the root cause of error: the data the model is trained on (pre-processing). Historically, there are at least three research communities that have been separately studying this problem: data management, machine learning (model fairness), and security. Although a significant amount of research has been done by each community, ultimately the same datasets must be preprocessed, and there is little understanding how the techniques relate to each other and can possibly be integrated. We contend that it is time to extend the notion of data cleaning for modern machine learning needs. We identify dependencies among the data preprocessing techniques and propose MLClean, a unified data cleaning framework that integrates the techniques and helps train accurate and fair models. This work is part of a broader trend of Big data — Artificial Intelligence (AI) integration.
CascadeML: An Automatic Neural Network Architecture Evolution and Training Algorithm for Multi-label Classification
Multi-label classification is an approach which allows a datapoint to be labelled with more than one class at the same time. A common but trivial approach is to train individual binary classifiers per label, but the performance can be improved by considering associations within the labels. Like with any machine learning algorithm, hyperparameter tuning is important to train a good multi-label classifier model. The task of selecting the best hyperparameter settings for an algorithm is an optimisation problem. Very limited work has been done on automatic hyperparameter tuning and AutoML in the multi-label domain. This paper attempts to fill this gap by proposing a neural network algorithm, CascadeML, to train multi-label neural network based on cascade neural networks. This method requires minimal or no hyperparameter tuning and also considers pairwise label associations. The cascade algorithm grows the network architecture incrementally in a two phase process as it learns the weights using adaptive first order gradient algorithm, therefore omitting the requirement of preselecting the number of hidden layers, nodes and the learning rate. The method was tested on 10 multi-label datasets and compared with other multi-label classification algorithms. Results show that CascadeML performs very well without hyperparameter tuning.
KFHE-HOMER: Kalman Filter-based Heuristic Ensemble of HOMER for Multi-Label Classification
Multi-label classification allows a datapoint to be labelled with more than one class at the same time. Ensemble methods generally perform much better than single classifiers. Except bagging style ensembles like ECC, RAkEL, in multi-label classification, other ensemble methods have not been explored much. KFHE (Kalman Filter-based Heuristic Ensemble), is a recent ensemble method which uses the Kalman filter to combine several models. KFHE views the final ensemble to be learned as a state to be estimated which it estimates using multiple noisy ‘measurements’. These ‘measurements’ are essentially component classifiers trained under different settings. This work extends KFHE to multi-label domain by proposing KFHE-HOMER which enhances the performance of HOMER using the KFHE framework. KFHE-HOMER sequentially trains multiple HOMER classifiers using weighted training datapoints and random hyperparameters. These models are considered as measurements and their related error as the uncertainty of the measurements. Then the Kalman filter framework is used to combine these measurements to get a more accurate estimate. The method was tested on 10 multi-label datasets and compared with other multi-label classification algorithms. Results show that KFHE-HOMER performs consistently better than similar multi-label ensemble methods.
Deep Q-Learning for Nash Equilibria: Nash-DQN
Model-free learning for multi-agent stochastic games is an active area of research. Existing reinforcement learning algorithms, however, are often restricted to zero-sum games, and are applicable only in small state-action spaces or other simplified settings. Here, we develop a new data efficient Deep-Q-learning methodology for model-free learning of Nash equilibria for general-sum stochastic games. The algorithm uses a local linear-quadratic expansion of the stochastic game, which leads to analytically solvable optimal actions. The expansion is parametrized by deep neural networks to give it sufficient flexibility to learn the environment without the need to experience all state-action pairs. We study symmetry properties of the algorithm stemming from label-invariant stochastic games and as a proof of concept, apply our algorithm to learning optimal trading strategies in competitive electronic markets.
Integer Programming for Learning Directed Acyclic Graphs from Continuous Data
Learning directed acyclic graphs (DAGs) from data is a challenging task both in theory and in practice, because the number of possible DAGs scales superexponentially with the number of nodes. In this paper, we study the problem of learning an optimal DAG from continuous observational data. We cast this problem in the form of a mathematical programming model which can naturally incorporate a super-structure in order to reduce the set of possible candidate DAGs. We use the penalized negative log-likelihood score function with both
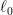
and
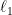
regularizations and propose a new mixed-integer quadratic optimization (MIQO) model, referred to as a layered network (LN) formulation. The LN formulation is a compact model, which enjoys as tight an optimal continuous relaxation value as the stronger but larger formulations under a mild condition. Computational results indicate that the proposed formulation outperforms existing mathematical formulations and scales better than available algorithms that can solve the same problem with only
regularization. In particular, the LN formulation clearly outperforms existing methods in terms of computational time needed to find an optimal DAG in the presence of a sparse super-structure.
Neural Collaborative Subspace Clustering
We introduce the Neural Collaborative Subspace Clustering, a neural model that discovers clusters of data points drawn from a union of low-dimensional subspaces. In contrast to previous attempts, our model runs without the aid of spectral clustering. This makes our algorithm one of the kinds that can gracefully scale to large datasets. At its heart, our neural model benefits from a classifier which determines whether a pair of points lies on the same subspace or not. Essential to our model is the construction of two affinity matrices, one from the classifier and the other from a notion of subspace self-expressiveness, to supervise training in a collaborative scheme. We thoroughly assess and contrast the performance of our model against various state-of-the-art clustering algorithms including deep subspace-based ones.
Design Automation for Efficient Deep Learning Computing
Efficient deep learning computing requires algorithm and hardware co-design to enable specialization: we usually need to change the algorithm to reduce memory footprint and improve energy efficiency. However, the extra degree of freedom from the algorithm makes the design space much larger: it’s not only about designing the hardware but also about how to tweak the algorithm to best fit the hardware. Human engineers can hardly exhaust the design space by heuristics. It’s labor consuming and sub-optimal. We propose design automation techniques for efficient neural networks. We investigate automatically designing specialized fast models, auto channel pruning, and auto mixed-precision quantization. We demonstrate such learning-based, automated design achieves superior performance and efficiency than rule-based human design. Moreover, we shorten the design cycle by 200x than previous work, so that we can afford to design specialized neural network models for different hardware platforms.
Low-Memory Neural Network Training: A Technical Report
Memory is increasingly often the bottleneck when training neural network models. Despite this, techniques to lower the overall memory requirements of training have been less widely studied compared to the extensive literature on reducing the memory requirements of inference. In this paper we study a fundamental question: How much memory is actually needed to train a neural network? To answer this question, we profile the overall memory usage of training on two representative deep learning benchmarks — the WideResNet model for image classification and the DynamicConv Transformer model for machine translation — and comprehensively evaluate four standard techniques for reducing the training memory requirements: (1) imposing sparsity on the model, (2) using low precision, (3) microbatching, and (4) gradient checkpointing. We explore how each of these techniques in isolation affects both the peak memory usage of training and the quality of the end model, and explore the memory, accuracy, and computation tradeoffs incurred when combining these techniques. Using appropriate combinations of these techniques, we show that it is possible to the reduce the memory required to train a WideResNet-28-2 on CIFAR-10 by up to 60.7x with a 0.4% loss in accuracy, and reduce the memory required to train a DynamicConv model on IWSLT’14 German to English translation by up to 8.7x with a BLEU score drop of 0.15.
Who Blames Whom in a Crisis? Detecting Blame Ties from News Articles Using Neural Networks
Blame games tend to follow major disruptions, be they financial crises, natural disasters or terrorist attacks. To study how the blame game evolves and shapes the dominant crisis narratives is of great significance, as sense-making processes can affect regulatory outcomes, social hierarchies, and cultural norms. However, it takes tremendous time and efforts for social scientists to manually examine each relevant news article and extract the blame ties (A blames B). In this study, we define a new task, Blame Tie Extraction, and construct a new dataset related to the United States financial crisis (2007-2010) from The New York Times, The Wall Street Journal and USA Today. We build a Bi-directional Long Short-Term Memory (BiLSTM) network for contexts where the entities appear in and it learns to automatically extract such blame ties at the document level. Leveraging the large unsupervised model such as GloVe and ELMo, our best model achieves an F1 score of 70% on the test set for blame tie extraction, making it a useful tool for social scientists to extract blame ties more efficiently.
Layer Dynamics of Linearised Neural Nets
Despite the phenomenal success of deep learning in recent years, there remains a gap in understanding the fundamental mechanics of neural nets. More research is focussed on handcrafting complex and larger networks, and the design decisions are often ad-hoc and based on intuition. Some recent research has aimed to demystify the learning dynamics in neural nets by attempting to build a theory from first principles, such as characterising the non-linear dynamics of specialised \textit{linear} deep neural nets (such as orthogonal networks). In this work, we expand and derive properties of learning dynamics respected by general multi-layer linear neural nets. Although an over-parameterisation of a single layer linear network, linear multi-layer neural nets offer interesting insights that explain how learning dynamics proceed in small pockets of the data space. We show in particular that multiple layers in linear nets grow at approximately the same rate, and there are distinct phases of learning with markedly different layer growth. We then apply a linearisation process to a general RelU neural net and show how nonlinearity breaks down the growth symmetry observed in liner neural nets. Overall, our work can be viewed as an initial step in building a theory for understanding the effect of layer design on the learning dynamics from first principles.
Neural Logic Reinforcement Learning
Deep reinforcement learning (DRL) has achieved significant breakthroughs in various tasks. However, most DRL algorithms suffer a problem of generalizing the learned policy which makes the learning performance largely affected even by minor modifications of the training environment. Except that, the use of deep neural networks makes the learned policies hard to be interpretable. To address these two challenges, we propose a novel algorithm named Neural Logic Reinforcement Learning (NLRL) to represent the policies in reinforcement learning by first-order logic. NLRL is based on policy gradient methods and differentiable inductive logic programming that have demonstrated significant advantages in terms of interpretability and generalisability in supervised tasks. Extensive experiments conducted on cliff-walking and blocks manipulation tasks demonstrate that NLRL can induce interpretable policies achieving near-optimal performance while demonstrating good generalisability to environments of different initial states and problem sizes.
A bag-of-concepts model improves relation extraction in a narrow knowledge domain with limited data
This paper focuses on a traditional relation extraction task in the context of limited annotated data and a narrow knowledge domain. We explore this task with a clinical corpus consisting of 200 breast cancer follow-up treatment letters in which 16 distinct types of relations are annotated. We experiment with an approach to extracting typed relations called window-bounded co-occurrence (WBC), which uses an adjustable context window around entity mentions of a relevant type, and compare its performance with a more typical intra-sentential co-occurrence baseline. We further introduce a new bag-of-concepts (BoC) approach to feature engineering based on the state-of-the-art word embeddings and word synonyms. We demonstrate the competitiveness of BoC by comparing with methods of higher complexity, and explore its effectiveness on this small dataset.
Latent Variable Session-Based Recommendation
Session based recommendation provides an attractive alternative to the traditional feature engineering approach to recommendation. Feature engineering approaches require hand tuned features of the users history to be created to produce a context vector. In contrast a session based approach is able to dynamically model the users state as they act. We present a probabilistic framework for session based recommendation. A latent variable for the user state is updated as the user views more items and we learn more about their interests. The latent variable model is conceptually simple and elegant; yet requires sophisticated computational technique to approximate the integral over the latent variable. We provide computational solutions using both the re-parameterization trick and also using the Bouchard bound for the softmax function, we further explore employing a variational auto-encoder and a variational Expectation-Maximization algorithm for tightening the variational bound. The model performs well against a number of baselines. The intuitive nature of the model allows an elegant formulation combining correlations between items and their popularity and that sheds light on other popular recommendation methods. An attractive feature of the latent variable approach is that, as the user continues to act, the posterior on the users state tightens reflecting the recommender system’s increased knowledge about that user.
The Scientific Method in the Science of Machine Learning
In the quest to align deep learning with the sciences to address calls for rigor, safety, and interpretability in machine learning systems, this contribution identifies key missing pieces: the stages of hypothesis formulation and testing, as well as statistical and systematic uncertainty estimation — core tenets of the scientific method. This position paper discusses the ways in which contemporary science is conducted in other domains and identifies potentially useful practices. We present a case study from physics and describe how this field has promoted rigor through specific methodological practices, and provide recommendations on how machine learning researchers can adopt these practices into the research ecosystem. We argue that both domain-driven experiments and application-agnostic questions of the inner workings of fundamental building blocks of machine learning models ought to be examined with the tools of the scientific method, to ensure we not only understand effect, but also begin to understand cause, which is the raison d’\^{e}tre of science.
Target-Based Temporal Difference Learning
The use of target networks has been a popular and key component of recent deep Q-learning algorithms for reinforcement learning, yet little is known from the theory side. In this work, we introduce a new family of target-based temporal difference (TD) learning algorithms and provide theoretical analysis on their convergences. In contrast to the standard TD-learning, target-based TD algorithms maintain two separate learning parameters-the target variable and online variable. Particularly, we introduce three members in the family, called the averaging TD, double TD, and periodic TD, where the target variable is updated through an averaging, symmetric, or periodic fashion, mirroring those techniques used in deep Q-learning practice. We establish asymptotic convergence analyses for both averaging TD and double TD and a finite sample analysis for periodic TD. In addition, we also provide some simulation results showing potentially superior convergence of these target-based TD algorithms compared to the standard TD-learning. While this work focuses on linear function approximation and policy evaluation setting, we consider this as a meaningful step towards the theoretical understanding of deep Q-learning variants with target networks.
Like this:
Like Loading...