Classification with Fairness Constraints: A Meta-Algorithm with Provable Guarantees
Developing classification algorithms that are fair with respect to sensitive attributes of the data has become an important problem due to the growing deployment of classification algorithms in various social contexts. Several recent works have focused on fairness with respect to a specific metric, modeled the corresponding fair classification problem as a constrained optimization problem, and developed tailored algorithms to solve them. Despite this, there still remain important metrics for which we do not have fair classifiers and many of the aforementioned algorithms do not come with theoretical guarantees; perhaps because the resulting optimization problem is non-convex. The main contribution of this paper is a new meta-algorithm for classification that takes as input a large class of fairness constraints, with respect to multiple non-disjoint sensitive attributes, and which comes with provable guarantees. This is achieved by first developing a meta-algorithm for a large family of classification problems with convex constraints, and then showing that classification problems with general types of fairness constraints can be reduced to those in this family. We present empirical results that show that our algorithm can achieve near-perfect fairness with respect to various fairness metrics, and that the loss in accuracy due to the imposed fairness constraints is often small. Overall, this work unifies several prior works on fair classification, presents a practical algorithm with theoretical guarantees, and can handle fairness metrics that were previously not possible.
Customized Local Differential Privacy for Multi-Agent Distributed Optimization
Real-time data-driven optimization and control problems over networks may require sensitive information of participating users to calculate solutions and decision variables, such as in traffic or energy systems. Adversaries with access to coordination signals may potentially decode information on individual users and put user privacy at risk. We develop \emph{local differential privacy}, which is a strong notion that guarantees user privacy regardless of any auxiliary information an adversary may have, for a larger family of convex distributed optimization problems. The mechanism allows agent to customize their own privacy level based on local needs and parameter sensitivities. We propose a general sampling based approach for determining sensitivity and derive analytical bounds for specific quadratic problems. We analyze inherent trade-offs between privacy and suboptimality and propose allocation schemes to divide the maximum allowable noise, a \emph{privacy budget}, among all participating agents. Our algorithm is implemented to enable privacy in distributed optimal power flow for electric grids.
Seeing Neural Networks Through a Box of Toys: The Toybox Dataset of Visual Object Transformations
Deep convolutional neural networks (CNNs) have enjoyed tremendous success in computer vision in the past several years, particularly for visual object recognition.However, how CNNs work remains poorly understood, and the training of deep CNNs is still considered more art than science. To better characterize deep CNNs and the training process, we introduce a new video dataset called Toybox. Images in Toybox come from first-person, wearable camera recordings of common household objects and toys being manually manipulated to undergo structured transformations like rotations and translations. We also present results from initial experiments using deep CNNs that begin to examine how different distributions of training data can affect visual object recognition performance, and how visual object concepts are represented within a trained network.
VIoLET: A Large-scale Virtual Environment for Internet of Things
IoT deployments have been growing manifold, encompassing sensors, networks, edge, fog and cloud resources. Despite the intense interest from researchers and practitioners, most do not have access to large-scale IoT testbeds for validation. Simulation environments that allow analytical modeling are a poor substitute for evaluating software platforms or application workloads in realistic computing environments. Here, we propose VIoLET, a virtual environment for defining and launching large-scale IoT deployments within cloud VMs. It offers a declarative model to specify container-based compute resources that match the performance of the native edge, fog and cloud devices using Docker. These can be inter-connected by complex topologies on which private/public networks, and bandwidth and latency rules are enforced. Users can configure synthetic sensors for data generation on these devices as well. We validate VIoLET for deployments with > 400 devices and > 1500 device-cores, and show that the virtual IoT environment closely matches the expected compute and network performance at modest costs. This fills an important gap between IoT simulators and real deployments.
Accelerating delayed-acceptance Markov chain Monte Carlo algorithms
Delayed-acceptance Markov chain Monte Carlo (DA-MCMC) samples from a probability distribution, via a two-stages version of the Metropolis-Hastings algorithm, by combining the target distribution with a ‘surrogate’ (i.e. an approximate and computationally cheaper version) of said distribution. DA-MCMC accelerates MCMC sampling in complex applications, while still targeting the exact distribution. We design a computationally faster DA-MCMC algorithm, which samples from an approximation of the target distribution. As a case study, we also introduce a novel stochastic differential equation model for protein folding data. We consider parameters inference in a Bayesian setting where a surrogate likelihood function is introduced in the delayed-acceptance scheme. In our applications we employ a Gaussian process as a surrogate likelihood, but other options are possible. In our accelerated algorithm the calculations in the ‘second stage’ of the delayed-acceptance scheme are reordered in such as way that we can obtain a significant speed-up in the MCMC sampling, when the evaluation of the likelihood function is computationally intensive. We consider both simulations studies, and the analysis of real protein folding data. Simulation studies for the stochastic Ricker model and the novel stochastic differential equation model for protein-folding data, show that the speed-up is highly problem dependent. The more involved the computations of the likelihood function are, the higher the acceleration becomes when using our algorithm. Inference results for the standard delayed-acceptance algorithm and our approximated version are similar, indicating that our approximated algorithm can return reliable Bayesian inference.
Bayesian Convolutional Neural Networks
We propose a Bayesian convolutional neural network built upon Bayes by Backprop and elaborate how this known method can serve as the fundamental construct of our novel reliable variational inference method for convolutional neural networks. First, we show how Bayes by Backprop can be applied to convolutional layers where weights in filters have probability distributions instead of point-estimates; and second, how our proposed framework leads with various network architectures to performances comparable to convolutional neural networks with point-estimates weights. This work represents the expansion of the group of Bayesian neural networks, which consist now of feedforward, recurrent, and convolutional ones.
Query K-means Clustering and the Double Dixie Cup Problem
We consider the problem of approximate

-means clustering with outliers and side information provided by same-cluster queries and possibly noisy answers. Our solution shows that, under some mild assumptions on the smallest cluster size, one can obtain an
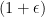
-approximation for the optimal potential with probability at least
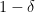
, where

and
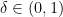
, using an expected number of

noiseless same-cluster queries and comparison-based clustering of complexity
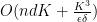
, here,

denotes the number of points and

the dimension of space. Compared to a handful of other known approaches that perform importance sampling to account for small cluster sizes, the proposed query technique reduces the number of queries by a factor of roughly

, at the cost of possibly missing very small clusters. We extend this settings to the case where some queries to the oracle produce erroneous information, and where certain points, termed outliers, do not belong to any clusters. Our proof techniques differ from previous methods used for
-means clustering analysis, as they rely on estimating the sizes of the clusters and the number of points needed for accurate centroid estimation and subsequent nontrivial generalizations of the double Dixie cup problem. We illustrate the performance of the proposed algorithm both on synthetic and real datasets, including MNIST and CIFAR

.
Robust Bayesian Model Selection for Variable Clustering with the Gaussian Graphical Model
Variable clustering is important for explanatory analysis. However, only few dedicated methods for variable clustering with the Gaussian graphical model have been proposed. Even more severe, small insignificant partial correlations due to noise can dramatically change the clustering result when evaluating for example with the Bayesian Information Criteria (BIC). In this work, we try to address this issue by proposing a Bayesian model that accounts for negligible small, but not necessarily zero, partial correlations. Based on our model, we propose to evaluate a variable clustering result using the marginal likelihood. To address the intractable calculation of the marginal likelihood, we propose two solutions: one based on a variational approximation, and another based on MCMC. Experiments on simulated data shows that the proposed method is similarly accurate as BIC in the no noise setting, but considerably more accurate when there are noisy partial correlations. Furthermore, on real data the proposed method provides clustering results that are intuitively sensible, which is not always the case when using BIC or its extensions.
Efficient Handling of SPARQL OPTIONAL for OBDA (Extended Version)
OPTIONAL is a key feature in SPARQL for dealing with missing information. While this operator is used extensively, it is also known for its complexity, which can make efficient evaluation of queries with OPTIONAL challenging. We tackle this problem in the Ontology-Based Data Access (OBDA) setting, where the data is stored in a SQL relational database and exposed as a virtual RDF graph by means of an R2RML mapping. We start with a succinct translation of a SPARQL fragment into SQL. It fully respects bag semantics and three-valued logic and relies on the extensive use of the LEFT JOIN operator and COALESCE function. We then propose optimisation techniques for reducing the size and improving the structure of generated SQL queries. Our optimisations capture interactions between JOIN, LEFT JOIN, COALESCE and integrity constraints such as attribute nullability, uniqueness and foreign key constraints. Finally, we empirically verify effectiveness of our techniques on the BSBM OBDA benchmark.
Learning Front-end Filter-bank Parameters using Convolutional Neural Networks for Abnormal Heart Sound Detection
Automatic heart sound abnormality detection can play a vital role in the early diagnosis of heart diseases, particularly in low-resource settings. The state-of-the-art algorithms for this task utilize a set of Finite Impulse Response (FIR) band-pass filters as a front-end followed by a Convolutional Neural Network (CNN) model. In this work, we propound a novel CNN architecture that integrates the front-end bandpass filters within the network using time-convolution (tConv) layers, which enables the FIR filter-bank parameters to become learnable. Different initialization strategies for the learnable filters, including random parameters and a set of predefined FIR filter-bank coefficients, are examined. Using the proposed tConv layers, we add constraints to the learnable FIR filters to ensure linear and zero phase responses. Experimental evaluations are performed on a balanced 4-fold cross-validation task prepared using the PhysioNet/CinC 2016 dataset. Results demonstrate that the proposed models yield superior performance compared to the state-of-the-art system, while the linear phase FIR filterbank method provides an absolute improvement of 9.54% over the baseline in terms of an overall accuracy metric.
Automated Image Data Preprocessing with Deep Reinforcement Learning
Data preparation, i.e. the process of transforming raw data into a format that can be used for training effective machine learning models, is a tedious and time-consuming task. For image data, preprocessing typically involves a sequence of basic transformations such as cropping, filtering, rotating or flipping images. Currently, data scientists decide manually based on their experience which transformations to apply in which particular order to a given image data set. Besides constituting a bottleneck in real-world data science projects, manual image data preprocessing may yield suboptimal results as data scientists need to rely on intuition or trial-and-error approaches when exploring the space of possible image transformations and thus might not be able to discover the most effective ones. To mitigate the inefficiency and potential ineffectiveness of manual data preprocessing, this paper proposes a deep reinforcement learning framework to automatically discover the optimal data preprocessing steps for training an image classifier. The framework takes as input sets of labeled images and predefined preprocessing transformations. It jointly learns the classifier and the optimal preprocessing transformations for individual images. Experimental results show that the proposed approach not only improves the accuracy of image classifiers, but also makes them substantially more robust to noisy inputs at test time.
Multilevel preconditioning for Ridge Regression
Solving linear systems is often the computational bottleneck in real-life problems. Iterative solvers are the only option due to the complexity of direct algorithms or because the system matrix is not explicitly known. Here, we develop a multilevel preconditioner for regularized least squares linear systems involving a feature or data matrix. Variants of this linear system may appear in machine learning applications, such as ridge regression, logistic regression, support vector machines and matrix factorization with side information. We use clustering algorithms to create coarser levels that preserve the principal components of the covariance or Gram matrix. These coarser levels approximate the dominant eigenvectors and are used to build a multilevel preconditioner accelerating the Conjugate Gradient method. We observed speed-ups for artificial and real-life data. For a specific data set, we achieved speed-up up to a factor 100.
RAPIDNN: In-Memory Deep Neural Network Acceleration Framework
Deep neural networks (DNN) have demonstrated effectiveness for various applications such as image processing, video segmentation, and speech recognition. Running state-of-the-art DNNs on current systems mostly relies on either general purpose processors, ASIC designs, or FPGA accelerators, all of which suffer from data movements due to the limited on chip memory and data transfer bandwidth. In this work, we propose a novel framework, called RAPIDNN, which processes all DNN operations within the memory to minimize the cost of data movement. To enable in-memory processing, RAPIDNN reinterprets a DNN model and maps it into a specialized accelerator, which is designed using non-volatile memory blocks that model four fundamental DNN operations, i.e., multiplication, addition, activation functions, and pooling. The framework extracts representative operands of a DNN model, e.g., weights and input values, using clustering methods to optimize the model for in-memory processing. Then, it maps the extracted operands and their precomputed results into the accelerator memory blocks. At runtime, the accelerator identifies computation results based on efficient in-memory search capability which also provides tunability of approximation to further improve computation efficiency. Our evaluation shows that RAPIDNN achieves 382.6x, 13.4x energy improvement and 211.5x, 5.6x performance speedup as compared to GPU-based DNN and the state-of-the-art DNN accelerator, while ensuring less than 0.3% of quality loss.
Sample-Efficient Deep RL with Generative Adversarial Tree Search
We propose Generative Adversarial Tree Search (GATS), a sample-efficient Deep Reinforcement Learning (DRL) algorithm. While Monte Carlo Tree Search (MCTS) is known to be effective for search and planning in RL, it is often sample-inefficient and therefore expensive to apply in practice. In this work, we develop a Generative Adversarial Network (GAN) architecture to model an environment’s dynamics and a predictor model for the reward function. We exploit collected data from interaction with the environment to learn these models, which we then use for model-based planning. During planning, we deploy a finite depth MCTS, using the learned model for tree search and a learned Q-value for the leaves, to find the best action. We theoretically show that GATS improves the bias-variance trade-off in value-based DRL. Moreover, we show that the generative model learns the model dynamics using orders of magnitude fewer samples than the Q-learner. In non-stationary settings where the environment model changes, we find the generative model adapts significantly faster than the Q-learner to the new environment.
Deep Learning Approximation: Zero-Shot Neural Network Speedup
Neural networks offer high-accuracy solutions to a range of problems, but are costly to run in production systems because of computational and memory requirements during a forward pass. Given a trained network, we propose a techique called Deep Learning Approximation to build a faster network in a tiny fraction of the time required for training by only manipulating the network structure and coefficients without requiring re-training or access to the training data. Speedup is achieved by by applying a sequential series of independent optimizations that reduce the floating-point operations (FLOPs) required to perform a forward pass. First, lossless optimizations are applied, followed by lossy approximations using singular value decomposition (SVD) and low-rank matrix decomposition. The optimal approximation is chosen by weighing the relative accuracy loss and FLOP reduction according to a single parameter specified by the user. On PASCAL VOC 2007 with the YOLO network, we show an end-to-end 2x speedup in a network forward pass with a 5% drop in mAP that can be re-gained by finetuning.
Hardware Trojan Attacks on Neural Networks
With the rising popularity of machine learning and the ever increasing demand for computational power, there is a growing need for hardware optimized implementations of neural networks and other machine learning models. As the technology evolves, it is also plausible that machine learning or artificial intelligence will soon become consumer electronic products and military equipment, in the form of well-trained models. Unfortunately, the modern fabless business model of manufacturing hardware, while economic, leads to deficiencies in security through the supply chain. In this paper, we illuminate these security issues by introducing hardware Trojan attacks on neural networks, expanding the current taxonomy of neural network security to incorporate attacks of this nature. To aid in this, we develop a novel framework for inserting malicious hardware Trojans in the implementation of a neural network classifier. We evaluate the capabilities of the adversary in this setting by implementing the attack algorithm on convolutional neural networks while controlling a variety of parameters available to the adversary. Our experimental results show that the proposed algorithm could effectively classify a selected input trigger as a specified class on the MNIST dataset by injecting hardware Trojans into

, on average, of neurons in the 5th hidden layer of arbitrary 7-layer convolutional neural networks, while undetectable under the test data. Finally, we discuss the potential defenses to protect neural networks against hardware Trojan attacks.
Motion Planning Networks
Fast and efficient motion planning algorithms are crucial for many state-of-the-art robotics applications such as self-driving cars. Existing motion planning methods such as RRT*, A*, and D*, become ineffective as their computational complexity increases exponentially with the dimensionality of the motion planning problem. To address this issue, we present a neural network-based novel planning algorithm which generates end-to-end collision-free paths irrespective of the obstacles’ geometry. The proposed method, called MPNet (Motion Planning Network), comprises of a Contractive Autoencoder which encodes the given workspaces directly from a point cloud measurement, and a deep feedforward neural network which takes the workspace encoding, start and goal configuration, and generates end-to-end feasible motion trajectories for the robot to follow. We evaluate MPNet on multiple planning problems such as planning of a point-mass robot, rigid-body, and 7 DOF Baxter robot manipulators in various 2D and 3D environments. The results show that MPNet is not only consistently computationally efficient in all 2D and 3D environments but also show remarkable generalization to completely unseen environments. The results also show that computation time of MPNet consistently remains less than 1 second which is significantly lower than existing state-of-the-art motion planning algorithms. Furthermore, through transfer learning, the MPNet trained in one scenario (e.g., indoor living places) can also quickly adapt to new scenarios (e.g., factory floors) with a little amount of data.
Insights on representational similarity in neural networks with canonical correlation
Comparing different neural network representations and determining how representations evolve over time remain challenging open questions in our understanding of the function of neural networks. Comparing representations in neural networks is fundamentally difficult as the structure of representations varies greatly, even across groups of networks trained on identical tasks, and over the course of training. Here, we develop projection weighted CCA (Canonical Correlation Analysis) as a tool for understanding neural networks, building off of SVCCA, a recently proposed method. We first improve the core method, showing how to differentiate between signal and noise, and then apply this technique to compare across a group of CNNs, demonstrating that networks which generalize converge to more similar representations than networks which memorize, that wider networks converge to more similar solutions than narrow networks, and that trained networks with identical topology but different learning rates converge to distinct clusters with diverse representations. We also investigate the representational dynamics of RNNs, across both training and sequential timesteps, finding that RNNs converge in a bottom-up pattern over the course of training and that the hidden state is highly variable over the course of a sequence, even when accounting for linear transforms. Together, these results provide new insights into the function of CNNs and RNNs, and demonstrate the utility of using CCA to understand representations.
Multilevel Artificial Neural Network Training for Spatially Correlated Learning
Multigrid modeling algorithms are a technique used to accelerate relaxation models running on a hierarchy of similar graphlike structures. We introduce and demonstrate a new method for training neural networks which uses multilevel methods. Using an objective function derived from a graph-distance metric, we perform orthogonally-constrained optimization to find optimal prolongation and restriction maps between graphs. We compare and contrast several methods for performing this numerical optimization, and additionally present some new theoretical results on upper bounds of this type of objective function. Once calculated, these optimal maps between graphs form the core of Multiscale Artificial Neural Network (MsANN) training, a new procedure we present which simultaneously trains a hierarchy of neural network models of varying spatial resolution. Parameter information is passed between members of this hierarchy according to standard coarsening and refinement schedules from the multiscale modelling literature. In our machine learning experiments, these models are able to learn faster than default training, achieving a comparable level of error in an order of magnitude fewer training examples.
Interactive Classification for Deep Learning Interpretation
We present an interactive system enabling users to manipulate images to explore the robustness and sensitivity of deep learning image classifiers. Using modern web technologies to run in-browser inference, users can remove image features using inpainting algorithms and obtain new classifications in real time, which allows them to ask a variety of ‘what if’ questions by experimentally modifying images and seeing how the model reacts. Our system allows users to compare and contrast what image regions humans and machine learning models use for classification, revealing a wide range of surprising results ranging from spectacular failures (e.g., a ‘water bottle’ image becomes a ‘concert’ when removing a person) to impressive resilience (e.g., a ‘baseball player’ image remains correctly classified even without a glove or base). We demonstrate our system at The 2018 Conference on Computer Vision and Pattern Recognition (CVPR) for the audience to try it live. Our system is open-sourced at
https://…/interactive-classification. A video demo is available at
https://youtu.be/llub5GcOF6w.
Self-Imitation Learning
This paper proposes Self-Imitation Learning (SIL), a simple off-policy actor-critic algorithm that learns to reproduce the agent’s past good decisions. This algorithm is designed to verify our hypothesis that exploiting past good experiences can indirectly drive deep exploration. Our empirical results show that SIL significantly improves advantage actor-critic (A2C) on several hard exploration Atari games and is competitive to the state-of-the-art count-based exploration methods. We also show that SIL improves proximal policy optimization (PPO) on MuJoCo tasks.
NCRF++: An Open-source Neural Sequence Labeling Toolkit
This paper describes NCRF++, a toolkit for neural sequence labeling. NCRF++ is designed for quick implementation of different neural sequence labeling models with a CRF inference layer. It provides users with an inference for building the custom model structure through configuration file with flexible neural feature design and utilization. Built on PyTorch, the core operations are calculated in batch, making the toolkit efficient with the acceleration of GPU. It also includes the implementations of most state-of-the-art neural sequence labeling models such as LSTM-CRF, facilitating reproducing and refinement on those methods.
• Deep Lip Reading: a comparison of models and an online application
• Computationally Efficient Estimation of the Spectral Gap of a Markov Chain
• AVX-512 extension to OpenQCD 1.6
• Differential Evolution Algorithm Aided Turbo Channel Estimation and Multi-User Detection for G.Fast Systems in the Presence of FEXT
• One-Shot Unsupervised Cross Domain Translation
• A new characterization of the Gamma distribution and associated goodness of fit tests
• Forecasting-Based State Estimation for Three-Phase Distribution Systems with Limited Sensing
• On finite sets of small tripling or small alternation in arbitrary groups
• Imbalanced Randomization in Non-Inferiority Trial
• Shifted-antimagic Labelings for Graphs
• Homonym Detection in Curated Bibliographies: Learning from dblp’s Experience (full version)
• Bounds on the number of 2-level polytopes, cones and configurations
• Partially-Supervised Image Captioning
• On Machine Learning and Structure for Mobile Robots
• Fluctuations for block spin Ising models
• Asymptotics for the number of zero drift reflectable walks in a Weyl chamber of type A
• A Dataset for Building Code-Mixed Goal Oriented Conversation Systems
• Simulating Coulomb gases and log-gases with hybrid Monte Carlo algorithms
• Ego-Lane Analysis System (ELAS): Dataset and Algorithms
• Transience and Recurrence of Markov Processes with Constrained Local Time
• Supervised learning with generalized tensor networks
• A characterization of linearized polynomials with maximum kernel
• Quantum computing with classical bits
• Higher order spacing ratios in random matrix theory and complex quantum systems
• Controllable Semantic Image Inpainting
• A goodness of fit test for the Pareto distribution
• Discovering User Groups for Natural Language Generation
• Efficient Nearest Neighbors Search for Large-Scale Landmark Recognition
• Enhanced string factoring from alphabet orderings
• Generalized Log-Normal Chain-Ladder
• The role of non-normality for control energy reduction in network controllability problems
• IPSME- Idempotent Publish/Subscribe Messaging Environment
• Rank-metric codes, linear sets, and their duality
• On a property of the inequality curve $λ(p)$
• Right marker speeds of solutions to the KPP equation with noise
• A $β$-mixing inequality for point processes induced by their intensity functions
• On the Coefficients of the Permanent and the Determinant of a Circulant Matric. Applications
• Optimal investment and consumption with labor income in incomplete markets
• An Empirical Analysis of the Correlation of Syntax and Prosody
• Improving width-based planning with compact policies
• Mining Rank Data
• Interior Point Methods for PDE-Constrained Optimization with Sparsity Constraints
• A simple blind-denoising filter inspired by electrically coupled photoreceptors in the retina
• Landscape Boolean Functions
• Financial Risk and Returns Prediction with Modular Networked Learning
• Cliques and a new measure of clustering: with application to U.S. domestic airlines
• Data-Efficient Design Exploration through Surrogate-Assisted Illumination
• On the automaticity of the Hankel determinants of a family of automatic sequences
• Practical Fault Attack on Deep Neural Networks
• Constructing an efficient machine learning model for tornado prediction
• Coupled conditional backward sampling particle filter
• Semantic Variation in Online Communities of Practice
• On Stochastic Cucker-Smale flocking dynamics
• A Covariance Matrix Self-Adaptation Evolution Strategy for Linear Constrained Optimization
• Bayesian inversion of a diffusion evolution equation with application to Biology
• Real-time Monocular Visual Odometry for Turbid and Dynamic Underwater Environments
• Density estimation for RWRE
• The Road to Success: Assessing the Fate of Linguistic Innovations in Online Communities
• On the exact minimization of saturated loss functions for robust regression and subspace estimation
• Parametric versus nonparametric: the fitness coefficient
• Statistical Inference with Ensemble of Clustered Desparsified Lasso
• Dispatch and Primary Frequency Control with Electrochemical Storage: a System-wise Verification
• Three dimensional Deep Learning approach for remote sensing image classification
• Primal-dual residual networks
• Measuring intergroup agreement and disagreement
• BubbleRank: Safe Online Learning to Rerank
• Safe Active Feature Selection for Sparse Learning
• Best sources forward: domain generalization through source-specific nets
• Molecular generative model based on conditional variational autoencoder for de novo molecular design
• Unsupervised Deep Image Hashing through Tag Embeddings
• On the characterization of the degree of interpolation polynomials in terms of certain combinatorical matrices
• The agreement distance of rooted phylogenetic networks
• CIA-Towards a Unified Marketing Optimization Framework for e-Commerce Sponsored Search
• SATR-DL: Improving Surgical Skill Assessment and Task Recognition in Robot-assisted Surgery with Deep Neural Networks
• Polyhedra Circuits and Their Applications
• Deep Learning with Convolutional Neural Network for Objective Skill Evaluation in Robot-assisted Surgery
• Recurrent Multiresolution Convolutional Networks for VHR Image Classification
• Monaural source enhancement maximizing source-to-distortion ratio via automatic differentiation
• Random depthwise signed convolutional neural networks
• Constrained quantum annealing of graph coloring
• A Survey of Automatic Facial Micro-expression Analysis: Databases, Methods and Challenges
• Permutation polynomials and complete permutation polynomials over $\mathbb{F}_{q^{3}}$
• Tiny Codes for Guaranteeable Delay
• Accurate and Robust Localization Techniques for Wireless Sensor Networks
• Generative Adversarial Networks and Perceptual Losses for Video Super-Resolution
• The Right Complexity Measure in Locally Private Estimation: It is not the Fisher Information
• Quantized State Hybrid Automata for Cyber-Physical Systems
• Relaxation-Relaxation Correlation Spectroscopic Imaging (RR-CSI): Leveraging the Blessings of Dimensionality to Map In Vivo Microstructure
• Adaptive Incentive Design
• Probing entanglement entropy via randomized measurements
• Simultaneous model calibration and source inversion in atmospheric dispersion models
• The distribution of shortest path lengths in subcritical Erdös-Renyi networks
• Age and Gender Classification From Ear Images
• Using Search Queries to Understand Health Information Needs in Africa
• A Sauer-Shelah-Perles Lemma for Sumsets
• Efficient sampling for Gaussian linear regression with arbitrary priors
• Personalized Context-Aware Point of Interest Recommendation
• Learning Influence-Receptivity Network Structure with Guarantee
• Action Learning for 3D Point Cloud Based Organ Segmentation
• Non-asymptotic Identification of LTI Systems from a Single Trajectory
• Multilevel constructions: coding, packing and geometric uniformity
• Ramanujan graphs in cryptography
• Ansatz for $(-1)^{n-1}\nabla p_n$
• On (signed) Takagi-Landsberg functions: $p^{\text{th}}$ variation, maximum, and modulus of continuity
• A Computational Approach to Organizational Structure
• Applications of Various Space-time Transformations to Determine Radar Signal Distortion Caused by a Moving Target Having Constant Velocity and Acceleration
• Evolving simple programs for playing Atari games
• Discovering Latent Patterns of Urban Cultural Interactions in WeChat for Modern City Planning
• Learning Human Optical Flow
• GLoMo: Unsupervisedly Learned Relational Graphs as Transferable Representations
• Structure-Infused Copy Mechanisms for Abstractive Summarization
• Losing at Checkers is Hard
• Abstract Meaning Representation for Multi-Document Summarization
• HGR-Net: A Two-stage Convolutional Neural Network for Hand Gesture Segmentation and Recognition
• Grounded Textual Entailment
• Burning the plane: densities of the infinite Cartesian grid
• Immunization of networks with non-overlapping community structure
• Improving SAGA via a Probabilistic Interpolation with Gradient Descent
• Learning in POMDPs with Monte Carlo Tree Search
• VoxCeleb2: Deep Speaker Recognition
• A Convex Hull Based Approach for MIMO Radar Waveform Design with Quantized Phases
• DynSLAM: Tracking, Mapping and Inpainting in Dynamic Scenes
• Stochastic Variance-Reduced Policy Gradient
• Disorder in quantum many-body systems
• From Self-ception to Image Self-ception: A method to represent an image with its own approximations
• Anonymous Information Delivery
• Gender Prediction in English-Hindi Code-Mixed Social Media Content : Corpus and Baseline System
• A Survey on Open Information Extraction
• Improving Consistency-Based Semi-Supervised Learning with Weight Averaging
• Inducing information stability and applications thereof to obtaining information theoretic necessary conditions directly from operational requirements
• Market-Oriented Information Trading in Internet of Things (IoT) for Smart Cities
• Tract orientation mapping for bundle-specific tractography
• An extremal property of the normal distribution, with a discrete analog
• Autoregressive Quantile Networks for Generative Modeling
• Weakly-Supervised Learning for Tool Localization in Laparoscopic Videos
• Direct Automated Quantitative Measurement of Spine via Cascade Amplifier Regression Network
• Cardiac Motion Scoring with Segment- and Subject-level Non-Local Modeling
• Data-Driven Analytics for Benchmarking and Optimizing Retail Store Performance
• A Generalized Framework for Simultaneous Long-Short Feedback Trading
• Adaptive Shooting for Bots in First Person Shooter Games Using Reinforcement Learning
• Online Variant of Parcel Allocation in Last-mile Delivery
• Hyper Space Exploration – A Multicriterial Quantitative Trade-Off Analysis for System Design in Complex Environment
• Understanding Complex Systems: From Networks to Optimal Higher-Order Models
• Structured Variational Learning of Bayesian Neural Networks with Horseshoe Priors
• Boosted Training of Convolutional Neural Networks for Multi-Class Segmentation
• Bayesian Uncertainty Quantification and Information Fusion in CALPHAD-based Thermodynamic Modeling
• Spectrum of SYK model II: Central limit theorem
• A closed formula for the generating function of $p$-Bernoulli numbers: An elementary proof
• Computation of option greeks under hybrid stochastic volatility models via Malliavin calculus
• An Enhanced BPSO based Approach for Service Placement in Hybrid Cloud
• Lung ultrasound surface wave elastography for assessing instititial lung disease
• The Bass diffusion model on finite Barabasi-Albert networks
• Infrared Safety of a Neural-Net Top Tagging Algorithm
Like this:
Like Loading...