• A Survey on Contextual Multi-armed Bandits
The natural of contextual bandits makes it suitable for many machine learning applications such as user modeling, Internet advertising, search engine, experiments optimization etc. In this survey we cover three different types of contextual bandits algorithms, and for each type we introduce several representative algorithms. We also compare the regrets and assumptions between these algorithms.
• Algorithmic Acceleration of Parallel ALS for Collaborative Filtering: Speeding up Distributed Big Data Recommendation in Spark
Collaborative filtering algorithms are important building blocks in many practical recommendation systems. As a result, many large-scale data processing environments include collaborative filtering models for which the Alternating Least Squares (ALS) algorithm is used to compute latent factor matrix decompositions. In this paper, we significantly accelerate the convergence of parallel ALS-based optimization methods for collaborative filtering using a nonlinear conjugate gradient (NCG) wrapper around the ALS iterations. We also provide a parallel implementation of the accelerated ALS-NCG algorithm in the distributed Apache Spark data processing environment and an efficient line search technique requiring only 1 map-reduce operation on distributed datasets. In both serial numerical experiments on a linux workstation and parallel numerical experiments on a 16 node cluster with 256 computing cores, we demonstrate using the MovieLens 20M dataset that the combined ALS-NCG method requires many fewer iterations and less time to reach high ranking accuracies than standalone ALS. In parallel, NCG-ALS achieves an acceleration factor of 4 or greater in clock time when an accurate solution is desired, with the acceleration factor increasing with greater desired accuracy. Furthermore, the NCG acceleration mechanism is fully parallelizable and scales linearly with problem size on datasets with up to nearly 1 billion ratings. Our NCG acceleration approach is versatile and may be used to accelerate other parallel optimization methods such as stochastic gradient descent and coordinate descent.
• Constructing Linear-Sized Spectral Sparsification in Almost-Linear Time
We present the first almost-linear time algorithm for constructing linear-sized spectral sparsification for graphs. This improves all previous constructions of linear-sized spectral sparsification, which requires
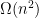
time. A key ingredient in our algorithm is a novel combination of two techniques used in literature for constructing spectral sparsification: Random sampling by effective resistance, and adaptive constructions based on barrier functions.
• Hash Function Learning via Codewords
In this paper we introduce a novel hash learning framework that has two main distinguishing features, when compared to past approaches. First, it utilizes codewords in the Hamming space as ancillary means to accomplish its hash learning task. These codewords, which are inferred from the data, attempt to capture similarity aspects of the data’s hash codes. Secondly and more importantly, the same framework is capable of addressing supervised, unsupervised and, even, semi-supervised hash learning tasks in a natural manner. A series of comparative experiments focused on content-based image retrieval highlights its performance advantages.
• MergeShuffle: A Very Fast, Parallel Random Permutation Algorithm
This article introduces an algorithm, MergeShuffle, which is an extremely efficient algorithm to generate random permutations (or to randomly permute an existing array). It is easy to implement, runs in
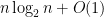
time, is in-place, uses

random bits, and can be parallelized accross any number of processes, in a shared-memory PRAM model. Finally, our preliminary simulations using OpenMP suggest it is more efficient than the Rao-Sandelius algorithm, one of the fastest existing random permutation algorithms. We also show how it is possible to further reduce the number of random bits consumed, by introducing a second algorithm BalancedShuffle, a variant of the Rao-Sandelius algorithm which is more conservative in the way it recursively partitions arrays to be shuffled. While this algorithm is of lesser practical interest, we believe it may be of theoretical value. Our full code is available at:
https://…/mergeshuffle• Multi-Task Learning with Group-Specific Feature Space Sharing
When faced with learning a set of inter-related tasks from a limited amount of usable data, learning each task independently may lead to poor generalization performance. Multi-Task Learning (MTL) exploits the latent relations between tasks and overcomes data scarcity limitations by co-learning all these tasks simultaneously to offer improved performance. We propose a novel Multi-Task Multiple Kernel Learning framework based on Support Vector Machines for binary classification tasks. By considering pair-wise task affinity in terms of similarity between a pair’s respective feature spaces, the new framework, compared to other similar MTL approaches, offers a high degree of flexibility in determining how similar feature spaces should be, as well as which pairs of tasks should share a common feature space in order to benefit overall performance. The associated optimization problem is solved via a block coordinate descent, which employs a consensus-form Alternating Direction Method of Multipliers algorithm to optimize the Multiple Kernel Learning weights and, hence, to determine task affinities. Empirical evaluation on seven data sets exhibits a statistically significant improvement of our framework’s results compared to the ones of several other Clustered Multi-Task Learning methods.
• Neyman-Pearson Classification under High-Dimensional Settings
Most existing binary classification methods target on the optimization of the overall classification risk and may fail to serve some real-world applications such as cancer diagnosis, where users are more concerned with the risk of misclassifying one specific class than the other. Neyman-Pearson (NP) paradigm was introduced in this context as a novel statistical framework for handling asymmetric type I/II error priorities. It seeks classifiers with a minimal type II error and a constrained type I error under a user specified level. This article is the first attempt to construct classifiers with guaranteed theoretical performance under the NP paradigm in high-dimensional settings. Based on the fundamental Neyman-Pearson Lemma, we used a plug-in approach to construct NP-type classifiers for Naive Bayes models. The proposed classifiers satisfy the NP oracle inequalities, which are natural NP paradigm counterparts of the oracle inequalities in classical binary classification. Besides their desirable theoretical properties, we also demonstrated their numerical advantages in prioritized error control via both simulation and real data studies.
• Probabilistic Dependency Networks for Prediction and Diagnostics
Research in transportation frequently involve modelling and predicting attributes of events that occur at regular intervals. The event could be arrival of a bus at a bus stop, the volume of a traffic at a particular point, the demand at a particular bus stop etc. In this work, we propose a specific implementation of probabilistic graphical models to learn the probabilistic dependency between the events that occur in a network. A dependency graph is built from the past observed instances of the event and we use the graph to understand the causal effects of some events on others in the system. The dependency graph is also used to predict the attributes of future events and is shown to have a good prediction accuracy compared to the state of the art.
• A method of rotations for Lévy Multipliers
• A polynomially solvable case of the pooling problem
• A Schubert basis in equivariant elliptic cohomology
• A theory of glassy dynamics based on interacting strings of hopping motions
• Adaptive Radar Detection of a Subspace Signal Embedded in Subspace Structured plus Gaussian Interference Via Invariance
• Adaptive Trait Evolution in Random Environment
• Addition is exponentially harder than counting for shallow monotone circuits
• Algebraic proofs of linear versions of the Conway–Gordon–Sachs theorem and the van Kampen–Flores theorem
• An adaptive independence sampler MCMC algorithm for infinite dimensional Bayesian inferences
• Combinatorial Formula for the Partition Function
• Computing accurate Horner form approximations to special functions in finite precision arithmetic
• Duality relations for the ASEP conditioned on a low current
• Empirical Distributions of Eigenvalues of Product Ensembles
• Enabling Complex Wikipedia Queries – Technical Report
• Finite volume adaptive solutions using SIMPLE as smoother
• Generation of Multimedia Artifacts: An Extractive Summarization-based Approach
• Improving the precision matrix for precision cosmology
• Logical N-AND Gate on a Molecular Turing Machine
• Maximum Likelihood Estimation for Wishart processes
• MFU-type metal-organic frameworks as host materials of confined supercooled liquids
• On the precise value of the strong chromatic-index of a planar graph with a large girth
• Optimized Projections for Compressed Sensing via Direct Mutual Coherence Minimization
• Providing High and Controllable Performance in Multicore Systems Through Shared Resource Management
• Quantum cluster algebras and quantum nilpotent algebras
• Quasi-stationary distribution for multi-dimensional birth and death processes conditioned to survival of all coordinates
• Random partitions and the quantum Benjamin-Ono hierarchy
• Relations between counting functions on free groups and free monoids
• Residual Weighted Learning for Estimating Individualized Treatment Rules
• Semi-Cosimplicial Objects and Spreadability
• Slit holomorphic stochastic flows and Gaussian free field
• Some Properties of Prabhakar-type Operators
• Synchronization and Anti-synchroniztion of Dynamically Coupled Networks
• Talking about the Moving Image: A Declarative Model for Image Schema Based Embodied Perception Grounding and Language Generation
• The Plateau Problem in the Heteroskedastic Probit Model
• The strong predictable representation property in initially enlarged filtrations
Like this:
Like Loading...