Convolutional Neural Networks for Fast Approximation of Graph Edit Distance
Graph Edit Distance (GED) computation is a core operation of many widely-used graph applications, such as graph classification, graph matching, and graph similarity search. However, computing the exact GED between two graphs is NP-complete. Most current approximate algorithms are based on solving a combinatorial optimization problem, which involves complicated design and high time complexity. In this paper, we propose a novel end-to-end neural network based approach to GED approximation, aiming to alleviate the computational burden while preserving good performance. The proposed approach, named GSimCNN, turns GED computation into a learning problem. Each graph is considered as a set of nodes, represented by learnable embedding vectors. The GED computation is then considered as a two-set matching problem, where a higher matching score leads to a lower GED. A Convolutional Neural Network (CNN) based approach is proposed to tackle the set matching problem. We test our algorithm on three real graph datasets, and our model achieves significant performance enhancement against state-of-the-art approximate GED computation algorithms.
An empirical learning-based validation procedure for simulation workflow
Simulation workflow is a top-level model for the design and control of simulation process. It connects multiple simulation components with time and interaction restrictions to form a complete simulation system. Before the construction and evaluation of the component models, the validation of upper-layer simulation workflow is of the most importance in a simulation system. However, the methods especially for validating simulation workflow is very limit. Many of the existing validation techniques are domain-dependent with cumbersome questionnaire design and expert scoring. Therefore, this paper present an empirical learning-based validation procedure to implement a semi-automated evaluation for simulation workflow. First, representative features of general simulation workflow and their relations with validation indices are proposed. The calculation process of workflow credibility based on Analytic Hierarchy Process (AHP) is then introduced. In order to make full use of the historical data and implement more efficient validation, four learning algorithms, including back propagation neural network (BPNN), extreme learning machine (ELM), evolving new-neuron (eNFN) and fast incremental gaussian mixture model (FIGMN), are introduced for constructing the empirical relation between the workflow credibility and its features. A case study on a landing-process simulation workflow is established to test the feasibility of the proposed procedure. The experimental results also provide some useful overview of the state-of-the-art learning algorithms on the credibility evaluation of simulation models.
Structured and Unstructured Outlier Identification for Robust PCA: A Non iterative, Parameter free Algorithm
Robust PCA, the problem of PCA in the presence of outliers has been extensively investigated in the last few years. Here we focus on Robust PCA in the outlier model where each column of the data matrix is either an inlier or an outlier. Most of the existing methods for this model assumes either the knowledge of the dimension of the lower dimensional subspace or the fraction of outliers in the system. However in many applications knowledge of these parameters is not available. Motivated by this we propose a parameter free outlier identification method for robust PCA which a) does not require the knowledge of outlier fraction, b) does not require the knowledge of the dimension of the underlying subspace, c) is computationally simple and fast d) can handle structured and unstructured outliers. Further, analytical guarantees are derived for outlier identification and the performance of the algorithm is compared with the existing state of the art methods in both real and synthetic data for various outlier structures.
Poisoning Attacks to Graph-Based Recommender Systems
Recommender system is an important component of many web services to help users locate items that match their interests. Several studies showed that recommender systems are vulnerable to poisoning attacks, in which an attacker injects fake data to a given system such that the system makes recommendations as the attacker desires. However, these poisoning attacks are either agnostic to recommendation algorithms or optimized to recommender systems that are not graph-based. Like association-rule-based and matrix-factorization-based recommender systems, graph-based recommender system is also deployed in practice, e.g., eBay, Huawei App Store. However, how to design optimized poisoning attacks for graph-based recommender systems is still an open problem. In this work, we perform a systematic study on poisoning attacks to graph-based recommender systems. Due to limited resources and to avoid detection, we assume the number of fake users that can be injected into the system is bounded. The key challenge is how to assign rating scores to the fake users such that the target item is recommended to as many normal users as possible. To address the challenge, we formulate the poisoning attacks as an optimization problem, solving which determines the rating scores for the fake users. We also propose techniques to solve the optimization problem. We evaluate our attacks and compare them with existing attacks under white-box (recommendation algorithm and its parameters are known), gray-box (recommendation algorithm is known but its parameters are unknown), and black-box (recommendation algorithm is unknown) settings using two real-world datasets. Our results show that our attack is effective and outperforms existing attacks for graph-based recommender systems. For instance, when 1% fake users are injected, our attack can make a target item recommended to 580 times more normal users in certain scenarios.
An irregular discrete time series model to identify residuals with autocorrelation in astronomical light curves
Time series observations are ubiquitous in astronomy, and are generated to distinguish between different types of supernovae, to detect and characterize extrasolar planets and to classify variable stars. These time series are usually modeled using a parametric and/or physical model that assumes independent and homoscedastic errors, but in many cases these assumptions are not accurate and there remains a temporal dependency structure on the errors. This can occur, for example, when the proposed model cannot explain all the variability of the data or when the parameters of the model are not properly estimated. In this work we define an autoregressive model for irregular discrete-time series, based on the discrete time representation of the continuous autoregressive model of order 1. We show that the model is ergodic and stationary. We further propose a maximum likelihood estimation procedure and assess the finite sample performance by Monte Carlo simulations. We implement the model on real and simulated data from Gaussian as well as other distributions, showing that the model can flexibly adapt to different data distributions. We apply the irregular autoregressive model to the residuals of a transit of an extrasolar planet to illustrate errors that remain with temporal structure. We also apply this model to residuals of an harmonic fit of light-curves from variable stars to illustrate how the model can be used to detect incorrect parameter estimation.
Fourier-Domain Optimization for Image Processing
Image optimization problems encompass many applications such as spectral fusion, deblurring, deconvolution, dehazing, matting, reflection removal and image interpolation, among others. With current image sizes in the order of megabytes, it is extremely expensive to run conventional algorithms such as gradient descent, making them unfavorable especially when closed-form solutions can be derived and computed efficiently. This paper explains in detail the framework for solving convex image optimization and deconvolution in the Fourier domain. We begin by explaining the mathematical background and motivating why the presented setups can be transformed and solved very efficiently in the Fourier domain. We also show how to practically use these solutions, by providing the corresponding implementations. The explanations are aimed at a broad audience with minimal knowledge of convolution and image optimization. The eager reader can jump to Section 3 for a footprint of how to solve and implement a sample optimization function, and Section 5 for the more complex cases.
Layerwise Perturbation-Based Adversarial Training for Hard Drive Health Degree Prediction
With the development of cloud computing and big data, the reliability of data storage systems becomes increasingly important. Previous researchers have shown that machine learning algorithms based on SMART attributes are effective methods to predict hard drive failures. In this paper, we use SMART attributes to predict hard drive health degrees which are helpful for taking different fault tolerant actions in advance. Given the highly imbalanced SMART datasets, it is a nontrivial work to predict the health degree precisely. The proposed model would encounter overfitting and biased fitting problems if it is trained by the traditional methods. In order to resolve this problem, we propose two strategies to better utilize imbalanced data and improve performance. Firstly, we design a layerwise perturbation-based adversarial training method which can add perturbations to any layers of a neural network to improve the generalization of the network. Secondly, we extend the training method to the semi-supervised settings. Then, it is possible to utilize unlabeled data that have a potential of failure to further improve the performance of the model. Our extensive experiments on two real-world hard drive datasets demonstrate the superiority of the proposed schemes for both supervised and semi-supervised classification. The model trained by the proposed method can correctly predict the hard drive health status 5 and 15 days in advance. Finally, we verify the generality of the proposed training method in other similar anomaly detection tasks where the dataset is imbalanced. The results argue that the proposed methods are applicable to other domains.
Discovering Low-Precision Networks Close to Full-Precision Networks for Efficient Embedded Inference
To realize the promise of ubiquitous embedded deep network inference, it is essential to seek limits of energy and area efficiency. To this end, low-precision networks offer tremendous promise because both energy and area scale down quadratically with the reduction in precision. Here, for the first time, we demonstrate ResNet-18, ResNet-34, ResNet-50, ResNet-152, Inception-v3, densenet-161, and VGG-16bn networks on the ImageNet classification benchmark that, at 8-bit precision exceed the accuracy of the full-precision baseline networks after one epoch of finetuning, thereby leveraging the availability of pretrained models. We also demonstrate for the first time ResNet-18, ResNet-34, and ResNet-50 4-bit models that match the accuracy of the full-precision baseline networks. Surprisingly, the weights of the low-precision networks are very close (in cosine similarity) to the weights of the corresponding baseline networks, making training from scratch unnecessary. The number of iterations required by stochastic gradient descent to achieve a given training error is related to the square of (a) the distance of the initial solution from the final plus (b) the maximum variance of the gradient estimates. By drawing inspiration from this observation, we (a) reduce solution distance by starting with pretrained fp32 precision baseline networks and fine-tuning, and (b) combat noise introduced by quantizing weights and activations during training, by using larger batches along with matched learning rate annealing. Together, these two techniques offer a promising heuristic to discover low-precision networks, if they exist, close to fp32 precision baseline networks.
Change-Point Detection on Hierarchical Circadian Models
This paper addresses the problem of change-point detection on sequences of high-dimensional and heterogeneous observations, which also possess a periodic temporal structure. Due to the dimensionality problem, when the time between change-points is on the order of the dimension of the model parameters, drifts in the underlying distribution can be misidentified as changes. To overcome this limitation we assume that the observations lie in a lower dimensional manifold that admits a latent variable representation. In particular, we propose a hierarchical model that is computationally feasible, widely applicable to heterogeneous data and robust to missing instances. Additionally, to deal with the observations’ periodic dependencies, we employ a circadian model where the data periodicity is captured by non-stationary covariance functions. We validate the proposed technique on synthetic examples and we demonstrate its utility in the detection of changes for human behavior characterization.
Zoom: SSD-based Vector Search for Optimizing Accuracy, Latency and Memory
With the advancement of machine learning and deep learning, vector search becomes instrumental to many information retrieval systems, to search and find best matches to user queries based on their semantic similarities.These online services require the search architecture to be both effective with high accuracy and efficient with low latency and memory footprint, which existing work fails to offer. We develop, Zoom, a new vector search solution that collaboratively optimizes accuracy, latency and memory based on a multiview approach. (1) A ‘preview’ step generates a small set of good candidates, leveraging compressed vectors in memory for reduced footprint and fast lookup. (2) A ‘fullview’ step on SSDs reranks those candidates with their full-length vector, striking high accuracy. Our evaluation shows that, Zoom achieves an order of magnitude improvements on efficiency while attaining equal or higher accuracy, comparing with the state-of-the-art.
Temporal Pattern Attention for Multivariate Time Series Forecasting
Forecasting multivariate time series data, such as prediction of electricity consumption, solar power production, and polyphonic piano pieces, has numerous valuable applications. However, complex and non-linear interdependencies between time steps and series complicate the task. To obtain accurate prediction, it is crucial to model long-term dependency in time series data, which can be achieved to some good extent by recurrent neural network (RNN) with attention mechanism. Typical attention mechanism reviews the information at each previous time step and selects the relevant information to help generate the outputs, but it fails to capture the temporal patterns across multiple time steps. In this paper, we propose to use a set of filters to extract time-invariant temporal patterns, which is similar to transforming time series data into its ‘frequency domain’. Then we proposed a novel attention mechanism to select relevant time series, and use its ‘frequency domain’ information for forecasting. We applied the proposed model on several real-world tasks and achieved the state-of-the-art performance in all of them with only one exception. We also show that to some degree the learned filters play the role of bases in discrete Fourier transform.
On Markov Chain Gradient Descent
Stochastic gradient methods are the workhorse (algorithms) of large-scale optimization problems in machine learning, signal processing, and other computational sciences and engineering. This paper studies Markov chain gradient descent, a variant of stochastic gradient descent where the random samples are taken on the trajectory of a Markov chain. Existing results of this method assume convex objectives and a reversible Markov chain and thus have their limitations. We establish new non-ergodic convergence under wider step sizes, for nonconvex problems, and for non-reversible finite-state Markov chains. Nonconvexity makes our method applicable to broader problem classes. Non-reversible finite-state Markov chains, on the other hand, can mix substatially faster. To obtain these results, we introduce a new technique that varies the mixing levels of the Markov chains. The reported numerical results validate our contributions.
TGE-PS: Text-driven Graph Embedding with Pairs Sampling
In graphs with rich text information, constructing expressive graph representations requires incorporating textual information with structural information. Graph embedding models are becoming more and more popular in representing graphs, yet they are faced with two issues: sampling efficiency and text utilization. Through analyzing existing models, we find their training objectives are composed of pairwise proximities, and there are large amounts of redundant node pairs in Random Walk-based methods. Besides, inferring graph structures directly from texts (also known as zero-shot scenario) is a problem that requires higher text utilization. To solve these problems, we propose a novel Text-driven Graph Embedding with Pairs Sampling (TGE-PS) framework. TGE-PS uses Pairs Sampling (PS) to generate training samples which reduces ~99% training samples and is competitive compared to Random Walk. TGE-PS uses Text-driven Graph Embedding (TGE) which adopts word- and character-level embeddings to generate node embeddings. We evaluate TGE-PS on several real-world datasets, and experimental results demonstrate that TGE-PS produces state-of-the-art results in traditional and zero-shot link prediction tasks.
An Ontology-Based Artificial Intelligence Model for Medicine Side-Effect Prediction: Taking Traditional Chinese Medicine as An Example
In this work, an ontology-based model for AI-assisted medicine side-effect (SE) prediction is developed, where three main components, including the drug model, the treatment model, and the AI-assisted prediction model, of proposed model are presented. To validate the proposed model, an ANN structure is established and trained by two hundred and forty-two TCM prescriptions that are gathered and classified from the most famous ancient TCM book and more than one thousand SE reports, in which two ontology-based attributions, hot and cold, are simply introduced to evaluate whether the prediction will cause a SE or not. The results preliminarily reveal that it is a relationship between the ontology-based attributions and the corresponding indicator that can be learnt by AI for predicting the SE, which suggests the proposed model has a potential in AI-assisted SE prediction. However, it should be noted that, the proposed model highly depends on the sufficient clinic data, and hereby, much deeper exploration is important for enhancing the accuracy of the prediction.
Knowledge Based Machine Reading Comprehension
Machine reading comprehension (MRC) requires reasoning about both the knowledge involved in a document and knowledge about the world. However, existing datasets are typically dominated by questions that can be well solved by context matching, which fail to test this capability. To encourage the progress on knowledge-based reasoning in MRC, we present knowledge-based MRC in this paper, and build a new dataset consisting of 40,047 question-answer pairs. The annotation of this dataset is designed so that successfully answering the questions requires understanding and the knowledge involved in a document. We implement a framework consisting of both a question answering model and a question generation model, both of which take the knowledge extracted from the document as well as relevant facts from an external knowledge base such as Freebase/ProBase/Reverb/NELL. Results show that incorporating side information from external KB improves the accuracy of the baseline question answer system. We compare it with a standard MRC model BiDAF, and also provide the difficulty of the dataset and lay out remaining challenges.
Rapid Training of Very Large Ensembles of Diverse Neural Networks
Ensembles of deep neural networks with diverse architectures significantly improve generalization accuracy. However, training such ensembles requires a large amount of computational resources and time as every network in the ensemble has to be separately trained. In practice, this restricts the number of different deep neural network architectures that can be included within an ensemble. We propose a new approach to address this problem. Our approach captures the structural similarity between members of a neural network ensemble and train it only once. Subsequently, this knowledge is transferred to all members of the ensemble using function-preserving transformations. Then, these ensemble networks converge significantly faster as compared to training from scratch. We show through experiments on CIFAR-10, CIFAR-100, and SVHN data sets that our approach can train large and diverse ensembles of deep neural networks achieving comparable accuracy to existing approaches in a fraction of their training time. In particular, our approach trains an ensemble of
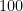
variants of deep neural networks with diverse architectures up to

faster as compared to existing approaches. This improvement in training cost grows linearly with the size of the ensemble.
Knowledge-Aware Conversational Semantic Parsing Over Web Tables
Conversational semantic parsing over tables requires knowledge acquiring and reasoning abilities, which have not been well explored by current state-of-the-art approaches. Motivated by this fact, we propose a knowledge-aware semantic parser to improve parsing performance by integrating various types of knowledge. In this paper, we consider three types of knowledge, including grammar knowledge, expert knowledge, and external resource knowledge. First, grammar knowledge empowers the model to effectively replicate previously generated logical form, which effectively handles the co-reference and ellipsis phenomena in conversation Second, based on expert knowledge, we propose a decomposable model, which is more controllable compared with traditional end-to-end models that put all the burdens of learning on trial-and-error in an end-to-end way. Third, external resource knowledge, i.e., provided by a pre-trained language model or an entity typing model, is used to improve the representation of question and table for a better semantic understanding. We conduct experiments on the SequentialQA dataset. Results show that our knowledge-aware model outperforms the state-of-the-art approaches. Incremental experimental results also prove the usefulness of various knowledge. Further analysis shows that our approach has the ability to derive the meaning representation of a context-dependent utterance by leveraging previously generated outcomes.
Prediction out-of-sample using block shrinkage estimators: model selection and predictive inference
In a linear regression model with random design, we consider a family of candidate models from which we want to select a `good’ model for prediction out-of-sample. We fit the models using block shrinkage estimators, and we focus on the challenging situation where the number of explanatory variables can be of the same order as sample size and where the number of candidate models can be much larger than sample size. We develop an estimator for the out-of-sample predictive performance, and we show that the empirically best model is asymptotically as good as the truly best model. Using the estimator corresponding to the empirically best model, we construct a prediction interval that is approximately valid and short with high probability, i.e., we show that the actual coverage probability is close to the nominal one and that the length of this prediction interval is close to the length of the shortest but infeasible prediction interval. All results hold uniformly over a large class of data-generating processes. These findings extend results of Leeb (2009), where the models are fit using least-squares estimators, and of Huber (2013), where the models are fit using shrinkage estimators without block structure.
Retrieval-Enhanced Adversarial Training for Neural Response Generation
Dialogue systems are usually built on either generation-based or retrieval-based approaches, yet they do not benefit from the advantages of different models. In this paper, we propose a Retrieval-Enhanced Adversarial Training (REAT) method for neural response generation. Distinct from existing ap- proaches, the REAT method leverages an encoder-decoder framework in terms of an adversarial training paradigm, while taking advantage of N-best response candidates from a retrieval-based system to construct the discriminator. An empirical study on a large scale public available benchmark dataset shows that the REAT method significantly outper- forms the vanilla Seq2Seq model as well as the conventional adversarial training approach.
Deep learning for time series classification: a review
Time Series Classification (TSC) is an important and challenging problem in data mining. With the increase of time series data availability, hundreds of TSC algorithms have been proposed. Among these methods, only a few have considered Deep Neural Networks (DNNs) to perform this task. This is surprising as deep learning has seen very successful applications in the last years. DNNs have indeed revolutionized the field of computer vision especially with the advent of novel deeper architectures such as Residual and Convolutional Neural Networks. Apart from images, sequential data such as text and audio can also be processed with DNNs to reach state of the art performance for document classification and speech recognition. In this article, we study the current state of the art performance of deep learning algorithms for TSC by presenting an empirical study of the most recent DNN architectures for TSC. We give an overview of the most successful deep learning applications in various time series domains under a unified taxonomy of DNNs for TSC. We also provide an open source deep learning framework to the TSC community where we implemented each of the compared approaches and evaluated them on a univariate TSC benchmark (the UCR archive) and 12 multivariate time series datasets. By training 8,730 deep learning models on 97 time series datasets, we propose the most exhaustive study of DNNs for TSC to date.
Training Deep Neural Networks with Different Datasets In-the-wild: The Emotion Recognition Paradigm
A novel procedure is presented in this paper, for training a deep convolutional and recurrent neural network, taking into account both the available training data set and some information extracted from similar networks trained with other relevant data sets. This information is included in an extended loss function used for the network training, so that the network can have an improved performance when applied to the other data sets, without forgetting the learned knowledge from the original data set. Facial expression and emotion recognition in-the-wild is the test bed application that is used to demonstrate the improved performance achieved using the proposed approach. In this framework, we provide an experimental study on categorical emotion recognition using datasets from a very recent related emotion recognition challenge.
Detection of time reversibility in time series by ordinal patterns analysis
Time irreversibility is a common signature of nonlinear processes, and a fundamental property of non-equilibrium systems driven by non-conservative forces. A time series is said to be reversible if its statistical properties are invariant regardless of the direction of time. Here we propose the Time Reversibility from Ordinal Patterns method (TiROP) to assess time-reversibility from an observed finite time series. TiROP captures the information of scalar observations in time forward, as well as its time-reversed counterpart by means of ordinal patterns. The method compares both underlying information contents by quantifying its (dis)-similarity via Jensen-Shannon divergence. The statistic is contrasted with a population of divergences coming from a set of surrogates to unveil the temporal nature and its involved time scales. We tested TiROP in different synthetic and real, linear and non linear time series, juxtaposed with results from the classical Ramsey’s time reversibility test. Our results depict a novel, fast-computation, and fully data-driven methodology to assess time-reversibility at different time scales with no further assumptions over data. This approach adds new insights about the current non-linear analysis techniques, and also could shed light on determining new physiological biomarkers of high reliability and computational efficiency.
Bayesian Semi-supervised Learning with Graph Gaussian Processes
We propose a data-efficient Gaussian process-based Bayesian approach to the semi-supervised learning problem on graphs. The proposed model shows extremely competitive performance when compared to the state-of-the-art graph neural networks on semi-supervised learning benchmark experiments, and outperforms the neural networks in active learning experiments where labels are scarce. Furthermore, the model does not require a validation data set for early stopping to control over-fitting. Our model can be viewed as an instance of empirical distribution regression weighted locally by network connectivity. We further motivate the intuitive construction of the model with a Bayesian linear model interpretation where the node features are filtered by an operator related to the graph Laplacian. The method can be easily implemented by adapting off-the-shelf scalable variational inference algorithms for Gaussian processes.
A Framework for Approval-based Budgeting Methods
We define and study a general framework for approval-based budgeting methods and compare certain methods within this framework by their axiomatic and computational properties. Furthermore, we visualize their behavior on certain Euclidean distributions and analyze them experimentally.
Artificial Intelligence for the Public Sector: Opportunities and challenges of cross-sector collaboration
Public sector organisations are increasingly interested in using data science and artificial intelligence capabilities to deliver policy and generate efficiencies in high uncertainty environments. The long-term success of data science and AI in the public sector relies on effectively embedding it into delivery solutions for policy implementation. However, governments cannot do this integration of AI into public service delivery on their own. The UK Government Industrial Strategy is clear that delivering on the AI grand challenge requires collaboration between universities and public and private sectors. This cross-sectoral collaborative approach is the norm in applied AI centres of excellence around the world. Despite their popularity, cross-sector collaborations entail serious management challenges that hinder their success. In this article we discuss the opportunities and challenges from AI for public sector. Finally, we propose a series of strategies to successfully manage these cross-sectoral collaborations.
Meta-analysis of few studies involving rare events
Meta-analyses of clinical trials targeting rare events face particular challenges when the data lack adequate numbers of events for all treatment arms. Especially when the number of studies is low, standard meta-analysis methods can lead to serious distortions because of such data sparsity. To overcome this, we suggest the use of weakly informative priors (WIP) for the treatment effect parameter of a Bayesian meta-analysis model, which may also be seen as a form of penalization. As a data model, we use a binomial-normal hierarchical model (BNHM) which does not require continuity corrections in case of zero counts in one or both arms. We suggest a normal prior for the log odds ratio with mean 0 and standard deviation 2.82, which is motivated (1) as a symmetric prior centred around unity and constraining the odds ratio to within a range from 1/250 to 250 with 95 % probability, and (2) as consistent with empirically observed effect estimates from a set of

37\,773

meta-analyses from the Cochrane Database of Systematic Reviews. In a simulation study with rare events and few studies, our BNHM with a WIP outperformed a Bayesian method without a WIP and a maximum likelihood estimator in terms of smaller bias and shorter interval estimates with similar coverage. Furthermore, the methods are illustrated by a systematic review in immunosuppression of rare safety events following paediatric transplantation. A publicly available

package,

, is developed to automate the

implementation of meta-analysis models using WIPs.
But How Does It Work in Theory? Linear SVM with Random Features
We prove that, under low noise assumptions, the support vector machine with

random features (RFSVM) can achieve the learning rate faster than
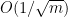
on a training set with

samples when an optimized feature map is used. Our work extends the previous fast rate analysis of random features method from least square loss to 0-1 loss. We also show that the reweighted feature selection method, which approximates the optimized feature map, helps improve the performance of RFSVM in experiments on a synthetic data set.
Benchmarking and Optimization of Gradient Boosted Decision Tree Algorithms
Gradient boosted decision trees (GBDTs) have seen widespread adoption in academia, industry and competitive data science due to their state-of-the-art performance in a wide variety of machine learning tasks. In this paper, we present an extensive empirical comparison of XGBoost, LightGBM and CatBoost, three popular GBDT algorithms, to aid the data science practitioner in the choice from the multitude of available implementations. Specifically, we evaluate their behavior on four large-scale datasets with varying shapes, sparsities and learning tasks, in order to evaluate the algorithms’ generalization performance, training times (on both CPU and GPU) and their sensitivity to hyper-parameter tuning. In our analysis, we first make use of a distributed grid-search to benchmark the algorithms on fixed configurations, and then employ a state-of-the-art algorithm for Bayesian hyper-parameter optimization to fine-tune the models.
Simplicity Creates Inequity: Implications for Fairness, Stereotypes, and Interpretability
Algorithmic predictions are increasingly used to aid, or in some cases supplant, human decision-making, and this development has placed new demands on the outputs of machine learning procedures. To facilitate human interaction, we desire that they output prediction functions that are in some fashion simple or interpretable. And because they influence consequential decisions, we also desire equitable prediction functions, ones whose allocations benefit (or at the least do not harm) disadvantaged groups. We develop a formal model to explore the relationship between simplicity and equity. Although the two concepts appear to be motivated by qualitatively distinct goals, our main result shows a fundamental inconsistency between them. Specifically, we formalize a general framework for producing simple prediction functions, and in this framework we show that every simple prediction function is strictly improvable: there exists a more complex prediction function that is both strictly more efficient and also strictly more equitable. Put another way, using a simple prediction function both reduces utility for disadvantaged groups and reduces overall welfare. Our result is not only about algorithms but about any process that produces simple models, and as such connects to the psychology of stereotypes and to an earlier economics literature on statistical discrimination.
• An Algebra of Lightweight Ontologies
• Balanced Phase Field model for Active Surfaces
• Steklov Regularization and Trajectory Methods for Univariate Global Optimization
• Unsupervised Controllable Text Formalization
• Addressing the Fundamental Tension of PCGML with Discriminative Learning
• Symmetric Function Theory at the Border of A_n and C_n
• Dependence of Inferred Climate Sensitivity on the Discrepancy Model
• Estimate the Warfarin Dose by Ensemble of Machine Learning Algorithms
• SETI Detection Strategies for Single Dish Radio Telescopes
• DNN Dataflow Choice Is Overrated
• Fertility Numbers
• Exploiting the structure effectively and efficiently in low rank matrix recovery
• Synchronization of stochastic hybrid oscillators driven by a common switching environment
• Generalized Staircase Tableaux: Symmetry and Applications
• Isolated and Ensemble Audio Preprocessing Methods for Detecting Adversarial Examples against Automatic Speech Recognition
• General Resolution Enhancement Method in Atomic Force Microscopy (AFM) Using Deep Learning
• The Visual QA Devil in the Details: The Impact of Early Fusion and Batch Norm on CLEVR
• The 21 Card Trick and its Generalization
• Mimicking complex dislocation dynamics by interaction networks
• Wideband mmWave Channel Estimation for Hybrid Massive MIMO with Low-Precision ADCs
• Solving Sinhala Language Arithmetic Problems using Neural Networks
• 5G Massive MIMO Architectures: Self-Backhauled Small Cells versus Direct Access
• Re-purposing Compact Neuronal Circuit Policies to Govern Reinforcement Learning Tasks
• DeepProteomics: Protein family classification using Shallow and Deep Networks
• Arbitrarily Varying Remote Sources
• Multivariate Brenier cumulative distribution functions and their application to non-parametric testing
• Smooth Structured Prediction Using Quantum and Classical Gibbs Samplers
• The Coin Problem in Constant Depth: Sample Complexity and Parity Gates
• Is together better? Examining scientific collaborations across multiple authors, institutions, and departments
• FIVR: Fine-grained Incident Video Retrieval
• Parallel Separable 3D Convolution for Video and Volumetric Data Understanding
• On the Structural Sensitivity of Deep Convolutional Networks to the Directions of Fourier Basis Functions
• Infectivity Enhances Prediction of Viral Cascades in Twitter
• On the Beneficial Roles of Fading and Transmit Diversity in Wireless Power Transfer with Nonlinear Energy Harvesting
• ACM RecSys 2018 Late-Breaking Results Proceedings
• Joint Embedding of Meta-Path and Meta-Graph for Heterogeneous Information Networks
• Detecting egregious responses in neural sequence-to-sequence models
• Taking a machine’s perspective: Human deciphering of adversarial images
• Cartesian Neural Network Constitutive Models for Data-driven Elasticity Imaging
• Servo Actuating System Control Using Optimal Fuzzy Approach Based on Particle Swarm Optimization
• Limitations in learning an interpreted language with recurrent models
• Rethinking the Effective Sample Size
• Magnetically Guided Capsule Endoscopy
• Thin-shell concentration for zero cells of stationary Poisson mosaics
• Simultaneous Localization and Layout Model Selection in Manhattan Worlds
• Randomized Wagering Mechanisms
• JigsawNet: Shredded Image Reassembly using Convolutional Neural Network and Loop-based Composition
• Large deviations and localization of the microcanonical ensembles given by multiple constraints
• Nonparametric Bayesian analysis of the compound Poisson prior for support boundary recovery
• Triangulating War: Network Structure and the Democratic Peace
• End-to-end Image Captioning Exploits Multimodal Distributional Similarity
• Nonconvex Variance Reduced Optimization with Arbitrary Sampling
• Joint Chance Constraints in AC Optimal Power Flow: Improving Bounds through Learning
• Intensity and Rescale Invariant Copy Move Forgery Detection Techniques
• Heated-Up Softmax Embedding
• Adversarial Propagation and Zero-Shot Cross-Lingual Transfer of Word Vector Specialization
• Leabra7: a Python package for modeling recurrent, biologically-realistic neural networks
• Phaseless Subspace Tracking
• What can linguistics and deep learning contribute to each other?
• Iterative Segmentation from Limited Training Data: Applications to Congenital Heart Disease
• Searching for Efficient Multi-Scale Architectures for Dense Image Prediction
• Deep Micro-Dictionary Learning and Coding Network
• Clinically Deployed Distributed Magnetic Resonance Imaging Reconstruction: Application to Pediatric Knee Imaging
• Optimization with Non-Differentiable Constraints with Applications to Fairness, Recall, Churn, and Other Goals
• Multimodal neural pronunciation modeling for spoken languages with logographic origin
• Cross Correlation-based Direct Positioning for Wideband Sources using Phased Arrays
• Convolutional Neural Network Approach for EEG-based Emotion Recognition using Brain Connectivity and its Spatial Information
• Hyperspectral Image Classification in the Presence of Noisy Labels
• Automatic, Personalized, and Flexible Playlist Generation using Reinforcement Learning
• Constrained optimization as ecological dynamics with applications to random quadratic programming in high dimensions
• Access to Population-Level Signaling as a Source of Inequality
• Ensemble of Convolutional Neural Networks for Automatic Grading of Diabetic Retinopathy and Macular Edema
• EEG-based video identification using graph signal modeling and graph convolutional neural network
• Trajectory Generation for Multiagent Point-To-Point Transitions via Distributed Model Predictive Control
• Concentration for Coulomb gases on compact manifolds
• Safe Exploration in Markov Decision Processes with Time-Variant Safety using Spatio-Temporal Gaussian Process
• Risk-Limiting Audits by Stratified Union-Intersection Tests of Elections (SUITE)
• A two-dimensional topological representation theorem for matroid polytopes of rank 4
• On the topological boundary of the range of super-Brownian motion-extended version
• Bayes-ToMoP: A Fast Detection and Best Response Algorithm Towards Sophisticated Opponents
• A geometric proof of an equivariant Pieri rule for flag manifolds
• Limit theorems for the minimal position of a branching random walk in random environment
• A Fast Globally Linearly Convergent Algorithm for the Computation of Wasserstein Barycenters
• On the convergence rate improvement of a splitting method for finding the resolvent of the sum of maximal monotone operators
• Free Pseudodistance Growth Rates for Spatially Coupled LDPC Codes over the BEC
• Generalizing Word Embeddings using Bag of Subwords
• Extracting Fairness Policies from Legal Documents
• Efficiency and detectability of random reactive jamming in carrier sense wireless networks
• Comparing Lifetimes of Coherent Systems with Dependent Components Operating in Random Environments
• Scalable Computation of 2D-Minkowski Sum of Arbitrary Non-Convex Domains: Modeling Flexibility in Energy Resources
• Classes of graphs with no long cycle as a vertex-minor are polynomially $χ$-bounded
• Discretely Relaxing Continuous Variables for tractable Variational Inference
• Safe Navigation with Human Instructions in Complex Scenes
• An Improved Relative Self-Attention Mechanism for Transformer with Application to Music Generation
• Joint Segmentation and Uncertainty Visualization of Retinal Layers in Optical Coherence Tomography Images using Bayesian Deep Learning
• Graph Convolutional Networks based Word Embeddings
• An Approach to Handle Big Data Warehouse Evolution
• Deep Learning Based Multi-modal Addressee Recognition in Visual Scenes with Utterances
• Cluster Variational Approximations for Structure Learning of Continuous-Time Bayesian Networks from Incomplete Data
• Data-driven repetitive control: Wind tunnel experiments under turbulent conditions
• Chinese Poetry Generation with a Working Memory Model
• Exponential-Time Approximation Algorithms for MAX-SAT: Correlations and Implications
• Chinese Poetry Generation with a Salient-Clue Mechanism
• On the number of increasing trees with label repetitions
• Neural Melody Composition from Lyrics
• Learning regression and verification networks for long-term visual tracking
• Reinforcement Learning in Topology-based Representation for Human Body Movement with Whole Arm Manipulation
• Poster Abstract: LPWA-MAC – a Low Power Wide Area network MAC protocol for cyber-physical systems
• The Dynamics of Norm Change in the Cultural Evolution of Language
• Privacy-Utility Management of Hypothesis Tests
• Deep Learning in Information Security
• Game time: statistical contests in the classroom
• Concurrent Robin Hood Hashing
• Stochastic Integral Representation for the Dynamics of Disordered Systems
• Compact Optimization Algorithms with Re-sampled Inheritance
• The Wisdom of MaSSeS: Majority, Subjectivity, and Semantic Similarity in the Evaluation of VQA
• High-dimensional Bayesian Fourier Analysis For Detecting Circadian Gene Expressions
• A Bayesian adaptive design in cancer phase I/II trials with drug combinations using escalation with overdose control (EWOC) and adaptive randomization
• Robust Beamforming for AN Aided MISO SWIPT System with Unknown Eavesdroppers and Non-linear EH Model
• Packing Sporadic Real-Time Tasks on Identical Multiprocessor Systems
• The Convergence of Iterative Delegations in Liquid Democracy
• Optimality conditions and complete description of polytopes in combinatorial optimization
• Thermal Features for Presentation Attack Detection in Hand Biometrics
• NNCP: A citation count prediction methodology based on deep neural network learning techniques
• Non-equilibrium fluctuations for the SSEP with a slow bond
• Thick points of random walk and the Gaussian free field
• A Collaborative Multi-agent Reinforcement Learning Anti-jamming Algorithm in Wireless Networks
• Binary MDS Array Codes with Optimal Repair
• A random geometric social network with Poisson point measures
• Spatio-Temporal Data Fusion for Massive Sea Surface Temperature Data from MODIS and AMSR-E Instruments
• Maximizing the Diversity of Exposure in a Social Network
• Induced path factors of regular graphs
• Finding Cheeger Cuts in Hypergraphs via Heat Equation
• Learning Deep Mixtures of Gaussian Process Experts Using Sum-Product Networks
• Label Denoising with Large Ensembles of Heterogeneous Neural Networks
• Optimal residence time control for stochastically perturbed prescription opioid epidemic models
• Inverse monoids of partial graph automorphisms
• Real-time Multiple People Tracking with Deeply Learned Candidate Selection and Person Re-Identification
• Convergence of jump processes with stochastic intensity to Brownian motion with inert drift
• Gradient-based Representational Similarity Analysis with Searchlight for Analyzing fMRI Data
• Deep learning to achieve clinically applicable segmentation of head and neck anatomy for radiotherapy
• Frame-level speaker embeddings for text-independent speaker recognition and analysis of end-to-end model
• Hate Speech Dataset from a White Supremacy Forum
• What is Schur positivity and how common is it?
• End-to-end depth from motion with stabilized monocular videos
• Unsupervised Representation Learning of Speech for Dialect Identification
• Multi range Real-time depth inference from a monocular stabilized footage using a Fully Convolutional Neural Network
• A note on deformations and mutations of fake weighted projective planes
• Learning structure-from-motionfrom motion
• Multi-task Deep Reinforcement Learning with PopArt
• Regularly Varying Random Fields
• Exploring More-Coherent Quantum Annealing
• Dynamic Edge Caching with Popularity Drifting
• Discovering Topical Interactions in Text-based Cascades using Hidden Markov Hawkes Processes
• Bounds on the expected size of the maximum agreement subtree for a given tree shape
• Automatic structure estimation of predictive models for symptom development
• The W4 method: a new multi-dimensional root-finding scheme for nonlinear systems of equations
• Hyperprior Induced Unsupervised Disentanglement of Latent Representations
• Emergence of Scenario-Appropriate Collaborative Behaviors for Teams of Robotic Bodyguards
• Emo2Vec: Learning Generalized Emotion Representation by Multi-task Training
• Combined Reinforcement Learning via Abstract Representations
• Joint Sub-bands Learning with Clique Structures for Wavelet Domain Super-Resolution
• A Simple Elementary Proof of P=NP based on the Relational Model of E. F. Codd
• Image contrast enhancement using fuzzy logic
• Characterizing the learning dynamics in extremum seeking
• Unpaired Brain MR-to-CT Synthesis using a Structure-Constrained CycleGAN
• Frequency-Aware Model Predictive Control
• Lugsail lag windows and their application to MCMC
• The Inductive Bias of Restricted f-GANs
• Using the Tsetlin Machine to Learn Human-Interpretable Rules for High-Accuracy Text Categorization with Medical Applications
• End-to-end Audiovisual Speech Activity Detection with Bimodal Recurrent Neural Models
• Coordinated Heterogeneous Distributed Perception based on Latent Space Representation
• Game-Based Video-Context Dialogue
• Constant Amortized RMR Complexity Deterministic Abortable Mutual Exclusion Algorithm for CC and DSM Models
• On the Stability and Convergence of Stochastic Gradient Descent with Momentum
• Optimization-Based Bound Tightening using a Strengthened QC-Relaxation of the Optimal Power Flow Problem
• On the uniform generation of random derangements
• Edge universality of separable covariance matrices
• Rainbow numbers for $x_1+x_2=kx_3$ in $\mathbb{Z}_n$
• Distorting an Adversary’s View in Cyber-Physical Systems
• Going Viral: Stability of Consensus-Driven Adoptive Spread
• Closed-Book Training to Improve Summarization Encoder Memory
• Distributed Chernoff Test: Optimal decision systems over networks
Like this:
Like Loading...