Obtaining Accurate Probabilistic Causal Inference by Post-Processing Calibration
Discovery of an accurate causal Bayesian network structure from observational data can be useful in many areas of science. Often the discoveries are made under uncertainty, which can be expressed as probabilities. To guide the use of such discoveries, including directing further investigation, it is important that those probabilities be well-calibrated. In this paper, we introduce a novel framework to derive calibrated probabilities of causal relationships from observational data. The framework consists of three components: (1) an approximate method for generating initial probability estimates of the edge types for each pair of variables, (2) the availability of a relatively small number of the causal relationships in the network for which the truth status is known, which we call a calibration training set, and (3) a calibration method for using the approximate probability estimates and the calibration training set to generate calibrated probabilities for the many remaining pairs of variables. We also introduce a new calibration method based on a shallow neural network. Our experiments on simulated data support that the proposed approach improves the calibration of causal edge predictions. The results also support that the approach often improves the precision and recall of predictions.
Online Forecasting Matrix Factorization
In this paper the problem of forecasting high dimensional time series is considered. Such time series can be modeled as matrices where each column denotes a measurement. In addition, when missing values are present, low rank matrix factorization approaches are suitable for predicting future values. This paper formally defines and analyzes the forecasting problem in the online setting, i.e. where the data arrives as a stream and only a single pass is allowed. We present and analyze novel matrix factorization techniques which can learn low-dimensional embeddings effectively in an online manner. Based on these embeddings a recursive minimum mean square error estimator is derived, which learns an autoregressive model on them. Experiments with two real datasets with tens of millions of measurements show the benefits of the proposed approach.
Bayesian Nonparametric Causal Inference: Information Rates and Learning Algorithms
We investigate the problem of estimating the causal effect of a treatment on individual subjects from observational data, this is a central problem in various application domains, including healthcare, social sciences, and online advertising. Within the Neyman Rubin potential outcomes model, we use the Kullback Leibler (KL) divergence between the estimated and true distributions as a measure of accuracy of the estimate, and we define the information rate of the Bayesian causal inference procedure as the (asymptotic equivalence class of the) expected value of the KL divergence between the estimated and true distributions as a function of the number of samples. Using Fano method, we establish a fundamental limit on the information rate that can be achieved by any Bayesian estimator, and show that this fundamental limit is independent of the selection bias in the observational data. We characterize the Bayesian priors on the potential (factual and counterfactual) outcomes that achieve the optimal information rate. As a consequence, we show that a particular class of priors that have been widely used in the causal inference literature cannot achieve the optimal information rate. On the other hand, a broader class of priors can achieve the optimal information rate. We go on to propose a prior adaptation procedure (which we call the information based empirical Bayes procedure) that optimizes the Bayesian prior by maximizing an information theoretic criterion on the recovered causal effects rather than maximizing the marginal likelihood of the observed (factual) data. Building on our analysis, we construct an information optimal Bayesian causal inference algorithm.
Dropout Feature Ranking for Deep Learning Models
Deep neural networks are a promising technology achieving state-of-the-art results in biological and healthcare domains. Unfortunately, DNNs are notorious for their non-interpretability. Clinicians are averse to black boxes and thus interpretability is paramount to broadly adopting this technology. We aim to close this gap by proposing a new general feature ranking method for deep learning. We show that our method outperforms LASSO, Elastic Net, Deep Feature Selection and various heuristics on a simulated dataset. We also compare our method in a multivariate clinical time-series dataset and demonstrate our ranking rivals or outperforms other methods in Recurrent Neural Network setting. Finally, we apply our feature ranking to the Variational Autoencoder recently proposed to predict drug response in cell lines and show that it identifies meaningful genes corresponding to the drug response.
An Approximate Bayesian Long Short-Term Memory Algorithm for Outlier Detection
Long Short-Term Memory networks trained with gradient descent and back-propagation have received great success in various applications. However, point estimation of the weights of the networks is prone to over-fitting problems and lacks important uncertainty information associated with the estimation. However, exact Bayesian neural network methods are intractable and non-applicable for real-world applications. In this study, we propose an approximate estimation of the weights uncertainty using Ensemble Kalman Filter, which is easily scalable to a large number of weights. Furthermore, we optimize the covariance of the noise distribution in the ensemble update step using maximum likelihood estimation. To assess the proposed algorithm, we apply it to outlier detection in five real-world events retrieved from the Twitter platform.
Distribution Regression
Linear regression is a fundamental and popular statistical method. There are various kinds of linear regression, such as mean regression and quantile regression. In this paper, we propose a new one called distribution regression, which allows broad-spectrum of the error distribution in the linear regression. Our method uses nonparametric technique to estimate regression parameters. Our studies indicate that our method provides a better alternative than mean regression and quantile regression under many settings, particularly for asymmetrical heavy-tailed distribution or multimodal distribution of the error term. Under some regular conditions, our estimator is

-consistent and possesses the asymptotically normal distribution. The proof of the asymptotic normality of our estimator is very challenging because our nonparametric likelihood function cannot be transformed into sum of independent and identically distributed random variables. Furthermore, penalized likelihood estimator is proposed and enjoys the so-called oracle property with diverging number of parameters. Numerical studies also demonstrate the effectiveness and the flexibility of the proposed method.
Merging $K$-means with hierarchical clustering for identifying general-shaped groups
Clustering partitions a dataset such that observations placed together in a group are similar but different from those in other groups. Hierarchical and

-means clustering are two approaches but have different strengths and weaknesses. For instance, hierarchical clustering identifies groups in a tree-like structure but suffers from computational complexity in large datasets while
-means clustering is efficient but designed to identify homogeneous spherically-shaped clusters. We present a hybrid non-parametric clustering approach that amalgamates the two methods to identify general-shaped clusters and that can be applied to larger datasets. Specifically, we first partition the dataset into spherical groups using
-means. We next merge these groups using hierarchical methods with a data-driven distance measure as a stopping criterion. Our proposal has the potential to reveal groups with general shapes and structure in a dataset. We demonstrate good performance on several simulated and real datasets.
Transfer Regression via Pairwise Similarity Regularization
Transfer learning methods address the situation where little labeled training data from the ‘target’ problem exists, but much training data from a related ‘source’ domain is available. However, the overwhelming majority of transfer learning methods are designed for simple settings where the source and target predictive functions are almost identical, limiting the applicability of transfer learning methods to real world data. We propose a novel, weaker, property of the source domain that can be transferred even when the source and target predictive functions diverge. Our method assumes the source and target functions share a Pairwise Similarity property, where if the source function makes similar predictions on a pair of instances, then so will the target function. We propose Pairwise Similarity Regularization Transfer, a flexible graph-based regularization framework which can incorporate this modeling assumption into standard supervised learning algorithms. We show how users can encode domain knowledge into our regularizer in the form of spatial continuity, pairwise ‘similarity constraints’ and how our method can be scaled to large data sets using the Nystrom approximation. Finally, we present positive and negative results on real and synthetic data sets and discuss when our Pairwise Similarity transfer assumption seems to hold in practice.
Towards Collaborative Conceptual Exploration
In domains with high knowledge distribution a natural objective is to create principle foundations for collaborative interactive learning environments. We present a first mathematical characterization of a collaborative learning group, a consortium, based on closure systems of attribute sets and the well-known attribute exploration algorithm from formal concept analysis. To this end, we introduce (weak) local experts for subdomains of a given knowledge domain. These entities are able to refute and potentially accept a given (implicational) query for some closure system that is a restriction of the whole domain. On this we build up a consortial expert and show first insights about the ability of such an expert to answer queries. Furthermore, we depict techniques on how to cope with falsely accepted implications and on combining counterexamples. Using notions from combinatorial design theory we further expand those insights as far as providing first results on the decidability problem if a given consortium is able to explore some target domain. Applications in conceptual knowledge acquisition as well as in collaborative interactive ontology learning are at hand.
How Intelligent is your Intelligent Robot?
How intelligent is robot A compared with robot B? And how intelligent are robots A and B compared with animals (or plants) X and Y? These are both interesting and deeply challenging questions. In this paper we address the question ‘how intelligent is your intelligent robot?’ by proposing that embodied intelligence emerges from the interaction and integration of four different and distinct kinds of intelligence. We then suggest a simple diagrammatic representation on which these kinds of intelligence are shown as four axes in a star diagram. A crude qualitative comparison of the intelligence graphs of animals and robots both exposes and helps to explain the chronic intelligence deficit of intelligent robots. Finally we examine the options for determining numerical values for the four kinds of intelligence in an effort to move toward a quantifiable intelligence vector.
Weighted Data Normalization Based on Eigenvalues for Artificial Neural Network Classification
Artificial neural network (ANN) is a very useful tool in solving learning problems. Boosting the performances of ANN can be mainly concluded from two aspects: optimizing the architecture of ANN and normalizing the raw data for ANN. In this paper, a novel method which improves the effects of ANN by preprocessing the raw data is proposed. It totally leverages the fact that different features should play different roles. The raw data set is firstly preprocessed by principle component analysis (PCA), and then its principle components are weighted by their corresponding eigenvalues. Several aspects of analysis are carried out to analyze its theory and the applicable occasions. Three classification problems are launched by an active learning algorithm to verify the proposed method. From the empirical results, conclusion comes to the fact that the proposed method can significantly improve the performance of ANN.
Comparative Opinion Mining: A Review
Opinion mining refers to the use of natural language processing, text analysis and computational linguistics to identify and extract subjective information in textual material. Opinion mining, also known as sentiment analysis, has received a lot of attention in recent times, as it provides a number of tools to analyse the public opinion on a number of different topics. Comparative opinion mining is a subfield of opinion mining that deals with identifying and extracting information that is expressed in a comparative form (e.g.~’paper X is better than the Y’). Comparative opinion mining plays a very important role when ones tries to evaluate something, as it provides a reference point for the comparison. This paper provides a review of the area of comparative opinion mining. It is the first review that cover specifically this topic as all previous reviews dealt mostly with general opinion mining. This survey covers comparative opinion mining from two different angles. One from perspective of techniques and the other from perspective of comparative opinion elements. It also incorporates preprocessing tools as well as dataset that were used by the past researchers that can be useful to the future researchers in the field of comparative opinion mining.
Change points, memory and epidemic spreading in temporal networks
Dynamic networks exhibit temporal patterns that vary across different time scales, all of which can potentially affect processes that take place on the network. However, most data-driven approaches used to model time-varying networks attempt to capture only a single characteristic time scale in isolation — typically associated with the short-time memory of a Markov chain or with long-time abrupt changes caused by external or systemic events. Here we propose a unified approach to model both aspects simultaneously, detecting short and long-time behaviors of temporal networks. We do so by developing an arbitrary-order mixed Markov model with change points, and using a nonparametric Bayesian formulation that allows the Markov order and the position of change points to be determined from data without overfitting. In addition, we evaluate the quality of the multiscale model in its capacity to reproduce the spreading of epidemics on the temporal network, and we show that describing multiple time scales simultaneously has a synergistic effect, where statistically significant features are uncovered that otherwise would remain hidden by treating each time scale independently.
Nearly optimal Bayesian Shrinkage for High Dimensional Regression
During the past decade, shrinkage priors have received much attention in Bayesian analysis of high-dimensional data. In this paper, we study the problem for high-dimensional linear regression models. We show that if the shrinkage prior has a heavy and flat tail, and allocates a sufficiently large probability mass in a very small neighborhood of zero, then its posterior properties are as good as those of the spike-and-slab prior. While enjoying its efficiency in Bayesian computation, the shrinkage prior can lead to a nearly optimal contraction rate and selection consistency as the spike-and-slab prior. Our numerical results show that under posterior consistency, Bayesian methods can yield much better results in variable selection than the regularization methods, such as Lasso and SCAD. We also establish a Bernstein von-Mises type results comparable to Castillo et al (2015), this result leads to a convenient way to quantify uncertainties of the regression coefficient estimates, which has been beyond the ability of regularization methods.
Structured Latent Factor Analysis for Large-scale Data: Identifiability, Estimability, and Their Implications
Latent factor models are widely used to measure unobserved latent traits in social and behavioral sciences, including psychology, education, and marketing. When used in a confirmatory manner, design information is incorporated, yielding structured (confirmatory) latent factor models. Motivated by the applications of latent factor models to large-scale measurements which consist of many manifest variables (e.g. test items) and a large sample size, we study the properties of structured latent factor models under an asymptotic setting where both the number of manifest variables and the sample size grow to infinity. Specifically, under such an asymptotic regime, we provide a definition of the structural identifiability of the latent factors and establish necessary and sufficient conditions on the measurement design that ensure the structural identifiability under a general family of structured latent factor models. In addition, we propose an estimator that can consistently recover the latent factors under mild conditions. This estimator can be efficiently computed through parallel computing. Our results shed lights on the design of large-scale measurement and have important implications on measurement validity. The properties of the proposed estimator are verified through simulation studies.
Mean Field Residual Networks: On the Edge of Chaos
We study randomly initialized residual networks using mean field theory and the theory of difference equations. Classical feedforward neural networks, such as those with tanh activations, exhibit exponential behavior on the average when propagating inputs forward or gradients backward. The exponential forward dynamics causes rapid collapsing of the input space geometry, while the exponential backward dynamics causes drastic vanishing or exploding gradients. We show, in contrast, that by adding skip connections, the network will, depending on the nonlinearity, adopt subexponential forward and backward dynamics, and in many cases in fact polynomial. The exponents of these polynomials are obtained through analytic methods and proved and verified empirically to be correct. In terms of the ‘edge of chaos’ hypothesis, these subexponential and polynomial laws allow residual networks to ‘hover over the boundary between stability and chaos,’ thus preserving the geometry of the input space and the gradient information flow. In our experiments, for each activation function we study here, we initialize residual networks with different hyperparameters and train them on MNIST. Remarkably, our initialization time theory can accurately predict test time performance of these networks, by tracking either the expected amount of gradient explosion or the expected squared distance between the images of two input vectors. Importantly, we show, theoretically as well as empirically, that common initializations such as the Xavier or the He schemes are not optimal for residual networks, because the optimal initialization variances depend on the depth. Finally, we have made mathematical contributions by deriving several new identities for the kernels of powers of ReLU functions by relating them to the zeroth Bessel function of the second kind.
Human-Centric Data Cleaning [Vision]
Data Cleaning refers to the process of detecting and fixing errors in the data. Human involvement is instrumental at several stages of this process, e.g., to identify and repair errors, to validate computed repairs, etc. There is currently a plethora of data cleaning algorithms addressing a wide range of data errors (e.g., detecting duplicates, violations of integrity constraints, missing values, etc.). Many of these algorithms involve a human in the loop, however, this latter is usually coupled to the underlying cleaning algorithms. There is currently no end-to-end data cleaning framework that systematically involves humans in the cleaning pipeline regardless of the underlying cleaning algorithms. In this paper, we highlight key challenges that need to be addressed to realize such a framework. We present a design vision and discuss scenarios that motivate the need for such a framework to judiciously assist humans in the cleaning process. Finally, we present directions to implement such a framework.
Kernel Regression with Sparse Metric Learning
Kernel regression is a popular non-parametric fitting technique. It aims at learning a function which estimates the targets for test inputs as precise as possible. Generally, the function value for a test input is estimated by a weighted average of the surrounding training examples. The weights are typically computed by a distance-based kernel function and they strongly depend on the distances between examples. In this paper, we first review the latest developments of sparse metric learning and kernel regression. Then a novel kernel regression method involving sparse metric learning, which is called kernel regression with sparse metric learning (KR

SML), is proposed. The sparse kernel regression model is established by enforcing a mixed
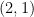
-norm regularization over the metric matrix. It learns a Mahalanobis distance metric by a gradient descent procedure, which can simultaneously conduct dimensionality reduction and lead to good prediction results. Our work is the first to combine kernel regression with sparse metric learning. To verify the effectiveness of the proposed method, it is evaluated on 19 data sets for regression. Furthermore, the new method is also applied to solving practical problems of forecasting short-term traffic flows. In the end, we compare the proposed method with other three related kernel regression methods on all test data sets under two criterions. Experimental results show that the proposed method is much more competitive.
Deep Collaborative Autoencoder for Recommender Systems: A Unified Framework for Explicit and Implicit Feedback
In recent years, deep neural networks have yielded state-of-the-art performance on several tasks. Although some recent works have focused on combining deep learning with recommendation, we highlight three issues of existing works. First, most works perform deep content feature learning and resort to matrix factorization, which cannot effectively model the highly complex user-item interaction function. Second, due to the difficulty on training deep neural networks, existing models utilize a shallow architecture, and thus limit the expressiveness potential of deep learning. Third, neural network models are easy to overfit on the implicit setting, because negative interactions are not taken into account. To tackle these issues, we present a novel recommender framework called Deep Collaborative Autoencoder (DCAE) for both explicit feedback and implicit feedback, which can effectively capture the relationship between interactions via its non-linear expressiveness. To optimize the deep architecture of DCAE, we develop a three-stage pre-training mechanism that combines supervised and unsupervised feature learning. Moreover, we propose a popularity-based error reweighting module and a sparsity-aware data-augmentation strategy for DCAE to prevent overfitting on the implicit setting. Extensive experiments on three real-world datasets demonstrate that DCAE can significantly advance the state-of-the-art.
On Connecting Stochastic Gradient MCMC and Differential Privacy
Significant success has been realized recently on applying machine learning to real-world applications. There have also been corresponding concerns on the privacy of training data, which relates to data security and confidentiality issues. Differential privacy provides a principled and rigorous privacy guarantee on machine learning models. While it is common to design a model satisfying a required differential-privacy property by injecting noise, it is generally hard to balance the trade-off between privacy and utility. We show that stochastic gradient Markov chain Monte Carlo (SG-MCMC) — a class of scalable Bayesian posterior sampling algorithms proposed recently — satisfies strong differential privacy with carefully chosen step sizes. We develop theory on the performance of the proposed differentially-private SG-MCMC method. We conduct experiments to support our analysis and show that a standard SG-MCMC sampler without any modification (under a default setting) can reach state-of-the-art performance in terms of both privacy and utility on Bayesian learning.
SAGA: A Submodular Greedy Algorithm For Group Recommendation
In this paper, we propose a unified framework and an algorithm for the problem of group recommendation where a fixed number of items or alternatives can be recommended to a group of users. The problem of group recommendation arises naturally in many real world contexts, and is closely related to the budgeted social choice problem studied in economics. We frame the group recommendation problem as choosing a subgraph with the largest group consensus score in a completely connected graph defined over the item affinity matrix. We propose a fast greedy algorithm with strong theoretical guarantees, and show that the proposed algorithm compares favorably to the state-of-the-art group recommendation algorithms according to commonly used relevance and coverage performance measures on benchmark dataset.
Strongly Hierarchical Factorization Machines and ANOVA Kernel Regression
High-order parametric models that include terms for feature interactions are applied to various data min- ing tasks, where ground truth depends on interactions of features. However, with sparse data, the high- dimensional parameters for feature interactions often face three issues: expensive computation, difficulty in parameter estimation and lack of structure. Previous work has proposed approaches which can partially re- solve the three issues. In particular, models with fac- torized parameters (e.g. Factorization Machines) and sparse learning algorithms (e.g. FTRL-Proximal) can tackle the first two issues but fail to address the third. Regarding to unstructured parameters, constraints or complicated regularization terms are applied such that hierarchical structures can be imposed. However, these methods make the optimization problem more challeng- ing. In this work, we propose Strongly Hierarchical Factorization Machines and ANOVA kernel regression where all the three issues can be addressed without making the optimization problem more difficult. Ex- perimental results show the proposed models signifi- cantly outperform the state-of-the-art in two data min- ing tasks: cold-start user response time prediction and stock volatility prediction.
Optimal Clustering Algorithms in Block Markov Chains
This paper considers cluster detection in Block Markov Chains (BMCs). These Markov chains are characterized by a block structure in their transition matrix. More precisely, the

possible states are divided into a finite number of
groups or clusters, such that states in the same cluster exhibit the same transition rates to other states. One observes a trajectory of the Markov chain, and the objective is to recover, from this observation only, the (initially unknown) clusters. In this paper we devise a clustering procedure that accurately, efficiently, and provably detects the clusters. We first derive a fundamental information-theoretical lower bound on the detection error rate satisfied under any clustering algorithm. This bound identifies the parameters of the BMC, and trajectory lengths, for which it is possible to accurately detect the clusters. We next develop two clustering algorithms that can together accurately recover the cluster structure from the shortest possible trajectories, whenever the parameters allow detection. These algorithms thus reach the fundamental detectability limit, and are optimal in that sense.
Scalable Prototype Selection by Genetic Algorithms and Hashing
Classification in the dissimilarity space has become a very active research area since it provides a possibility to learn from data given in the form of pairwise non-metric dissimilarities, which otherwise would be difficult to cope with. The selection of prototypes is a key step for the further creation of the space. However, despite previous efforts to find good prototypes, how to select the best representation set remains an open issue. In this paper we proposed scalable methods to select the set of prototypes out of very large datasets. The methods are based on genetic algorithms, dissimilarity-based hashing, and two different unsupervised and supervised scalable criteria. The unsupervised criterion is based on the Minimum Spanning Tree of the graph created by the prototypes as nodes and the dissimilarities as edges. The supervised criterion is based on counting matching labels of objects and their closest prototypes. The suitability of these type of algorithms is analyzed for the specific case of dissimilarity representations. The experimental results showed that the methods select good prototypes taking advantage of the large datasets, and they do so at low runtimes.
FogLearn: Leveraging Fog-based Machine Learning for Smart System Big Data Analytics
Big data analytics with the cloud computing are one of the emerging area for processing and analytics. Fog computing is the paradigm where fog devices help to reduce latency and increase throughput for assisting at the edge of the client. This paper discussed the emergence of fog computing for mining analytics in big data from geospatial and medical health applications. This paper proposed and developed fog computing based framework i.e. FogLearn for application of K-means clustering in Ganga River Basin Management and real world feature data for detecting diabetes patients suffering from diabetes mellitus. Proposed architecture employed machine learning on deep learning framework for analysis of pathological feature data that obtained from smart watches worn by the patients with diabetes and geographical parameters of River Ganga basin geospatial database. The results showed that fog computing hold an immense promise for analysis of medical and geospatial big data.
Rate of convergence to alpha stable law using Zolotarev distance : technical report
This paper considers the question of the rate of convergence to
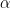
– stable laws, using arguments based on the Zolotarev distance to prove bounds. We provide a rate of convergence to
-stable random variable where 1 <
< 2, in the generalized CLT, that is, for the partial sums of independent identically distributed random variables which are not assumed to be square integrable. This work is a technical report based on the Zolotarev paper in [1].
• Analysis and Implementation of a Hourly Billing Mechanism for Demand Response Management
• A Data Colocation Grid Framework for Big Data Medical Image Processing – Backend Design
• Rough controls for Schroedinger operators on 2-tori
• Find the Conversation Killers: a Predictive Study of Thread-ending Posts
• The Geometry of Continuous Latent Space Models for Network Data
• Least-Squares Temporal Difference Learning for the Linear Quadratic Regulator
• Emo, Love, and God: Making Sense of Urban Dictionary, a Crowd-Sourced Online Dictionary
• A short variational proof of equivalence between policy gradients and soft Q learning
• A counterexample to Strassen’s direct sum conjecture
• Enumeration of words that contain the pattern 123 exactly once
• Mixtures of Matrix Variate Bilinear Factor Analyzers
• Quasi-maximum likelihood estimation for cointegrated solutions of continuous-time state space models observed at discrete time points
• Modular periodicity of the Euler numbers and a sequence by Arnold
• Modeling Spatial Overdispersion with the Generalized Waring Process
• Relevance Scoring of Triples Using Ordinal Logistic Classification – The Celosia Triple Scorer at WSDM Cup 2017
• RelSifter: Scoring Triples from Type-like Relations — The Samphire Triple Scorer at WSDM Cup 2017
• Boundary-sensitive Network for Portrait Segmentation
• Tightness of the Ising-Kac model on the two-dimensional torus
• Estimating Node Similarity by Sampling Streaming Bipartite Graphs
• Study of Iterative Detection and Decoding for Large-Scale MIMO Systems with 1-Bit ADCs
• Aerial Spectral Super-Resolution using Conditional Adversarial Networks
• Sheaves and Duality in the Two-Vertex Graph Riemann-Roch Theorem
• Interpretable Counting for Visual Question Answering
• Angle-Based Models for Ranking Data
• Online coloring a token graph
• On the Universality of Memcomputing Machines
• Freebase-triples: A Methodology for Processing the Freebase Data Dumps
• Variational Autoencoders for Learning Latent Representations of Speech Emotion
• Distance Labelings on Random Power Law Graphs
• Persistence of the Jordan center in Random Growing Trees
• Query-limited Black-box Attacks to Classifiers
• Towards Structured Analysis of Broadcast Badminton Videos
• The Parable of the Fruit Sellers Or, A Game of Random Variables
• Multiaccess Communication via a Broadcast Approach Adapted to the Multiuser Channel
• Finding the Submodularity Hidden in Symmetric Difference
• Denoising of 3D magnetic resonance images with multi-channel residual learning of convolutional neural network
• Combining Weakly and Webly Supervised Learning for Classifying Food Images
• On the Individual Surrogate Paradox
• Quantized Precoding for Multi-Antenna Downlink Channels with MAGIQ
• Circle patterns and critical Ising models
• Scene-Specific Pedestrian Detection Based on Parallel Vision
• Electric vehicle charging: a queueing approach
• Cointegration and representation of integrated autoregressive processes in function spaces
• Cartesian trees and Lyndon trees
• On Estimation of Conditional Modes Using Multiple Quantile Regressions
• Complete MDP convolutional codes
• Texture Object Segmentation Based on Affine Invariant Texture Detection
• On Grundy total domination number in product graphs
• Stochastic Geometry Modeling and Analysis of Single- and Multi-Cluster Wireless Networks
• Parallelogram polyominoes, partially labelled Dyck paths, and the Delta conjecture (FULL VERSION)
• Are words easier to learn from infant- than adult-directed speech? A quantitative corpus-based investigation
• A Low-Rank Approach to Off-The-Grid Sparse Deconvolution
• Non-asymptotic estimation for Bell function, with probabilistic applications
• LEPA: Incentivizing Long-term Privacy-preserving Data Aggregation in Crowdsensing
• The tractability frontier of well-designed SPARQL queries
• Inhibition as a determinant of activity and criticality in dynamical networks
• Distributed Coupled Multi-Agent Stochastic Optimization
• Spatial Motifs for Device-to-Device Network Analysis (DNA) in Cellular Networks
• A Framework for Enriching Lexical Semantic Resources with Distributional Semantics
• A Benchmark for Dose Finding Studies with Continuous Outcomes
• Large-Scale Object Discovery and Detector Adaptation from Unlabeled Video
• Exponentially convergent data assimilation algorithm for Navier-Stokes equations
• Optimization and Testing in Linear Non-Gaussian Component Analysis
• Texture Synthesis with Recurrent Variational Auto-Encoder
• Dual Long Short-Term Memory Networks for Sub-Character Representation Learning
• Framework of Channel Estimation for Hybrid Analog-and-Digital Processing Enabled Massive MIMO Communications
• Hypergraphic polytopes: combinatorial properties and antipode
• A Low-Cost Robust Distributed Linearly Constrained Beamformer for Wireless Acoustic Sensor Networks with Arbitrary Topology
• Let’s Make Block Coordinate Descent Go Fast: Faster Greedy Rules, Message-Passing, Active-Set Complexity, and Superlinear Convergence
• Neural Network Multitask Learning for Traffic Flow Forecasting
• Biological Systems as Heterogeneous Information Networks: A Mini-review and Perspectives
• On Irregular Linear Quadratic Control: Stochastic Case
• Asymptotically Stable Drift and Minorization for Markov Chains with Application to Albert and Chib’s Algorithm
• Use of Generative Adversarial Network for Cross-Domain Change Detection
• Pentagons in triangle-free graphs
• A Data-driven Approach to Multi-event Analytics in Large-scale Power Systems Using Factor Model
• The Solution of the Kadison-Singer Problem
• Predicting Rich Drug-Drug Interactions via Biomedical Knowledge Graphs and Text Jointly Embedding
• Blind Image Deblurring via Reweighted Graph Total Variation
• Lectures on Randomized Numerical Linear Algebra
• Traffic Flow Forecasting Using a Spatio-Temporal Bayesian Network Predictor
• Efficient data augmentation techniques for Gaussian state space models
• Asymptotic Behaviors for Critical Branching Processes with Immigration
• EXONEST: The Bayesian Exoplanetary Explorer
• PuRe: Robust pupil detection for real-time pervasive eye tracking
• Hopf algebras for matroids over hyperfields
• Walrasian Dynamics in Multi-unit Markets
• Building a Sentiment Corpus of Tweets in Brazilian Portuguese
• Deep Learning for Massive MIMO CSI Feedback
• The Support of Integer Optimal Solutions
• Deterministic Sampling of Expensive Posteriors Using Minimum Energy Designs
• Congruences modulo $4$ for Rogers–Ramanujan–Gordon type overpartitions
• Limits of maximal monotone operators driven by their representative functions
• Semi-automatic definite description annotation: a first report
• On tractable query evaluation for SPARQL
• A multi-material transport problem and its convex relaxation via rectifiable $G$-currents
• Judicious Judgment Meets Unsettling Updating: Dilation, Sure Loss, and Simpson’s Paradox
• Directed polymers on a disordered tree with a defect subtree
• Towards Profit Maximization for Online Social Network Providers
• Spurious Local Minima are Common in Two-Layer ReLU Neural Networks
• The Better Half of Selling Separately
• Robust functional estimation in the multivariate partial linear model
• The Minimal Position of a Stable Branching Random Walk
• Forward Backward SDEs in Weak Formulation
• On Statistical Optimality of Variational Bayes
• New families of Hadamard matrices with maximum excess
• Learning to Run with Actor-Critic Ensemble
• Soliton cellular automata associated with infinite reduced words
• Application of the Fourier Method to the Mean-Square Approximation of Multiple Ito and Stratonovich Stochastic Integrals
• Leveraging Native Language Speech for Accent Identification using Deep Siamese Networks
• Android Malware Detection using Deep Learning on API Method Sequences
• Planar graphs without 4-cycles adjacent to triangles are DP-4-colorable
• RIDI: Robust IMU Double Integration
• Efficient Algorithms for t-distributed Stochastic Neighborhood Embedding
• Stochastic Multi-armed Bandits in Constant Space
• DMSS: A Robust Deep Meta Structure Based Similarity Measure in Heterogeneous Information Networks
• HelPal: A Search System for Mobile Crowd Service
• Null Dynamical State Models of Human Cognitive Dysfunction
• Topological Representation of the Transit Sets of k-Point Crossover Operators
• Disentangled Representation Learning for Domain Adaptation and Style Transfer
• Minimal Ordered Ramsey Graphs
• Secure Network Code for Adaptive and Active Attacks with No-Randomness in Intermediate Nodes
• Large Deviations and Fluctuation Theorem for Selectively Decoupled Measures on Shift Spaces
• Polynomial functions as splines
• Automatic Image Cropping for Visual Aesthetic Enhancement Using Deep Neural Networks and Cascaded Regression
• Leveraging Long and Short-term Information in Content-aware Movie Recommendation
• Optimal detection and error exponents for hidden multi-state processes via random duration model approach
• Uniform Rates of Convergence of Some Representations of Extremes : a first approach
• Measuring inequality: application of semi-parametric methods to real life data
• Space-Filling Designs for Robustness Experiments
• Deep Blind Image Inpainting
• Guesswork Subject to a Total Entropy Budget
• An Exact and Robust Conformal Inference Method for Counterfactual and Synthetic Controls
• A Novel Recursive Construction for Coded Caching Schemes
• Brain Tumor Segmentation Based on Refined Fully Convolutional Neural Networks with A Hierarchical Dice Loss
• SoA-Fog: Secure Service-Oriented Edge Computing Architecture for Smart Health Big Data Analytics
• HEPDrone: a toolkit for the mass application of machine learning in High Energy Physics
• Overcomplete Frame Thresholding for Acoustic Scene Analysis
• A large-population limit for a Markovian model of group-structured populations
• On Gabor orthonormal bases over finite prime fields
• Improved Distributed Algorithms for Exact Shortest Paths
• Generative Adversarial Nets for Multiple Text Corpora
• A Random Block-Coordinate Douglas-Rachford Splitting Method with Low Computational Complexity for Binary Logistic Regression
• Enhancement of light transmission through randomly located copper nano-islands near the percolation threshold
• Reduced Bias for respondent driven sampling: accounting for non-uniform edge sampling probabilities in people who inject drugs in Mauritius
• Variational Bayes Estimation of Time Series Copulas for Multivariate Ordinal and Mixed Data
• Technical Report on Deploying a highly secured OpenStack Cloud Infrastructure using BradStack as a Case Study
• Deep Meta Learning for Real-Time Visual Tracking based on Target-Specific Feature Space
• Cooperative Transmission for Physical Layer Security by Exploring Social Awareness
• Segmenting Sky Pixels in Images
• Computer Algebra Methods in Control Systems
• Near-linear Time Algorithms for Approximate Minimum Degree Spanning Trees
• High-throughput Binding Affinity Calculations at Extreme Scales
• Orbits of Plane Partitions of Exceptional Lie Type
• Detection of the Prodromal Phase of Bipolar Disorder from Psychological and Phonological Aspects in Social Media
• Detect-and-Track: Efficient Pose Estimation in Videos
• Actionable Email Intent Modeling with Reparametrized RNNs
• An expectation-based space-time scan statistic for ZIP-distributed data
• The Robust Manifold Defense: Adversarial Training using Generative Models
• Approximation methods for piecewise deterministic Markov processes and their costs
• Algorithmic Regularization in Over-parameterized Matrix Recovery
• Chaos-guided Input Structuring for Improved Learning in Recurrent Neural Networks
• Sampling alien species inside and outside protected areas: does it matter?
• Aircraft Fuselage Defect Detection using Deep Neural Networks
• Large-Scale 3D Scene Classification With Multi-View Volumetric CNN
• On the Euler-Maruyama scheme for spectrally one-sided Lévy driven SDEs with Hölder continuous coefficients
• Identification and Estimation of Nonseparable Panel Data Models
• Monotone dynamical systems with dense periodic points
• Simple models for multivariate regular variations and the Hüsler-Reiss Pareto distribution
• A Real-Time Autonomous Highway Accident Detection Model Based on Big Data Processing and Computational Intelligence
• Space-Efficient Algorithms for Longest Increasing Subsequence
• Topological orders of strongly interacting particles
• Intention Games
• Perfect State Transfer on Abelian Cayley Graphs
• Arithmetic Properties of Odd Ranks and $k$-Marked Odd Durfee Symbols
• On the Hamilton-Waterloo problem: the case of two cycles sizes of different parity
• A model for interpreting social interactions in local image regions
• Zero-Shot Learning via Latent Space Encoding
• Stable regularity for relational structures
• Who is Smarter? Intelligence Measure of Learning-based Cognitive Radios
• Formulae for the conjugate and the $\varepsilon$-subdifferential of the supremum function
• Building Robust Deep Neural Networks for Road Sign Detection
Like this:
Like Loading...