A Review of Different Word Embeddings for Sentiment Classification using Deep Learning
The web is loaded with textual content, and Natural Language Processing is a standout amongst the most vital fields in Machine Learning. But when data is huge simple Machine Learning algorithms are not able to handle it and that is when Deep Learning comes into play which based on Neural Networks. However since neural networks cannot process raw text, we have to change over them through some diverse strategies of word embedding. This paper demonstrates those distinctive word embedding strategies implemented on an Amazon Review Dataset, which has two sentiments to be classified: Happy and Unhappy based on numerous customer reviews. Moreover we demonstrate the distinction in accuracy with a discourse about which word embedding to apply when.
Scalable Recommender Systems through Recursive Evidence Chains
Recommender systems can be formulated as a matrix completion problem, predicting ratings from user and item parameter vectors. Optimizing these parameters by subsampling data becomes difficult as the number of users and items grows. We develop a novel approach to generate all latent variables on demand from the ratings matrix itself and a fixed pool of parameters. We estimate missing ratings using chains of evidence that link them to a small set of prototypical users and items. Our model automatically addresses the cold-start and online learning problems by combining information across both users and items. We investigate the scaling behavior of this model, and demonstrate competitive results with respect to current matrix factorization techniques in terms of accuracy and convergence speed.
Minimizing Sensitivity to Model Misspecification
We propose a framework to improve the predictions based on an economic model, and the estimates of the model parameters, when the model may be misspecified. We rely on a local asymptotic approach where the degree of misspecification is indexed by the sample size. We derive formulas to construct estimators whose mean squared error is minimax in a neighborhood of the reference model, based on simple one-step adjustments. We construct confidence intervals that contain the true parameter under both correct specification and local misspecification. We calibrate the degree of misspecification using a model detection error approach, which allows us to perform systematic sensitivity analysis in both point-identified and partially-identified settings. To illustrate our approach we study panel data models where the distribution of individual effects may be misspecified and the number of time periods is small, and we revisit the structural evaluation of a conditional cash transfer program in Mexico.
Progressive Spatial Recurrent Neural Network for Intra Prediction
Intra prediction is an important component of modern video codecs, which is able to efficiently squeeze out the spatial redundancy in video frames. With preceding pixels as the context, traditional intra prediction schemes generate linear predictions based on several predefined directions (i.e. modes) for blocks to be encoded. However, these modes are relatively simple and their predictions may fail when facing blocks with complex textures, which leads to additional bits encoding the residue. In this paper, we design a Progressive Spatial Recurrent Neural Network (PS-RNN) that learns to conduct intra prediction. Specifically, our PS-RNN consists of three spatial recurrent units and progressively generates predictions by passing information along from preceding contents to blocks to be encoded. To make our network generate predictions considering both distortion and bit-rate, we propose to use Sum of Absolute Transformed Difference (SATD) as the loss function to train PS-RNN since SATD is able to measure rate-distortion cost of encoding a residue block. Moreover, our method supports variable-block-size for intra prediction, which is more practical in real coding conditions. The proposed intra prediction scheme achieves on average 2.4% bit-rate reduction on variable-block-size settings under the same reconstruction quality compared with HEVC.
Distributed Self-Paced Learning in Alternating Direction Method of Multipliers
Self-paced learning (SPL) mimics the cognitive process of humans, who generally learn from easy samples to hard ones. One key issue in SPL is the training process required for each instance weight depends on the other samples and thus cannot easily be run in a distributed manner in a large-scale dataset. In this paper, we reformulate the self-paced learning problem into a distributed setting and propose a novel Distributed Self-Paced Learning method (DSPL) to handle large-scale datasets. Specifically, both the model and instance weights can be optimized in parallel for each batch based on a consensus alternating direction method of multipliers. We also prove the convergence of our algorithm under mild conditions. Extensive experiments on both synthetic and real datasets demonstrate that our approach is superior to those of existing methods.
Towards more Reliable Transfer Learning
Multi-source transfer learning has been proven effective when within-target labeled data is scarce. Previous work focuses primarily on exploiting domain similarities and assumes that source domains are richly or at least comparably labeled. While this strong assumption is never true in practice, this paper relaxes it and addresses challenges related to sources with diverse labeling volume and diverse reliability. The first challenge is combining domain similarity and source reliability by proposing a new transfer learning method that utilizes both source-target similarities and inter-source relationships. The second challenge involves pool-based active learning where the oracle is only available in source domains, resulting in an integrated active transfer learning framework that incorporates distribution matching and uncertainty sampling. Extensive experiments on synthetic and two real-world datasets clearly demonstrate the superiority of our proposed methods over several baselines including state-of-the-art transfer learning methods.
Scalable Formal Concept Analysis algorithm for large datasets using Spark
In the process of knowledge discovery and representation in large datasets using formal concept analysis, complexity plays a major role in identifying all the formal concepts and constructing the concept lattice(digraph of the concepts). For identifying the formal concepts and constructing the digraph from the identified concepts in very large datasets, various distributed algorithms are available in the literature. However, the existing distributed algorithms are not very well suitable for concept generation because it is an iterative process. The existing algorithms are implemented using distributed frameworks like MapReduce and Open MP, these frameworks are not appropriate for iterative applications. Hence, in this paper we proposed efficient distributed algorithms for both formal concept generation and concept lattice digraph construction in large formal contexts using Apache Spark. Various performance metrics are considered for the evaluation of the proposed work, the results of the evaluation proves that the proposed algorithms are efficient for concept generation and lattice graph construction in comparison with the existing algorithms.
Temporal graph-based clustering for historical record linkage
Research in the social sciences is increasingly based on large and complex data collections, where individual data sets from different domains are linked and integrated to allow advanced analytics. A popular type of data used in such a context are historical censuses, as well as birth, death, and marriage certificates. Individually, such data sets however limit the types of studies that can be conducted. Specifically, it is impossible to track individuals, families, or households over time. Once such data sets are linked and family trees spanning several decades are available it is possible to, for example, investigate how education, health, mobility, employment, and social status influence each other and the lives of people over two or even more generations. A major challenge is however the accurate linkage of historical data sets which is due to data quality and commonly also the lack of ground truth data being available. Unsupervised techniques need to be employed, which can be based on similarity graphs generated by comparing individual records. In this paper we present initial results from clustering birth records from Scotland where we aim to identify all births of the same mother and group siblings into clusters. We extend an existing clustering technique for record linkage by incorporating temporal constraints that must hold between births by the same mother, and propose a novel greedy temporal clustering technique. Experimental results show improvements over non-temporary approaches, however further work is needed to obtain links of high quality.
TextRank Based Search Term Identification for Software Change Tasks
During maintenance, software developers deal with a number of software change requests. Each of those requests is generally written using natural language texts, and it involves one or more domain related concepts. A developer needs to map those concepts to exact source code locations within the project in order to implement the requested change. This mapping generally starts with a search within the project that requires one or more suitable search terms. Studies suggest that the developers often perform poorly in coming up with good search terms for a change task. In this paper, we propose and evaluate a novel TextRank-based technique that automatically identifies and suggests search terms for a software change task by analyzing its task description. Experiments with 349 change tasks from two subject systems and comparison with one of the latest and closely related state-of-the-art approaches show that our technique is highly promising in terms of suggestion accuracy, mean average precision and recall.
Variance Reduction for Reinforcement Learning in Input-Driven Environments
We consider reinforcement learning in input-driven environments, where an exogenous, stochastic input process affects the dynamics of the system. Input processes arise in many applications, including queuing systems, robotics control with disturbances, and object tracking. Since the state dynamics and rewards depend on the input process, the state alone provides limited information for the expected future returns. Therefore, policy gradient methods with standard state-dependent baselines suffer high variance during training. We derive a bias-free, input-dependent baseline to reduce this variance, and analytically show its benefits over state-dependent baselines. We then propose a meta-learning approach to overcome the complexity of learning a baseline that depends on a long sequence of inputs. Our experimental results show that across environments from queuing systems, computer networks, and MuJoCo robotic locomotion, input-dependent baselines consistently improve training stability and result in better eventual policies.
Recommending Relevant Sections from a Webpage about Programming Errors and Exceptions
Programming errors or exceptions are inherent in software development and maintenance, and given today’s Internet era, software developers often look at web for finding working solutions. They make use of a search engine for retrieving relevant pages, and then look for the appropriate solutions by manually going through the pages one by one. However, both the manual checking of a page’s content against a given exception (and its context) and then working an appropriate solution out are non-trivial tasks. They are even more complex and time-consuming with the bulk of irrelevant (i.e., off-topic) and noisy (e.g., advertisements) content in the web page. In this paper, we propose an IDE-based and context-aware page content recommendation technique that locates and recommends relevant sections from a given web page by exploiting the technical details, in particular, the context of an encountered exception in the IDE. An evaluation with 250 web pages related to 80 programming exceptions, comparison with the only available closely related technique, and a case study involving comparison with VSM and LSA techniques show that the proposed technique is highly promising in terms of precision, recall and F1-measure.
Sliced Recurrent Neural Networks
Recurrent neural networks have achieved great success in many NLP tasks. However, they have difficulty in parallelization because of the recurrent structure, so it takes much time to train RNNs. In this paper, we introduce sliced recurrent neural networks (SRNNs), which could be parallelized by slicing the sequences into many subsequences. SRNNs have the ability to obtain high-level information through multiple layers with few extra parameters. We prove that the standard RNN is a special case of the SRNN when we use linear activation functions. Without changing the recurrent units, SRNNs are 136 times as fast as standard RNNs and could be even faster when we train longer sequences. Experiments on six largescale sentiment analysis datasets show that SRNNs achieve better performance than standard RNNs.
Sequential Copying Networks
Copying mechanism shows effectiveness in sequence-to-sequence based neural network models for text generation tasks, such as abstractive sentence summarization and question generation. However, existing works on modeling copying or pointing mechanism only considers single word copying from the source sentences. In this paper, we propose a novel copying framework, named Sequential Copying Networks (SeqCopyNet), which not only learns to copy single words, but also copies sequences from the input sentence. It leverages the pointer networks to explicitly select a sub-span from the source side to target side, and integrates this sequential copying mechanism to the generation process in the encoder-decoder paradigm. Experiments on abstractive sentence summarization and question generation tasks show that the proposed SeqCopyNet can copy meaningful spans and outperforms the baseline models.
JUMPER: Learning When to Make Classification Decisions in Reading
In early years, text classification is typically accomplished by feature-based machine learning models; recently, deep neural networks, as a powerful learning machine, make it possible to work with raw input as the text stands. However, exiting end-to-end neural networks lack explicit interpretation of the prediction. In this paper, we propose a novel framework, JUMPER, inspired by the cognitive process of text reading, that models text classification as a sequential decision process. Basically, JUMPER is a neural system that scans a piece of text sequentially and makes classification decisions at the time it wishes. Both the classification result and when to make the classification are part of the decision process, which is controlled by a policy network and trained with reinforcement learning. Experimental results show that a properly trained JUMPER has the following properties: (1) It can make decisions whenever the evidence is enough, therefore reducing total text reading by 30-40% and often finding the key rationale of prediction. (2) It achieves classification accuracy better than or comparable to state-of-the-art models in several benchmark and industrial datasets.
Causal Deep Information Bottleneck
Estimating causal effects in the presence of latent confounding is a frequently occurring problem in several tasks. In real world applications such as medicine, accounting for the effects of latent confounding is even more challenging as a result of high-dimensional and noisy data. In this work, we propose estimating the causal effect from the perspective of the information bottleneck principle by explicitly identifying a low-dimensional representation of latent confounding. In doing so, we prove theoretically that the proposed model can be used to recover the average causal effect. Experiments on both synthetic data and existing causal benchmarks illustrate that our method achieves state-of-the-art performance in terms of prediction accuracy and sample efficiency, without sacrificing interpretability.
Data-driven causal path discovery without prior knowledge – a benchmark study
Causal discovery broadens the inference possibilities, as correlation does not inform about the relationship direction. The common approaches were proposed for cases in which prior knowledge is desired when the impact of a treatment/intervention variable is discovered or to analyze time-related dependencies. In some practical applications, more universal techniques are needed and have already been presented. Therefore, the aim of the study was to assess the accuracies in determining causal paths in a dataset without taking into account the ground truth and the contextual information. This benchmark was performed on the database with cause-effect pairs, using a framework consisting of generalized correlations (GC), kernel regression gradients and absolute residuals criteria (AR), along with causal additive modeling (CAM). The best overall accuracy, 80%, was achieved for the (majority voting) combination of GC, AR, and CAM. We also used proposed bootstrap simulation to establish the probability of correct causal path determination and for which pairs the inference appears indeterminate. In this way, the mean accuracy was improved to 83% for the selected subset of pairs. The described approach can be used for preliminary dependence assessment, as an initial step for commonly used causality assessment frameworks or for comparison with prior assumptions.
A Variational Time Series Feature Extractor for Action Prediction
We propose a Variational Time Series Feature Extractor (VTSFE), inspired by the VAE-DMP model of Chen et al., to be used for action recognition and prediction. Our method is based on variational autoencoders. It improves VAE-DMP in that it has a better noise inference model, a simpler transition model constraining the acceleration in the trajectories of the latent space, and a tighter lower bound for the variational inference. We apply the method for classification and prediction of whole-body movements on a dataset with 7 tasks and 10 demonstrations per task, recorded with a wearable motion capture suit. The comparison with VAE and VAE-DMP suggests the better performance of our method for feature extraction. An open-source software implementation of each method with TensorFlow is also provided. In addition, a more detailed version of this work can be found in the indicated code repository. Although it was meant to, the VTSFE hasn’t been tested for action prediction, due to a lack of time in the context of Maxime Chaveroche’s Master thesis at INRIA.
Near Optimal Exploration-Exploitation in Non-Communicating Markov Decision Processes
While designing the state space of an MDP, it is common to include states that are transient or not reachable by any policy (e.g., in mountain car, the product space of speed and position contains configurations that are not physically reachable). This leads to defining weakly-communicating or multi-chain MDPs. In this paper, we introduce \tucrl, the first algorithm able to perform efficient exploration-exploitation in any finite Markov Decision Process (MDP) without requiring any form of prior knowledge. In particular, for any MDP with
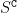
communicating states,

actions and
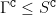
possible communicating next states, we derive a
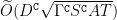
regret bound, where
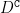
is the diameter (i.e., the longest shortest path) of the communicating part of the MDP. This is in contrast with optimistic algorithms (e.g., UCRL, Optimistic PSRL) that suffer linear regret in weakly-communicating MDPs, as well as posterior sampling or regularised algorithms (e.g., REGAL), which require prior knowledge on the bias span of the optimal policy to bias the exploration to achieve sub-linear regret. We also prove that in weakly-communicating MDPs, no algorithm can ever achieve a logarithmic growth of the regret without first suffering a linear regret for a number of steps that is exponential in the parameters of the MDP. Finally, we report numerical simulations supporting our theoretical findings and showing how TUCRL overcomes the limitations of the state-of-the-art.
A Structured Prediction Approach for Label Ranking
We propose to solve a label ranking problem as a structured output regression task. We adopt a least square surrogate loss approach that solves a supervised learning problem in two steps: the regression step in a well-chosen feature space and the pre-image step. We use specific feature maps/embeddings for ranking data, which convert any ranking/permutation into a vector representation. These embeddings are all well-tailored for our approach, either by resulting in consistent estimators, or by solving trivially the pre-image problem which is often the bottleneck in structured prediction. We also propose their natural extension to the case of partial rankings and prove their efficiency on real-world datasets.
Natural Language Processing for Information Extraction
With rise of digital age, there is an explosion of information in the form of news, articles, social media, and so on. Much of this data lies in unstructured form and manually managing and effectively making use of it is tedious, boring and labor intensive. This explosion of information and need for more sophisticated and efficient information handling tools gives rise to Information Extraction(IE) and Information Retrieval(IR) technology. Information Extraction systems takes natural language text as input and produces structured information specified by certain criteria, that is relevant to a particular application. Various sub-tasks of IE such as Named Entity Recognition, Coreference Resolution, Named Entity Linking, Relation Extraction, Knowledge Base reasoning forms the building blocks of various high end Natural Language Processing (NLP) tasks such as Machine Translation, Question-Answering System, Natural Language Understanding, Text Summarization and Digital Assistants like Siri, Cortana and Google Now. This paper introduces Information Extraction technology, its various sub-tasks, highlights state-of-the-art research in various IE subtasks, current challenges and future research directions.
Quality Diversity Through Surprise
Quality diversity is a recent evolutionary computation paradigm which maintains an appropriate balance between divergence and convergence and has achieved promising results in complex problems. There is, however, limited exploration on how different paradigms of divergent search may impact the solutions found by quality diversity algorithms. Inspired by the notion of \emph{surprise} as an effective driver of divergent search and its orthogonal nature to novelty this paper investigates the impact of the former to quality diversity performance. For that purpose we introduce three new quality diversity algorithms which use surprise as a diversity measure, either on its own or combined with novelty, and compare their performance against novelty search with local competition, the state of the art quality diversity algorithm. The algorithms are tested in a robot maze navigation task, in a challenging set of 60 deceptive mazes. Our findings suggest that allowing surprise and novelty to operate synergistically for divergence and in combination with local competition leads to quality diversity algorithms of significantly higher efficiency, speed and robustness.
A Fully Convolutional Two-Stream Fusion Network for Interactive Image Segmentation
In this paper, we propose a novel fully convolutional two-stream fusion network (FCTSFN) for interactive image segmentation. The proposed network includes two sub-networks: a two-stream late fusion network (TSLFN) that predicts the foreground at a reduced resolution, and a multi-scale refining network (MSRN) that refines the foreground at full resolution. The TSLFN includes two distinct deep streams followed by a fusion network. The intuition is that, since user interactions are more direction information on foreground/background than the image itself, the two-stream structure of the TSLFN reduces the number of layers between the pure user interaction features and the network output, allowing the user interactions to have a more direct impact on the segmentation result. The MSRN fuses the features from different layers of TSLFN with different scales, in order to seek the local to global information on the foreground to refine the segmentation result at full resolution. We conduct comprehensive experiments on four benchmark datasets. The results show that the proposed network achieves competitive performance compared to current state-of-the-art interactive image segmentation methods.
• Multi-atomic Annealing Heuristic for Static Dial-a-ride Problem
• CAIL2018: A Large-Scale Legal Dataset for Judgment Prediction
• Comments on Cooperative Density Estimation in Random Wireless Ad Hoc Networks
• TextTopicNet – Self-Supervised Learning of Visual Features Through Embedding Images on Semantic Text Spaces
• Large-Scale Multiple Hypothesis Testing with the Normal-Beta Prime Prior
• On the nonlocal stabilization by starting control of the normal equation generated from Helmholtz system
• Improved bounds on the extremal function of hypergraphs
• Extracting Actionable Knowledge from Domestic Violence Discourses on Social Media
• A Semi-parametric Realized Joint Value-at-Risk and Expected Shortfall Regression Framework
• Learning a Representation Map for Robot Navigation using Deep Variational Autoencoder
• Scalable Gaussian Processes with Grid-Structured Eigenfunctions (GP-GRIEF)
• Adaptive Path-Integral Approach to Representation Learning and Planning for Dynamical Systems
• 3D Human Action Recognition with Siamese-LSTM Based Deep Metric Learning
• Face Recognition Using Map Discriminant on YCbCr Color Space
• Detecting Visual Relationships Using Box Attention
• Distances between zeroes and critical points for random polynomials with i.i.d. zeroes
• Spatiotemporal KSVD Dictionary Learning for Online Multi-target Tracking
• Large gaps of CUE and GUE
• On Ergodic Capacity and Optimal Number of Tiers in UAV-Assisted Communication Systems
• Automatic deep learning-based normalization of breast dynamic contrast-enhanced magnetic resonance images
• Betti numbers of toric ideals of graphs: A case study
• Gridbot: An autonomous robot controlled by a Spiking Neural Network mimicking the brain’s navigational system
• A Geometric Interpretation of the Intertwining Number
• Feature Assisted bi-directional LSTM Model for Protein-Protein Interaction Identification from Biomedical Texts
• Adaptive Paired-Comparison Method for Subjective Video Quality Assessment on Mobile Devices
• A Stochastic Levenberg-Marquardt Method Using Random Models with Application to Data Assimilation
• Encoding Motion Primitives for Autonomous Vehicles using Virtual Velocity Constraints and Neural Network Scheduling
• Explainable Learning: Implicit Generative Modelling during Training for Adversarial Robustness
• Functional Object-Oriented Network: Construction & Expansion
• Strong Numerical Methods of Order 3.0 for Ito Stochastic Differential Equations, Based on the Unified Stochastic Taylor Expansions and Multiple Fourier-Legendre Series
• An MCMC Approach to Empirical Bayes Inference and Bayesian Sensitivity Analysis via Empirical Processes
• A Survey of Knowledge Representation and Retrieval for Learning in Service Robotics
• An algorithm for enumerating difference sets
• The Radius of Metric Subregularity
• Natural Language Processing for Music Knowledge Discovery
• Monte Carlo Methods for Insurance Risk Computation
• The price of debiasing automatic metrics in natural language evaluation
• Empirical distributions of the robustified $t$-test statistics
• The Data Science of Hollywood: Using Emotional Arcs of Movies to Drive Business Model Innovation in Entertainment Industries
• Cooperative Adaptive Cruise Control for a Platoon of Connected and Autonomous Vehicles Considering Dynamic Information Flow Topology
• Cheeger inequalities for graph limits
• Addressing the Barriers to Interlingual Rule-based Machine Translation with a Concept Specification and Abstraction Semantic Representation
• Beating the curse of dimensionality in options pricing and optimal stopping
• Bayesian State Space Modeling of Physical Processes in Industrial Hygiene
• Coastline Kriging: A Bayesian Approach
• U-SLADS: Unsupervised Learning Approach for Dynamic Dendrite Sampling
• Expanding polynomials: A generalization of the Elekes-Rónyai theorem to $d$ variables
• A Flexible Joint Longitudinal-Survival Model for Analysis of End-Stage Renal Disease Data
• Mask TextSpotter: An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes
• A Bayesian Framework for Non-Collapsible Models
• Isomorphism of the cubical and categorical cohomology groups of a higher-rank graph
• Adversarial Learning for Fine-grained Image Search
• State-Varying Factor Models of Large Dimensions
• Face-Cap: Image Captioning using Facial Expression Analysis
• Minutia Texture Cylinder Codes for fingerprint matching
• The Ahlswede–Khachatrian Theorem on cross $t$-intersecting families
• Faster Data-access in Large-scale Systems: Network-scale Latency Analysis under General Service-time Distributions
• Singing Style Transfer Using Cycle-Consistent Boundary Equilibrium Generative Adversarial Networks
• Towards a Context-Aware IDE-Based Meta Search Engine for Recommendation about Programming Errors and Exceptions
• Dynamic Multimodal Instance Segmentation guided by natural language queries
• Parallel Convolutional Networks for Image Recognition via a Discriminator
• Multi-target Joint Detection, Tracking and Classification Based on Generalized Bayesian Risk using Radar and ESM sensors
• Outperforming Good-Turing: Preliminary Report
• Interleaved lattice-based maximin distance designs
• Differentially Private Online Submodular Optimization
• Combining SLAM with muti-spectral photometric stereo for real-time dense 3D reconstruction
• Combinatorial Bandits for Incentivizing Agents with Dynamic Preferences
• On the Equilibrium of Query Reformulation and Document Retrieval
• Risk Forms: Representation, Disintegration, and Application to Partially Observable Two-Stage Systems
• A survey on policy search algorithms for learning robot controllers in a handful of trials
• Neural Document Summarization by Jointly Learning to Score and Select Sentences
• A moment approach for entropy solutions to nonlinear hyperbolic PDEs
• Vertex partition of hypergraphs and maximum degenerate subhypergraphs
• Exponential Convergence for Functional SDEs with Hölder Continuous Drift
• Ramsey goodness of cycles
• The maximal flow from a compact convex subset to infinity in first passage percolation on $\mathbb{Z}^d$
• Approximately Reachable Directions for Piecewise Linear Switched Systems
• Memory Augmented Policy Optimization for Program Synthesis with Generalization
• Optimal Sensor Data Fusion Architecture for Object Detection in Adverse Weather Conditions
• Sum-Product Networks for Sequence Labeling
• Deviations for the Capacity of the Range of a Random Walk
• Managing approximation errors in quantum programs
• Oracle-free Detection of Translation Issue for Neural Machine Translation
• The stepping stone model in a random environment and the effect of local heterogneities on isolation by distance patterns
• Autoregressive Wild Bootstrap Inference for Nonparametric Trends
• Schoenberg coefficients and curvature at the origin of continuous isotropic positive definite kernels on spheres
• On minimal edge version of doubly resolving sets of a graph
• The combinatorial invariance conjecture for parabolic Kazhdan-Lusztig polynomials of lower intervals
• Deep Back Projection for Sparse-View CT Reconstruction
• End-to-End Race Driving with Deep Reinforcement Learning
• Rigidity of the Bonnet-Myers inequality for graphs with respect to Ollivier Ricci curvature
• Generative models on accelerated neuromorphic hardware
• The isotropic constant of random polytopes with vertices on convex surfaces
• Spin-polarized localization in a magnetized chain
• Two-species active transport along cylindrical biofilaments is limited by emergent topological hindrance
• A multidisciplinary task-based perspective for evaluating the impact of AI autonomy and generality on the future of work
• Reversed Active Learning based Atrous DenseNet for Pathological Image Classification
• Beamforming in Millimeter Wave Systems: Prototyping and Measurement Results
• The mincut graph of a graph
• Freeness of Hyperplane Arrangements between Boolean Arrangements and Weyl Arrangements of Type $ B_{\ell} $
• Deep Sequential Segmentation of Organs in Volumetric Medical Scans
• Multi-Task Learning with Incomplete Data for Healthcare
• Tangent Convolutions for Dense Prediction in 3D
• Multi-modal Non-line-of-sight Passive Imaging
• Random band matrices in the delocalized phase, III: Averaging fluctuations
• A Bayesian Approach to Forced Oscillation Source Location Given Uncertain Generator Parameters
• Evolution of natural patterns from random fields
• Stein’s method and Papangelou intensity for Poisson or Cox process approximation
• $P$-partitions and $p$-positivity
• Optimal sustainable harvesting of populations in random environments
• Development of a sensory-neural network for medical diagnosing
• Design of Low-Complexity Convolutional Codes over GF(q)
• Deployment Strategies of Multiple Aerial BSs for User Coverage and Power Efficiency Maximization
• Enabling Covariance-Based Feedback in Massive MIMO: A User Classification Approach
• Deep Multiple Instance Feature Learning via Variational Autoencoder
• Dynamic Load Balancing for Compressible Multiphase Turbulence
• Joint Channel-Estimation/Decoding with Frequency-Selective Channels and Few-Bit ADCs
• Creep dynamics of athermal amorphous materials: a mesoscopic approach
• Overview and Comparison of Gate Level Quantum Software Platforms
• EPIC: Welfare Maximization under Economically Postulated Independent Cascade Model
• From Rank Estimation to Rank Approximation: Rank Residual Constraint for Image Denoising
• Tensor ring decomposition
Like this:
Like Loading...