Hyperparameter Importance Across Datasets
With the advent of automated machine learning, automated hyperparameter optimization methods are by now routinely used. However, this progress is not yet matched by equal progress on automatic analyses that yield information beyond performance-optimizing hyperparameter settings. In this work, we aim to answer the following two questions: Given an algorithm, what are generally its most important hyperparameters, and what are good priors over their hyperparameters’ ranges to draw values from? We present methodology and a framework to answer these questions based on meta-learning across many datasets. We apply this methodology using the experimental meta-data available on OpenML to determine the most important hyperparameters of support vector machines, random forests and Adaboost, and to infer priors for all their hyperparameters. Our results, obtained fully automatically, provide a quantitative basis to focus efforts in both manual algorithm design and in automated hyperparameter optimization. Our experiments confirm that the selected hyperparameters are indeed the most important ones and that our obtained priors also lead to improvements in hyperparameter optimization.
Bayesian Hypernetworks
We propose Bayesian hypernetworks: a framework for approximate Bayesian inference in neural networks. A Bayesian hypernetwork,

, is a neural network which learns to transform a simple noise distribution,

, to a distribution

over the parameters

of another neural network (the ‘primary network’). We train

with variational inference, using an invertible
to enable efficient estimation of the variational lower bound on the posterior

via sampling. In contrast to most methods for Bayesian deep learning, Bayesian hypernets can represent a complex multimodal approximate posterior with correlations between parameters, while enabling cheap i.i.d. sampling of
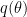
. We demonstrate these qualitative advantages of Bayesian hypernets, which also achieve competitive performance on a suite of tasks that demonstrate the advantage of estimating model uncertainty, including active learning and anomaly detection.
Sparse Weighted Canonical Correlation Analysis
Given two data matrices

and

, sparse canonical correlation analysis (SCCA) is to seek two sparse canonical vectors

and

to maximize the correlation between

and

. However, classical and sparse CCA models consider the contribution of all the samples of data matrices and thus cannot identify an underlying specific subset of samples. To this end, we propose a novel sparse weighted canonical correlation analysis (SWCCA), where weights are used for regularizing different samples. We solve the
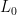
-regularized SWCCA (
-SWCCA) using an alternating iterative algorithm. We apply
-SWCCA to synthetic data and real-world data to demonstrate its effectiveness and superiority compared to related methods. Lastly, we consider also SWCCA with different penalties like LASSO (Least absolute shrinkage and selection operator) and Group LASSO, and extend it for integrating more than three data matrices.
LLASSO: A linear unified LASSO for multicollinear situations
We propose a rescaled LASSO, by premultipying the LASSO with a matrix term, namely linear unified LASSO (LLASSO) for multicollinear situations. Our numerical study has shown that the LLASSO is comparable with other sparse modeling techniques and often outperforms the LASSO and elastic net. Our findings open new visions about using the LASSO still for sparse modeling and variable selection. We conclude our study by pointing that the LLASSO can be solved by the same efficient algorithm for solving the LASSO and suggest to follow the same construction technique for other penalized estimators.
Deep Learning for Case-based Reasoning through Prototypes: A Neural Network that Explains its Predictions
Deep neural networks are widely used for classification. These deep models often suffer from a lack of interpretability — they are particularly difficult to understand because of their non-linear nature. As a result, neural networks are often treated as ‘black box’ models, and in the past, have been trained purely to optimize the accuracy of predictions. In this work, we create a novel network architecture for deep learning that naturally explains its own reasoning for each prediction. This architecture contains an autoencoder and a special prototype layer, where each unit of that layer stores a weight vector that resembles an encoded training input. The encoder of the autoencoder allows us to do comparisons within the latent space, while the decoder allows us to visualize the learned prototypes. The training objective has four terms: an accuracy term, a term that encourages every prototype to be similar to at least one encoded input, a term that encourages every encoded input to be close to at least one prototype, and a term that encourages faithful reconstruction by the autoencoder. The distances computed in the prototype layer are used as part of the classification process. Since the prototypes are learned during training, the learned network naturally comes with explanations for each prediction, and the explanations are loyal to what the network actually computes.
Deep Regression Bayesian Network and Its Applications
Deep directed generative models have attracted much attention recently due to their generative modeling nature and powerful data representation ability. In this paper, we review different structures of deep directed generative models and the learning and inference algorithms associated with the structures. We focus on a specific structure that consists of layers of Bayesian Networks due to the property of capturing inherent and rich dependencies among latent variables. The major difficulty of learning and inference with deep directed models with many latent variables is the intractable inference due to the dependencies among the latent variables and the exponential number of latent variable configurations. Current solutions use variational methods often through an auxiliary network to approximate the posterior probability inference. In contrast, inference can also be performed directly without using any auxiliary network to maximally preserve the dependencies among the latent variables. Specifically, by exploiting the sparse representation with the latent space, max-max instead of max-sum operation can be used to overcome the exponential number of latent configurations. Furthermore, the max-max operation and augmented coordinate ascent are applied to both supervised and unsupervised learning as well as to various inference. Quantitative evaluations on benchmark datasets of different models are given for both data representation and feature learning tasks.
User Modelling for Avoiding Overfitting in Interactive Knowledge Elicitation for Prediction
In human-in-the-loop machine learning, the user provides information beyond that in the training data. Many algorithms and user interfaces have been designed to optimize and facilitate this human–machine interaction; however, fewer studies have addressed the potential defects the designs can cause. Effective interaction often requires exposing the user to the training data or its statistics. The design of the system is then critical, as this can lead to double use of data and overfitting, if the user reinforces noisy patterns in the data. We propose a user modelling methodology, by assuming simple rational behaviour, to correct the problem. We show, in a user study with 48 participants, that the method improves predictive performance in a sparse linear regression sentiment analysis task, where graded user knowledge on feature relevance is elicited. We believe that the key idea of inferring user knowledge with probabilistic user models has general applicability in guarding against overfitting and improving interactive machine learning.
High Dimensional Cluster Analysis Using Path Lengths
A hierarchical scheme for clustering data is presented which applies to spaces with a high number of dimension (

). The data set is first reduced to a smaller set of partitions (multi-dimensional bins). Multiple clustering techniques are used, including spectral clustering, however, new techniques are also introduced based on the path length between partitions that are connected to one another. A Line-Of-Sight algorithm is also developed for clustering. A test bank of 12 data sets with varying properties is used to expose the strengths and weaknesses of each technique. Finally, a robust clustering technique is discussed based on reaching a consensus among the multiple approaches, overcoming the weaknesses found individually.
Knowledge is at the Edge! How to Search in Distributed Machine Learning Models
With the advent of the Internet of Things and Industry 4.0 an enormous amount of data is produced at the edge of the network. Due to a lack of computing power, this data is currently send to the cloud where centralized machine learning models are trained to derive higher level knowledge. With the recent development of specialized machine learning hardware for mobile devices, a new era of distributed learning is about to begin that raises a new research question: How can we search in distributed machine learning models? Machine learning at the edge of the network has many benefits, such as low-latency inference and increased privacy. Such distributed machine learning models can also learn personalized for a human user, a specific context, or application scenario. As training data stays on the devices, control over possibly sensitive data is preserved as it is not shared with a third party. This new form of distributed learning leads to the partitioning of knowledge between many devices which makes access difficult. In this paper we tackle the problem of finding specific knowledge by forwarding a search request (query) to a device that can answer it best. To that end, we use a entropy based quality metric that takes the context of a query and the learning quality of a device into account. We show that our forwarding strategy can achieve over 95% accuracy in a urban mobility scenario where we use data from 30 000 people commuting in the city of Trento, Italy.
Two-stage Algorithm for Fairness-aware Machine Learning
Algorithmic decision making process now affects many aspects of our lives. Standard tools for machine learning, such as classification and regression, are subject to the bias in data, and thus direct application of such off-the-shelf tools could lead to a specific group being unfairly discriminated. Removing sensitive attributes of data does not solve this problem because a \textit{disparate impact} can arise when non-sensitive attributes and sensitive attributes are correlated. Here, we study a fair machine learning algorithm that avoids such a disparate impact when making a decision. Inspired by the two-stage least squares method that is widely used in the field of economics, we propose a two-stage algorithm that removes bias in the training data. The proposed algorithm is conceptually simple. Unlike most of existing fair algorithms that are designed for classification tasks, the proposed method is able to (i) deal with regression tasks, (ii) combine explanatory attributes to remove reverse discrimination, and (iii) deal with numerical sensitive attributes. The performance and fairness of the proposed algorithm are evaluated in simulations with synthetic and real-world datasets.
Parsimonious Adaptive Rejection Sampling
Monte Carlo (MC) methods have become very popular in signal processing during the past decades. The adaptive rejection sampling (ARS) algorithms are well-known MC technique which draw efficiently independent samples from univariate target densities. The ARS schemes yield a sequence of proposal functions that converge toward the target, so that the probability of accepting a sample approaches one. However, sampling from the proposal pdf becomes more computationally demanding each time it is updated. We propose the Parsimonious Adaptive Rejection Sampling (PARS) method, where an efficient trade-off between acceptance rate and proposal complexity is obtained. Thus, the resulting algorithm is faster than the standard ARS approach.
A Deep Incremental Boltzmann Machine for Modeling Context in Robots
Context is an essential capability for robots that are to be as adaptive as possible in challenging environments. Although there are many context modeling efforts, they assume a fixed structure and number of contexts. In this paper, we propose an incremental deep model that extends Restricted Boltzmann Machines. Our model gets one scene at a time, and gradually extends the contextual model when necessary, either by adding a new context or a new context layer to form a hierarchy. We show on a scene classification benchmark that our method converges to a good estimate of the contexts of the scenes, and performs better or on-par on several tasks compared to other incremental models or non-incremental models.
A Learning Based Approach to Incremental Context Modeling in Robots
There have been several attempts at modeling context in robots. However, either these attempts assume a fixed number of contexts or use a rule-based approach to determine when to increment the number of contexts. In this paper, we propose to pose the task of incrementing as a learning problem, which we solve using a Recurrent Neural Network. We show that the network successfully (with 98% testing accuracy) learns to predict when to increment, and demonstrate, in a scene modeling problem (where the correct number of contexts is not known), that the robot increments the number of contexts in an expected manner (i.e., the entropy of the system is reduced). We also present how the incremental model can be used for various scene reasoning tasks.
Enumerating Multiple Equivalent Lasso Solutions
Predictive modelling is a data-analysis task common in many scientific fields. However, it is rather unknown that multiple predictive models can be equally well-performing for the same problem. This multiplicity often leads to poor reproducibility when searching for a unique solution in datasets with low number of samples, high dimensional feature space and/or high levels of noise, a common scenario in biology and medicine. The Lasso regression is one of the most powerful and popular regularization methods, yet it also produces a single, sparse solution. In this paper, we show that nearly-optimal Lasso solutions, whose out-of-sample statistical error is practically indistinguishable from the optimal one, exist. We formalize various notions of equivalence between Lasso solutions, and we devise an algorithm to enumerate the ones that are equivalent in a statistical sense: we define a tolerance on the root mean square error (RMSE) which creates a RMSE-equivalent Lasso solution space. Results in both regression and classification tasks reveal that the out-of-sample error due to the RMSE relaxation is within the range of the statistical error due to the sampling size.
Methods for Analyzing Large Spatial Data: A Review and Comparison
The Gaussian process is an indispensable tool for spatial data analysts. The onset of the ‘big data’ era, however, has lead to the traditional Gaussian process being computationally infeasible for modern spatial data. As such, various alternatives to the full Gaussian process that are more amenable to handling big spatial data have been proposed. These modern methods often exploit low rank structures and/or multi-core and multi-threaded computing environments to facilitate computation. This study provides, first, an introductory overview of several methods for analyzing large spatial data. Second, this study describes the results of a predictive competition among the described methods as implemented by different groups with strong expertise in the methodology. Specifically, each research group was provided with two training datasets (one simulated and one observed) along with a set of prediction locations. Each group then wrote their own implementation of their method to produce predictions at the given location and each which was subsequently run on a common computing environment. The methods were then compared in terms of various predictive diagnostics. Supplementary materials regarding implementation details of the methods and code are available for this article online.
• Game-Theoretic Design of Secure and Resilient Distributed Support Vector Machines with Adversaries
• Hyperspectral band selection using genetic algorithm and support vector machines for early identification of charcoal rot disease in soybean
• A Single Visualization Technique for Displaying Multiple Metabolite-Phenotype Associations
• Reduction of Look Up Tables for Computation of Reciprocal of Square Roots
• Social Attention: Modeling Attention in Human Crowds
• Conant’s generalised metric spaces are Ramsey
• On statistics of bi-orthogonal eigenvectors in real and complex Ginibre ensembles: combining partial Schur decomposition with supersymmetry
• ‘Relative-Continuity’ for Non-Lipschitz Non-Smooth Convex Optimization using Stochastic (or Deterministic) Mirror Descent
• Cox regression analysis with missing covariates via multiple imputation
• RAWSim-O: A Simulation Framework for Robotic Mobile Fulfillment Systems
• Entropy operates in non-linear semifields
• Planning, Fast and Slow: A Framework for Adaptive Real-Time Safe Trajectory Planning
• A poset $Φ_n$ whose maximal chains are in bijection with the $n \times n$ alternating sign matrices
• STDP Based Pruning of Connections and Weight Quantization in Spiking Neural Networks for Energy Efficient Recognition
• On the Runtime-Efficacy Trade-off of Anomaly Detection Techniques for Real-Time Streaming Data
• Robust Submodular Maximization: Offline and Online Algorithms
• Identifying On-time Reward Delivery Projects with Estimating Delivery Duration on Kickstarter
• Can the early human visual system compete with Deep Neural Networks?
• Movement-efficient Sensor Deployment in Wireless Sensor Networks
• HyperENTM: Evolving Scalable Neural Turing Machines through HyperNEAT
• Explaining Aviation Safety Incidents Using Deep Learned Precursors
• Generalized Gaussian Multiterminal Source Coding: The Symmetric Case
• Central Moments-based Cascaded Lattice Boltzmann Method for Thermal Convective Flows in Three-Dimensions
• Vertex degree sums for perfect matchings in 3-uniform hypergraphs
• A Robust Accelerated Optimization Algorithm for Strongly Convex Functions
• Hamilton path decompositions of complete multipartite graphs
• Estimating a network from multiple noisy realizations
• Applications of Economic and Pricing Models for Resource Management in 5G Wireless Networks: A Survey
• Edge sampling using network local information
• Residual Connections Encourage Iterative Inference
• The Law of the Iterated Logarithm for a Class of SPDEs
• Short-Packet Communications with NOMA for IoT Applications
• Retinal Fluid Segmentation and Detection in Optical Coherence Tomography Images using Fully Convolutional Neural Network
• Multimodal and Multiscale Deep Neural Networks for the Early Diagnosis of Alzheimer’s Disease using structural MR and FDG-PET images
• Retinal Vasculature Segmentation Using Local Saliency Maps and Generative Adversarial Networks For Image Super Resolution
• A Unified Scheme to Accelerate Adaptive Cubic Regularization and Gradient Methods for Convex Optimization
• Arc-transitive digraphs of given out-valency and with blocks of given size
• A Goodness-of-Fit Test for Sampled Subgraphs
• End-to-end Network for Twitter Geolocation Prediction and Hashing
• VGR-Net: A View Invariant Gait Recognition Network
• Combinatorial Multi-armed Bandits for Real-Time Strategy Games
• Counterexamples on matchings in hypergraphs and full rainbow matchings in graphs
• On Integrated $L^{1}$ Convergence Rate of an Isotonic Regression Estimator for Multivariate Observations
• Higher codimension relative isoperimetric inequality outside a convex set
• Fast Top-$\boldsymbol{k}$ Area Topics Extraction with Knowledge Base
• The basic equation for target detection in remote sensing
• WeText: Scene Text Detection under Weak Supervision
• Anti-jamming Communications Using Spectrum Waterfall: A Deep Reinforcement Learning Approach
• Machine Learning by Two-Dimensional Hierarchical Tensor Networks: A Quantum Information Theoretic Perspective on Deep Architectures
• Filmy Cloud Removal on Satellite Imagery with Multispectral Conditional Generative Adversarial Nets
• Recent Advances in Zero-shot Recognition
• Efficient Computation in Adaptive Artificial Spiking Neural Networks
• The Semantics of Transactions and Weak Memory in x86, Power, ARMv8, and C++
• Dynamic texture recognition using time-causal and time-recursive spatio-temporal receptive fields
• Performance Comparison of Intrusion Detection Systems and Application of Machine Learning to Snort System
• Compact Formulae in Sparse Elimination
• Power Synthesis of Maximally-Sparse Linear Arrays Radiating Shaped Patterns through a Compressive-Sensing Driven Strategy
• The colored Jones polynomial and Kontsevich-Zagier series for double twist knots
• Using a Factored Dual in Augmented Lagrangian Methods for Semidefinite Programming
• Manifold regularization based on Nystr{ö}m type subsampling
• A Method of Generating Random Weights and Biases in Feedforward Neural Networks with Random Hidden Nodes
• On the Placement and Delivery Schemes for Decentralized Coded Caching System
• Out-of-equilibrium dynamical mean-field equations for the perceptron model
• Stochastic continuity equations with conservative noise
• Robots as-a-Service in Cloud Computing: Search and Rescue in Large-scale Disasters Case Study
• RADNET: Radiologist Level Accuracy using Deep Learning for HEMORRHAGE detection in CT Scans
• Object Classification in Images of Neoclassical Artifacts Using Deep Learning
• A combinatorial framework to quantify peak/pit asymmetries in complex dynamics
• $\ell^1$-Analysis Minimization and Generalized (Co-)Sparsity: When Does Recovery Succeed?
• Even Fourier multipliers and martingale transforms in infinite dimensions
• The Loewner energy of loops and regularity of driving functions
• Isotone Cones in Banach Spaces and Applications to Best Approximations of Operators without Continuity Conditions
• Continuous Behavioural Function Equilibria and Approximation Schemes in Bayesian Games with Non-Finite Type and Action Spaces
• Bayes factors for partially observed stochastic epidemic models
• Enumerating permutations sortable by $k$ passes through a pop-stack
• Characterization and Enumeration of Complementary Dual Abelian Codes
• Simulating the Ising Model with a Deep Convolutional Generative Adversarial Network
• Complex Word Identification: Challenges in Data Annotation and System Performance
• Matrix-Product Constructions for Hermitian Self-Orthogonal Codes
• A deformation of instanton homology for webs
• Skin Lesion Analysis Toward Melanoma Detection: A Challenge at the 2017 International Symposium on Biomedical Imaging (ISBI), Hosted by the International Skin Imaging Collaboration (ISIC)
• Automatic Detection and Uncertainty Quantification of Landmarks on Elastic Curves
• Potential Conditional Mutual Information: Estimators, Properties and Applications
• The power of sum-of-squares for detecting hidden structures
• Simultaneous Detection of Signal Regions With Applications in Genome-Wide Association Studies
Like this:
Like Loading...