Informing Artificial Intelligence Generative Techniques using Cognitive Theories of Human Creativity
The common view that our creativity is what makes us uniquely human suggests that incorporating research on human creativity into generative deep learning techniques might be a fruitful avenue for making their outputs more compelling and human-like. Using an original synthesis of Deep Dream-based convolutional neural networks and cognitive based computational art rendering systems, we show how honing theory, intrinsic motivation, and the notion of a ‘seed incident’ can be implemented computationally, and demonstrate their impact on the resulting generative art. Conversely, we discuss how explorations in deep learn-ing convolutional neural net generative systems can inform our understanding of human creativity. We conclude with ideas for further cross-fertilization between AI based computational creativity and psychology of creativity.
Conditional Graph Neural Processes: A Functional Autoencoder Approach
We introduce a novel encoder-decoder architecture to embed functional processes into latent vector spaces. This embedding can then be decoded to sample the encoded functions over any arbitrary domain. This autoencoder generalizes the recently introduced Conditional Neural Process (CNP) model of random processes. Our architecture employs the latest advances in graph neural networks to process irregularly sampled functions. Thus, we refer to our model as Conditional Graph Neural Process (CGNP). Graph neural networks can effectively exploit `local’ structures of the metric spaces over which the functions/processes are defined. The contributions of this paper are twofold: (i) a novel graph-based encoder-decoder architecture for functional and process embeddings, and (ii) a demonstration of the importance of using the structure of metric spaces for this type of representations.
Learning to Learn from Noisy Labeled Data
Despite the success of deep neural networks (DNNs) in image classification tasks, the human-level performance relies on massive training data with high-quality manual annotations, which are expensive and time-consuming to collect. There exist many inexpensive data sources on the web, but they tend to contain inaccurate labels. Training on noisy labeled datasets causes performance degradation because DNNs can easily overfit to the label noise. To overcome this problem, we propose a noise-tolerant training algorithm, where a meta-learning update is performed prior to conventional gradient update. The proposed meta-learning method simulates actual training by generating synthetic noisy labels, and train the model such that after one gradient update using each set of synthetic noisy labels, the model does not overfit to the specific noise. We conduct extensive experiments on the noisy CIFAR-10 dataset and the Clothing1M dataset. The results demonstrate the advantageous performance of the proposed method compared to several state-of-the-art baselines.
Local Probabilistic Model for Bayesian Classification: a Generalized Local Classification Model
In Bayesian classification, it is important to establish a probabilistic model for each class for likelihood estimation. Most of the previous methods modeled the probability distribution in the whole sample space. However, real-world problems are usually too complex to model in the whole sample space; some fundamental assumptions are required to simplify the global model, for example, the class conditional independence assumption for naive Bayesian classification. In this paper, with the insight that the distribution in a local sample space should be simpler than that in the whole sample space, a local probabilistic model established for a local region is expected much simpler and can relax the fundamental assumptions that may not be true in the whole sample space. Based on these advantages we propose establishing local probabilistic models for Bayesian classification. In addition, a Bayesian classifier adopting a local probabilistic model can even be viewed as a generalized local classification model; by tuning the size of the local region and the corresponding local model assumption, a fitting model can be established for a particular classification problem. The experimental results on several real-world datasets demonstrate the effectiveness of local probabilistic models for Bayesian classification.
Bezier Simplex Fitting: Describing Pareto Fronts of Simplicial Problems with Small Samples in Multi-objective Optimization
Multi-objective optimization problems require simultaneously optimizing two or more objective functions. Many studies have reported that the solution set of an M-objective optimization problem often forms an (M-1)-dimensional topological simplex (a curved line for M=2, a curved triangle for M=3, a curved tetrahedron for M=4, etc.). Since the dimensionality of the solution set increases as the number of objectives grows, an exponentially large sample size is needed to cover the solution set. To reduce the required sample size, this paper proposes a Bezier simplex model and its fitting algorithm. These techniques can exploit the simplex structure of the solution set and decompose a high-dimensional surface fitting task into a sequence of low-dimensional ones. An approximation theorem of Bezier simplices is proven. Numerical experiments with synthetic and real-world optimization problems demonstrate that the proposed method achieves an accurate approximation of high-dimensional solution sets with small samples. In practice, such an approximation will be conducted in the post-optimization process and enable a better trade-off analysis.
Improving fairness in machine learning systems: What do industry practitioners need?
The potential for machine learning (ML) systems to amplify social inequities and unfairness is receiving increasing popular and academic attention. A surge of recent work has focused on the development of algorithmic tools to assess and mitigate such unfairness. If these tools are to have a positive impact on industry practice, however, it is crucial that their design be informed by an understanding of real-world needs. Through 35 semi-structured interviews and an anonymous survey of 267 ML practitioners, we conduct the first systematic investigation of commercial product teams’ challenges and needs for support in developing fairer ML systems. We identify areas of alignment and disconnect between the challenges faced by industry practitioners and solutions proposed in the fair ML research literature. Based on these findings, we highlight directions for future ML and HCI research that will better address industry practitioners’ needs.
Dynamic Network Prediction
We present a statistical framework for generating predicted dynamic networks based on the observed evolution of social relationships in a population. The framework includes a novel and flexible procedure to sample dynamic networks given a probability distribution on evolving network properties; it permits the use of a broad class of approaches to model trends, seasonal variability, uncertainty, and changes in population composition. Current methods do not account for the variability in the observed historical networks when predicting the network structure; the proposed method provides a principled approach to incorporate uncertainty in prediction. This advance aids in the designing of network-based interventions, as development of such interventions often requires prediction of the network structure in the presence and absence of the intervention. Two simulation studies are conducted to demonstrate the usefulness of generating predicted networks when designing network-based interventions. The framework is also illustrated by investigating results of potential interventions on bill passage rates using a dynamic network that represents the sponsor/co-sponsor relationships among senators derived from bills introduced in the US Senate from 2003-2016.
ELASTIC: Improving CNNs with Instance Specific Scaling Policies
Scale variation has been a challenge from traditional to modern approaches in computer vision. Most solutions to scale issues have similar theme: a set of intuitive and manually designed policies that are generic and fixed (e.g. SIFT or feature pyramid). We argue that the scale policy should be learned from data. In this paper, we introduce ELASTIC, a simple, efficient and yet very effective approach to learn instance-specific scale policy from data. We formulate the scaling policy as a non-linear function inside the network’s structure that (a) is learned from data, (b) is instance specific, (c) does not add extra computation, and (d) can be applied on any network architecture. We applied ELASTIC to several state-of-the-art network architectures and showed consistent improvement without extra (sometimes even lower) computation on ImageNet classification, MSCOCO multi-label classification, and PASCAL VOC semantic segmentation. Our results show major improvement for images with scale challenges e.g. images with several small objects or objects with large scale variations. Our code and models will be publicly available soon.
End-to-end Joint Entity Extraction and Negation Detection for Clinical Text
Negative medical findings are prevalent in clinical reports, yet discriminating them from positive findings remains a challenging task for information extraction. Most of the existing systems treat this task as a pipeline of two separate tasks, i.e., named entity recognition (NER) and rule-based negation detection. We consider this as a multi-task problem and present a novel end-to-end neural model to jointly extract entities and negations. We extend a standard hierarchical encoder-decoder NER model and first adopt a shared encoder followed by separate decoders for the two tasks. This architecture performs considerably better than the previous rule-based and machine learning-based systems. To overcome the problem of increased parameter size especially for low-resource settings, we propose the \textit{Conditional Softmax Shared Decoder} architecture which achieves state-of-art results for NER and negation detection on the 2010 i2b2/VA challenge dataset and a proprietary de-identified clinical dataset.
IRLAS: Inverse Reinforcement Learning for Architecture Search
In this paper, we propose an inverse reinforcement learning method for architecture search (IRLAS), which trains an agent to learn to search network structures that are topologically inspired by human-designed network. Most existing architecture search approaches totally neglect the topological characteristics of architectures, which results in complicated architecture with a high inference latency. Motivated by the fact that human-designed networks are elegant in topology with a fast inference speed, we propose a mirror stimuli function inspired by biological cognition theory to extract the abstract topological knowledge of an expert human-design network (ResNeXt). To avoid raising a too strong prior over the search space, we introduce inverse reinforcement learning to train the mirror stimuli function and exploit it as a heuristic guidance for architecture search, easily generalized to different architecture search algorithms. On CIFAR-10, the best architecture searched by our proposed IRLAS achieves 2.60% error rate. For ImageNet mobile setting, our model achieves a state-of-the-art top-1 accuracy 75.28%, while being 2~4x faster than most auto-generated architectures. A fast version of this model achieves 10% faster than MobileNetV2, while maintaining a higher accuracy.
Dynamic Transfer Learning for Named Entity Recognition
State-of-the-art named entity recognition (NER) systems have been improving continuously using neural architectures over the past several years. However, many tasks including NER require large sets of annotated data to achieve such performance. In particular, we focus on NER from clinical notes, which is one of the most fundamental and critical problems for medical text analysis. Our work centers on effectively adapting these neural architectures towards low-resource settings using parameter transfer methods. We complement a standard hierarchical NER model with a general transfer learning framework consisting of parameter sharing between the source and target tasks, and showcase scores significantly above the baseline architecture. These sharing schemes require an exponential search over tied parameter sets to generate an optimal configuration. To mitigate the problem of exhaustively searching for model optimization, we propose the Dynamic Transfer Networks (DTN), a gated architecture which learns the appropriate parameter sharing scheme between source and target datasets. DTN achieves the improvements of the optimized transfer learning framework with just a single training setting, effectively removing the need for exponential search.
A second-quantised Shannon theory
Shannon’s theory of information was built on the assumption that the information carriers were classical systems. Its quantum counterpart, quantum Shannon theory, explores the new possibilities that arise when the information carriers are quantum particles. Traditionally,quantum Shannon theory has focussed on scenarios where the internal state of the particles is quantum, while their trajectory in spacetime is classical. Here we propose a second level of quantisation where both the information and its propagation in spacetime is treated quantum mechanically. The framework is illustrated with a number of examples, showcasing some of the couterintuitive phenomena taking place when information travels in a superposition of paths.
Optimal Algorithm for Profiling Dynamic Arrays with Finite Values
How can one quickly answer the most and top popular objects at any time, given a large log stream in a system of billions of users? It is equivalent to find the mode and top-frequent elements in a dynamic array corresponding to the log stream. However, most existing work either restrain the dynamic array within a sliding window, or do not take advantages of only one element can be added or removed in a log stream. Therefore, we propose a profiling algorithm, named S-Profile, which is of
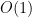
time complexity for every updating of the dynamic array, and optimal in terms of computational complexity. With the profiling results, answering the queries on the statistics of dynamic array becomes trivial and fast. With the experiments of various settings of dynamic arrays, our accurate S-Profile algorithm outperforms the well-known methods, showing at least 2X speedup to the heap based approach and 13X or larger speedup to the balanced tree based approach.
When Semi-Supervised Learning Meets Transfer Learning: Training Strategies, Models and Datasets
Semi-Supervised Learning (SSL) has been proved to be an effective way to leverage both labeled and unlabeled data at the same time. Recent semi-supervised approaches focus on deep neural networks and have achieved promising results on several benchmarks: CIFAR10, CIFAR100 and SVHN. However, most of their experiments are based on models trained from scratch instead of pre-trained models. On the other hand, transfer learning has demonstrated its value when the target domain has limited labeled data. Here comes the intuitive question: is it possible to incorporate SSL when fine-tuning a pre-trained model? We comprehensively study how SSL methods starting from pretrained models perform under varying conditions, including training strategies, architecture choice and datasets. From this study, we obtain several interesting and useful observations. While practitioners have had an intuitive understanding of these observations, we do a comprehensive emperical analysis and demonstrate that: (1) the gains from SSL techniques over a fully-supervised baseline are smaller when trained from a pre-trained model than when trained from random initialization, (2) when the domain of the source data used to train the pre-trained model differs significantly from the domain of the target task, the gains from SSL are significantly higher and (3) some SSL methods are able to advance fully-supervised baselines (like Pseudo-Label). We hope our studies can deepen the understanding of SSL research and facilitate the process of developing more effective SSL methods to utilize pre-trained models. Code is now available at github.
Mind the Independence Gap
The independence gap of a graph was introduced by Ekim et al. (2018) as a measure of how far a graph is from being well-covered. It is defined as the difference between the maximum and minimum size of a maximal independent set. We investigate the independence gap of a graph from structural and algorithmic points of view, with a focus on classes of perfect graphs. Generalizing results on well-covered graphs due to Dean and Zito (1994) and Hujdurovi\’c et al. (2018), we express the independence gap of a perfect graph in terms of clique partitions and use this characterization to develop a polynomial-time algorithm for recognizing graphs of constant independence gap in any class of perfect graphs of bounded clique number. Next, we introduce a hereditary variant of the parameter, which we call hereditary independence gap and which measures the maximum independence gap over all induced subgraphs of the graph. We show that determining whether a given graph has hereditary independence gap at most

is polynomial-time solvable if
is fixed and co-NP-complete if
is part of input. We also investigate the complexity of the independent set problem in graph classes related to independence gap, showing that the problem is NP-complete in the class of graphs of independence gap at most one and polynomial-time solvable in any class of graphs with bounded hereditary independence gap. Combined with some known results on claw-free graphs, our results imply that the independent domination problem is solvable in polynomial time.
Probing high order dependencies with information theory
Information theoretic measures (entropies, entropy rates, mutual information) are nowadays commonly used in statistical signal processing for real-world data analysis. The present work proposes the use of Auto Mutual Information (Mutual Information between subsets of the same signal) and entropy rate as powerful tools to assess refined dependencies of any order in signal temporal dynamics. Notably, it is shown how two-point Auto Mutual Information and entropy rate unveil information conveyed by higher order statistic and thus capture details of temporal dynamics that are overlooked by the (two-point) correlation function. Statistical performance of relevant estimators for Auto Mutual Information and entropy rate are studied numerically, by means of Monte Carlo simulations, as functions of sample size, dependence structures and hyper parameters that enter their definition. Further, it is shown how Auto Mutual Information permits to discriminate between several different non Gaussian processes, having exactly the same marginal distribution and covariance function. Assessing higher order statistics via multipoint Auto Mutual Information is also shown to unveil the global dependence structure fo these processes, indicating that one of the non Gaussian actually has temporal dynamics that ressembles that of a Gaussian process with same covariance while the other does not.
Penalized maximum likelihood for cure regression models
We propose a new likelihood approach for estimation, inference and variable selection for parametric cure regression models in time-to-event analysis under random right-censoring. In such a context, it often happens that some subjects under study are ‘cured’, meaning that they do not experience the event of interest. Then, sample of the censored observations is an unlabeled mixture of cured and ‘susceptible’ subjects. Using inverse probability censoring weighting (IPCW), we propose a binary outcome regression likelihood for the probability of being cured given the covariate vector. Meanwhile the conditional law of the susceptible subjects is allowed to be very general. The IPCW requires a preliminary fit for the conditional law of the censoring, for which general parametric, semi- or non-parametric approaches could be used. The incorporation of a penalty term in our approach is straightforward; we propose L1-type penalties for variable selection. Our theoretical results are derived under mild technical assumptions. Simulation experiments and real data analysis illustrate the effectiveness of the new approach.
Abstractive Text Summarization by Incorporating Reader Comments
In neural abstractive summarization field, conventional sequence-to-sequence based models often suffer from summarizing the wrong aspect of the document with respect to the main aspect. To tackle this problem, we propose the task of reader-aware abstractive summary generation, which utilizes the reader comments to help the model produce better summary about the main aspect. Unlike traditional abstractive summarization task, reader-aware summarization confronts two main challenges: (1) Comments are informal and noisy; (2) jointly modeling the news document and the reader comments is challenging. To tackle the above challenges, we design an adversarial learning model named reader-aware summary generator (RASG), which consists of four components: (1) a sequence-to-sequence based summary generator; (2) a reader attention module capturing the reader focused aspects; (3) a supervisor modeling the semantic gap between the generated summary and reader focused aspects; (4) a goal tracker producing the goal for each generation step. The supervisor and the goal tacker are used to guide the training of our framework in an adversarial manner. Extensive experiments are conducted on our large-scale real-world text summarization dataset, and the results show that RASG achieves the state-of-the-art performance in terms of both automatic metrics and human evaluations. The experimental results also demonstrate the effectiveness of each module in our framework. We release our large-scale dataset for further research.
On the Differences between L2-Boosting and the Lasso
We prove that L2-Boosting lacks a theoretical property which is central to the behaviour of l1-penalized methods such as basis pursuit and the Lasso: Whereas l1-penalized methods are guaranteed to recover the sparse parameter vector in a high-dimensional linear model under an appropriate restricted nullspace property, L2-Boosting is not guaranteed to do so. Hence, L2-Boosting behaves quite differently from l1-penalized methods when it comes to parameter recovery/estimation in high-dimensional linear models.
Gaussian Process Deep Belief Networks: A Smooth Generative Model of Shape with Uncertainty Propagation
The shape of an object is an important characteristic for many vision problems such as segmentation, detection and tracking. Being independent of appearance, it is possible to generalize to a large range of objects from only small amounts of data. However, shapes represented as silhouette images are challenging to model due to complicated likelihood functions leading to intractable posteriors. In this paper we present a generative model of shapes which provides a low dimensional latent encoding which importantly resides on a smooth manifold with respect to the silhouette images. The proposed model propagates uncertainty in a principled manner allowing it to learn from small amounts of data and providing predictions with associated uncertainty. We provide experiments that show how our proposed model provides favorable quantitative results compared with the state-of-the-art while simultaneously providing a representation that resides on a low-dimensional interpretable manifold.
Impact of Data Normalization on Deep Neural Network for Time Series Forecasting
For the last few years it has been observed that the Deep Neural Networks (DNNs) has achieved an excellent success in image classification, speech recognition. But DNNs are suffer great deal of challenges for time series forecasting because most of the time series data are nonlinear in nature and highly dynamic in behaviour. The time series forecasting has a great impact on our socio-economic environment. Hence, to deal with these challenges its need to be redefined the DNN model and keeping this in mind, data pre-processing, network architecture and network parameters are need to be consider before feeding the data into DNN models. Data normalization is the basic data pre-processing technique form which learning is to be done. The effectiveness of time series forecasting is heavily depend on the data normalization technique. In this paper, different normalization methods are used on time series data before feeding the data into the DNN model and we try to find out the impact of each normalization technique on DNN to forecast the time series. Here the Deep Recurrent Neural Network (DRNN) is used to predict the closing index of Bombay Stock Exchange (BSE) and New York Stock Exchange (NYSE) by using BSE and NYSE time series data.
Like this:
Like Loading...