Unsupervised Domain Adaptation with Copula Models
Fully Bayesian Estimation Under Informative Sampling
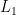 consistency of the joint posterior is guaranteed. We compare performances between the two approaches on synthetic data.
consistency of the joint posterior is guaranteed. We compare performances between the two approaches on synthetic data.
Toward a System Building Agenda for Data Integration
Complex Correntropy Function: properties, and application to a channel equalization problem
Toward Scalable Machine Learning and Data Mining: the Bioinformatics Case
Matching Anonymized and Obfuscated Time Series to Users’ Profiles
Enabling Quality Control for Entity Resolution: A Human and Machine Cooperative Framework
Bag-of-Vector Embeddings of Dependency Graphs for Semantic Induction
Testing for Feature Relevance: The HARVEST Algorithm
The Deep Ritz method: A deep learning-based numerical algorithm for solving variational problems
Towards Understanding the Evolution of Vocabulary Terms in Knowledge Graphs
DTATG: An Automatic Title Generator based on Dependency Trees
libact: Pool-based Active Learning in Python
Visual Reasoning with Natural Language
Building a Structured Query Engine
Factor selection by permutation
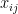 of samples, such as test scores of students. In factor analysis and PCA, these features are thought to be influenced by unobserved factors, such as skills. Can we determine how many factors affect the data? Many approaches have been developed for this factor selection problem. The popular Parallel Analysis method randomly permutes each feature of the data. It selects factors if their singular values are larger than those of the permuted data. It is used by leading applied statisticians, including T Hastie, M Stephens, J Storey, R Tibshirani and WH Wong. Despite empirical evidence for its accuracy, there is currently no theoretical justification. This prevents us from knowing when it will work in the future. In this paper, we show that parallel analysis consistently selects the significant factors in certain high-dimensional factor models. The intuition is that permutations keep the noise invariant, while ‘destroying’ the low-rank signal. This provides justification for permutation methods in PCA and factor models under some conditions. A key requirement is that the factors must load on several variables. Our work points to improvements of permutation methods.
of samples, such as test scores of students. In factor analysis and PCA, these features are thought to be influenced by unobserved factors, such as skills. Can we determine how many factors affect the data? Many approaches have been developed for this factor selection problem. The popular Parallel Analysis method randomly permutes each feature of the data. It selects factors if their singular values are larger than those of the permuted data. It is used by leading applied statisticians, including T Hastie, M Stephens, J Storey, R Tibshirani and WH Wong. Despite empirical evidence for its accuracy, there is currently no theoretical justification. This prevents us from knowing when it will work in the future. In this paper, we show that parallel analysis consistently selects the significant factors in certain high-dimensional factor models. The intuition is that permutations keep the noise invariant, while ‘destroying’ the low-rank signal. This provides justification for permutation methods in PCA and factor models under some conditions. A key requirement is that the factors must load on several variables. Our work points to improvements of permutation methods.
Weighted-SVD: Matrix Factorization with Weights on the Latent Factors
 . In this work, we propose an attentive convolution network, AttentiveConvNet. It extends the context scope of the convolution operation, deriving higher-level features for a word not only from local context, but also from information extracted from nonlocal context by the attention mechanism commonly used in RNNs. This nonlocal context can come (i) from parts of the input text that are distant or (ii) from a second input text, the context text
. In this work, we propose an attentive convolution network, AttentiveConvNet. It extends the context scope of the convolution operation, deriving higher-level features for a word not only from local context, but also from information extracted from nonlocal context by the attention mechanism commonly used in RNNs. This nonlocal context can come (i) from parts of the input text that are distant or (ii) from a second input text, the context text  . In an evaluation on sentence relation classification (textual entailment and answer sentence selection) and text classification, experiments demonstrate that AttentiveConvNet has state-of-the-art performance and outperforms RNN/CNN variants with and without attention.
. In an evaluation on sentence relation classification (textual entailment and answer sentence selection) and text classification, experiments demonstrate that AttentiveConvNet has state-of-the-art performance and outperforms RNN/CNN variants with and without attention.
KV-match: An Efficient Subsequence Matching Approach for Large Scale Time Series
 , which utilizes multiple varied length indexes to process the query simultaneously. A two-dimensional dynamic programming algorithm is proposed to find the optimal query segmentation. We implement our approach on both local files and HBase tables, and conduct extensive experiments on synthetic and real-world datasets. Results show that our index is of comparable size to the popular tree-style index while our query processing is order of magnitudes more efficient.
, which utilizes multiple varied length indexes to process the query simultaneously. A two-dimensional dynamic programming algorithm is proposed to find the optimal query segmentation. We implement our approach on both local files and HBase tables, and conduct extensive experiments on synthetic and real-world datasets. Results show that our index is of comparable size to the popular tree-style index while our query processing is order of magnitudes more efficient.
DeepER — Deep Entity Resolution
Building Chatbots from Forum Data: Model Selection Using Question Answering Metrics
What Does Explainable AI Really Mean? A New Conceptualization of Perspectives
Change Acceleration and Detection
Interpretable Convolutional Neural Networks
Event Identification as a Decision Process with Non-linear Representation of Text
A concatenating framework of shortcut convolutional neural networks
Time Series Management Systems: A Survey
An Updated Literature Review of Distance Correlation and its Applications to Time Series
• Hyperfield Grassmannians
• Hierarchical modeling of molecular energies using a deep neural network
• Lower bounds on the lattice-free rank for packing and covering integer programs
• Learning the Exact Topology of Undirected Consensus Networks
• Gradient Flows in Filtering and Fisher-Rao Geometry
• CARMA: Contention-aware Auction-based Resource Management in Architecture
• A Gaussian mixture model representation of endmember variability in hyperspectral unmixing
• Distance-based Depths for Directional Data
• Extremal Threshold Graphs for Matchings and Independent Sets
• Ergodicity versus non-ergodicity for Probabilistic Cellular Automata on rooted trees
• Language-depedent I-Vectors for LRE15
• On diregular digraphs with degree two and excess three
• On spectral and numerical properties of random butterfly matrices
• Inclusive Prime Number Races
• User-friendly guarantees for the Langevin Monte Carlo with inaccurate gradient
• HEPCloud, a New Paradigm for HEP Facilities: CMS Amazon Web Services Investigation
• Reconstruction from Periodic Nonlinearities, With Applications to HDR Imaging
• Graphs, Skeleta and Reconstruction of Polytopes
• An Efficient Load Balancing Method for Tree Algorithms
• 3DOF Pedestrian Trajectory Prediction Learned from Long-Term Autonomous Mobile Robot Deployment Data
• A Cheeger-type exponential bound for the number of triangulated manifolds
• Dense RGB-D semantic mapping with Pixel-Voxel neural network
• A Game-Theoretic Method for Multi-Period Demand Response: Revenue Maximization, Power Allocation, and Asymptotic Behavior
• A Multi-Resolution Model for Non-Gaussian Random Fields on a Sphere with Application to Ionospheric Electrostatic Potentials
• Enhanced Linear-array Photoacoustic Beamforming using Modified Coherence Factor
• Accelerated Directional Search and Derivative-Free Methods with non-euclidian prox-structure
• Speaker Role Contextual Modeling for Language Understanding and Dialogue Policy Learning
• Dynamic Time-Aware Attention to Speaker Roles and Contexts for Spoken Language Understanding
• Continuous-Time Relationship Prediction in Dynamic Heterogeneous Information Networks
• PCANet-II: When PCANet Meets the Second Order Pooling
• On heat kernel decay for the random conductance model
• Group-labeled light dual multinets in the projective plane (with Appendix)
• Multi-Scale Pipeline for the Search of String-Induced CMB Anisotropies
• A Many-Objective Evolutionary Algorithm with Angle-Based Selection and Shift-Based Density Estimation
• Full-Duplex Relay Selection in Cognitive Underlay Networks
• Deep learning for source camera identification on mobile devices
• Variational Grid Setting Network
• Unsupervised Segmentation of Action Segments in Egocentric Videos using Gaze
• Unsupervised Classification of Intrusive Igneous Rock Thin Section Images using Edge Detection and Colour Analysis
• Power analysis for a linear regression model when regressors are matrix sampled
• Where computer vision can aid physics: dynamic cloud motion forecasting from satellite images
• New binary and ternary LCD codes
• Improved Training for Self-Training
• Spherical embeddings of symmetric association schemes in 3-dimensional Euclidean space
• Parameterized Algorithms for Conflict-free Colorings of Graphs
• Decontamination of Mutual Contamination Models
• Clustering and Hitting Times of Threshold Exceedances and Applications
• Robust Photometric Stereo Using Learned Image and Gradient Dictionaries
• Robust Surface Reconstruction from Gradients via Adaptive Dictionary Regularization
• Fast Fine-grained Image Classification via Weakly Supervised Discriminative Localization
• A Coin-Tossing Conundrum
• Homomorphisms are indeed a good basis for counting: Three fixed-template dichotomy theorems, for the price of one
• Spectral distributions of periodic random matrix ensembles
• DeepWheat: Estimating Phenotypic Traits From Images of Crops Using Deep Learning
• The graph theory general position problem on some interconnection networks
• Gaussian Three-Dimensional kernel SVM for Edge Detection Applications
• Laplacian Simplices Associated to Digraphs
• Harmonic analysis and inference for spherical distributions
• Fine-grained Event Learning of Human-Object Interaction with LSTM-CRF
• Bayesian estimation from few samples: community detection and related problems
• Distributed and Managed: Research Challenges and Opportunities of the Next Generation Cyber-Physical Systems
• DREMS-OS: An Operating System for Managed Distributed Real-time Embedded Systems
• On the Complexity of Chore Division
• What Words Do We Use to Lie?: Word Choice in Deceptive Messages
• Heptavalent symmetric graphs with solvable stabilizers admitting vertex-transitive non-abelian simple groups
• Image Dehazing using Bilinear Composition Loss Function
• A Versatile Approach to Evaluating and Testing Automated Vehicles based on Kernel Methods
• Efficient and Effective Single-Document Summarizations and A Word-Embedding Measurement of Quality
• A Lottery Model for Center-type Problems With Outliers
• A Moving-Horizon Hybrid Stochastic Game for Secure Control of Cyber-Physical Systems
• Translating Videos to Commands for Robotic Manipulation with Deep Recurrent Neural Networks
• Domination game on uniform hypergraphs
• Velocity Field Generation for Density Control of Swarms using Heat Equation and Smoothing Kernels
• Pyramidal RoR for Image Classification
• Load Balancing in Hypergraphs
• Personalized Fuzzy Text Search Using Interest Prediction and Word Vectorization
• The Crowdfunding Game
• FPT-algorithms for The Shortest Lattice Vector and Integer Linear Programming Problems
• Mutual Information based Bayesian Analysis of Power System Reliability
• The Width and Integer Optimization on Simplices With Bounded Minors of the Constraint Matrices
• Parameter Sharing Deep Deterministic Policy Gradient for Cooperative Multi-agent Reinforcement Learning
• Fully Automated Fact Checking Using External Sources
• The Edwards-Wilkinson limit of the random heat equation in dimensions three and higher
• Robust Tuning Datasets for Statistical Machine Translation
• Large deviations for level sets of branching Brownian motion and Gaussian free fields
• A New Property of Random Regular Bipartite Graphs
• On the Limit Distributions Associated with Step-kind Boundary Problems
• Activating the ‘Breakfast Club’: Modeling Influence Spread in Natural-World Social Networks
• Mathematical foundations of matrix syntax
• Multivalued matrices and forbidden configurations
• On a generalization of Lie($k$): a CataLAnKe theorem
• Homogenization of a Random Walk with Irreversible Rates On a Graph in $d$ Dimensions
• Efficient Preconditioning for Noisy Separable NMFs by Successive Projection Based Low-Rank Approximations
• Channel Hardening and Favorable Propagation in Cell-Free Massive MIMO with Stochastic Geometry
• Wikipedia graph mining: dynamic structure of collective memory
• Identifying Clickbait Posts on Social Media with an Ensemble of Linear Models
• Ext and local cohomology modules of face rings of simplicial posets
• Combinatorics of Toric Arrangements
• Straggler Mitigation by Delayed Relaunch of Tasks
• An Estimation-Theoretic View of Privacy
• Learning event representation: As sparse as possible, but not sparser
• Asymptotic Allocation Rules for a Class of Dynamic Multi-armed Bandit Problems
• Creating a Social Brain for Cooperative Connected Autonomous Vehicles: Issues and Challenges
• Large-Scale Quadratically Constrained Quadratic Program via Low-Discrepancy Sequences
• Patrolling a Path Connecting a Set of Points with Unbalanced Frequencies of Visits
• Oracle Importance Sampling for Stochastic Simulation Models
• HUMOR: A Crowd-Annotated Spanish Corpus for Humor Analysis
• Margin Sample Mining Loss: A Deep Learning Based Method for Person Re-identification
• Breathing multichimera states in nonlocally coupled phase oscillators
• Performance analysis of FSO using relays and spatial diversity under log-normal fading channel
• DeepSafe: A Data-driven Approach for Checking Adversarial Robustness in Neural Networks
• SE3-Pose-Nets: Structured Deep Dynamics Models for Visuomotor Planning and Control
• The Dutch’s Real World Financial Institute: Introducing Quantum-Like Bayesian Networks as an Alternative Model to deal with Uncertainty
• Log-majorizations for the (symplectic) eigenvalues of the Cartan barycenter
• Online control of the false discovery rate with decaying memory
• Bivariate Exponentiated Generalized Linear Exponential Distribution with Applications in Reliability Analysis
• Hamiltonicity in random graphs is born resilient
• Depth estimation using structured light flow — analysis of projected pattern flow on an object’s surface —
• Temporal shape super-resolution by intra-frame motion encoding using high-fps structured light
• Plethysm and fast matrix multiplication
• Regular Sequences of Quasi-Nonexpansive Operators and Their Applications
• The Strategy of Experts for Repeated Predictions
• Sparse Doppler Sensing
• Distributed Optimization for Coordinated Beamforming in Multi-Cell Multigroup Multicast Systems: Power Minimization and SINR Balancing
• Design and Performance Analysis of Dual and Multi-hop Diffusive Molecular Communication Systems
• Crude EEG parameter provides sleep medicine with well-defined continuous hypnograms
• Diffusive Molecular Communication with Nanomachine Mobility
• Random iterations of homeomorphisms on the circle
• The branching-ruin number and the critical parameter of once-reinforced random walk on trees
• Indirect Match Highlights Detection with Deep Convolutional Neural Networks
• Raman spectroscopy of femtosecond multi-pulse irradiation of vitreous silica: experiment and simulation
• Quantum Multicritical Phenomena in Disordered Weyl Semimetal
• Remote Sensing Image Classification with Large Scale Gaussian Processes
• On minimax nonparametric estimation of signal in Gaussian noise
• sgmcmc: An R Package for Stochastic Gradient Markov Chain Monte Carlo
• Orthogonal Vectors Indexing
• Scalable Bayesian regression in high dimensions with multiple data sources
• Lasso Regularization Paths for NARMAX Models via Coordinate Descent
• Solving Two Conjectures regarding Codes for Location in Circulant Graphs
• Constrained Differential Privacy for Count Data
• Large deviations for the annealed Ising model on inhomogeneous random graphs: spins and degrees
• Improving Spark Application Throughput Via Memory Aware Task Co-location: A Mixture of Experts Approach
• Out-of-focus Blur: Image De-blurring
• Adaptive Smoothing in fMRI Data Processing Neural Networks
• Central limit theorem for the quenched path measures for the continuous directed polymer in $d\geq 3$ in weak disorder
• Deep Convolutional Neural Networks for Interpretable Analysis of EEG Sleep Stage Scoring
• Factorial characters of classical Lie groups and their combinatorial realisations
• A Justification of Conditional Confidence Intervals
• Analysis of Feedback Error in Automatic Repeat reQuest
• Low Complexity Modem Structure for OFDM-based Orthogonal Time Frequency Space Modulation
• The heptagon-wheel cocycle in the Kontsevich graph complex
• Parameterized Approximation Schemes for Steiner Trees with Small Number of Steiner Vertices
• Conditional Chromatic Filtering with Spatial Enhancement for Restoring Pansharpened Images
• Profile extrema for visualizing and quantifying uncertainties on excursion regions. Application to coastal flooding
• Global phase and magnitude synchronization of coupled oscillators with application to the control of grid-forming power inverters
• Upper bounds for the function solution of the homogenuous 2D Bolzmann equation with hard potential
• Volumes and Ehrhart polynomials of flow polytopes
• Channel Estimation for TDD/FDD Massive MIMO Systems with Channel Covariance Computing
• Synthesising Evolutionarily Stable Normative Systems
• Revealing the Unseen: How to Expose Cloud Usage While Protecting User Privacy
• A novel quantile-based decomposition of the indirect effect in mediation analysis with an application to infant mortality in the US population
• DFT-Spread OFDM with Frequency Domain Reference Symbols
• Learning hard quantum distributions with variational autoencoders
• A Furstenberg type formula for the speed of distance stationary sequences
• CHIPS: A Service for Collecting, Organizing, Processing, and Sharing Medical Image Data in the Cloud
• A Hopf-algebraic approach to cumulants-moments relations and Wick polynomials
• Effective Straggler Mitigation: Which Clones Should Attack and When?
• Spinal cord gray matter segmentation using deep dilated convolutions
• Neural Color Transfer between Images
• On the smallest snarks with oddness 4 and connectivity 2
• AUC Maximization with K-hyperplane
• Resonance Graphs and Perfect Matchings of Graphs on Surfaces
• Accelerating Scientific Data Exploration via Visual Query Systems
• Stochastic Comparisons of Lifetimes of Two Series and Parallel Systems with Location-Scale Family Distributed Components having Archimedean Copulas
• Sequential Deliberation for Social Choice
• Exploring Graphs with Time Constraints by Unreliable Collections of Mobile Robots
• Zeons, Permanents, the Johnson scheme, and Generalized Derangements
• Identification of critical nodes in large-scale spatial networks
• Accelerated Methods for $α$-Weakly-Quasi-Convex Problems
• Local resilience of a random graph throughout its evolution
• On the entropy power inequality for the Rényi entropy of order [0,1]
• Colorful combinatorics and Macdonald polynomials
• Compiling and Processing Historical and Contemporary Portuguese Corpora
• The Capacity of Private Information Retrieval with Partially Known Private Side Information
• Deep Learning for Unsupervised Insider Threat Detection in Structured Cybersecurity Data Streams
• Entropy Inequalities for Sums in Prime Cyclic Groups
• Detecting Adversarial Attacks on Neural Network Policies with Visual Foresight
• Finding the optimal nets for self-folding Kirigami
• On the smoothness of the partition function for multiple Schramm-Loewner evolutions
• Testing for Global Network Structure Using Small Subgraph Statistics
• Clustering Stream Data by Exploring the Evolution of Density Mountain
• Rethinking Feature Discrimination and Polymerization for Large-scale Recognition
• A note on perfect simulation for exponential random graph models
• Local likelihood estimation of complex tail dependence structures in high dimensions, applied to U.S. precipitation extremes
• Unsupervised Hypernym Detection by Distributional Inclusion Vector Embedding
• Classification of Time-Series Images Using Deep Convolutional Neural Networks
• Sentiment Perception of Readers and Writers in Emoji use
• How is Distributed ADMM Affected by Network Topology?
• Rényi Differential Privacy Mechanisms for Posterior Sampling
• PIRVS: An Advanced Visual-Inertial SLAM System with Flexible Sensor Fusion and Hardware Co-Design
• Detecting Epistatic Selection with Partially Observed Genotype Data Using Copula Graphical Models
• Valuation of Employee Stock Options (ESOs) by means of Mean-Variance Hedging
• Online and Distributed Robust Regressions under Adversarial Data Corruption
• On Landauer principle and bound for infinite systems
• End-to-end Learning for 3D Facial Animation from Raw Waveforms of Speech
• Minimal Dependency Translation: a Framework for Computer-Assisted Translation for Under-Resourced Languages
• Fine-Grained Head Pose Estimation Without Keypoints
• Identifying Nominals with No Head Match Co-references Using Deep Learning
• Natural boundary and zero distribution of random polynomials in smooth domains
• An Extension of Clark-Haussman Formula and Applications
• The ‘weak’ interdependence of infrastructure systems produces mixed percolation transitions in multilayer networks
• Ordered Dags: HypercubeSort
• VIDOSAT: High-dimensional Sparsifying Transform Learning for Online Video Denoising
• Two-dimensional plasmons in the random impedance network model of disordered thin-film nanocomposites
• Optimal Matroid Partitioning Problems
• Maximum Matchings in Graphs for Allocating Kidney Paired Donation
• Monte Carlo approximation certificates for k-means clustering
• Bayesian Inference under Cluster Sampling with Probability Proportional to Size
• GP-GAN: Gender Preserving GAN for Synthesizing Faces from Landmarks
• Automated and Robust Quantification of Colocalization in Dual-Color Fluorescence Microscopy: A Nonparametric Statistical Approach
• Asymptotic analysis of a multiclass queueing control problem under heavy-traffic with model uncertainty
• Facial Key Points Detection using Deep Convolutional Neural Network – NaimishNet
• Supervised Q-walk for Learning Vector Representation of Nodes in Networks
• Random numerical semigroups and a simplicial complex of irreducible semigroups
• Energy-Efficient Power and Bandwidth Allocation in an Integrated Sub-6 GHz — Millimeter Wave System
• Joint Person Re-identification and Camera Network Topology Inference in Multiple Cameras
• Annotation and Detection of Emotion in Text-based Dialogue Systems with CNN
• On the trace of unimodal Lévy processes on Lipschitz domains
• Equilibrium computation for zero sum games with submodular structure
• Is Structure Necessary for Modeling Argument Expectations in Distributional Semantics?
• Nearest Neighbor Imputation for Categorical Data by Weighting of Attributes
• Training Feedforward Neural Networks with Standard Logistic Activations is Feasible
• Dynamic range maximization in excitable networks
• Learning Affinity via Spatial Propagation Networks
• MMCR4NLP: Multilingual Multiway Corpora Repository for Natural Language Processing
• Randomized Truncated SVD Levenberg-Marquardt Approach to Geothermal Natural State and History Matching
• Estimating the decoherence time using non-commutative Functional Inequalities
• Asymptotic Log-Harnack Inequality and Applications for Stochastic Systems of Infinite Memory
• Degenerate SDEs with Singular Drift and Applications to Heisenberg Groups
• Simulating Structure-from-Motion
• Parameter estimation of platelets deposition: Approximate Bayesian computation with high performance computing
• Improving approximate Bayesian computation via quasi Monte Carlo
• De novo construction of q-ploid linkage maps using discrete graphical models
• Pareto optimality in multilayer network growth
• Generalised Mycielski graphs and the Borsuk-Ulam theorem
• Resolution limits on visual speech recognition
• Precise large deviations for random walk in random environment
• Optimal DNN Primitive Selection with Partitioned Boolean Quadratic Programming
• Some observations on computer lip-reading: moving from the dream to the reality
• Learning the optimal scale for GWAS through hierarchical SNP aggregation
• Long-time behaviour of generalised Zig-Zag process
• Persistence probability of random weyl polynomial
• Which phoneme-to-viseme maps best improve visual-only computer lip-reading?
• Adaptive p-value weighting with power optimality
• Towards an Inferential Lexicon of Event Selecting Predicates for French
• Isotropic and Steerable Wavelets in N Dimensions. A multiresolution analysis framework for ITK
• Differential Privacy for Sets in Euclidean Space
• Detection of Inferior Myocardial Infarction using Shallow Convolutional Neural Networks
• Speaker-independent machine lip-reading with speaker-dependent viseme classifiers
• Finding Talk About the Past in the Discourse of Non-Historians
• Finding phonemes: improving machine lip-reading
• Computing Top-k Closeness Centrality in Fully-dynamic Graphs
• Scaling up Group Closeness Maximization
• Fractional equations via convergence of forms
• Spectral gaps and discrete magnetic Laplacians
• Decoding visemes: improving machine lipreading
• A MAP-Based Layered Detection Algorithm and Outage Analysis over MIMO Channels
• Secure Private Information Retrieval from Colluding Databases with Eavesdroppers
• Secrecy Outage Analysis over Correlated Composite Nakagami-$m$/Gamma Fading Channels
• Ramsey expansions of $Λ$-ultrametric spaces
• A family of transformed copulas with singular component
• Person Re-Identification with Vision and Language
• The tail does not determine the size of the giant
• Multi-Pair Two Way AF Full-Duplex Massive MIMO Relaying with ZFR/ZFT Processing
• On a predator-prey system with random switching that never converges to its equilibrium
• Asymptotic harvesting of populations in random environments
• Weak convergence of weighted additive functionals of long-range dependent fields
• Keep It Real: Tail Probabilities of Compound Heavy-Tailed Distributions
• Perturbation theory approaches to Anderson and Many-Body Localization: some lecture notes
• netgwas: An R Package for Network-Based Genome-Wide Association Studies
• Relationships between cycles spaces, gain graphs, graph coverings, path homology, and graph curvature
• A D2D-based Protocol for Ultra-Reliable Wireless Communications for Industrial Automation
• Coverage and Rate Analysis for Co-Existing RF/VLC Downlink Cellular Networks
• Weak convergence rates for stochastic evolution equations and applications to nonlinear stochastic wave, HJMM, stochastic Schroedinger and linearized stochastic Korteweg–de Vries equations
• Indexing the Event Calculus with Kd-trees to Monitor Diabetes
• Dilated Convolutions for Modeling Long-Distance Genomic Dependencies
• Analysis of Large Scale Web Experiments Using Sequences of Estimators
• Decoding visemes: improving machine lipreading (PhD thesis)
• Visual speech recognition: aligning terminologies for better understanding
• Multiple domination models for placement of electric vehicle charging stations in road networks
• Isotropic covariance functions on graphs and their edges
• Visual gesture variability between talkers in continuous visual speech