Causal inference for interfering units with cluster and population level treatment allocation programs
Interference arises when an individual’s potential outcome depends on the individual treatment level, but also on the treatment level of others. A common assumption in the causal inference literature in the presence of interference is partial interference, implying that the population can be partitioned in clusters of individuals whose potential outcomes only depend on the treatment of units within the same cluster. Previous literature has defined average potential outcomes under counterfactual scenarios where treatments are randomly allocated to units within a cluster. However, within clusters there may be units that are more or less likely to receive treatment based on covariates or neighbors’ treatment. We define estimands that describe average potential outcomes for realistic counterfactual treatment allocation programs taking into consideration the units’ covariates, as well as dependence between units’ treatment assignment. We discuss these estimands, propose unbiased estimators and derive asymptotic results as the number of clusters grows. Finally, we estimate effects in a comparative effectiveness study of power plant emission reduction technologies on ambient ozone pollution.
Mandolin: A Knowledge Discovery Framework for the Web of Data
Markov Logic Networks join probabilistic modeling with first-order logic and have been shown to integrate well with the Semantic Web foundations. While several approaches have been devised to tackle the subproblems of rule mining, grounding, and inference, no comprehensive workflow has been proposed so far. In this paper, we fill this gap by introducing a framework called Mandolin, which implements a workflow for knowledge discovery specifically on RDF datasets. Our framework imports knowledge from referenced graphs, creates similarity relationships among similar literals, and relies on state-of-the-art techniques for rule mining, grounding, and inference computation. We show that our best configuration scales well and achieves at least comparable results with respect to other statistical-relational-learning algorithms on link prediction.
Implicit Weight Uncertainty in Neural Networks
We interpret HyperNetworks within the framework of variational inference within implicit distributions. Our method, Bayes by Hypernet, is able to model a richer variational distribution than previous methods. Experiments show that it achieves comparable predictive performance on the MNIST classification task while providing higher predictive uncertainties compared to MC-Dropout and regular maximum likelihood training.
BoostClean: Automated Error Detection and Repair for Machine Learning
Predictive models based on machine learning can be highly sensitive to data error. Training data are often combined with a variety of different sources, each susceptible to different types of inconsistencies, and new data streams during prediction time, the model may encounter previously unseen inconsistencies. An important class of such inconsistencies is domain value violations that occur when an attribute value is outside of an allowed domain. We explore automatically detecting and repairing such violations by leveraging the often available clean test labels to determine whether a given detection and repair combination will improve model accuracy. We present BoostClean which automatically selects an ensemble of error detection and repair combinations using statistical boosting. BoostClean selects this ensemble from an extensible library that is pre-populated general detection functions, including a novel detector based on the Word2Vec deep learning model, which detects errors across a diverse set of domains. Our evaluation on a collection of 12 datasets from Kaggle, the UCI repository, real-world data analyses, and production datasets that show that Boost- Clean can increase absolute prediction accuracy by up to 9% over the best non-ensembled alternatives. Our optimizations including parallelism, materialization, and indexing techniques show a 22.2x end-to-end speedup on a 16-core machine.
Differentially Private ANOVA Testing
Modern society generates an incredible amount of data about individuals, and releasing summary statistics about this data in a manner that provably protects individual privacy would offer a valuable resource for researchers in many fields. We present the first algorithm for analysis of variance (ANOVA) that preserves differential privacy, allowing this important statistical test to be conducted (and the results released) on databases of sensitive information. In addition to our private algorithm for the F test statistic, we show a rigorous way to compute p-values that accounts for the added noise needed to preserve privacy. Finally, we present experimental results quantifying the statistical power of this differentially private version of the test, finding that a sample of several thousand observations is frequently enough to detect variation between groups. The differentially private ANOVA algorithm is a promising approach for releasing a common test statistic that is valuable in fields in the sciences and social sciences.
Statistical Evaluation of Spectral Methods for Anomaly Detection in Networks
Monitoring of networks for anomaly detection has attracted a lot of attention in recent years especially with the rise of connected devices and social networks. This is of importance as anomaly detection could span a wide range of application, from detecting terrorist cells in counter-terrorism efforts to phishing attacks in social network circles. For this reason, numerous techniques for anomaly detection have been introduced. However, application of these techniques to more complex network models is hindered by various challenges such as the size of the network being investigated, how much apriori information is needed, the size of the anomalous graph, among others. A recent technique introduced by Miller et al, which relies on a spectral framework for anomaly detection, has the potential to address many of these challenges. In their discussion of the spectral framework, three algorithms were proposed that relied on the eigenvalues and eigenvectors of the residual matrix of a binary network. The authors demonstrated the ability to detect anomalous subgraphs that were less than 1\% of the network size. However, to date, there is little work that has been done to evaluate the statistical performance of these algorithms. This study investigates the statistical properties of the spectral methods, specifically the Chi-square and

norm algorithm proposed by Miller. We will analyze the performance of the algorithm using simulated networks and also extend the method’s application to count networks. Finally we will make some methodological improvements and recommendations to both algorithms.
The Case for Meta-Cognitive Machine Learning: On Model Entropy and Concept Formation in Deep Learning
Machine learning is usually defined in behaviourist terms, where external validation is the primary mechanism of learning. In this paper, I argue for a more holistic interpretation in which finding more probable, efficient and abstract representations is as central to learning as performance. In other words, machine learning should be extended with strategies to reason over its own learning process, leading to so-called meta-cognitive machine learning. As such, the de facto definition of machine learning should be reformulated in these intrinsically multi-objective terms, taking into account not only the task performance but also internal learning objectives. To this end, we suggest a ‘model entropy function’ to be defined that quantifies the efficiency of the internal learning processes. It is conjured that the minimization of this model entropy leads to concept formation. Besides philosophical aspects, some initial illustrations are included to support the claims.
Wasserstein Auto-Encoders
We propose the Wasserstein Auto-Encoder (WAE)—a new algorithm for building a generative model of the data distribution. WAE minimizes a penalized form of the Wasserstein distance between the model distribution and the target distribution, which leads to a different regularizer than the one used by the Variational Auto-Encoder (VAE). This regularizer encourages the encoded training distribution to match the prior. We compare our algorithm with several other techniques and show that it is a generalization of adversarial auto-encoders (AAE). Our experiments show that WAE shares many of the properties of VAEs (stable training, encoder-decoder architecture, nice latent manifold structure) while generating samples of better quality, as measured by the FID score.
Multi-label Dataless Text Classification with Topic Modeling
Manually labeling documents is tedious and expensive, but it is essential for training a traditional text classifier. In recent years, a few dataless text classification techniques have been proposed to address this problem. However, existing works mainly center on single-label classification problems, that is, each document is restricted to belonging to a single category. In this paper, we propose a novel Seed-guided Multi-label Topic Model, named SMTM. With a few seed words relevant to each category, SMTM conducts multi-label classification for a collection of documents without any labeled document. In SMTM, each category is associated with a single category-topic which covers the meaning of the category. To accommodate with multi-labeled documents, we explicitly model the category sparsity in SMTM by using spike and slab prior and weak smoothing prior. That is, without using any threshold tuning, SMTM automatically selects the relevant categories for each document. To incorporate the supervision of the seed words, we propose a seed-guided biased GPU (i.e., generalized Polya urn) sampling procedure to guide the topic inference of SMTM. Experiments on two public datasets show that SMTM achieves better classification accuracy than state-of-the-art alternatives and even outperforms supervised solutions in some scenarios.
Wider and Deeper, Cheaper and Faster: Tensorized LSTMs for Sequence Learning
Long Short-Term Memory (LSTM) is a popular approach to boosting the ability of Recurrent Neural Networks to store longer term temporal information. The capacity of an LSTM network can be increased by widening and adding layers. However, usually the former introduces additional parameters, while the latter increases the runtime. As an alternative we propose the Tensorized LSTM in which the hidden states are represented by tensors and updated via a cross-layer convolution. By increasing the tensor size, the network can be widened efficiently without additional parameters since the parameters are shared across different locations in the tensor; by delaying the output, the network can be deepened implicitly with little additional runtime since deep computations for each timestep are merged into temporal computations of the sequence. Experiments conducted on five challenging sequence learning tasks show the potential of the proposed model.
Multilayer tensor factorization with applications to recommender systems
Recommender systems have been widely adopted by electronic commerce and entertainment industries for individualized prediction and recommendation, which benefit consumers and improve business intelligence. In this article, we propose an innovative method, namely the recommendation engine of multilayers (REM), for tensor recommender systems. The proposed method utilizes the structure of a tensor response to integrate information from multiple modes, and creates an additional layer of nested latent factors to accommodate between-subjects dependency. One major advantage is that the proposed method is able to address the ‘cold-start’ issue in the absence of information from new customers, new products or new contexts. Specifically, it provides more effective recommendations through sub-group information. To achieve scalable computation, we develop a new algorithm for the proposed method, which incorporates a maximum block improvement strategy into the cyclic blockwise-coordinate-descent algorithm. In theory, we investigate both algorithmic properties for global and local convergence, along with the asymptotic consistency of estimated parameters. Finally, the proposed method is applied in simulations and IRI marketing data with 116 million observations of product sales. Numerical studies demonstrate that the proposed method outperforms existing competitors in the literature.
Strategies for Conceptual Change in Convolutional Neural Networks
A remarkable feature of human beings is their capacity for creative behaviour, referring to their ability to react to problems in ways that are novel, surprising, and useful. Transformational creativity is a form of creativity where the creative behaviour is induced by a transformation of the actor’s conceptual space, that is, the representational system with which the actor interprets its environment. In this report, we focus on ways of adapting systems of learned representations as they switch from performing one task to performing another. We describe an experimental comparison of multiple strategies for adaptation of learned features, and evaluate how effectively each of these strategies realizes the adaptation, in terms of the amount of training, and in terms of their ability to cope with restricted availability of training data. We show, among other things, that across handwritten digits, natural images, and classical music, adaptive strategies are systematically more effective than a baseline method that starts learning from scratch.
Beyond Profiling: Scaling Profiling Data Usage to Multiple Applications
Profiling techniques are used extensively at different parts of the computing stack to achieve many goals. One major goal is to make a piece of software execute more efficiently on a specific hardware platform, where efficiency spans criteria such as power, performance, resource requirements, etc. Researchers, both in academia and industry, have introduced many techniques to gather, and make use of, profiling data. However, one thing remains unchanged: making application A run more efficiently on machine 1. In this paper, we extend this criteria by asking: can profiling information of application A on machine 1 be used to make application B run more efficiently on machine 1? If so, then this means as machine 1 continues to execute more applications, it becomes better and more efficient. We present a generalized method for using profiling information gathered from the execution of programs from a limited corpus of applications to improve the performance of software from outside our corpus. As a proof of concept, we apply our technique to the specific problem of selecting the most efficient last-level-cache with which to execute an application. We were able to turn off an average of 19% of last-level-cache blocks for selected programs from PARSEC benchmark suite and only saw an average 2.8% increase in the rate of last-level cache misses.
A Survey on Dialogue Systems: Recent Advances and New Frontiers
Dialogue systems have attracted more and more attention. Recent advances on dialogue systems are overwhelmingly contributed by deep learning techniques, which have been employed to enhance a wide range of big data applications such as computer vision, natural language processing, and recommender systems. For dialogue systems, deep learning can leverage a massive amount of data to learn meaningful feature representations and response generation strategies, while requiring a minimum amount of hand-crafting. In this article, we give an overview to these recent advances on dialogue systems from various perspectives and discuss some possible research directions. In particular, we generally di- vide existing dialogue systems into task-oriented and non- task-oriented models, then detail how deep learning techniques help them with representative algorithms and finally discuss some appealing research directions that can bring the dialogue system research into a new frontier.
Active Learning for Visual Question Answering: An Empirical Study
We present an empirical study of active learning for Visual Question Answering, where a deep VQA model selects informative question-image pairs from a pool and queries an oracle for answers to maximally improve its performance under a limited query budget. Drawing analogies from human learning, we explore cramming (entropy), curiosity-driven (expected model change), and goal-driven (expected error reduction) active learning approaches, and propose a fast and effective goal-driven active learning scoring function to pick question-image pairs for deep VQA models under the Bayesian Neural Network framework. We find that deep VQA models need large amounts of training data before they can start asking informative questions. But once they do, all three approaches outperform the random selection baseline and achieve significant query savings. For the scenario where the model is allowed to ask generic questions about images but is evaluated only on specific questions (e.g., questions whose answer is either yes or no), our proposed goal-driven scoring function performs the best.
Memory-efficient Kernel PCA via Partial Matrix Sampling and Nonconvex Optimization: a Model-free Analysis of Local Minima
Kernel PCA is a widely used nonlinear dimension reduction technique in machine learning, but storing the kernel matrix is notoriously challenging when the sample size is large. Inspired by [YPCC16], where the idea of partial matrix sampling followed by nonconvex optimization is proposed for matrix completion and robust PCA, we apply a similar approach to memory-efficient Kernel PCA. In theory, with no assumptions on the kernel matrix in terms of eigenvalues or eigenvectors, we established a model-free theory for the low-rank approximation based on any local minimum of the proposed objective function. As interesting byproducts, when the underlying positive semidefinite matrix is assumed to be low-rank and highly structured, corollaries of our main theorem improve the state-of-the-art results [GLM16, GJZ17] for nonconvex matrix completion with no spurious local minima. Numerical experiments also show that our approach is competitive in terms of approximation accuracy compared to the well-known Nystr\'{o}m algorithm for Kernel PCA.
Learning Solving Procedure for Artificial Neural Network
It is expected that progress toward true artificial intelligence will be achieved through the emergence of a system that integrates representation learning and complex reasoning (LeCun et al. 2015). In response to this prediction, research has been conducted on implementing the symbolic reasoning of a von Neumann computer in an artificial neural network (Graves et al. 2016; Graves et al. 2014; Reed et al. 2015). However, these studies have many limitations in realizing neural-symbolic integration (Jaeger. 2016). Here, we present a new learning paradigm: a learning solving procedure (LSP) that learns the procedure for solving complex problems. This is not accomplished merely by learning input-output data, but by learning algorithms through a solving procedure that obtains the output as a sequence of tasks for a given input problem. The LSP neural network system not only learns simple problems of addition and multiplication, but also the algorithms of complicated problems, such as complex arithmetic expression, sorting, and Hanoi Tower. To realize this, the LSP neural network structure consists of a deep neural network and long short-term memory, which are recursively combined. Through experimentation, we demonstrate the efficiency and scalability of LSP and its validity as a mechanism of complex reasoning.
Whitening Black-Box Neural Networks
Many deployed learned models are black boxes: given input, returns output. Internal information about the model, such as the architecture, optimisation procedure, or training data, is not disclosed explicitly as it might contain proprietary information or make the system more vulnerable. This work shows that such attributes of neural networks can be exposed from a sequence of queries. This has multiple implications. On the one hand, our work exposes the vulnerability of black-box neural networks to different types of attacks — we show that the revealed internal information helps generate more effective adversarial examples against the black box model. On the other hand, this technique can be used for better protection of private content from automatic recognition models using adversarial examples. Our paper suggests that it is actually hard to draw a line between white box and black box models.
Performance Analysis of Trial and Error Algorithms
Model-free decentralized optimizations and learning are receiving increasing attention from theoretical and practical perspectives. In particular, two fully decentralized learning algorithms, namely Trial and Error (TEL) and Optimal Dynamical Learning (ODL), are very appealing for a broad class of games. In fact, ODL has the property to spend a high proportion of time in an optimum state that maximizes the sum of utility of all players. And the TEL has the property to spend a high proportion of time in an optimum state that maximizes the sum of utility of all players if there is a Pure Nash Equilibrium (PNE), otherwise, it spends a high proportion of time in an optimum state that maximizes a tradeoff between the sum of utility of all players and a predefined stability function. On the other hand, estimating the mean fraction of time spent in the optimum state (as well as the mean time duration to reach it) is challenging due to the high complexity and dimension of the inherent Markov Chains. In this paper, under some specific system model, an evaluation of the above performance metrics is provided by proposing an approximation of the considered Markov chains, which allows overcoming the problem of high dimensionality. A comparison between the two algorithms is then performed which allows a better understanding of their performances.
Independently Interpretable Lasso: A New Regularizer for Sparse Regression with Uncorrelated Variables
Sparse regularization such as
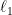
regularization is a quite powerful and widely used strategy for high dimensional learning problems. The effectiveness of sparse regularization have been supported practically and theoretically by several studies. However, one of the biggest issues in sparse regularization is that its performance is quite sensitive to correlations between features. Ordinary
regularization often selects variables correlated with each other, which results in deterioration of not only its generalization error but also interpretability. In this paper, we propose a new regularization method, ‘Independently Interpretable Lasso’ (IILasso for short). Our proposed regularizer suppresses selecting correlated variables, and thus each active variables independently affect the objective variable in the model. Hence, we can interpret regression coefficients intuitively and also improve the performance by avoiding overfitting. We analyze theoretical property of IILasso and show that the proposed method is much advantageous for its sign recovery and achieves almost minimax optimal convergence rate. Synthetic and real data analyses also indicate the effectiveness of IILasso.
Interpretable Feature Recommendation for Signal Analytics
This paper presents an automated approach for interpretable feature recommendation for solving signal data analytics problems. The method has been tested by performing experiments on datasets in the domain of prognostics where interpretation of features is considered very important. The proposed approach is based on Wide Learning architecture and provides means for interpretation of the recommended features. It is to be noted that such an interpretation is not available with feature learning approaches like Deep Learning (such as Convolutional Neural Network) or feature transformation approaches like Principal Component Analysis. Results show that the feature recommendation and interpretation techniques are quite effective for the problems at hand in terms of performance and drastic reduction in time to develop a solution. It is further shown by an example, how this human-in-loop interpretation system can be used as a prescriptive system.
NeST: A Neural Network Synthesis Tool Based on a Grow-and-Prune Paradigm
Neural networks (NNs) have begun to have a pervasive impact on various applications of machine learning. However, the problem of finding an optimal NN architecture for large applications has remained open for several decades. Conventional approaches search for the optimal NN architecture through extensive trial-and-error. Such a procedure is quite inefficient. In addition, the generated NN architectures incur substantial redundancy. To address these problems, we propose an NN synthesis tool (NeST) that automatically generates very compact architectures for a given dataset. NeST starts with a seed NN architecture. It iteratively tunes the architecture with gradient-based growth and magnitude-based pruning of neurons and connections. Our experimental results show that NeST yields accurate yet very compact NNs with a wide range of seed architecture selection. For example, for the LeNet-300-100 (LeNet-5) NN architecture derived from the MNIST dataset, we reduce network parameters by 34.1x (74.3x) and floating-point operations (FLOPs) by 35.8x (43.7x). For the AlexNet NN architecture derived from the ImageNet dataset, we reduce network parameters by 15.7x and FLOPs by 4.6x. All these results are the current state-of-the-art for these architectures.
Randomized Nonnegative Matrix Factorization
Nonnegative matrix factorization (NMF) is a powerful tool for data mining. However, the emergence of `big data’ has severely challenged our ability to compute this fundamental decomposition using deterministic algorithms. This paper presents a randomized hierarchical alternating least squares (HALS) algorithm to compute the NMF. By deriving a smaller matrix from the nonnegative input data, a more efficient nonnegative decomposition can be computed. Our algorithm scales to big data applications while attaining a near-optimal factorization, i.e., the algorithm scales with the target rank of the data rather than the ambient dimension of measurement space. The proposed algorithm is evaluated using synthetic and real world data and shows substantial speedups compared to deterministic HALS.
• Higher Cluster Categories and QFT Dualities
• Discovering More Precise Process Models from Event Logs by Filtering Out Chaotic Activities
• Localization of Multiple Targets with Identical Radar Signatures in Multipath Environments with Correlated Blocking
• Optimal Data Acquisition for Statistical Estimation
• On local non-global minimizers of quadratic functions with cubic regularization
• Versions of the Central Sets Theorem with higher degree terms
• Deep Learning-Based Dynamic Watermarking for Secure Signal Authentication in the Internet of Things
• On Graphs of Bounded Semi-Lattices
• NeuralFDR: Learning Discovery Thresholds from Hypothesis Features
• Improving Exoplanet Detection Power: Multivariate Gaussian Process Models for Stellar Activity
• A Rethinking of RF Wireless Power Transfer: How to Re-Green the Future Networks?
• Constant Approximation for $k$-Median and $k$-Means with Outliers via Iterative Rounding
• An homotopy method for $\ell_p$ regression provably beyond self-concordance and in input-sparsity time
• Learning to Bid Without Knowing
• A Study of Optimizing Heterogeneous Resources for Open IoT
• Binary Linear Codes with Optimal Scaling and Quasi-Linear Complexity
• Generalized Linear Model Regression under Distance-to-set Penalties
• Accelerating Training of Deep Neural Networks via Sparse Edge Processing
• Computationally efficient cardiac views projection using 3D Convolutional Neural Networks
• Automatic Differentiation for Tensor Algebras
• Non-Wire Alternatives to Capacity Expansion
• Uplink Performance Analysis of a Drone Cell in a Random Field of Ground Interferers
• Decentralised firewall for malware detection
• Counting Roots of Polynomials Over Prime Power Rings
• Reconstructing Video from Interferometric Measurements of Time-Varying Sources
• Strengthening Convex Relaxations of 0/1-Sets Using Boolean Formulas
• Dynamical Freezing in a Spin Glass System with Logarithmic Correlations
• An Optimal Distributed $(Δ+1)$-Coloring Algorithm?
• ‘Attention’ for Detecting Unreliable News in the Information Age
• A Faster Distributed Single-Source Shortest Paths Algorithm
• Sequential two-fold Pearson chi-squared test and tails of the Bessel process distributions
• Proximal Alternating Penalty Algorithms for Constrained Convex Optimization
• A deceptive step towards quantum speedup detection
• On constant multi-commodity flow-cut gaps for directed minor-free graphs
• An Iterative Co-Saliency Framework for RGBD Images
• An Ensemble-based Approach to Click-Through Rate Prediction for Promoted Listings at Etsy
• Joint Power Allocation and Beamforming for Non-Orthogonal Multiple Access (NOMA) in 5G Millimeter-Wave Communications
• Finding branch-decompositions of matroids, hypergraphs, and more
• Predicting Discharge Medications At Admission Time Based On Deep Learning
• Guiding the search in continuous state-action spaces by learning an action sampling distribution from off-target samples
• Separation-Free Super-Resolution from Compressed Measurements is Possible: an Orthonormal Atomic Norm Minimization Approach
• RSSI-Based Self-Localization with Perturbed Anchor Positions
• Tighter Einstein-Podolsky-Rosen steering inequality based on the sum uncertainty relation
• SPUX: Scalable Particle Markov Chain Monte Carlo for uncertainty quantification in stochastic ecological models
• Ryuo Nim: A Variant of the classical game of Wythoff Nim
• Language as a matrix product state
• Stable interior-point method for convex quadratic programming with strict error bounds
• The critical infection rate of the high-dimensional two-stage contact process
• Deep Stacking Networks for Low-Resource Chinese Word Segmentation with Transfer Learning
• Noise-induced synchronization of self-organized systems: Hegselmann-Krause dynamics in infinite space
• Transaction Fraud Detection Using GRU-centered Sandwich-structured Model
• Searching for Biophysically Realistic Parameters for Dynamic Neuron Models by Genetic Algorithms from Calcium Imaging Recording
• Computational Method for Phase Space Transport with Applications to Lobe Dynamics and Rate of Escape
• Game theoretic path selection to support security in device-to-device communications
• Existence, Uniqueness and Comparison Results for BSDEs with Lévy Jumps in an Extended Monotonic Generator Setting
• Superconducting, Insulating, and Anomalous Metallic Regimes in a Gated Two-Dimensional Semiconductor-Superconductor Array
• Optimal Checkpointing for Secure Intermittently-Powered IoT Devices
• DDD17: End-To-End DAVIS Driving Dataset
• Gaussian Kernel in Quantum Paradigm
• Birthday Paradox, Monochromatic Subgraphs, and the Second Moment Phenomenon
• Attentional Pooling for Action Recognition
• Ensembles of Multiple Models and Architectures for Robust Brain Tumour Segmentation
• Johnson’s bijections and their application to counting simultaneous core partitions
• Object-Centric Photometric Bundle Adjustment with Deep Shape Prior
• Modeling Duct Flow for Molecular Communication
• Classes of graphs without star forests and related graphs
• How well do reduced models capture the dynamics in models of interacting neurons ?
• Approximate Supermodularity Bounds for Experimental Design
• Composing Meta-Policies for Autonomous Driving Using Hierarchical Deep Reinforcement Learning
• Mixtures of Hidden Truncation Hyperbolic Factor Analyzers
• Towards Linguistically Generalizable NLP Systems: A Workshop and Shared Task
• Focal FCN: Towards Small Object Segmentation with Limited Training Data
• A Bayesian Nonparametric Model for Predicting Pregnancy Outcomes Using Longitudinal Profiles
• Distribution-Preserving k-Anonymity
• Learning Word Embeddings from Speech
• Semantic Web Today: From Oil Rigs to Panama Papers
• HPX Smart Executors
• Practical Data-Dependent Metric Compression with Provable Guarantees
• Stochastic Greedy Algorithms For Multiple Measurement Vectors
• On Identification of Distribution Grids
• Likelihood Based Study Designs for Time-to-Event Endpoints
• Asymmetric Rényi Problem
• Fisher-Rao Metric, Geometry, and Complexity of Neural Networks
• Lower bounding the Folkman numbers $F_v(a_1, …, a_s; m – 1)$
• On Powers of the Catalan Number Sequence
• Some Investigations about the Properties of Maximum Likelihood Estimations Based on Lower Record Values for a Sub-Family of the Exponential Family
• Registration and Fusion of Multi-Spectral Images Using a Novel Edge Descriptor
• Vertex covering with monochromatic pieces of few colours
• Stochastic Submodular Maximization: The Case of Coverage Functions
• Robust Speech Recognition Using Generative Adversarial Networks
• Double Q($σ$) and Q($σ, λ$): Unifying Reinforcement Learning Control Algorithms
• Modeling of Persistent Homology
• The Local Dimension of Deep Manifold
• On the Computational Complexity of Non-dictatorial Aggregation
• Adversarial Dropout Regularization
• Open system model for quantum dynamical maps with classical noise and corresponding master equations
• Robust Expectation-Maximization Algorithm for DOA Estimation of Acoustic Sources in the Spherical Harmonic Domain
• Levy processes in cones of fuzzy vectors
• Inference-Based Similarity Search in Randomized Montgomery Domains for Privacy-Preserving Biometric Identification
• Simultaneous Joint and Object Trajectory Templates for Human Activity Recognition from 3-D Data
• Is Input Sparsity Time Possible for Kernel Low-Rank Approximation?
• Planar Turán numbers for Theta graphs and paths of small order
• Bloom Filters, Adaptivity, and the Dictionary Problem
• Triangle roundedness in matroids
• Enlarged Controllability of Riemann-Liouville Fractional Differential Equations
• Scheduling Wireless Ad Hoc Networks in Polynomial Time Using Claw-free Conflict Graphs
• EW-tableaux, Le-tableaux, tree-like tableaux and the Abelian sandpile model
• Fooling Views: A New Lower Bound Technique for Distributed Computations under Congestion
• Real-Time Feedback-Based Optimization of Distribution Grids: A Unified Approach
• The Effect of Communication on Noncooperative Multiplayer Multi-Armed Bandit Problems
• Mutual Information in Frequency and its Application to Measure Cross-Frequency Coupling in Epilepsy
• Capacity upper bounds for deletion-type channels
• Space Time MUSIC: Consistent Signal Subspace Estimation for Wide-band Sensor Arrays
• Random Forests and Networks Analysis
• Sparse Kneser graphs are Hamiltonian
• Optimized State Space Grids for Abstractions
• Performance Comparison of Algorithms for Movie Rating Estimation
• Dispersal heterogeneity in the spatial Lambda-Fleming-Viot process
• Analysis of a Stratified Kraichnan Flow
• A gradient flow perspective on the quantization problem
• Approximating Partition Functions in Constant Time
• Spatial Pyramid Context-Aware Moving Object Detection and Tracking for Full Motion Video and Wide Aerial Motion Imagery
• Conditional Gradient Method for Stochastic Submodular Maximization: Closing the Gap
• Provenance and Pseudo-Provenance for Seeded Learning-Based Automated Test Generation
• Label-driven weakly-supervised learning for multimodal deformable image registration
• Multivariate Bayesian Predictive Synthesis in Macroeconomic Forecasting
• A robust RUV-testing procedure via gamma-divergence
• Estimation of Low-Rank Matrices via Approximate Message Passing
• Authorship Analysis of Xenophon’s Cyropaedia
• Routing Symmetric Demands in Directed Minor-Free Graphs with Constant Congestion
• Multilingual Speech Recognition With A Single End-To-End Model
• Bilinear Controllability of a Class of Advection-Diffusion-Reaction Systems
• Nearly Work-Efficient Parallel Algorithm for Digraph Reachability
• Distributed Representation for Traditional Chinese Medicine Herb via Deep Learning Models
• Impact of Communication Delay on Asynchronous Distributed Optimal Power Flow Using ADMM
• RoboCupSimData: A RoboCup soccer research dataset
• Coding-theorem Like Behaviour and Emergence of the Universal Distribution from Resource-bounded Algorithmic Probability
• End-to-End Video Classification with Knowledge Graphs
• Joining Local Knowledge to Communicate Reliably (Extended Abstract)
• Analysing Meteoroid Flights Using Particle Filters
• PowerModels.jl: An Open-Source Framework for Exploring Power Flow Formulations
• Iterative method of construction of good rhythms
• Two sources of poor coverage of confidence intervals after model selection
• KGAN: How to Break The Minimax Game in GAN
• Optimal investment-consumption and life insurance selection problem under inflation. A BSDE approach
• AdaBatch: Efficient Gradient Aggregation Rules for Sequential and Parallel Stochastic Gradient Methods
• A fast subsampling method for estimating the distribution of signal-to-noise ratio statistics in nonparametric time series regression models
• Game Theoretic Approaches to Massive Data Processing in Wireless Networks
• LAMN in a class of parametric models for null recurrent diffusion
• On the Outage Probability Conjecture for MIMO Channels
• Lattice theory of torsion classes
• Fusible HSTs and the randomized k-server conjecture
• Simultaneous Block-Sparse Signal Recovery Using Pattern-Coupled Sparse Bayesian Learning
• HyperNetworks with statistical filtering for defending adversarial examples
• On Codes over $\mathbb{Z}_{p^2}$ and its Covering Radius
• Evaluation of Croatian Word Embeddings
• Directed Graph Embeddings
• Performance Analysis of NOMA in Training Based Multiuser MIMO Systems
• On Z2Z4[ξ]-Skew Cyclic Codes
• Resource Allocation for D2D Communications with Partial Channel State Information
• Prophet Secretary: Surpassing the $1-1/e$ Barrier
• Asymptotics for high-dimensional covariance matrices and quadratic forms with applications to the trace functional and shrinkage
• Online Tool Condition Monitoring Based on Parsimonious Ensemble+
• Fast amortized inference of neural activity from calcium imaging data with variational autoencoders
• Extracting low-dimensional dynamics from multiple large-scale neural population recordings by learning to predict correlations
• A universal modification of the linear coupling method
• Overrelaxed Sinkhorn-Knopp Algorithm for Regularized Optimal Transport
• Lisco: A Continuous Approach in LiDAR Point-cloud Clustering
• Flexible statistical inference for mechanistic models of neural dynamics
• Combined shared/dedicated resource allocation for Device-to-Device Communication
• The covering radii of the $2$-transitive unitary, Suzuki, and Ree groups
• New Classes of Distributed Time Complexity
• Secure Transmission in Linear Multihop Relaying Networks
• Modelling non-stationary extreme precipitation with max-stable processes and multi-dimensional scaling
• Information capacity of direct detection optical transmission systems
• Simple and efficient GPU parallelization of existing H-Matrix accelerated BEM code
• On the complexity of hazard-free circuits
• The TensorFlow Partitioning and Scheduling Problem: It’s the Critical Path!
• Fast Integral Histogram Computations on GPU for Real-Time Video Analytics
• On the Complexity and Approximability of Optimal Sensor Selection for Kalman Filtering
• Author Attribute Anonymity by Adversarial Training of Neural Machine Translation
• Negative to Positive Magnetoresistance transition in Functionalization of Carbon nanotube and Polyaniline Composite
• An Iterative Scheme for Leverage-based Approximate Aggregation
• Deformable Deep Convolutional Generative Adversarial Network in Microwave Based Hand Gesture Recognition System
• Optimal transport maps for distribution preserving operations on latent spaces of Generative Models
• Constant-Factor Approximation for Ordered k-Median
• $\left( n , k , k – 1 \right)$-Steiner Systems in Random Hypergraphs
• Distributed Multi-resource Allocation with Little Communication Overhead
• Almost Polynomial Hardness of Node-Disjoint Paths in Grids
• INDIGO-DataCloud: Project Achievements
• PersonRank: Detecting Important People in Images
• Entrograms and coarse graining of dynamics on complex networks
• Mitigating adversarial effects through randomization
• Goal-oriented adaptive mesh refinement for non-symmetric functional settings
• A DC–programming approach for sparse PDE optimal control problems with nonconvex fractional costs
• Artificial Generation of Big Data for Improving Image Classification: A Generative Adversarial Network Approach on SAR Data
• When Cars Meet Distributed Computing: Data Storage as an Example
• Full-Duplex Cloud Radio Access Network: Stochastic Design and Analysis
• Towards Optimal Energy Harvesting Receiver Design in MIMO Systems
• Applying Convex Integer Programming: Sum Multicoloring and Bounded Neighborhood Diversity
• Estimating Cosmological Parameters from the Dark Matter Distribution
• FAMOUS: Fast Approximate string Matching using OptimUm search Schemes
• Computing Maximum Entropy Distributions Everywhere
• An efficient quantum algorithm for generative machine learning
• Convex Ramsey matrices and non-amenability of automophism groups of generic structures
• Throughput Maximization for Delay-Sensitive Random Access Communication
• On the proper treatment of improper distributions
• Wirelessly Powered Crowd Sensing: Joint Power Transfer, Sensing, Compression, and Transmission
• A random walk approach to linear statistics in random tournament ensembles
• End-to-End Abnormality Detection in Medical Imaging
• On Structural Parameterizations of the Edge Disjoint Paths Problem
• Fully-Dynamic Bin Packing with Limited Repacking
• Inverting the Turán Problem
• Neural Speed Reading via Skim-RNN
Like this:
Like Loading...