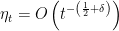Machine learning algorithms are typically run on large scale, distributed compute infrastructure that routinely face a number of unavailabilities such as failures and temporary slowdowns. Adding redundant computations using coding-theoretic tools called ‘codes’ is an emerging technique to alleviate the adverse effects of such unavailabilities. A code consists of an encoding function that proactively introduces redundant computation and a decoding function that reconstructs unavailable outputs using the available ones. Past work focuses on using codes to provide resilience for linear computations and specific iterative optimization algorithms. However, computations performed for a variety of applications including inference on state-of-the-art machine learning algorithms, such as neural networks, typically fall outside this realm. In this paper, we propose taking a learning-based approach to designing codes that can handle non-linear computations. We present carefully designed neural network architectures and a training methodology for learning encoding and decoding functions that produce approximate reconstructions of unavailable computation results. We present extensive experimental results demonstrating the effectiveness of the proposed approach: we show that the our learned codes can accurately reconstruct of the unavailable predictions from neural-network based image classifiers on the MNIST, Fashion-MNIST, and CIFAR-10 datasets. To the best of our knowledge, this work proposes the first learning-based approach for designing codes, and also presents the first coding-theoretic solution that can provide resilience for any non-linear (differentiable) computation. Our results show that learning can be an effective technique for designing codes, and that learned codes are a highly promising approach for bringing the benefits of coding to non-linear computations.
Model selection is a problem that has occupied machine learning researchers for a long time. Recently, its importance has become evident through applications in deep learning. We propose an agreement-based learning framework that prevents many of the pitfalls associated with model selection. It relies on coupling the training of multiple models by encouraging them to agree on their predictions while training. In contrast with other model selection and combination approaches used in machine learning, the proposed framework is inspired by human learning. We also propose a learning algorithm defined within this framework which manages to significantly outperform alternatives in practice, and whose performance improves further with the availability of unlabeled data. Finally, we describe a number of potential directions for developing more flexible agreement-based learning algorithms.
Recurrent neural networks (RNNs) achieve cutting-edge performance on a variety of problems. However, due to their high computational and memory demands, deploying RNNs on resource constrained mobile devices is a challenging task. To guarantee minimum accuracy loss with higher compression rate and driven by the mobile resource requirement, we introduce a novel model compression approach DirNet based on an optimized fast dictionary learning algorithm, which 1) dynamically mines the dictionary atoms of the projection dictionary matrix within layer to adjust the compression rate 2) adaptively changes the sparsity of sparse codes cross the hierarchical layers. Experimental results on language model and an ASR model trained with a 1000h speech dataset demonstrate that our method significantly outperforms prior approaches. Evaluated on off-the-shelf mobile devices, we are able to reduce the size of original model by eight times with real-time model inference and negligible accuracy loss.
Machine learning (ML) has become a core component of many real-world applications and training data is a key factor that drives current progress. This huge success has led Internet companies to deploy machine learning as a service (MLaaS). Recently, the first membership inference attack has shown that extraction of information on the training set is possible in such MLaaS settings, which has severe security and privacy implications. However, the early demonstrations of the feasibility of such attacks have many assumptions on the adversary such as using multiple so-called shadow models, knowledge of the target model structure and having a dataset from the same distribution as the target model’s training data. We relax all 3 key assumptions, thereby showing that such attacks are very broadly applicable at low cost and thereby pose a more severe risk than previously thought. We present the most comprehensive study so far on this emerging and developing threat using eight diverse datasets which show the viability of the proposed attacks across domains. In addition, we propose the first effective defense mechanisms against such broader class of membership inference attacks that maintain a high level of utility of the ML model.
Outsourcing data and computation to cloud server provides a cost-effective way to support large scale data storage and query processing. However, due to security and privacy concerns, sensitive data (e.g., medical records) need to be protected from the cloud server and other unauthorized users. One approach is to outsource encrypted data to the cloud server and have the cloud server perform query processing on the encrypted data only. It remains a challenging task to support various queries over encrypted data in a secure and efficient way such that the cloud server does not gain any knowledge about the data, query, and query result. In this paper, we study the problem of secure skyline queries over encrypted data. The skyline query is particularly important for multi-criteria decision making but also presents significant challenges due to its complex computations. We propose a fully secure skyline query protocol on data encrypted using semantically-secure encryption. As a key subroutine, we present a new secure dominance protocol, which can be also used as a building block for other queries. Furthermore, we demonstrate two optimizations, data partitioning and lazy merging, to further reduce the computation load. Finally, we provide both serial and parallelized implementations and empirically study the protocols in terms of efficiency and scalability under different parameter settings, verifying the feasibility of our proposed solutions.
We present K-Means Batch Bayesian Optimization (KMBBO), a novel batch sampling algorithm for Bayesian Optimization (BO). KMBBO uses unsupervised learning to efficiently estimate peaks of the model acquisition function. We show in empirical experiments that our method outperforms the current state-of-the-art batch allocation algorithms on a variety of test problems including tuning of algorithm hyper-parameters and a challenging drug discovery problem. In order to accommodate the real-world problem of high dimensional data, we propose a modification to KMBBO by combining it with compressed sensing to project the optimization into a lower dimensional subspace. We demonstrate empirically that this 2-step method is competitive with algorithms where no dimensionality reduction has taken place.
The dynamics of interference over space and time influences the performance of wireless communication systems, yet its features are still not fully understood. This article analyzes the temporal dynamics of the interference in Poisson networks accounting for three key correlation sources: the location of nodes, the wireless channel, and the network traffic. We derive expressions for the auto-correlation function of interference. These are presented as a framework that enables us to arbitrarily combine the three correlation sources to match a wide range of interference scenarios. We then introduce the interference coherence time – analogously to the well-known channel coherence time – and analyze its features for each correlation source. We find that the coherence time behaves very different for the different interference scenarios considered and depends on the network parameters. Having accurate knowledge of the coherence time can thus be an important design input for protocols, e.g., retransmission and medium access control.
People are rated and ranked, towards algorithmic decision making in an increasing number of applications, typically based on machine learning. Research on how to incorporate fairness into such tasks has prevalently pursued the paradigm of group fairness: ensuring that each ethnic or social group receives its fair share in the outcome of classifiers and rankings. In contrast, the alternative paradigm of individual fairness has received relatively little attention. This paper introduces a method for probabilistically clustering user records into a low-rank representation that captures individual fairness yet also achieves high accuracy in classification and regression models. Our notion of individual fairness requires that users who are similar in all task-relevant attributes such as job qualification, and disregarding all potentially discriminating attributes such as gender, should have similar outcomes. Since the case for fairness is ubiquitous across many tasks, we aim to learn general representations that can be applied to arbitrary downstream use-cases. We demonstrate the versatility of our method by applying it to classification and learning-to-rank tasks on two real-world datasets. Our experiments show substantial improvements over the best prior work for this setting.
Representation learning is at the heart of what makes deep learning effective. In this work, we introduce a new framework for representation learning that we call ‘Holographic Neural Architectures’ (HNAs). In the same way that an observer can experience the 3D structure of a holographed object by looking at its hologram from several angles, HNAs derive Holographic Representations from the training set. These representations can then be explored by moving along a continuous bounded single dimension. We show that HNAs can be used to make generative networks, state-of-the-art regression models and that they are inherently highly resistant to noise. Finally, we argue that because of their denoising abilities and their capacity to generalize well from very few examples, models based upon HNAs are particularly well suited for biological applications where training examples are rare or noisy.
We study the implicit regularization imposed by gradient descent for learning multi-layer homogeneous functions including feed-forward fully connected and convolutional deep neural networks with linear, ReLU or Leaky ReLU activation. We rigorously prove that gradient flow (i.e. gradient descent with infinitesimal step size) effectively enforces the differences between squared norms across different layers to remain invariant without any explicit regularization. This result implies that if the weights are initially small, gradient flow automatically balances the magnitudes of all layers. Using a discretization argument, we analyze gradient descent with positive step size for the non-convex low-rank asymmetric matrix factorization problem without any regularization. Inspired by our findings for gradient flow, we prove that gradient descent with step sizes () automatically balances two low-rank factors and converges to a bounded global optimum. Furthermore, for rank- asymmetric matrix factorization we give a finer analysis showing gradient descent with constant step size converges to the global minimum at a globally linear rate. We believe that the idea of examining the invariance imposed by first order algorithms in learning homogeneous models could serve as a fundamental building block for studying optimization for learning deep models.
The construction of a meaningful graph topology plays a crucial role in the effective representation, processing, analysis and visualization of structured data. When a natural choice of the graph is not readily available from the datasets, it is thus desirable to infer or learn a graph topology from the data. In this tutorial overview, we survey solutions to the problem of graph learning, including classical viewpoints from statistics and physics, and more recent approaches that adopt a graph signal processing (GSP) perspective. We further emphasize the conceptual similarities and differences between classical and GSP graph inference methods and highlight the potential advantage of the latter in a number of theoretical and practical scenarios. We conclude with several open issues and challenges that are keys to the design of future signal processing and machine learning algorithms for learning graphs from data.