There is no general AI: Why Turing machines cannot pass the Turing test
Since 1950, when Alan Turing proposed what has since come to be called the Turing test, the ability of a machine to pass this test has established itself as the primary hallmark of general AI. To pass the test, a machine would have to be able to engage in dialogue in such a way that a human interrogator could not distinguish its behaviour from that of a human being. AI researchers have attempted to build machines that could meet this requirement, but they have so far failed. To pass the test, a machine would have to meet two conditions: (i) react appropriately to the variance in human dialogue and (ii) display a human-like personality and intentions. We argue, first, that it is for mathematical reasons impossible to program a machine which can master the enormously complex and constantly evolving pattern of variance which human dialogues contain. And second, that we do not know how to make machines that possess personality and intentions of the sort we find in humans. Since a Turing machine cannot master human dialogue behaviour, we conclude that a Turing machine also cannot possess what is called “general” Artificial Intelligence. We do, however, acknowledge the potential of Turing machines to master dialogue behaviour in highly restricted contexts, where what is called “narrow” AI can still be of considerable utility.
Sionnx: Automatic Unit Test Generator for ONNX Conformance
Open Neural Network Exchange (ONNX) is an open format to represent AI models and is supported by many machine learning frameworks. While ONNX defines unified and portable computation operators across various frameworks, the conformance tests for those operators are insufficient, which makes it difficult to verify if an operator’s behavior in an ONNX backend implementation complies with the ONNX standard. In this paper, we present the first automatic unit test generator named Sionnx for verifying the compliance of ONNX implementation. First, we propose a compact yet complete set of rules to describe the operator’s attributes and the properties of its operands. Second, we design an Operator Specification Language (OSL) to provide a high-level description for the operator’s syntax. Finally, through this easy-to-use specification language, we are able to build a full testing specification which leverages LLVM TableGen to automatically generate unit tests for ONNX operators with much large coverage. Sionnx is lightweight and flexible to support cross-framework verification. The Sionnx framework is open-sourced in the github repository (
https://…/Sionnx ).
Boosting Few-Shot Visual Learning with Self-Supervision
Few-shot learning and self-supervised learning address different facets of the same problem: how to train a model with little or no labeled data. Few-shot learning aims for optimization methods and models that can learn efficiently to recognize patterns in the low data regime. Self-supervised learning focuses instead on unlabeled data and looks into it for the supervisory signal to feed high capacity deep neural networks. In this work we exploit the complementarity of these two domains and propose an approach for improving few-shot learning through self-supervision. We use self-supervision as an auxiliary task in a few-shot learning pipeline, enabling feature extractors to learn richer and more transferable visual representations while still using few annotated samples. Through self-supervision, our approach can be naturally extended towards using diverse unlabeled data from other datasets in the few-shot setting. We report consistent improvements across an array of architectures, datasets and self-supervision techniques.
Task Agnostic Continual Learning via Meta Learning
While neural networks are powerful function approximators, they suffer from catastrophic forgetting when the data distribution is not stationary. One particular formalism that studies learning under non-stationary distribution is provided by continual learning, where the non-stationarity is imposed by a sequence of distinct tasks. Most methods in this space assume, however, the knowledge of task boundaries, and focus on alleviating catastrophic forgetting. In this work, we depart from this view and move the focus towards faster remembering — i.e measuring how quickly the network recovers performance rather than measuring the network’s performance without any adaptation. We argue that in many settings this can be more effective and that it opens the door to combining meta-learning and continual learning techniques, leveraging their complementary advantages. We propose a framework specific for the scenario where no information about task boundaries or task identity is given. It relies on a separation of concerns into what task is being solved and how the task should be solved. This framework is implemented by differentiating task specific parameters from task agnostic parameters, where the latter are optimized in a continual meta learning fashion, without access to multiple tasks at the same time. We showcase this framework in a supervised learning scenario and discuss the implication of the proposed formalism.
Warping Resilient Time Series Embeddings
Time series are ubiquitous in real world problems and computing distance between two time series is often required in several learning tasks. Computing similarity between time series by ignoring variations in speed or warping is often encountered and dynamic time warping (DTW) is the state of the art. However DTW is not applicable in algorithms which require kernel or vectors. In this paper, we propose a mechanism named WaRTEm to generate vector embeddings of time series such that distance measures in the embedding space exhibit resilience to warping. Therefore, WaRTEm is more widely applicable than DTW. WaRTEm is based on a twin auto-encoder architecture and a training strategy involving warping operators for generating warping resilient embeddings for time series datasets. We evaluate the performance of WaRTEm and observed more than
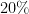
improvement over DTW in multiple real-world datasets.
Explore, Propose, and Assemble: An Interpretable Model for Multi-Hop Reading Comprehension
Multi-hop reading comprehension requires the model to explore and connect relevant information from multiple sentences/documents in order to answer the question about the context. To achieve this, we propose an interpretable 3-module system called Explore-Propose-Assemble reader (EPAr). First, the Document Explorer iteratively selects relevant documents and represents divergent reasoning chains in a tree structure so as to allow assimilating information from all chains. The Answer Proposer then proposes an answer from every root-to-leaf path in the reasoning tree. Finally, the Evidence Assembler extracts a key sentence containing the proposed answer from every path and combines them to predict the final answer. Intuitively, EPAr approximates the coarse-to-fine-grained comprehension behavior of human readers when facing multiple long documents. We jointly optimize our 3 modules by minimizing the sum of losses from each stage conditioned on the previous stage’s output. On two multi-hop reading comprehension datasets WikiHop and MedHop, our EPAr model achieves significant improvements over the baseline and competitive results compared to the state-of-the-art model. We also present multiple reasoning-chain-recovery tests and ablation studies to demonstrate our system’s ability to perform interpretable and accurate reasoning.
Functional Singular Spectrum Analysis
In this paper, we introduce a new extension of the Singular Spectrum Analysis (SSA) called functional SSA to analyze functional time series. The new methodology is developed by integrating ideas from functional data analysis and univariate SSA. We explore the advantages of the functional SSA in terms of simulation results and with an application to a call center data. We compare the proposed approach with Multivariate SSA (MSSA) and Functional Principal Component Analysis (FPCA). The results suggest that further improvement to MSSA is possible and the new method provides an attractive alternative to the novel extensions of the FPCA for correlated functions. We have also developed an efficient and user-friendly R package and a shiny web application to allow interactive exploration of the results.
Better Code, Better Sharing:On the Need of Analyzing Jupyter Notebooks
By bringing together code, text, and examples, Jupyter notebooks have become one of the most popular means to produce scientific results in a productive and reproducible way. As many of the notebook authors are experts in their scientific fields, but laymen with respect to software engineering, one may ask questions on the quality of notebooks and their code. In a preliminary study, we experimentally demonstrate that Jupyter notebooks are inundated with poor quality code, e.g., not respecting recommended coding practices, or containing unused variables and deprecated functions. Considering the education nature of Jupyter notebooks, these poor coding practices as well as the lacks of quality control might be propagated into the next generation of developers. Hence, we argue that there is a strong need to programmatically analyze Jupyter notebooks, calling on our community to pay more attention to the reliability of Jupyter notebooks.
Representation Learning for Words and Entities
This thesis presents new methods for unsupervised learning of distributed representations of words and entities from text and knowledge bases. The first algorithm presented in the thesis is a multi-view algorithm for learning representations of words called Multiview Latent Semantic Analysis (MVLSA). By incorporating up to 46 different types of co-occurrence statistics for the same vocabulary of english words, I show that MVLSA outperforms other state-of-the-art word embedding models. Next, I focus on learning entity representations for search and recommendation and present the second method of this thesis, Neural Variational Set Expansion (NVSE). NVSE is also an unsupervised learning method, but it is based on the Variational Autoencoder framework. Evaluations with human annotators show that NVSE can facilitate better search and recommendation of information gathered from noisy, automatic annotation of unstructured natural language corpora. Finally, I move from unstructured data and focus on structured knowledge graphs. I present novel approaches for learning embeddings of vertices and edges in a knowledge graph that obey logical constraints.
GluonTS: Probabilistic Time Series Models in Python
We introduce Gluon Time Series (GluonTS)\footnote{\url{
https://gluon-ts.mxnet.io}}, a library for deep-learning-based time series modeling. GluonTS simplifies the development of and experimentation with time series models for common tasks such as forecasting or anomaly detection. It provides all necessary components and tools that scientists need for quickly building new models, for efficiently running and analyzing experiments and for evaluating model accuracy.
Learning Curves for Deep Neural Networks: A Gaussian Field Theory Perspective
A series of recent works suggest that deep neural networks (DNNs), of fixed depth, are equivalent to certain Gaussian Processes (NNGP/NTK) in the highly over-parameterized regime (width or number-of-channels going to infinity). Other works suggest that this limit is relevant for real-world DNNs. These results invite further study into the generalization properties of Gaussian Processes of the NNGP and NTK type. Here we make several contributions along this line. First, we develop a formalism, based on field theory tools, for calculating learning curves perturbatively in one over the dataset size. For the case of NNGPs, this formalism naturally extends to finite width corrections. Second, in cases where one can diagonalize the covariance-function of the NNGP/NTK, we provide analytic expressions for the asymptotic learning curves of any given target function. These go beyond the standard equivalence kernel results. Last, we provide closed analytic expressions for the eigenvalues of NNGP/NTK kernels of depth 2 fully-connected ReLU networks. For datasets on the hypersphere, the eigenfunctions of such kernels, at any depth, are hyperspherical harmonics. A simple coherent picture emerges wherein fully-connected DNNs have a strong entropic bias towards functions which are low order polynomials of the input.
COMET: Commonsense Transformers for Automatic Knowledge Graph Construction
We present the first comprehensive study on automatic knowledge base construction for two prevalent commonsense knowledge graphs: ATOMIC (Sap et al., 2019) and ConceptNet (Speer et al., 2017). Contrary to many conventional KBs that store knowledge with canonical templates, commonsense KBs only store loosely structured open-text descriptions of knowledge. We posit that an important step toward automatic commonsense completion is the development of generative models of commonsense knowledge, and propose COMmonsEnse Transformers (COMET) that learn to generate rich and diverse commonsense descriptions in natural language. Despite the challenges of commonsense modeling, our investigation reveals promising results when implicit knowledge from deep pre-trained language models is transferred to generate explicit knowledge in commonsense knowledge graphs. Empirical results demonstrate that COMET is able to generate novel knowledge that humans rate as high quality, with up to 77.5% (ATOMIC) and 91.7% (ConceptNet) precision at top 1, which approaches human performance for these resources. Our findings suggest that using generative commonsense models for automatic commonsense KB completion could soon be a plausible alternative to extractive methods.
Pairwise Fairness for Ranking and Regression
We present pairwise metrics of fairness for ranking and regression models that form analogues of statistical fairness notions such as equal opportunity or equal accuracy, as well as statistical parity. Our pairwise formulation supports both discrete protected groups, and continuous protected attributes. We show that the resulting training problems can be efficiently and effectively solved using constrained optimization and robust optimization techniques based on two player game algorithms developed for fair classification. Experiments illustrate the broad applicability and trade-offs of these methods.
Tensor Canonical Correlation Analysis
In many applications, such as classification of images or videos, it is of interest to develop a framework for tensor data instead of ad-hoc way of transforming data to vectors due to the computational and under-sampling issues. In this paper, we study canonical correlation analysis by extending the framework of two dimensional analysis (Lee and Choi, 2007) to tensor-valued data. Instead of adopting the iterative algorithm provided in Lee and Choi (2007), we propose an efficient algorithm, called the higher-order power method, which is commonly used in tensor decomposition and more efficient for large-scale setting. Moreover, we carefully examine theoretical properties of our algorithm and establish a local convergence property via the theory of Lojasiewicz’s inequalities. Our results fill a missing, but crucial, part in the literature on tensor data. For practical applications, we further develop (a) an inexact updating scheme which allows us to use the state-of-the-art stochastic gradient descent algorithm, (b) an effective initialization scheme which alleviates the problem of local optimum in non-convex optimization, and (c) an extension for extracting several canonical components. Empirical analyses on challenging data including gene expression, air pollution indexes in Taiwan, and electricity demand in Australia, show the effectiveness and efficiency of the proposed methodology.
Dynamic Time Scan Forecasting
The dynamic time scan forecasting method relies on the premise that the most important pattern in a time series precedes the forecasting window, i.e., the last observed values. Thus, a scan procedure is applied to identify similar patterns, or best matches, throughout the time series. As oppose to euclidean distance, or any distance function, a similarity function is dynamically estimated in order to match previous values to the last observed values. Goodness-of-fit statistics are used to find the best matches. Using the respective similarity functions, the observed values proceeding the best matches are used to create a forecasting pattern, as well as forecasting intervals. Remarkably, the proposed method outperformed statistical and machine learning approaches in a real case wind speed forecasting problem.
Linear Distillation Learning
Deep Linear Networks do not have expressive power but they are mathematically tractable. In our work, we found an architecture in which they are expressive. This paper presents a Linear Distillation Learning (LDL) a simple remedy to improve the performance of linear networks through distillation. In deep learning models, distillation often allows the smaller/shallow network to mimic the larger models in a much more accurate way, while a network of the same size trained on the one-hot targets can’t achieve comparable results to the cumbersome model. In our method, we train students to distill teacher separately for each class in dataset. The most striking result to emerge from the data is that neural networks without activation functions can achieve high classification score on a small amount of data on MNIST and Omniglot datasets. Due to tractability, linear networks can be used to explain some phenomena observed experimentally in deep non-linear networks. The suggested approach could become a simple and practical instrument while further studies in the field of linear networks and distillation are yet to be undertaken.
Random Tessellation Forests
Space partitioning methods such as random forests and the Mondrian process are powerful machine learning methods for multi-dimensional and relational data, and are based on recursively cutting a domain. The flexibility of these methods is often limited by the requirement that the cuts be axis aligned. The Ostomachion process and the self-consistent binary space partitioning-tree process were recently introduced as generalizations of the Mondrian process for space partitioning with non-axis aligned cuts in the two dimensional plane. Motivated by the need for a multi-dimensional partitioning tree with non-axis aligned cuts, we propose the Random Tessellation Process (RTP), a framework that includes the Mondrian process and the binary space partitioning-tree process as special cases. We derive a sequential Monte Carlo algorithm for inference, and provide random forest methods. Our process is self-consistent and can relax axis-aligned constraints, allowing complex inter-dimensional dependence to be captured. We present a simulation study, and analyse gene expression data of brain tissue, showing improved accuracies over other methods.
A Brief Introduction to Manifold Optimization
Manifold optimization is ubiquitous in computational and applied mathematics, statistics, engineering, machine learning, physics, chemistry and etc. One of the main challenges usually is the non-convexity of the manifold constraints. By utilizing the geometry of manifold, a large class of constrained optimization problems can be viewed as unconstrained optimization problems on manifold. From this perspective, intrinsic structures, optimality conditions and numerical algorithms for manifold optimization are investigated. Some recent progress on the theoretical results of manifold optimization are also presented.
Factorized Mutual Information Maximization
We investigate the sets of joint probability distributions that maximize the average multi-information over a collection of margins. These functionals serve as proxies for maximizing the multi-information of a set of variables or the mutual information of two subsets of variables, at a lower computation and estimation complexity. We describe the maximizers and their relations to the maximizers of the multi-information and the mutual information.
Reinforcement Learning of Spatio-Temporal Point Processes
Spatio-temporal event data is ubiquitous in various applications, such as social media, crime events, and electronic health records. Spatio-temporal point processes offer a versatile framework for modeling such event data, as it can jointly capture spatial and temporal dependency. A key question is to estimate the generative model for such point processes, which enables the subsequent machine learning tasks. Existing works mainly focus on parametric models for the conditional intensity function, such as the widely used multi-dimensional Hawkes processes. However, parametric models tend to lack flexibility in tackling real data. On the other hand, non-parametric for spatio-temporal point processes tend to be less interpretable. We introduce a novel and flexible semi-parametric spatial-temporal point processes model, by combining spatial statistical models based on heterogeneous Gaussian mixture diffusion kernels, whose parameters are represented using neural networks. We learn the model using a reinforcement learning framework, where the reward function is defined via the maximum mean discrepancy (MMD) of the empirical processes generated by the model and the real data. Experiments based on real data show the superior performance of our method relative to the state-of-the-art.
Like this:
Like Loading...