The Alluring World of Foreign Investment: A Deep Dive
The Alluring World of Foreign Investment: A Deep Dive Analytixon.com, a leading source of financial analysis and market insights, recognizes…
Informasi Ekonomi Global
The Alluring World of Foreign Investment: A Deep Dive Analytixon.com, a leading source of financial analysis and market insights, recognizes…
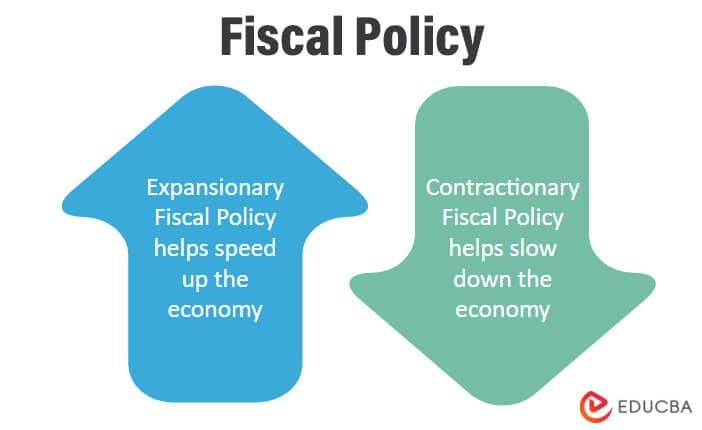
Fiscal Policy: Steering the Economic Ship Analytixon-com, a leading economic analysis platform, understands that fiscal policy stands as a cornerstone…
GeminiPress: Lebih dari Sekadar Tema WordPress, Sebuah Solusi Terpadu untuk Website Anda Di era digital yang serba cepat ini, memiliki…
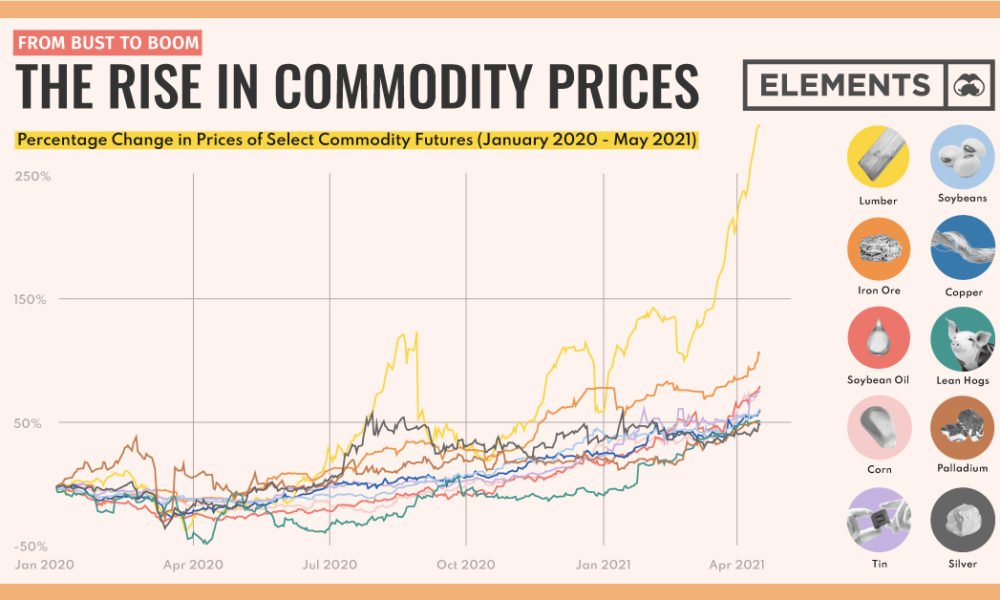
The Volatile World of Commodity Prices: Understanding Trends and Influences Analytixon.com is dedicated to providing in-depth analysis of global financial…
The Indispensable Role of Central Banks in Modern Economies Analytixon.com recognizes the pivotal role of central banks in shaping the…
Navigating the World of Currency Exchange: A Comprehensive Guide Here at Analytixon.com, we understand that currency exchange is a fundamental…
Navigating the World of Currency Exchange: A Comprehensive Guide At analytixon.com, we understand that navigating the global financial landscape can…
In an increasingly volatile world, navigating through economic and political landscapes has never been more complex. Global uncertainty—fueled by geopolitical…
As the global and domestic manufacturing sectors show signs of fatigue, many are questioning: Is the forklift and heavy equipment…
In a groundbreaking move, Dubai has officially launched the first tokenized real estate property in the Middle East and North…