Interactive Spoken Content Retrieval by Deep Reinforcement Learning
User-machine interaction is important for spoken content retrieval. For text content retrieval, the user can easily scan through and select on a list of retrieved item. This is impossible for spoken content retrieval, because the retrieved items are difficult to show on screen. Besides, due to the high degree of uncertainty for speech recognition, the retrieval results can be very noisy. One way to counter such difficulties is through user-machine interaction. The machine can take different actions to interact with the user to obtain better retrieval results before showing to the user. The suitable actions depend on the retrieval status, for example requesting for extra information from the user, returning a list of topics for user to select, etc. In our previous work, some hand-crafted states estimated from the present retrieval results are used to determine the proper actions. In this paper, we propose to use Deep-Q-Learning techniques instead to determine the machine actions for interactive spoken content retrieval. Deep-Q-Learning bypasses the need for estimation of the hand-crafted states, and directly determine the best action base on the present retrieval status even without any human knowledge. It is shown to achieve significantly better performance compared with the previous hand-crafted states.
Select-Additive Learning: Improving Cross-individual Generalization in Multimodal Sentiment Analysis
Multimodal sentiment analysis is drawing an increasing amount of attention these days. It enables mining of opinions in video reviews and surveys which are now available aplenty on online platforms like YouTube. However, the limited number of high-quality multimodal sentiment data samples may introduce the problem of the sentiment being dependent on the individual specific features in the dataset. This results in a lack of generalizability of the trained models for classification on larger online platforms. In this paper, we first examine the data and verify the existence of this dependence problem. Then we propose a Select-Additive Learning (SAL) procedure that improves the generalizability of trained discriminative neural networks. SAL is a two-phase learning method. In Selection phase, it selects the confounding learned representation. In Addition phase, it forces the classifier to discard confounded representations by adding Gaussian noise. In our experiments, we show how SAL improves the generalizability of state-of-the-art models. We increase prediction accuracy significantly in all three modalities (text, audio, video), as well as in their fusion. We show how SAL, even when trained on one dataset, achieves good accuracy across test datasets.
ReasoNet: Learning to Stop Reading in Machine Comprehension
Teaching a computer to read a document and answer general questions pertaining to the document is a challenging yet unsolved problem. In this paper, we describe a novel neural network architecture called Reasoning Network ({ReasoNet}) for machine comprehension tasks. ReasoNet makes use of multiple turns to effectively exploit and then reason over the relation among queries, documents, and answers. Different from previous approaches using a fixed number of turns during inference, ReasoNet introduces a termination state to relax this constraint on the reasoning depth. With the use of reinforcement learning, ReasoNet can dynamically determine whether to continue the comprehension process after digesting intermediate results, or to terminate reading when it concludes that existing information is adequate to produce an answer. ReasoNet has achieved state-of-the-art performance in machine comprehension datasets, including unstructured CNN and Daily Mail datasets, and a structured Graph Reachability dataset.
Sparse Boltzmann Machines with Structure Learning as Applied to Text Analysis
We are interested in exploring the possibility and benefits of structure learning for deep models. As the first step, this paper investigates the matter for Restricted Boltzmann Machines (RBMs). We conduct the study with Replicated Softmax, a variant of RBMs for unsupervised text analysis. We present a method for learning what we call Sparse Boltzmann Machines, where each hidden unit is connected to a subset of the visible units instead of all of them. Empirical results show that the method yields models with significantly improved model fit and interpretability as compared with RBMs where each hidden unit is connected to all visible units.
Applications of Data Mining (DM) in Science and Engineering: State of the art and perspectives
The continuous increase in the availability of data of any kind, coupled with the development of networks of high-speed communications, the popularization of cloud computing and the growth of data centers and the emergence of high-performance computing does essential the task to develop techniques that allow more efficient data processing and analyzing of large volumes datasets and extraction of valuable information. In the following pages we will discuss about development of this field in recent decades, and its potential and applicability present in the various branches of scientific research. Also, we try to review briefly the different families of algorithms that are included in data mining research area, its scalability with increasing dimensionality of the input data and how they can be addressed and what behavior different methods in a scenario in which the information is distributed or decentralized processed so as to increment performance optimization in heterogeneous environments.
Probabilistic Feature Selection and Classification Vector Machine
Sparse Bayesian classifiers are among the state-of-the-art classification algorithms, which are able to make stable and reliable probabilistic predictions. However, some of these algorithms, e.g. probabilistic classification vector machine (PCVM) and relevant vector machine (RVM), are not capable of eliminating irrelevant and redundant features which result in performance degradation. To tackle this problem, in this paper, a Bayesian approach is adopted to simultaneously select the relevant samples and features for clas- sification. We call it a probabilistic feature selection and classification vector machine (PFCVM), which adopts truncated Gaussian priors as both sample and feature priors. In order to derive the analytical solution to Bayesian inference, we use Laplace approximation to obtain approximate posteriors and marginal likelihoods. Then we obtain the optimized parameters and hyperparameters by the type-II maximum likelihood method. The experi- ments on benchmark data sets and high dimensional data sets validate the performance of PFCVM under two criteria: accuracy of classification and effectiveness of selected features. Finally, we analyse the generalization performance of PFCVM and derive a generalization error bound for PFCVM. Then by tightening the bound, we demonstrate the significance of the sparseness for the model.
Towards Deep Symbolic Reinforcement Learning
Deep reinforcement learning (DRL) brings the power of deep neural networks to bear on the generic task of trial-and-error learning, and its effectiveness has been convincingly demonstrated on tasks such as Atari video games and the game of Go. However, contemporary DRL systems inherit a number of shortcomings from the current generation of deep learning techniques. For example, they require very large datasets to work effectively, entailing that they are slow to learn even when such datasets are available. Moreover, they lack the ability to reason on an abstract level, which makes it difficult to implement high-level cognitive functions such as transfer learning, analogical reasoning, and hypothesis-based reasoning. Finally, their operation is largely opaque to humans, rendering them unsuitable for domains in which verifiability is important. In this paper, we propose an end-to-end reinforcement learning architecture comprising a neural back end and a symbolic front end with the potential to overcome each of these shortcomings. As proof-of-concept, we present a preliminary implementation of the architecture and apply it to several variants of a simple video game. We show that the resulting system — though just a prototype — learns effectively, and, by acquiring a set of symbolic rules that are easily comprehensible to humans, dramatically outperforms a conventional, fully neural DRL system on a stochastic variant of the game.
Principled Option Learning in Markov Decision Processes
It is well known that options can make planning more efficient, among their many benefits. Thus far, algorithms for autonomously discovering a set of useful options were heuristic. Naturally, a principled way of finding a set of useful options may be more promising and insightful. In this paper we suggest a mathematical characterization of good sets of options using tools from information theory. This characterization enables us to find conditions for a set of options to be optimal and an algorithm that outputs a useful set of options and illustrate the proposed algorithm in simulation.
Sequential Ensemble Learning for Outlier Detection: A Bias-Variance Perspective
Ensemble methods for classification and clustering have been effectively used for decades, while ensemble learning for outlier detection has only been studied recently. In this work, we design a new ensemble approach for outlier detection in multi-dimensional point data, which provides improved accuracy by reducing error through both bias and variance. Although classification and outlier detection appear as different problems, their theoretical underpinnings are quite similar in terms of the bias-variance trade-off [1], where outlier detection is considered as a binary classification task with unobserved labels but a similar bias-variance decomposition of error. In this paper, we propose a sequential ensemble approach called CARE that employs a two-phase aggregation of the intermediate results in each iteration to reach the final outcome. Unlike existing outlier ensembles which solely incorporate a parallel framework by aggregating the outcomes of independent base detectors to reduce variance, our ensemble incorporates both the parallel and sequential building blocks to reduce bias as well as variance by (

) successively eliminating outliers from the original dataset to build a better data model on which outlierness is estimated (sequentially), and (
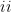
) combining the results from individual base detectors and across iterations (parallelly). Through extensive experiments on sixteen real-world datasets mainly from the UCI machine learning repository [2], we show that CARE performs significantly better than or at least similar to the individual baselines. We also compare CARE with the state-of-the-art outlier ensembles where it also provides significant improvement when it is the winner and remains close otherwise.
Parallel Computing for Copula Parameter Estimation with Big Data: A Simulation Study
Copula-based modeling has seen rapid advances in recent years. However, in big data applications, the lengthy computation time for estimating copula parameters is a major difficulty. Here, we develop a novel method to speed computation time in estimating copula parameters, using communication-free parallel computing. Our procedure partitions full data sets into disjoint independent subsets, performs copula parameter estimation on the subsets, and combines the results to produce an approximation to the full data copula parameter. We show in simulation studies that the computation time is greatly reduced through our method, using three well-known one-parameter bivariate copulas within the elliptical and Archimedean families: Gaussian, Frank and Gumbel. In addition, our simulation studies find small values for estimated bias, estimated mean squared error, and estimated relative L1 and L2 errors for our method, when compared to the full data parameter estimates.
Opponent Modeling in Deep Reinforcement Learning
Opponent modeling is necessary in multi-agent settings where secondary agents with competing goals also adapt their strategies, yet it remains challenging because strategies interact with each other and change. Most previous work focuses on developing probabilistic models or parameterized strategies for specific applications. Inspired by the recent success of deep reinforcement learning, we present neural-based models that jointly learn a policy and the behavior of opponents. Instead of explicitly predicting the opponent’s action, we encode observation of the opponents into a deep Q-Network (DQN); however, we retain explicit modeling (if desired) using multitasking. By using a Mixture-of-Experts architecture, our model automatically discovers different strategy patterns of opponents without extra supervision. We evaluate our models on a simulated soccer game and a popular trivia game, showing superior performance over DQN and its variants.
Stochastic Matrix Factorization
This paper considers a restriction to non-negative matrix factorization in which at least one matrix factor is stochastic. That is, the elements of the matrix factors are non-negative and the columns of one matrix factor sum to 1. This restriction includes topic models, a popular method for analyzing unstructured data. It also includes a method for storing and finding pictures. The paper presents necessary and sufficient conditions on the observed data such that the factorization is unique. In addition, the paper characterizes natural bounds on the parameters for any observed data and presents a consistent least squares estimator. The results are illustrated using a topic model analysis of PhD abstracts in economics and the problem of storing and retrieving a set of pictures of faces.
Context-aware Sequential Recommendation
Since sequential information plays an important role in modeling user behaviors, various sequential recommendation methods have been proposed. Methods based on Markov assumption are widely-used, but independently combine several most recent components. Recently, Recurrent Neural Networks (RNN) based methods have been successfully applied in several sequential modeling tasks. However, for real-world applications, these methods have difficulty in modeling the contextual information, which has been proved to be very important for behavior modeling. In this paper, we propose a novel model, named Context-Aware Recurrent Neural Networks (CA-RNN). Instead of using the constant input matrix and transition matrix in conventional RNN models, CA-RNN employs adaptive context-specific input matrices and adaptive context-specific transition matrices. The adaptive context-specific input matrices capture external situations where user behaviors happen, such as time, location, weather and so on. And the adaptive context-specific transition matrices capture how lengths of time intervals between adjacent behaviors in historical sequences affect the transition of global sequential features. Experimental results show that the proposed CA-RNN model yields significant improvements over state-of-the-art sequential recommendation methods and context-aware recommendation methods on two public datasets, i.e., the Taobao dataset and the Movielens-1M dataset.
The Projected Power Method: An Efficient Algorithm for Joint Alignment from Pairwise Differences
Various applications involve assigning discrete label values to a collection of objects based on some noisy data. Due to the discrete—and hence nonconvex—structure of the problem, computing the maximum likelihood estimates (MLE) becomes intractable at first sight. This paper makes progress towards efficient computation of the MLE by focusing on a concrete joint alignment problem—that is, the problem of recovering

discrete variables

,
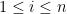
given noisy observations of their modulo differences
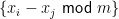
. We propose a novel low-complexity procedure, which operates in a lifted space by representing distinct label values in orthogonal directions, and which attempts to optimize quadratic functions over hyper cubes. Starting with a first guess computed via a special method, the algorithm successively refines the iterates via projected power iterations. We prove that the proposed projected power method makes no error—and hence converges to the MLE—in a suitable regime. Numerical experiments have been carried out on both synthetic and real data to demonstrate the practicality of our algorithm. We expect this algorithmic framework to be effective for a broad range of discrete assignment problems.
Scope for Machine Learning in Digital Manufacturing
This provocation paper provides an overview of the underlying optimisation problem in the emerging field of Digital Manufacturing. Initially, this paper discusses how the notion of Digital Manufacturing is transforming from a term describing a suite of software tools for the integration of production and design functions towards a more general concept incorporating computerised manufacturing and supply chain processes, as well as information collection and utilisation across the product life cycle. On this basis, we use the example of one such manufacturing process, Additive Manufacturing, to identify an integrated multi-objective optimisation problem underlying Digital Manufacturing. Forming an opportunity for a concurrent application of data science and optimisation, a set of challenges arising from this problem is outlined.
• Hurwitz numbers for real polynomials
• Linked systems of symmetric group divisible designs
• The ACRV Picking Benchmark (APB): A Robotic Shelf Picking Benchmark to Foster Reproducible Research
• Effects of electron-impurity scattering on density of states in silicene: impurity bands and band-gap narrowing
• Improved Lower Bounds on the Size of Balls over Permutations with the Infinity Metric
• NPCs Vote! Changing Voter Reactions Over Time Using the Extreme AI Personality Engine
• Lower bounds for sensitivity of graph properties
• The marginally stable Bethe lattice spin glass revisited
• Generalized residual vector quantization for large scale data
• The existence of the graphs that have exactly two main eigenvalues
• Automorphism groups of a class of cubic Cayley graphs on symmetric groups
• Leveraging Environmental Correlations: The Thermodynamics of Requisite Variety
• Service Rate Control For Jobs with Decaying Value
• Solving the Wastewater Treatment Plant Problem with SMT
• Permutation Methods for Sharpening Gaussian Process Approximations
• Extended Formulation for Online Learning of Combinatorial Objects
• ADAGIO: Fast Data-aware Near-Isometric Linear Embeddings
• Predicting Future Shanghai Stock Market Price using ANN in the Period 21-Sep-2016 to 11-Oct-2016
• A Deep Metric for Multimodal Registration
• Enumeration of cubic Cayley graphs on dihedral groups
• Computing unit-weighted scales as a proxy for principal components or as factor score estimates
• Consistent Discretization and Minimization of the L1 Norm on Manifolds
• Hall sets, Lazard sets and comma-free codes
• A note on intersecting hypergraphs with large cover number
• Connected Order Ideals and P-Partitions
• SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient
• Replica Analysis for the Duality of the Portfolio Optimization Problem
• $L^{p}$ and almost sure rates of convergence of averaged stochastic gradient algorithms with applications to online robust estimation
• Enumeration of points, lines, planes, etc
• Rationality in map and hypermap enumeration by genus
• On strong starters for $\mathbb{F}_q$
• Multilinear Grammar: Ranks and Interpretations
• Some copula inference procedures adapted to the presence of ties
• Playing FPS Games with Deep Reinforcement Learning
• Learning Personalized Optimal Control for Repeatedly Operated Systems
• Quantum Speed-ups for Semidefinite Programming
• On Randomized Distributed Coordinate Descent with Quantized Updates
• Public Goods Games on Adaptive Coevolutionary Networks
• Graphical Models for Discrete and Continuous Data
• Searching for Gene Sets with Mutually Exclusive Mutations
• Label-Free Supervision of Neural Networks with Physics and Domain Knowledge
• Automated Proof (or Disproof) of Linear Recurrences Satisfied by Pisot Sequences
• Optimality and Sub-optimality of PCA for Spiked Random Matrices and Synchronization
• Matrix representations of matroids of biased graphs correspond to gain functions
• Abelian Squares and Their Progenies
• Tensor Completion by Alternating Minimization under the Tensor Train (TT) Model
• Graph-Structured Representations for Visual Question Answering
• The effect of distributed time-delays on the synchronization of neuronal networks
• Selective sampling after solving a convex problem
• Enhancing LambdaMART Using Oblivious Trees
• Stability phenomena in the homology of tree braid groups
• Discussion of ‘Fast Approximate Inference for Arbitrarily Large Semiparametric Regression Models via Message Passing’
• Poset-based Triangle: An Improved Alternative for Bilattice-based Triangle
• On the scaling limits of weakly asymmetric bridges
• Extending Unification in $\mathcal{EL}$ to Disunification: The Case of Dismatching and Local Disunification
• The MGB-2 Challenge: Arabic Multi-Dialect Broadcast Media Recognition
• Kmerlight: fast and accurate k-mer abundance estimation
• On the adoption of abductive reasoning for time series interpretation
• Multi-view Dimensionality Reduction for Dialect Identification of Arabic Broadcast Speech
• On the smallest size of an almost complete subset of a conic in $\mathrm{PG}(2,q)$ and extendability of Reed-Solomon codes
• Errors bounds for finite approximations of coherent lower previsions on finite probability spaces
• Scaling limits of stochastic processes associated with resistance forms
• General bounds on limited broadcast domination
• Uniform sampling in a structured branching population
• Flexible linear mixed models with improper priors for longitudinal and survival data
• Improving landscape inference by integrating heterogeneous data in the inverse Ising problem
• High-Dimensional Disorder-Driven Phenomena in Weyl Semimetals, Semiconductors and Related Systems
• Survival exponents for fractional Brownian motion with multivariate time
• TODIM and TOPSIS with Z-numbers
• On the local density problem for graphs of given odd-girth
• Randomized dual proximal gradient for large-scale distributed optimization
• Bounds for the normal approximation of the maximum likelihood estimator from m-dependent random variables
• Almost Periodic Solutions and Stable Solutions for Stochastic Differential Equations
• The quasispecies distribution
• The Kelmans-Seymour conjecture III: 3-vertices in $K_4^-$
• On descriptions of products of simplices
• Optimal waveform for the entrainment of oscillators perturbed by an amplitude-modulated high-frequency force
• Minimizing Total Busy Time with Application to Energy-efficient Scheduling of Virtual Machines in IaaS clouds
• Time-dependent rate of convergence for binomial approximations
• Cycles and Clustering in Multiplex Networks
• A Variation on Chip-Firing: the diffusion game
• Enabling Dark Energy Science with Deep Generative Models of Galaxy Images
• Functional delta-method for the bootstrap of uniformly quasi-Hadamard differentiable functionals
• A New Two Sample Type-II Progressive Censoring Scheme
• Inherent Trade-Offs in the Fair Determination of Risk Scores
• The exchange graph and variations of the ratio of the two Symanzik polynomials
• Temporal Logic Programs with Variables
• List 3-dynamic coloring of graphs with small maximum average degree
• Context-free grammars for several polynomials associated with Eulerian polynomials
• Circuit Breakers, Discovery, and API Gateways in Microservices
• Weighted Lattice Walks and Universality Classes
• Weak solution of a continuum model for vicinal surface in the attachment-detachment-limited regime
• Brushing Number and Zero-Forcing Number of Graphs and their Line Graphs
• Asymptotic properties of maximum likelihood estimator for the growth rate for a jump-type CIR process based on continuous time observations
• A Cheap Linear Attention Mechanism with Fast Lookups and Fixed-Size Representations
• Fully Dynamic Connectivity in $O(\log n(\log\log n)^2)$ Amortized Expected Time
• On the Phase Transition of Finding a Biclique in a larger Bipartite Graph
• Geometrically Convergent Distributed Optimization with Uncoordinated Step-Sizes
• Online and Distributed learning of Gaussian mixture models by Bayesian Moment Matching
• A Quantum Implementation Model for Artificial Neural Networks
• Sketches for Matrix Norms: Faster, Smaller and More General
Like this:
Like Loading...