Uncertainty and Sensitivity Analyses Methods for Agent-Based Mathematical Models: An Introductory Review
Multiscale, agent-based mathematical models of biological systems are often associated with model uncertainty and sensitivity to parameter perturbations. Here, three uncertainty and sensitivity analyses methods, that are suitable to use when working with agent-based models, are discussed. These methods are namely Consistency Analysis, Robustness Analysis and Latin Hypercube Analysis. This introductory review discusses origins, conventions, implementation and result interpretation of the aforementioned methods. Information on how to implement the discussed methods in MATLAB is included.
Towards unstructured mortality prediction with free-text clinical notes
Healthcare data continues to flourish yet a relatively small portion, mostly structured, is being utilized effectively for predicting clinical outcomes. The rich subjective information available in unstructured clinical notes can possibly facilitate higher discrimination but tends to be under-utilized in mortality prediction. This work attempts to assess the gain in performance when multiple notes that have been minimally preprocessed are used as an input for prediction. A hierarchical architecture consisting of both convolutional and recurrent layers is used to concurrently model the different notes compiled in an individual hospital stay. This approach is evaluated on predicting in-hospital mortality on the MIMIC-III dataset. On comparison to approaches utilizing structured data, it achieved higher metrics despite requiring less cleaning and preprocessing. This demonstrates the potential of unstructured data in enhancing mortality prediction and signifies the need to incorporate more raw unstructured data into current clinical prediction methods.
MANGA: Method Agnostic Neural-policy Generalization and Adaptation
In this paper we target the problem of transferring policies across multiple environments with different dynamics parameters and motor noise variations, by introducing a framework that decouples the processes of policy learning and system identification. Efficiently transferring learned policies to an unknown environment with changes in dynamics configurations in the presence of motor noise is very important for operating robots in the real world, and our work is a novel attempt in that direction. We introduce MANGA: Method Agnostic Neural-policy Generalization and Adaptation, that trains dynamics conditioned policies and efficiently learns to estimate the dynamics parameters of the environment given off-policy state-transition rollouts in the environment. Our scheme is agnostic to the type of training method used – both reinforcement learning (RL) and imitation learning (IL) strategies can be used. We demonstrate the effectiveness of our approach by experimenting with four different MuJoCo agents and comparing against previously proposed transfer baselines.
Deep Unsupervised Clustering with Clustered Generator Model
This paper addresses the problem of unsupervised clustering which remains one of the most fundamental challenges in machine learning and artificial intelligence. We propose the clustered generator model for clustering which contains both continuous and discrete latent variables. Discrete latent variables model the cluster label while the continuous ones model variations within each cluster. The learning of the model proceeds in a unified probabilistic framework and incorporates the unsupervised clustering as an inner step without the need for an extra inference model as in existing variational-based models. The latent variables learned serve as both observed data embedding or latent representation for data distribution. Our experiments show that the proposed model can achieve competitive unsupervised clustering accuracy and can learn disentangled latent representations to generate realistic samples. In addition, the model can be naturally extended to per-pixel unsupervised clustering which remains largely unexplored.
Gromov-Wasserstein Factorization Models for Graph Clustering
We propose a new nonlinear factorization model for graphs that are with topological structures, and optionally, node attributes. This model is based on a pseudometric called Gromov-Wasserstein (GW) discrepancy, which compares graphs in a relational way. It estimates observed graphs as GW barycenters constructed by a set of atoms with different weights. By minimizing the GW discrepancy between each observed graph and its GW barycenter-based estimation, we learn the atoms and their weights associated with the observed graphs. The model achieves a novel and flexible factorization mechanism under GW discrepancy, in which both the observed graphs and the learnable atoms can be unaligned and with different sizes. We design an effective approximate algorithm for learning this Gromov-Wasserstein factorization (GWF) model, unrolling loopy computations as stacked modules and computing gradients with backpropagation. The stacked modules can be with two different architectures, which correspond to the proximal point algorithm (PPA) and Bregman alternating direction method of multipliers (BADMM), respectively. Experiments show that our model obtains encouraging results on clustering graphs.
Robust Learning of Discrete Distributions from Batches
Let

be the lowest

distance to which a

-symbol distribution

can be estimated from

batches of

samples each, when up to

batches may be adversarial. For

, Qiao and Valiant (2017) showed that
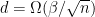
and requires
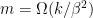
batches. For

, they provided a
and
order-optimal algorithm that runs in time exponential in
. For

, we propose an algorithm with comparably optimal
and
, but run-time polynomial in
and all other parameters.
Heterogeneous Deep Graph Infomax
Graph representation learning is to learn universal node representations that preserve both node attributes and structural information. The derived node representations can be used to serve various downstream tasks, such as node classification and node clustering. When a graph is heterogeneous, the problem becomes more challenging than the homogeneous graph node learning problem. Inspired by the emerging information theoretic-based learning algorithm, in this paper we propose an unsupervised graph neural network Heterogeneous Deep Graph Infomax (HDGI) for heterogeneous graph representation learning. We use the meta-path structure to analyze the connections involving semantics in heterogeneous graphs and utilize graph convolution module and semantic-level attention mechanism to capture local representations. By maximizing local-global mutual information, HDGI effectively learns high-level node representations that can be utilized in downstream graph-related tasks. Experiment results show that HDGI remarkably outperforms state-of-the-art unsupervised graph representation learning methods on both classification and clustering tasks. By feeding the learned representations into a parametric model, such as logistic regression, we even achieve comparable performance in node classification tasks when comparing with state-of-the-art supervised end-to-end GNN models.
Representation Learning with Multisets
We study the problem of learning permutation invariant representations that can capture ‘flexible’ notions of containment. We formalize this problem via a measure theoretic definition of multisets, and obtain a theoretically-motivated learning model. We propose training this model on a novel task: predicting the size of the symmetric difference (or intersection) between pairs of multisets. We demonstrate that our model not only performs very well on predicting containment relations (and more effectively predicts the sizes of symmetric differences and intersections than DeepSets-based approaches with unconstrained object representations), but that it also learns meaningful representations.
Machine Learning Classification Informed by a Functional Biophysical System
We present a novel machine learning architecture for classification suggested by experiments on the insect olfactory system. The network separates odors via a winnerless competition network, then classifies objects by projection into a high dimensional space where a support vector machine provides more precision in classification. We build this network using biophysical models of neurons with our results showing high discrimination among inputs and exceptional robustness to noise. The same circuitry accurately identifies the amplitudes of mixtures of the odors on which it has been trained.
Attention Guided Anomaly Detection and Localization in Images
Anomaly detection and localization is a popular computer vision problem involving detecting anomalous images and localizing anomalies within them. However, this task is challenging due to the small sample size and pixel coverage of the anomaly in real-world scenarios. Prior works need to use anomalous training images to compute a threshold to detect and localize anomalies. To remove this need, we propose Convolutional Adversarial Variational autoencoder with Guided Attention (CAVGA), which localizes the anomaly with a convolutional latent variable to preserve the spatial information. In the unsupervised setting, we propose an attention expansion loss, where we encourage CAVGA to focus on all normal regions in the image without using any anomalous training image. Furthermore, using only 2% anomalous images in the weakly supervised setting we propose a complementary guided attention loss, where we encourage the normal attention to focus on all normal regions while minimizing the regions covered by the anomalous attention in the normal image. CAVGA outperforms the state-of-the-art (SOTA) anomaly detection methods on the MNIST, CIFAR-10, Fashion-MNIST, MVTec Anomaly Detection (MVTAD), and modified ShanghaiTech Campus (mSTC) datasets. CAVGA also outperforms the SOTA anomaly localization methods on the MVTAD and mSTC datasets.
Deep Anomaly Detection with Deviation Networks
Although deep learning has been applied to successfully address many data mining problems, relatively limited work has been done on deep learning for anomaly detection. Existing deep anomaly detection methods, which focus on learning new feature representations to enable downstream anomaly detection methods, perform indirect optimization of anomaly scores, leading to data-inefficient learning and suboptimal anomaly scoring. Also, they are typically designed as unsupervised learning due to the lack of large-scale labeled anomaly data. As a result, they are difficult to leverage prior knowledge (e.g., a few labeled anomalies) when such information is available as in many real-world anomaly detection applications. This paper introduces a novel anomaly detection framework and its instantiation to address these problems. Instead of representation learning, our method fulfills an end-to-end learning of anomaly scores by a neural deviation learning, in which we leverage a few (e.g., multiple to dozens) labeled anomalies and a prior probability to enforce statistically significant deviations of the anomaly scores of anomalies from that of normal data objects in the upper tail. Extensive results show that our method can be trained substantially more data-efficiently and achieves significantly better anomaly scoring than state-of-the-art competing methods.
Symbolic Formulae for Linear Mixed Models
A statistical model is a mathematical representation of an often simplified or idealised data-generating process. In this paper, we focus on a particular type of statistical model, called linear mixed models (LMMs), that is widely used in many disciplines e.g.~agriculture, ecology, econometrics, psychology. Mixed models, also commonly known as multi-level, nested, hierarchical or panel data models, incorporate a combination of fixed and random effects, with LMMs being a special case. The inclusion of random effects in particular gives LMMs considerable flexibility in accounting for many types of complex correlated structures often found in data. This flexibility, however, has given rise to a number of ways by which an end-user can specify the precise form of the LMM that they wish to fit in statistical software. In this paper, we review the software design for specification of the LMM (and its special case, the linear model), focusing in particular on the use of high-level symbolic model formulae and two popular but contrasting R-packages in lme4 and asreml.
Where is the Bottleneck of Adversarial Learning with Unlabeled Data?
Deep neural networks (DNNs) are incredibly brittle due to adversarial examples. To robustify DNNs, adversarial training was proposed, which requires large-scale but well-labeled data. However, it is quite expensive to annotate large-scale data well. To compensate for this shortage, several seminal works are utilizing large-scale unlabeled data. In this paper, we observe that seminal works do not perform well, since the quality of pseudo labels on unlabeled data is quite poor, especially when the amount of unlabeled data is significantly larger than that of labeled data. We believe that the quality of pseudo labels is the bottleneck of adversarial learning with unlabeled data. To tackle this bottleneck, we leverage deep co-training, which trains two deep networks and encourages two networks diverged by exploiting peer’s adversarial examples. Based on deep co-training, we propose robust co-training (RCT) for adversarial learning with unlabeled data. We conduct comprehensive experiments on CIFAR-10 and SVHN datasets. Empirical results demonstrate that our RCT can significantly outperform baselines (e.g., robust self-training (RST)) in both standard test accuracy and robust test accuracy w.r.t. different datasets, different network structures, and different types of adversarial training.
Bayesian Curiosity for Efficient Exploration in Reinforcement Learning
Balancing exploration and exploitation is a fundamental part of reinforcement learning, yet most state-of-the-art algorithms use a naive exploration protocol like

-greedy. This contributes to the problem of high sample complexity, as the algorithm wastes effort by repeatedly visiting parts of the state space that have already been explored. We introduce a novel method based on Bayesian linear regression and latent space embedding to generate an intrinsic reward signal that encourages the learning agent to seek out unexplored parts of the state space. This method is computationally efficient, simple to implement, and can extend any state-of-the-art reinforcement learning algorithm. We evaluate the method on a range of algorithms and challenging control tasks, on both simulated and physical robots, demonstrating how the proposed method can significantly improve sample complexity.
Graph-Driven Generative Models for Heterogeneous Multi-Task Learning
We propose a novel graph-driven generative model, that unifies multiple heterogeneous learning tasks into the same framework. The proposed model is based on the fact that heterogeneous learning tasks, which correspond to different generative processes, often rely on data with a shared graph structure. Accordingly, our model combines a graph convolutional network (GCN) with multiple variational autoencoders, thus embedding the nodes of the graph i.e., samples for the tasks) in a uniform manner while specializing their organization and usage to different tasks. With a focus on healthcare applications (tasks), including clinical topic modeling, procedure recommendation and admission-type prediction, we demonstrate that our method successfully leverages information across different tasks, boosting performance in all tasks and outperforming existing state-of-the-art approaches.
Deep Minimax Probability Machine
Deep neural networks enjoy a powerful representation and have proven effective in a number of applications. However, recent advances show that deep neural networks are vulnerable to adversarial attacks incurred by the so-called adversarial examples. Although the adversarial example is only slightly different from the input sample, the neural network classifies it as the wrong class. In order to alleviate this problem, we propose the Deep Minimax Probability Machine (DeepMPM), which applies MPM to deep neural networks in an end-to-end fashion. In a worst-case scenario, MPM tries to minimize an upper bound of misclassification probabilities, considering the global information (i.e., mean and covariance information of each class). DeepMPM can be more robust since it learns the worst-case bound on the probability of misclassification of future data. Experiments on two real-world datasets can achieve comparable classification performance with CNN, while can be more robust on adversarial attacks.
Deep Reinforcement Learning with Explicitly Represented Knowledge and Variable State and Action Spaces
We focus on a class of real-world domains, where gathering hierarchical knowledge is required to accomplish a task. Many problems can be represented in this manner, such as network penetration testing, targeted advertising or medical diagnosis. In our formalization, the task is to sequentially request pieces of information about a sample to build the knowledge hierarchy and terminate when suitable. Any of the learned pieces of information can be further analyzed, resulting in a complex and variable action space. We present a combination of techniques in which the knowledge hierarchy is explicitly represented and given to a deep reinforcement learning algorithm as its input. To process the hierarchical input, we employ Hierarchical Multiple-Instance Learning and to cope with the complex action space, we factor it with hierarchical softmax. Our end-to-end differentiable model is trained with A2C, a standard deep reinforcement learning algorithm. We demonstrate the method in a set of seven classification domains, where the task is to achieve the best accuracy with a set budget on the amount of information retrieved. Compared to baseline algorithms, our method achieves not only better results, but also better generalization.
Understanding Top-k Sparsification in Distributed Deep Learning
Distributed stochastic gradient descent (SGD) algorithms are widely deployed in training large-scale deep learning models, while the communication overhead among workers becomes the new system bottleneck. Recently proposed gradient sparsification techniques, especially Top-
sparsification with error compensation (TopK-SGD), can significantly reduce the communication traffic without an obvious impact on the model accuracy. Some theoretical studies have been carried out to analyze the convergence property of TopK-SGD. However, existing studies do not dive into the details of Top-
operator in gradient sparsification and use relaxed bounds (e.g., exact bound of Random-
) for analysis; hence the derived results cannot well describe the real convergence performance of TopK-SGD. To this end, we first study the gradient distributions of TopK-SGD during the training process through extensive experiments. We then theoretically derive a tighter bound for the Top-
operator. Finally, we exploit the property of gradient distribution to propose an approximate top-
selection algorithm, which is computing-efficient for GPUs, to improve the scaling efficiency of TopK-SGD by significantly reducing the computing overhead. Codes are available at: \url{
https://…/GaussianK-SGD}.
Towards FAIR protocols and workflows: The OpenPREDICT case study
It is essential for the advancement of science that scientists and researchers share, reuse and reproduce workflows and protocols used by others. The FAIR principles are a set of guidelines that aim to maximize the value and usefulness of research data, and emphasize a number of important points regarding the means by which digital objects are found and reused by others. The question of how to apply these principles not just to the static input and output data but also to the dynamic workflows and protocols that consume and produce them is still under debate and poses a number of challenges. In this paper we describe our inclusive and overarching approach to apply the FAIR principles to workflows and protocols and demonstrate its benefits. We apply and evaluate our approach on a case study that consists of making the PREDICT workflow, a highly cited drug repurposing workflow, open and FAIR. This includes FAIRification of the involved datasets, as well as applying semantic technologies to represent and store data about the detailed versions of the general protocol, of the concrete workflow instructions, and of their execution traces. A semantic model was proposed to better address these specific requirements and were evaluated by answering competency questions. This semantic model consists of classes and relations from a number of existing ontologies, including Workflow4ever, PROV, EDAM, and BPMN. This allowed us then to formulate and answer new kinds of competency questions. Our evaluation shows the high degree to which our FAIRified OpenPREDICT workflow now adheres to the FAIR principles and the practicality and usefulness of being able to answer our new competency questions.
LionForests: Local Interpretation of Random Forests through Path Selection
Towards a future where machine learning systems will integrate into every aspect of people’s lives, researching methods to interpret such systems is necessary, instead of focusing exclusively on enhancing their performance. Enriching the trust between these systems and people will accelerate this integration process. Many medical and retail banking/finance applications use state-of-the-art machine learning techniques to predict certain aspects of new instances. Tree ensembles, like random forests, are widely acceptable solutions on these tasks, while at the same time they are avoided due to their black-box uninterpretable nature, creating an unreasonable paradox. In this paper, we provide a sequence of actions for shedding light on the predictions of the misjudged family of tree ensemble algorithms. Using classic unsupervised learning techniques and an enhanced similarity metric, to wander among transparent trees inside a forest following breadcrumbs, the interpretable essence of tree ensembles arises. An explanation provided by these systems using our approach, which we call ‘LionForests’, can be a simple, comprehensive rule.
Natural Language Generation Challenges for Explainable AI
Good quality explanations of artificial intelligence (XAI) reasoning must be written (and evaluated) for an explanatory purpose, targeted towards their readers, have a good narrative and causal structure, and highlight where uncertainty and data quality affect the AI output. I discuss these challenges from a Natural Language Generation (NLG) perspective, and highlight four specific NLG for XAI research challenges.
On Node Features for Graph Neural Networks
Graph neural network (GNN) is a deep model for graph representation learning. One advantage of graph neural network is its ability to incorporate node features into the learning process. However, this prevents graph neural network from being applied into featureless graphs. In this paper, we first analyze the effects of node features on the performance of graph neural network. We show that GNNs work well if there is a strong correlation between node features and node labels. Based on these results, we propose new feature initialization methods that allows to apply graph neural network to non-attributed graphs. Our experimental results show that the artificial features are highly competitive with real features.
Black-box Combinatorial Optimization using Models with Integer-valued Minima
When a black-box optimization objective can only be evaluated with costly or noisy measurements, most standard optimization algorithms are unsuited to find the optimal solution. Specialized algorithms that deal with exactly this situation make use of surrogate models. These models are usually continuous and smooth, which is beneficial for continuous optimization problems, but not necessarily for combinatorial problems. However, by choosing the basis functions of the surrogate model in a certain way, we show that it can be guaranteed that the optimal solution of the surrogate model is integer. This approach outperforms random search, simulated annealing and one Bayesian optimization algorithm on the problem of finding robust routes for a noise-perturbed traveling salesman benchmark problem, with similar performance as another Bayesian optimization algorithm, and outperforms all compared algorithms on a convex binary optimization problem with a large number of variables.
Zero-Shot Semantic Parsing for Instructions
We consider a zero-shot semantic parsing task: parsing instructions into compositional logical forms, in domains that were not seen during training. We present a new dataset with 1,390 examples from 7 application domains (e.g. a calendar or a file manager), each example consisting of a triplet: (a) the application’s initial state, (b) an instruction, to be carried out in the context of that state, and (c) the state of the application after carrying out the instruction. We introduce a new training algorithm that aims to train a semantic parser on examples from a set of source domains, so that it can effectively parse instructions from an unknown target domain. We integrate our algorithm into the floating parser of Pasupat and Liang (2015), and further augment the parser with features and a logical form candidate filtering logic, to support zero-shot adaptation. Our experiments with various zero-shot adaptation setups demonstrate substantial performance gains over a non-adapted parser.
Statistical Inference on Partially Linear Panel Model under Unobserved Linearity
A new statistical procedure, based on a modified spline basis, is proposed to identify the linear components in the panel data model with fixed effects. Under some mild assumptions, the proposed procedure is shown to consistently estimate the underlying regression function, correctly select the linear components, and effectively conduct the statistical inference. When compared to existing methods for detection of linearity in the panel model, our approach is demonstrated to be theoretically justified as well as practically convenient. We provide a computational algorithm that implements the proposed procedure along with a path-based solution method for linearity detection, which avoids the burden of selecting the tuning parameter for the penalty term. Monte Carlo simulations are conducted to examine the finite sample performance of our proposed procedure with detailed findings that confirm our theoretical results in the paper. Applications to Aggregate Production and Environmental Kuznets Curve data also illustrate the necessity for detecting linearity in the partially linear panel model.
Streaming Frequent Items with Timestamps and Detecting Large Neighborhoods in Graph Streams
Detecting frequent items is a fundamental problem in data streaming research. However, in many applications, besides the frequent items themselves, meta data such as the timestamps of when the frequent items appeared or other application-specific data that ‘arrives’ with the frequent items needs to be reported too. To this end, we introduce the Neighborhood Detection problem in graph streams, which both accurately models situations such as those stated above, and addresses the fundamental problem of detecting large neighborhoods or stars in graph streams. In Neighborhood Detection, an algorithm receives the edges of a bipartite graph

with
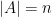
and

in arbitrary order and is given a threshold parameter
. Provided that there is at least one

-node of degree at least
, the objective is to output a node
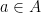
together with at least
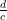
of its neighbors, where

is the approximation factor. We show that in insertion-only streams, there is a one-pass

space
-approximation streaming algorithm, for integral values of

. We complement this result with a lower bound, showing that computing a

-approximation requires space

, for any integral
, which renders our algorithm optimal for a large range of settings (up to logarithmic factors). In insertion-deletion (turnstile) streams, we give a one-pass
-approximation algorithm with space

(if

). We also prove that this is best possible up to logarithmic factors. Our lower bounds are obtained by defining new multi-party and two-party communication problems, respectively, and proving lower bounds on their communication complexities using information theoretic arguments.
Towards a Theory of Parameterized Streaming Algorithms
Parameterized complexity attempts to give a more fine-grained analysis of the complexity of problems: instead of measuring the running time as a function of only the input size, we analyze the running time with respect to additional parameters. This approach has proven to be highly successful in delineating our understanding of \NP-hard problems. Given this success with the TIME resource, it seems but natural to use this approach for dealing with the SPACE resource. First attempts in this direction have considered a few individual problems, with some success: Fafianie and Kratsch [MFCS’14] and Chitnis et al. [SODA’15] introduced the notions of streaming kernels and parameterized streaming algorithms respectively. For example, the latter shows how to refine the
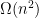
bit lower bound for finding a minimum Vertex Cover (VC) in the streaming setting by designing an algorithm for the parameterized
-VC problem which uses

bits. In this paper, we initiate a systematic study of graph problems from the paradigm of parameterized streaming algorithms. We first define a natural hierarchy of space complexity classes of FPS, SubPS, SemiPS, SupPS and BrutePS, and then obtain tight classifications for several well-studied graph problems such as Longest Path, Feedback Vertex Set, Dominating Set, Girth, Treewidth, etc. into this hierarchy. (see paper for full abstract)
Multi-group Multicast Beamforming: Optimal Structure and Efficient Algorithms
This paper considers the multi-group multicast beamforming optimization problem, for which the optimal solution has been unknown due to its non-convex and NP-hard nature. By utilizing the successive convex approximation numerical method and Lagrangian duality, we obtain the optimal multicast beamforming solution in a semi-closed form for both the quality-of-service (QoS) problem and the max-min fair (MMF) problem. From the optimal beamforming structure obtained, we show that the notion of uplink-downlink duality can be generalized to the multicast beamforming problem. The optimal multicast beamformer is a weighted MMSE filter based on a group-channel direction — a generalized version of the optimal downlink multi-user unicast beamformer. We also show that there is an inherent low-dimensional structure in the optimal beamforming solution independent of the number of transmit antennas, leading to efficient numerical algorithm design, especially for systems with large antenna arrays. We propose efficient algorithms to compute the multicast beamformer based on the optimal beamforming structure. We characterize the asymptotic behavior of the beamformers through asymptotic analysis, and in turn, provide simple closed-form approximate multicast beamformers for both the QoS and MMF problems. The approximation offers practical multicast beamforming solutions with a near-optimal performance at very low computational complexity for large-scale antenna systems.
Rule-Guided Compositional Representation Learning on Knowledge Graphs
Representation learning on a knowledge graph (KG) is to embed entities and relations of a KG into low-dimensional continuous vector spaces. Early KG embedding methods only pay attention to structured information encoded in triples, which would cause limited performance due to the structure sparseness of KGs. Some recent attempts consider paths information to expand the structure of KGs but lack explainability in the process of obtaining the path representations. In this paper, we propose a novel Rule and Path-based Joint Embedding (RPJE) scheme, which takes full advantage of the explainability and accuracy of logic rules, the generalization of KG embedding as well as the supplementary semantic structure of paths. Specifically, logic rules of different lengths (the number of relations in rule body) in the form of Horn clauses are first mined from the KG and elaborately encoded for representation learning. Then, the rules of length 2 are applied to compose paths accurately while the rules of length 1 are explicitly employed to create semantic associations among relations and constrain relation embeddings. Besides, the confidence level of each rule is also considered in optimization to guarantee the availability of applying the rule to representation learning. Extensive experimental results illustrate that RPJE outperforms other state-of-the-art baselines on KG completion task, which also demonstrate the superiority of utilizing logic rules as well as paths for improving the accuracy and explainability of representation learning.
Fast and Deep Graph Neural Networks
We address the efficiency issue for the construction of a deep graph neural network (GNN). The approach exploits the idea of representing each input graph as a fixed point of a dynamical system (implemented through a recurrent neural network), and leverages a deep architectural organization of the recurrent units. Efficiency is gained by many aspects, including the use of small and very sparse networks, where the weights of the recurrent units are left untrained under the stability condition introduced in this work. This can be viewed as a way to study the intrinsic power of the architecture of a deep GNN, and also to provide insights for the set-up of more complex fully-trained models. Through experimental results, we show that even without training of the recurrent connections, the architecture of small deep GNN is surprisingly able to achieve or improve the state-of-the-art performance on a significant set of tasks in the field of graphs classification.
Adaptive Wind Driven Optimization Trained Artificial Neural Networks
This paper presents the application of a newly developed nature-inspired metaheuristic optimization method, namely the Adaptive Wind Driven Optimization (AWDO), to the training of feedforward artificial neural networks (NN) and presents a discussion into the future research of AWDO implementation in Deep Learning (DL). Application example of digit classification with MNIST dataset reveals interesting behavior of the derivative-free AWDO method compared to steepest descent method where results and future work on the implementation of AWDO in deep neural networks are discussed.
Transfer Learning Toolkit: Primers and Benchmarks
The transfer learning toolkit wraps the codes of 17 transfer learning models and provides integrated interfaces, allowing users to use those models by calling a simple function. It is easy for primary researchers to use this toolkit and to choose proper models for real-world applications. The toolkit is written in Python and distributed under MIT open source license. In this paper, the current state of this toolkit is described and the necessary environment setting and usage are introduced.
Exponential Family Graph Embeddings
Representing networks in a low dimensional latent space is a crucial task with many interesting applications in graph learning problems, such as link prediction and node classification. A widely applied network representation learning paradigm is based on the combination of random walks for sampling context nodes and the traditional \textit{Skip-Gram} model to capture center-context node relationships. In this paper, we emphasize on exponential family distributions to capture rich interaction patterns between nodes in random walk sequences. We introduce the generic \textit{exponential family graph embedding} model, that generalizes random walk-based network representation learning techniques to exponential family conditional distributions. We study three particular instances of this model, analyzing their properties and showing their relationship to existing unsupervised learning models. Our experimental evaluation on real-world datasets demonstrates that the proposed techniques outperform well-known baseline methods in two downstream machine learning tasks.
Like this:
Like Loading...