Hierarchical Reinforcement Learning with Hindsight
Reinforcement Learning (RL) algorithms can suffer from poor sample efficiency when rewards are delayed and sparse. We introduce a solution that enables agents to learn temporally extended actions at multiple levels of abstraction in a sample efficient and automated fashion. Our approach combines universal value functions and hindsight learning, allowing agents to learn policies belonging to different time scales in parallel. We show that our method significantly accelerates learning in a variety of discrete and continuous tasks.
Turbo Learning for Captionbot and Drawingbot
We study in this paper the problems of both image captioning and text-to-image generation, and present a novel turbo learning approach to jointly training an image-to-text generator (a.k.a. captionbot) and a text-to-image generator (a.k.a. drawingbot). The key idea behind the joint training is that image-to-text generation and text-to-image generation as dual problems can form a closed loop to provide informative feedback to each other. Based on such feedback, we introduce a new loss metric by comparing the original input with the output produced by the closed loop. In addition to the old loss metrics used in captionbot and drawingbot, this extra loss metric makes the jointly trained captionbot and drawingbot better than the separately trained captionbot and drawingbot. Furthermore, the turbo-learning approach enables semi-supervised learning since the closed loop can provide peudo-labels for unlabeled samples. Experimental results on the COCO dataset demonstrate that the proposed turbo learning can significantly improve the performance of both captionbot and drawingbot by a large margin.
Learning to Optimize Tensor Programs
We introduce a learning-based framework to optimize tensor programs for deep learning workloads. Efficient implementations of tensor operators, such as matrix multiplication and high dimensional convolution, are key enablers of effective deep learning systems. However, existing systems rely on manually optimized libraries such as cuDNN where only a narrow range of server class GPUs are well-supported. The reliance on hardware-specific operator libraries limits the applicability of high-level graph optimizations and incurs significant engineering costs when deploying to new hardware targets. We use learning to remove this engineering burden. We learn domain-specific statistical cost models to guide the search of tensor operator implementations over billions of possible program variants. We further accelerate the search by effective model transfer across workloads. Experimental results show that our framework delivers performance competitive with state-of-the-art hand-tuned libraries for low-power CPU, mobile GPU, and server-class GPU.
VideoCapsuleNet: A Simplified Network for Action Detection
The recent advances in Deep Convolutional Neural Networks (DCNNs) have shown extremely good results for video human action classification, however, action detection is still a challenging problem. The current action detection approaches follow a complex pipeline which involves multiple tasks such as tube proposals, optical flow, and tube classification. In this work, we present a more elegant solution for action detection based on the recently developed capsule network. We propose a 3D capsule network for videos, called VideoCapsuleNet: a unified network for action detection which can jointly perform pixel-wise action segmentation along with action classification. The proposed network is a generalization of capsule network from 2D to 3D, which takes a sequence of video frames as input. The 3D generalization drastically increases the number of capsules in the network, making capsule routing computationally expensive. We introduce capsule-pooling in the convolutional capsule layer to address this issue which makes the voting algorithm tractable. The routing-by-agreement in the network inherently models the action representations and various action characteristics are captured by the predicted capsules. This inspired us to utilize the capsules for action localization and the class-specific capsules predicted by the network are used to determine a pixel-wise localization of actions. The localization is further improved by parameterized skip connections with the convolutional capsule layers and the network is trained end-to-end with a classification as well as localization loss. The proposed network achieves sate-of-the-art performance on multiple action detection datasets including UCF-Sports, J-HMDB, and UCF-101 (24 classes) with an impressive ~20% improvement on UCF-101 and ~15% improvement on J-HMDB in terms of v-mAP scores.
A Marketplace for Data: An Algorithmic Solution
In this work, we aim to create a data marketplace; a robust real-time matching mechanism to efficiently buy and sell training data for Machine Learning tasks. While the monetization of data and pre-trained models is an essential focus of industry today, there does not exist a market mechanism to price training data and match buyers to vendors while still addressing the associated (computational and other) complexity. The challenge in creating such a market stems from the very nature of data as an asset: it is freely replicable; its value is inherently combinatorial due to correlation with signal in other data; prediction tasks and the value of accuracy vary widely; usefulness of training data is difficult to verify a priori without first applying it to a prediction task. As our main contributions we: (i) propose a mathematical model for a two-sided data market and formally define key challenges; (ii) construct algorithms for such a market to function and rigorously prove how they meet the challenges defined. We highlight two technical contributions: (i) a remarkable link between Myerson’s payment function arising in mechanism design and the Lovasz extension arising in submodular optimization; (ii) a novel notion of ‘fairness’ required for cooperative games with freely replicable goods. These might be of independent interest.
Graph Capsule Convolutional Neural Networks
Graph Convolutional Neural Networks (GCNNs) are the most recent exciting advancement in deep learning field and their applications are quickly spreading in multi-cross-domains including bioinformatics, chemoinformatics, social networks, natural language processing and computer vision. In this paper, we expose and tackle some of the basic weaknesses of a GCNN model with a capsule idea presented in~\cite{hinton2011transforming} and propose our Graph Capsule Network (GCAPS-CNN) model. In addition, we design our GCAPS-CNN model to solve especially graph classification problem which current GCNN models find challenging. Through extensive experiments, we show that our proposed Graph Capsule Network can significantly outperforms both the existing state-of-art deep learning methods and graph kernels on graph classification benchmark datasets.
Faster Neural Network Training with Approximate Tensor Operations
We propose a novel technique for faster Neural Network (NN) training by systematically approximating all the constituent matrix multiplications and convolutions. This approach is complementary to other approximation techniques, requires no changes to the dimensions of the network layers, hence compatible with existing training frameworks. We first analyze the applicability of the existing methods for approximating matrix multiplication to NN training, and extend the most suitable column-row sampling algorithm to approximating multi-channel convolutions. We apply approximate tensor operations to training MLP, CNN and LSTM network architectures on MNIST, CIFAR-100 and Penn Tree Bank datasets and demonstrate 30%-80% reduction in the amount of computations while maintaining little or no impact on the test accuracy. Our promising results encourage further study of general methods for approximating tensor operations and their application to NN training.
NEWMA: a new method for scalable model-free online change-point detection
We consider the problem of detecting abrupt changes in the distribution of a multi-dimensional time series, with limited computing power and memory. In this paper, we propose a new method for model-free online change-point detection that relies only on fast and light recursive statistics, inspired by the classical Exponential Weighted Moving Average algorithm (EWMA). The proposed idea is to compute two EWMA statistics on the stream of data with different forgetting factors, and to compare them. By doing so, we show that we implicitly compare recent samples with older ones, without the need to explicitly store them. Additionally, we leverage Random Features to efficiently use the Maximum Mean Discrepancy as a distance between distributions. We show that our method is orders of magnitude faster than usual non-parametric methods for a given accuracy.
Algorithms and Analysis for the SPARQL Constructs
As Resource Description Framework (RDF) is becoming a popular data modelling standard, the challenges of efficient processing of Basic Graph Pattern (BGP) SPARQL queries (a.k.a. SQL inner-joins) have been a focus of the research community over the past several years. In our recently published work we brought community’s attention to another equally important component of SPARQL, i.e., OPTIONAL pattern queries (a.k.a. SQL left-outer-joins). We proposed novel optimization techniques — first of a kind — and showed experimentally that our techniques perform better for the low-selectivity queries, and give at par performance for the highly selective queries, compared to the state-of-the-art methods. BGPs and OPTIONALs (BGP-OPT) make the basic building blocks of the SPARQL query language. Thus, in this paper, treating our BGP-OPT query optimization techniques as the primitives, we extend them to handle other broader components of SPARQL such as such as UNION, FILTER, and DISTINCT. We mainly focus on the procedural (algorithmic) aspects of these extensions. We also make several important observations about the structural aspects of complex SPARQL queries with any intermix of these clauses, and relax some of the constraints regarding the cyclic properties of the queries proposed earlier. We do so without affecting the correctness of the results, thus providing more flexibility in using the BGP-OPT optimization techniques.
Bidirectional Learning for Robust Neural Networks
A multilayer perceptron can behave as a generative classifier by applying bidirectional learning (BL). It consists of training an undirected neural network to map input to output and vice-versa; therefore it can produce a classifier in one direction, and a generator in the opposite direction for the same data. In this paper, two novel learning techniques are introduced which use BL for improving robustness to white noise static and adversarial examples. The first method is bidirectional propagation of errors, which the error propagation occurs in backward and forward directions. Motivated by the fact that its generative model receives as input a constant vector per class, we introduce as a second method the hybrid adversarial networks (HAN). Its generative model receives a random vector as input and its training is based on generative adversarial networks (GAN). To assess the performance of BL, we perform experiments using several architectures with fully and convolutional layers, with and without bias. Experimental results show that both methods improve robustness to white noise static and adversarial examples, but have different behaviour depending on the architecture and task, being more beneficial to use the one or the other. Nevertheless, HAN using a convolutional architecture with batch normalization presents outstanding robustness, reaching state-of-the-art accuracy on adversarial examples of hand-written digits.
Adversarial Noise Layer: Regularize Neural Network By Adding Noise
In this paper, we introduce a novel regularization method called Adversarial Noise Layer (ANL), which significantly improve the CNN’s generalization ability by adding adversarial noise in the hidden layers. ANL is easy to implement and can be integrated with most of the CNN-based models. We compared the impact of the different type of noise and visually demonstrate that adversarial noise guide CNNs to learn to extract cleaner feature maps, further reducing the risk of over-fitting. We also conclude that the model trained with ANL is more robust to FGSM and IFGSM attack. Code is available at:
https://…/ANL
Streaming MANN: A Streaming-Based Inference for Energy-Efficient Memory-Augmented Neural Networks
With the successful development of artificial intelligence using deep learning, there has been growing interest in its deployment. The mobile environment is the closest hardware platform to real life, and it has become an important platform for the success or failure of artificial intelligence. Memory-augmented neural networks (MANNs) are neural networks proposed to efficiently handle question-and-answer (Q&A) tasks, well-suited for mobile devices. As a MANN requires various types of operations and recurrent data paths, it is difficult to accelerate the inference in the structure designed for other conventional neural network models, which is one of the biggest obstacles to deploying MANNs in mobile environments. To address the aforementioned issues, we propose Streaming MANN. This is the first attempt to implement and demonstrate the architecture for energy-efficient inference of MANNs with the concept of streaming processing. To achieve the full potential of the streaming process, we propose a novel approach, called inference thresholding, using Bayesian approach considering the characteristics of natural language processing (NLP) tasks. To evaluate our proposed approaches, we implemented the architecture and method in a field-programmable gate array (FPGA) which is suitable for streaming processing. We measured the execution time and power consumption of the inference for the bAbI dataset. The experimental results showed that the performance efficiency per energy (FLOPS/kJ) of the Streaming MANN increased by a factor of up to about 126 compared to the results of NVIDIA TITAN V, and up to 140 if inference thresholding is applied.
Silence
The cost of communication is a substantial factor affecting the scalability of many distributed applications. Every message sent can incur a cost in storage, computation, energy and bandwidth. Consequently, reducing the communication costs of distributed applications is highly desirable. The best way to reduce message costs is by communicating without sending any messages whatsoever. This paper initiates a rigorous investigation into the use of silence in synchronous settings, in which processes can fail. We formalize sufficient conditions for information transfer using silence, as well as necessary conditions for particular cases of interest. This allows us to identify message patterns that enable communication through silence. In particular, a pattern called a {\em silent choir} is identified, and shown to be central to information transfer via silence in failure-prone systems. The power of the new framework is demonstrated on the {\em atomic commitment} problem (AC). A complete characterization of the tradeoff between message complexity and round complexity in the synchronous model with crash failures is provided, in terms of lower bounds and matching protocols. In particular, a new message-optimal AC protocol is designed using silence, in which processes decide in~3 rounds in the common case. This significantly improves on the best previously known message-optimal AC protocol, in which decisions were performed in
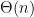
rounds.
Transductive Boltzmann Machines
We present transductive Boltzmann machines (TBMs), which firstly achieve transductive learning of the Gibbs distribution. While exact learning of the Gibbs distribution is impossible by the family of existing Boltzmann machines due to combinatorial explosion of the sample space, TBMs overcome the problem by adaptively constructing the minimum required sample space from data to avoid unnecessary generalization. We theoretically provide bias-variance decomposition of the KL divergence in TBMs to analyze its learnability, and empirically demonstrate that TBMs are superior to the fully visible Boltzmann machines and popularly used restricted Boltzmann machines in terms of efficiency and effectiveness.
Bilinear Attention Networks
Attention networks in multimodal learning provide an efficient way to utilize given visual information selectively. However, the computational cost to learn attention distributions for every pair of multimodal input channels is prohibitively expensive. To solve this problem, co-attention builds two separate attention distributions for each modality neglecting the interaction between multimodal inputs. In this paper, we propose bilinear attention networks (BAN) that find bilinear attention distributions to utilize given vision-language information seamlessly. BAN considers bilinear interactions among two groups of input channels, while low-rank bilinear pooling extracts the joint representations for each pair of channels. Furthermore, we propose a variant of multimodal residual networks to exploit eight-attention maps of the BAN efficiently. We quantitatively and qualitatively evaluate our model on visual question answering (VQA 2.0) and Flickr30k Entities datasets, showing that BAN significantly outperforms previous methods and achieves new state-of-the-arts on both datasets.
Evolutionary Reinforcement Learning
Deep Reinforcement Learning (DRL) algorithms have been successfully applied to a range of challenging control tasks. However, these methods typically suffer from three core difficulties: temporal credit assignment with sparse rewards, lack of effective exploration, and brittle convergence properties that are extremely sensitive to hyperparameters. Collectively, these challenges severely limit the applicability of these approaches to real world problems. Evolutionary Algorithms (EAs), a class of black box optimization techniques inspired by natural evolution, are well suited to address each of these three challenges. However, EAs typically suffer with high sample complexity and struggle to solve problems that require optimization of a large number of parameters. In this paper, we introduce Evolutionary Reinforcement Learning (ERL), a hybrid algorithm that leverages the population of an EA to provide diversified data to train an RL agent, and reinserts the RL agent into the EA population periodically to inject gradient information into the EA. ERL inherits EA’s ability of temporal credit assignment with a fitness metric, effective exploration with a diverse set of policies, and stability of a population-based approach and complements it with off-policy DRL’s ability to leverage gradients for higher sample efficiency and faster learning. Experiments in a range of challenging continuous control benchmark tasks demonstrate that ERL significantly outperforms prior DRL and EA methods, achieving state-of-the-art performances.
IoT2Vec: Identification of Similar IoT Devices via Activity Footprints
We consider a smart home or smart office environment with a number of IoT devices connected and passing data between one another. The footprints of the data transferred can provide valuable information about the devices, which can be used to (a) identify the IoT devices and (b) in case of failure, to identify the correct replacements for these devices. In this paper, we generate the embeddings for IoT devices in a smart home using Word2Vec, and explore the possibility of having a similar concept for IoT devices, aka IoT2Vec. These embeddings can be used in a number of ways, such as to find similar devices in an IoT device store, or as a signature of each type of IoT device. We show results of a feasibility study on the CASAS dataset of IoT device activity logs, using our method to identify the patterns in embeddings of various types of IoT devices in a household.
Localized Multiple Kernel Learning for Anomaly Detection: One-class Classification
Multi-kernel learning has been well explored in the recent past and has exhibited promising outcomes for multi-class classification and regression tasks. In this paper, we present a multiple kernel learning approach for the One-class Classification (OCC) task and employ it for anomaly detection. Recently, the basic multi-kernel approach has been proposed to solve the OCC problem, which is simply a convex combination of different kernels with equal weights. This paper proposes a Localized Multiple Kernel learning approach for Anomaly Detection (LMKAD) using OCC, where the weight for each kernel is assigned locally. Proposed LMKAD approach adapts the weight for each kernel using a gating function. The parameters of the gating function and one-class classifier are optimized simultaneously through a two-step optimization process. We present the empirical results of the performance of LMKAD on 25 benchmark datasets from various disciplines. This performance is evaluated against existing Multi Kernel Anomaly Detection (MKAD) algorithm, and four other existing kernel-based one class classifiers to showcase the credibility of our approach. Our algorithm achieves significantly better Gmean scores while using a lesser number of support vectors compared to MKAD. Friedman test is also performed to verify the statistical significance of the results claimed in this paper.
Parameter Hub: a Rack-Scale Parameter Server for Distributed Deep Neural Network Training
Distributed deep neural network (DDNN) training constitutes an increasingly important workload that frequently runs in the cloud. Larger DNN models and faster compute engines are shifting DDNN training bottlenecks from computation to communication. This paper characterizes DDNN training to precisely pinpoint these bottlenecks. We found that timely training requires high performance parameter servers (PSs) with optimized network stacks and gradient processing pipelines, as well as server and network hardware with balanced computation and communication resources. We therefore propose PHub, a high performance multi-tenant, rack-scale PS design. PHub co-designs the PS software and hardware to accelerate rack-level and hierarchical cross-rack parameter exchange, with an API compatible with many DDNN training frameworks. PHub provides a performance improvement of up to 2.7x compared to state-of-the-art distributed training techniques for cloud-based ImageNet workloads, with 25% better throughput per dollar.
A Framework and Method for Online Inverse Reinforcement Learning
Inverse reinforcement learning (IRL) is the problem of learning the preferences of an agent from the observations of its behavior on a task. While this problem has been well investigated, the related problem of {\em online} IRL—where the observations are incrementally accrued, yet the demands of the application often prohibit a full rerun of an IRL method—has received relatively less attention. We introduce the first formal framework for online IRL, called incremental IRL (I2RL), and a new method that advances maximum entropy IRL with hidden variables, to this setting. Our formal analysis shows that the new method has a monotonically improving performance with more demonstration data, as well as probabilistically bounded error, both under full and partial observability. Experiments in a simulated robotic application of penetrating a continuous patrol under occlusion shows the relatively improved performance and speed up of the new method and validates the utility of online IRL.
Parallel Transport Convolution: A New Tool for Convolutional Neural Networks on Manifolds
Convolution has been playing a prominent role in various applications in science and engineering for many years. It is the most important operation in convolutional neural networks. There has been a recent growth of interests of research in generalizing convolutions on curved domains such as manifolds and graphs. However, existing approaches cannot preserve all the desirable properties of Euclidean convolutions, namely compactly supported filters, directionality, transferability across different manifolds. In this paper we develop a new generalization of the convolution operation, referred to as parallel transport convolution (PTC), on Riemannian manifolds and their discrete counterparts. PTC is designed based on the parallel transportation which is able to translate information along a manifold and to intrinsically preserve directionality. PTC allows for the construction of compactly supported filters and is also robust to manifold deformations. This enables us to preform wavelet-like operations and to define deep convolutional neural networks on curved domains.
A Hierarchical Structured Self-Attentive Model for Extractive Document Summarization (HSSAS)
The recent advance in neural network architecture and training algorithms have shown the effectiveness of representation learning. The neural network-based models generate better representation than the traditional ones. They have the ability to automatically learn the distributed representation for sentences and documents. To this end, we proposed a novel model that addresses several issues that are not adequately modeled by the previously proposed models, such as the memory problem and incorporating the knowledge of document structure. Our model uses a hierarchical structured self-attention mechanism to create the sentence and document embeddings. This architecture mirrors the hierarchical structure of the document and in turn enables us to obtain better feature representation. The attention mechanism provides extra source of information to guide the summary extraction. The new model treated the summarization task as a classification problem in which the model computes the respective probabilities of sentence-summary membership. The model predictions are broken up by several features such as information content, salience, novelty and positional representation. The proposed model was evaluated on two well-known datasets, the CNN / Daily Mail, and DUC 2002. The experimental results show that our model outperforms the current extractive state-of-the-art by a considerable margin.
• Boosting Uncertainty Estimation for Deep Neural Classifiers
• A theory on the absence of spurious optimality
• The elastic and directed percolation backbone
• Learning Maximum-A-Posteriori Perturbation Models for Structured Prediction in Polynomial Time
• Depth-Limited Solving for Imperfect-Information Games
• Masking: A New Perspective of Noisy Supervision
• Hierarchically Structured Reinforcement Learning for Topically Coherent Visual Story Generation
• Fiding forbidden minors in sublinear time: a $O(n^{1/2 + o(1)})$-query one-sided tester for minor closed properties on bounded degree graphs
• Constrained Sparse Subspace Clustering with Side-Information
• Party Matters: Enhancing Legislative Embeddings with Author Attributes for Vote Prediction
• Reproducibility Report for ‘Learning To Count Objects In Natural Images For Visual Question Answering’
• ‘You Know What to Do’: Proactive Detection of YouTube Videos Targeted by Coordinated Hate Attacks
• Multi-Perspective Relevance Matching with Hierarchical ConvNets for Social Media Search
• Snapping out Walsh’s Brownian motion and related stiff problem
• Numeracy for Language Models: Evaluating and Improving their Ability to Predict Numbers
• Persistence of natural disasters on child health: Evidence from the Great Kanto Earthquake of 1923
• On Universally Good Flower Codes
• Steiner Wiener index of block graphs
• Assessing randomness in case assignment: the case study of the Brazilian Supreme Court
• A New Lower Bound for Agnostic Learning with Sample Compression Schemes
• Meta-learning with differentiable closed-form solvers
• Overabundant Information and Learning Traps
• On standard Young tableaux of bounded height
• Distributed Algorithms for Directed Betweenness Centrality and All Pairs Shortest Paths
• A General Family of Robust Stochastic Operators for Reinforcement Learning
• Impulsive Noise Immunity of Multidimensional Pulse Position Modulation
• On the Complexity of the Cogrowth Sequence
• On the Convergence of Stochastic Gradient Descent with Adaptive Stepsizes
• Stacked Semantic-Guided Attention Model for Fine-Grained Zero-Shot Learning
• On a general structure for hazard-based regression models: an application to population-based cancer research
• Comparison of Semantic Segmentation Approaches for Horizon/Sky Line Detection
• Non-Oscillatory Pattern Learning for Non-Stationary Signals
• Computational Historical Linguistics
• Invariant Representations from Adversarially Censored Autoencoders
• Understanding Self-Paced Learning under Concave Conjugacy Theory
• Small steps and giant leaps: Minimal Newton solvers for Deep Learning
• Variational based Mixed Noise Removal with CNN Deep Learning Regularization
• NeuralREG: An end-to-end approach to referring expression generation
• Efficient and Robust Question Answering from Minimal Context over Documents
• On The Joint Normality of Certain Statistics on Ordered Trees
• Channel Estimation for Visible Light Communications Using Neural Networks
• Super Learning in the SAS system
• Online Learning in Kernelized Markov Decision Processes
• A universal framework for learning based on the elliptical mixture model (EMM)
• The Adaptive sampling revisited
• Never look back – The EnKF method and its application to the training of neural networks without back propagation
• A Talker Ensemble: the University of Wrocław’s Entry to the NIPS 2017 Conversational Intelligence Challenge
• On graphs with exactly two positive eigenvalues
• Polarization Rank: A Study on European News Consumption on Facebook
• Incorporating Glosses into Neural Word Sense Disambiguation
• A Correlation Measure Based on Vector-Valued $L_p$-Norms
• Energy balancing for robotic aided clustered wireless sensor networks using mobility diversity algorithms
• Restricted eigenvalue property for corrupted Gaussian designs
• DiDA: Disentangled Synthesis for Domain Adaptation
• Improving Anti-Eavesdropping Ability without Eavesdropper’s CSI: A Practical Secure Transmission Design Perspective
• DifNet: Semantic Segmentation by DiffusionNetworks
• Incentive-Compatible Diffusion
• Where Do You Think You’re Going : Inferring Beliefs about Dynamics from Behavior
• Object Detection in Equirectangular Panorama
• Performance Bound Analysis for Crowdsourced Mobile Video Streaming
• Stein’s Method for the Single Server Queue in Heavy Traffic
• Modeling the Random Orientation of Mobile Devices: Measurement, Analysis and LiFi Use Case
• Performance Reproduction and Prediction of Selected Dynamic Loop Scheduling Experiments
• Anime Style Space Exploration Using Metric Learning and Generative Adversarial Networks
• Comparing Two Partitions of Non-Equal Sets of Units
• Number of Vertices of the Polytope of Integer Partitions and Factorization of the Partitioned Number
• Adversarial Attacks on Classification Models for Graphs
• A Tensor-Based Sub-Mode Coordinate Algorithm for Stock Prediction
• A New Efficient Explicit Scheme of Order $1.5$ for SDE with Super-linear Drift Coefficient
• Massive MIMO with Spatially Correlated Rician Fading Channels
• Implicit Probabilistic Integrators for ODEs
• Uplink Spectral Efficiency of Massive MIMO with Spatially Correlated Rician Fading
• Aff2Vec: Affect–Enriched Distributional Word Representations
• A Nonconvex Projection Method for Robust PCA
• Stochastic Gradient Descent for Stochastic Doubly-Nonconvex Composite Optimization
• Can Hardware Distortion Correlation be Neglected When Analyzing Uplink SE in Massive MIMO
• Stochastic maximum principle for equations with delay: the non-convex case
• Multiple-Step Greedy Policies in Online and Approximate Reinforcement Learning
• A new dataset and model for learning to understand navigational instructions
• MorphNet: A sequence-to-sequence model that combines morphological analysis and disambiguation
• Large deviations for intersection measures of some Markov processes
• Detection of Sensor Attack and Resilient State Estimation for Uniformly Observable Nonlinear Systems having Redundant Sensors
• Relating Leverage Scores and Density using Regularized Christoffel Functions
• Quantizing Convolutional Neural Networks for Low-Power High-Throughput Inference Engines
• Coarse-to-Fine Salient Object Detection with Low-Rank Matrix Recovery
• DEEPEYE: A Compact and Accurate Video Comprehension at Terminal Devices Compressed with Quantization and Tensorization
• Event-based Convolutional Networks for Object Detection in Neuromorphic Cameras
• Adaptive Neighborhood Resizing for Stochastic Reachability in Multi-Agent Systems
• Category coding with neural network application
• Batch-Instance Normalization for Adaptively Style-Invariant Neural Networks
• Multi-View Stereo with Asymmetric Checkerboard Propagation and Multi-Hypothesis Joint View Selection
• Stochastic Primal-Dual Algorithm for Distributed Gradient Temporal Difference Learning
• Distributed Convex Optimization With Coupling Constraints Over Time-Varying Directed Graphs
• Imitating Latent Policies from Observation
• Frank-Wolfe Stein Sampling
• Quickshift++: Provably Good Initializations for Sample-Based Mean Shift
• Class Representative Autoencoder for Low Resolution Multi-Spectral Gender Classification
• Unsupervised Deep Context Prediction for Background Foreground Separation
• Noisy Multiparameter Quantum Bounds
• Phase retrieval from the magnitudes of affine measurements
• SmoothOut: Smoothing Out Sharp Minima for Generalization in Large-Batch Deep Learning
• Predicting Electricity Outages Caused by Convective Storms
• Generative Adversarial Examples
• Improving Aspect Term Extraction with Bidirectional Dependency Tree Representation
• DeepPhys: Video-Based Physiological Measurement Using Convolutional Attention Networks
• How Many Samples are Needed to Learn a Convolutional Neural Network
• Sentence Modeling via Multiple Word Embeddings and Multi-level Comparison for Semantic Textual Similarity
• Learning with Non-Convex Truncated Losses by SGD
• Flow polynomials of a signed graph
• Noncoherent Short-Packet Communication via Modulation on Conjugated Zeros
• GSAE: an autoencoder with embedded gene-set nodes for genomics functional characterization
• Spherical Convolutional Neural Network for 3D Point Clouds
• Learning Device Models with Recurrent Neural Networks
• A $\frac{5}{2}$-Approximation Algorithm for Coloring Rooted Subtrees of a Degree $3$ Tree
• Hybrid Macro/Micro Level Backpropagation for Training Deep Spiking Neural Networks
• Modes of wall induced granular crystallisation in vibrational packing
• Featurized Bidirectional GAN: Adversarial Defense via Adversarially Learned Semantic Inference
• Over-Sampling Codebook-Based Hybrid Minimum Sum-Mean-Square-Error Precoding for Millimeter-Wave 3D-MIMO
• On Carleman and Observability Estimates for Wave Equations on Time-Dependent Domains
• Knowledgeable Reader: Enhancing Cloze-Style Reading Comprehension with External Commonsense Knowledge
• Squares of Tribonacci numbers
• Kernel Pre-Training in Feature Space via m-Kernels
• A Text Analysis of Federal Reserve meeting minutes
• Two-Stage Residual Inclusion under the Additive Hazards Model – An Instrumental Variable Approach with Application to SEER-Medicare Linked Data
• A Universal Music Translation Network
• Pseudo-perturbation-based Broadcast Control of Multi-agent Systems
• Projection-Free Algorithms in Statistical Estimation
• Communication-Efficient Projection-Free Algorithm for Distributed Optimization
• On the Subnet Prune and Regraft Distance
• Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels
• Generalizing Tree Probability Estimation via Bayesian Networks
• Wasserstein regularization for sparse multi-task regression
• Learning to Teach in Cooperative Multiagent Reinforcement Learning
• A Vest of the Pseudoinverse Learning Algorithm
• Utilizing Bluetooth and Adaptive Signal Control Data for Urban Arterials Safety Analysis
• Real-Time Crash Risk Analysis of Urban Arterials Incorporating Bluetooth, Weather, and Adaptive Signal Control Data
• On Maximizing Weighted Algebraic Connectivity for Synthesizing Robust Networks
• Validating WordNet Meronymy Relations using Adimen-SUMO
• An Intrinsic Approach to Formation Control of Regular Polyhedra for Reduced Attitudes
• UAV-aided Multi-Way Communications
• Low-Cost Parameterizations of Deep Convolution Neural Networks
• Targeted Adversarial Examples for Black Box Audio Systems
• Knowledge-enriched Two-layered Attention Network for Sentiment Analysis
• Learning Real-World Robot Policies by Dreaming
• Online Structured Laplace Approximations For Overcoming Catastrophic Forgetting
• Randomized Strategies for Robust Combinatorial Optimization
• Multi-layer Kernel Ridge Regression for One-class Classification
• On the structure of cube tiling codes
• Safe Policy Learning from Observations
• Cutoff for the Bernoulli-Laplace urn model with $o(n)$ swaps
• Network Learning with Local Propagation
• Large Sample Theory for Merged Data from Multiple Sources
• Improved Learning of One-hidden-layer Convolutional Neural Networks with Overlaps
• One Formalization of Virtue Ethics via Learning
• Co-existence Between a Radar System and a Massive MIMO Wireless Cellular System
• Breaking the Span Assumption Yields Fast Finite-Sum Minimization
• Conditional Inference in Pre-trained Variational Autoencoders via Cross-coding
• Adaptive Dictionary Sparse Signal Recovery Using Binary Measurements
• Knowledge Aggregation via Epsilon Model Spaces
• Two Erdős–Hajnal-type Theorems in Hypergraphs
• Unsupervised Video Object Segmentation for Deep Reinforcement Learning
• DLBI: Deep learning guided Bayesian inference for structure reconstruction of super-resolution fluorescence microscopy
• Reducing Cubic Metric of Circularly Pulse-Shaped OFDM Signals Through Constellation Shaping Optimization With Performance Constraints
• Optimising data for modelling neuronal responses
• Analysis of Outage Probability of MRC with $η-μ$ co-channel interference
• Constrained Partial Group Decoding with Max-Min Fairness for Multi-color Multi-user Visible Light Communication
• Distributed Approximation of Minimum $k$-edge-connected Spanning Subgraphs
• Selfishness need not be bad: a general proof
• Adaptive Gains to Super-Twisting Technique for Sliding Mode Design
• Dunkl jump processes: relaxation and a phase transition
Like this:
Like Loading...