• Generating Text with Deep Reinforcement Learning
We introduce a novel schema for sequence to sequence learning with a Deep Q-Network (DQN), which decodes the output sequence iteratively. The aim here is to enable the decoder to first tackle easier portions of the sequences, and then turn to cope with difficult parts. Specifically, in each iteration, an encoder-decoder Long Short-Term Memory (LSTM) network is employed to, from the input sequence, automatically create features to represent the internal states of and formulate a list of potential actions for the DQN. Take rephrasing a natural sentence as an example. This list can contain ranked potential words. Next, the DQN learns to make decision on which action (e.g., word) will be selected from the list to modify the current decoded sequence. The newly modified output sequence is subsequently used as the input to the DQN for the next decoding iteration. In each iteration, we also bias the reinforcement learning’s attention to explore sequence portions which are previously difficult to be decoded. For evaluation, the proposed strategy was trained to decode ten thousands natural sentences. Our experiments indicate that, when compared to a left-to-right greedy beam search LSTM decoder, the proposed method performed competitively well when decoding sentences from the training set, but significantly outperformed the baseline when decoding unseen sentences, in terms of BLEU score obtained.
• Streaming, Distributed Variational Inference for Bayesian Nonparametrics
This paper presents a methodology for creating streaming, distributed inference algorithms for Bayesian nonparametric (BNP) models. In the proposed framework, processing nodes receive a sequence of data minibatches, compute a variational posterior for each, and make asynchronous streaming updates to a central model. In contrast to previous algorithms, the proposed framework is truly streaming, distributed, asynchronous, learning-rate-free, and truncation-free. The key challenge in developing the framework, arising from the fact that BNP models do not impose an inherent ordering on their components, is finding the correspondence between minibatch and central BNP posterior components before performing each update. To address this, the paper develops a combinatorial optimization problem over component correspondences, and provides an efficient solution technique. The paper concludes with an application of the methodology to the DP mixture model, with experimental results demonstrating its practical scalability and performance.
• SentiWords: Deriving a High Precision and High Coverage Lexicon for Sentiment Analysis
Deriving prior polarity lexica for sentiment analysis – where positive or negative scores are associated with words out of context – is a challenging task. Usually, a trade-off between precision and coverage is hard to find, and it depends on the methodology used to build the lexicon. Manually annotated lexica provide a high precision but lack in coverage, whereas automatic derivation from pre-existing knowledge guarantees high coverage at the cost of a lower precision. Since the automatic derivation of prior polarities is less time consuming than manual annotation, there has been a great bloom of these approaches, in particular based on the SentiWordNet resource. In this paper, we compare the most frequently used techniques based on SentiWordNet with newer ones and blend them in a learning framework (a so called ‘ensemble method’). By taking advantage of manually built prior polarity lexica, our ensemble method is better able to predict the prior value of unseen words and to outperform all the other SentiWordNet approaches. Using this technique we have built SentiWords, a prior polarity lexicon of approximately 155,000 words, that has both a high precision and a high coverage. We finally show that in sentiment analysis tasks, using our lexicon allows us to outperform both the single metrics derived from SentiWordNet and popular manually annotated sentiment lexica.
• CONQUER: Confusion Queried Online Bandit Learning
We present a new recommendation setting for picking out two items from a given set to be highlighted to a user, based on contextual input. These two items are presented to a user who chooses one of them, possibly stochastically, with a bias that favours the item with the higher value. We propose a second-order algorithm framework that members of it use uses relative upper-confidence bounds to trade off exploration and exploitation, and some explore via sampling. We analyze one algorithm in this framework in an adversarial setting with only mild assumption on the data, and prove a regret bound of

, where

is the number of rounds and
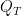
is the cumulative approximation error of item values using a linear model. Experiments with product reviews from 33 domains show the advantage of our methods over algorithms designed for related settings, and that UCB based algorithms are inferior to greed or sampling based algorithms.
• Principal Differences Analysis: Interpretable Characterization of Differences between Distributions
We introduce principal differences analysis (PDA) for analyzing differences between high-dimensional distributions. The method operates by finding the projection that maximizes the Wasserstein divergence between the resulting univariate populations. Relying on the Cramer-Wold device, it requires no assumptions about the form of the underlying distributions, nor the nature of their inter-class differences. A sparse variant of the method is introduced to identify features responsible for the differences. We provide algorithms for both the original minimax formulation as well as its semidefinite relaxation. In addition to deriving some convergence results, we illustrate how the approach may be applied to identify differences between cell populations in the somatosensory cortex and hippocampus as manifested by single cell RNA-seq. Our broader framework extends beyond the specific choice of Wasserstein divergence.
• Extreme Events of Markov Chains
The extremal behaviour of a Markov chain is typically characterized by its tail chain. For asymptotically dependent Markov chains existing formulations fail to capture the full evolution of the extreme event when the chain moves out of the extreme tail region and for asymptotically independent chains recent results fail to cover well-known asymptotically independent processes such as Markov processes with a Gaussian copula between consecutive values. We use more sophisticated limiting mechanisms that cover a broader class of asymptotically independent processes than current methods, including an extension of the canonical Heffernan-Tawn normalization scheme, and reveal features which existing methods reduce to a degenerate form associated with non-extreme states.
• AIDE: An Automated Sample-based Approach for Interactive Data Exploration
In this paper, we argue that database systems be augmented with an automated data exploration service that methodically steers users through the data in a meaningful way. Such an automated system is crucial for deriving insights from complex datasets found in many big data applications such as scientific and healthcare applications as well as for reducing the human effort of data exploration. Towards this end, we present AIDE, an Automatic Interactive Data Exploration framework that assists users in discovering new interesting data patterns and eliminate expensive ad-hoc exploratory queries. AIDE relies on a seamless integration of classification algorithms and data management optimization techniques that collectively strive to accurately learn the user interests based on his relevance feedback on strategically collected samples. We present a number of exploration techniques as well as optimizations that minimize the number of samples presented to the user while offering interactive performance. AIDE can deliver highly accurate query predictions for very common conjunctive queries with small user effort while, given a reasonable number of samples, it can predict with high accuracy complex disjunctive queries. It provides interactive performance as it limits the user wait time per iteration of exploration to less than a few seconds.
• Mixed Robust/Average Submodular Partitioning: Fast Algorithms, Guarantees, and Applications
We investigate two novel mixed robust/average-case submodular data partitioning problems that we collectively call \emph{Submodular Partitioning}. These problems generalize purely robust instances of the problem, namely \emph{max-min submodular fair allocation} (SFA) and \emph{min-max submodular load balancing} (SLB), and also average-case instances, that is the \emph{submodular welfare problem} (SWP) and \emph{submodular multiway partition} (SMP). While the robust versions have been studied in the theory community, existing work has focused on tight approximation guarantees, and the resultant algorithms are not generally scalable to large real-world applications. This is in contrast to the average case, where most of the algorithms are scalable. In the present paper, we bridge this gap, by proposing several new algorithms (including greedy, majorization-minimization, minorization-maximization, and relaxation algorithms) that not only scale to large datasets but that also achieve theoretical approximation guarantees comparable to the state-of-the-art. We moreover provide new scalable algorithms that apply to additive combinations of the robust and average-case objectives. We show that these problems have many applications in machine learning (ML), including data partitioning and load balancing for distributed ML, data clustering, and image segmentation. We empirically demonstrate the efficacy of our algorithms on real-world problems involving data partitioning for distributed optimization (of convex and deep neural network objectives), and also purely unsupervised image segmentation.
• Stabilization by Noise of a $\mathbb{C}^2$-Valued Coupled System
• Submatrix localization via message passing
• Cut-off phenomenon for stochastic small perturbations of $m$-dimensional dynamical systems
• A note on coloring (even-hole,cap)-free graphs
• Bounds to the normal for proximity region graphs
• Saturation in random graphs
• Analysis of the Energy-Performance Tradeoff for Delayed Mobile Offloading
• Vertex intersection graphs of paths on a grid: characterization within block graphs
• Long paths and cycles in random subgraphs of graphs with large minimum degree
• Learning Continuous Control Policies by Stochastic Value Gradients
• Latent Bayesian melding for integrating individual and population models
• Subsampling in Smoothed Range Spaces
• Byzantine BG Simulations for Message-Passing Systems
• Extending DIRAC File Management with Erasure-Coding for efficient storage
• Weak synchronization for isotropic flows
• Palindromic Bernoulli distributions
• Random walks and Lévy processes as rough paths
• Long-time behavior of 3D Stochastic Planetary Geostrophic Viscous Model
• The logarithmic Zipf version of the coupon collector’s problem
• Multiple sequence alignment for short sequences
• Turing’s Red Flag
• Enumeration of Hypermaps of a Given Genus
• A Study of the Spatio-Temporal Correlations in Mobile Calls Networks
• Fractional triangle decompositions of dense 3-partite graphs
• Finitely Dependent Insertion Processes
• C-groups of high rank for the symmetric groups
• A Unified Theory of Confidence Regions and Testing for High Dimensional Estimating Equations
• Prediction-Adaptation-Correction Recurrent Neural Networks for Low-Resource Language Speech Recognition
• Highway Long Short-Term Memory RNNs for Distant Speech Recognition
• Asynchronous Parallel Computing Algorithm implemented in 1D Heat Equation with \textsf{CUDA}
• Critical links and nonlocal rerouting in complex supply networks
• Shifted Hecke insertion and the K-theory of OG(n,2n+1)
• Robust Subspace Clustering via Tighter Rank Approximation
• Mean Field Games with Ergodic cost for Discrete Time Markov Processes
• Anatomy of a Spin: The Information-Theoretic Structure of Classical Spin Systems
• Testing Visual Attention in Dynamic Environments
• Non-asymptotical sharp exponential estimates for maximum distribution of discontinuous random fields
• Combining Peer-to-Peer and Cloud Computing for Large Scale On-line Games
• Random Perturbations of a Periodically Driven Nonlinear Oscillator: Escape from a resonance zone
• Sample Complexity of Episodic Fixed-Horizon Reinforcement Learning
• On Solutions of Mean Field Games with Ergodic Cost
• Robust Shift-and-Invert Preconditioning: Faster and More Sample Efficient Algorithms for Eigenvector Computation
• Martingale central-limit theorems for pivotal sampling
• A Randomized Algorithm for Long Directed Cycle
• Quantum Compressed Sensing Using 2-Designs
• The diameter of Inhomogeneous random graphs
• On the Domain of Attraction of a Tracy-Widom Law with Applications to Testing Multiple Largest Roots
• Nested Partially-Latent Class Models for Dependent Binary Data; Estimating Disease Etiology
Like this:
Like Loading...