Adaptive Hierarchical Down-Sampling for Point Cloud Classification
While several convolution-like operators have recently been proposed for extracting features out of point clouds, down-sampling an unordered point cloud in a deep neural network has not been rigorously studied. Existing methods down-sample the points regardless of their importance for the output. As a result, some important points in the point cloud may be removed, while less valuable points may be passed to the next layers. In contrast, adaptive down-sampling methods sample the points by taking into account the importance of each point, which varies based on the application, task and training data. In this paper, we propose a permutation-invariant learning-based adaptive down-sampling layer, called Critical Points Layer (CPL), which reduces the number of points in an unordered point cloud while retaining the important points. Unlike most graph-based point cloud down-sampling methods that use

-NN search algorithm to find the neighbouring points, CPL is a global down-sampling method, rendering it computationally very efficient. The proposed layer can be used along with any graph-based point cloud convolution layer to form a convolutional neural network, dubbed CP-Net in this paper. We introduce a CP-Net for
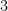
D object classification that achieves the best accuracy for the ModelNet
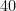
dataset among point cloud-based methods, which validates the effectiveness of the CPL.
Tensor Sparse PCA and Face Recognition: A Novel Approach
Face recognition is the important field in machine learning and pattern recognition research area. It has a lot of applications in military, finance, public security, to name a few. In this paper, the combination of the tensor sparse PCA with the nearest-neighbor method (and with the kernel ridge regression method) will be proposed and applied to the face dataset. Experimental results show that the combination of the tensor sparse PCA with any classification system does not always reach the best accuracy performance measures. However, the accuracy of the combination of the sparse PCA method and one specific classification system is always better than the accuracy of the combination of the PCA method and one specific classification system and is always better than the accuracy of the classification system itself.
MultiNet++: Multi-Stream Feature Aggregation and Geometric Loss Strategy for Multi-Task Learning
Multi-task learning is commonly used in autonomous driving for solving various visual perception tasks. It offers significant benefits in terms of both performance and computational complexity. Current work on multi-task learning networks focus on processing a single input image and there is no known implementation of multi-task learning handling a sequence of images. In this work, we propose a multi-stream multi-task network to take advantage of using feature representations from preceding frames in a video sequence for joint learning of segmentation, depth, and motion. The weights of the current and previous encoder are shared so that features computed in the previous frame can be leveraged without additional computation. In addition, we propose to use the geometric mean of task losses as a better alternative to the weighted average of task losses. The proposed loss function facilitates better handling of the difference in convergence rates of different tasks. Experimental results on KITTI, Cityscapes and SYNTHIA datasets demonstrate that the proposed strategies outperform various existing multi-task learning solutions.
Loss-based risk statistics with set-valued analysis
Since the portfolio has become a hot topic, we wii introduce a special risk statistics from the perspective of loss. This new risk statistic can be uesd for the quantification of portfolio risk. Representation results are provided. Finally, examples are also given to demonstrate the application prospect of this risk statistic.
An Empirical Evaluation of Text Representation Schemes on Multilingual Social Web to Filter the Textual Aggression
This paper attempt to study the effectiveness of text representation schemes on two tasks namely: User Aggression and Fact Detection from the social media contents. In User Aggression detection, The aim is to identify the level of aggression from the contents generated in the Social media and written in the English, Devanagari Hindi and Romanized Hindi. Aggression levels are categorized into three predefined classes namely: `Non-aggressive`, `Overtly Aggressive`, and `Covertly Aggressive`. During the disaster-related incident, Social media like, Twitter is flooded with millions of posts. In such emergency situations, identification of factual posts is important for organizations involved in the relief operation. We anticipated this problem as a combination of classification and Ranking problem. This paper presents a comparison of various text representation scheme based on BoW techniques, distributed word/sentence representation, transfer learning on classifiers. Weighted
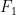
score is used as a primary evaluation metric. Results show that text representation using BoW performs better than word embedding on machine learning classifiers. While pre-trained Word embedding techniques perform better on classifiers based on deep neural net. Recent transfer learning model like ELMO, ULMFiT are fine-tuned for the Aggression classification task. However, results are not at par with pre-trained word embedding model. Overall, word embedding using fastText produce best weighted
-score than Word2Vec and Glove. Results are further improved using pre-trained vector model. Statistical significance tests are employed to ensure the significance of the classification results. In the case of lexically different test Dataset, other than training Dataset, deep neural models are more robust and perform substantially better than machine learning classifiers.
Defensive Quantization: When Efficiency Meets Robustness
Neural network quantization is becoming an industry standard to efficiently deploy deep learning models on hardware platforms, such as CPU, GPU, TPU, and FPGAs. However, we observe that the conventional quantization approaches are vulnerable to adversarial attacks. This paper aims to raise people’s awareness about the security of the quantized models, and we designed a novel quantization methodology to jointly optimize the efficiency and robustness of deep learning models. We first conduct an empirical study to show that vanilla quantization suffers more from adversarial attacks. We observe that the inferior robustness comes from the error amplification effect, where the quantization operation further enlarges the distance caused by amplified noise. Then we propose a novel Defensive Quantization (DQ) method by controlling the Lipschitz constant of the network during quantization, such that the magnitude of the adversarial noise remains non-expansive during inference. Extensive experiments on CIFAR-10 and SVHN datasets demonstrate that our new quantization method can defend neural networks against adversarial examples, and even achieves superior robustness than their full-precision counterparts while maintaining the same hardware efficiency as vanilla quantization approaches. As a by-product, DQ can also improve the accuracy of quantized models without adversarial attack.
Headline Generation: Learning from Decomposed Document Titles
We propose a novel method for generating titles for unstructured text documents. We reframe the problem as a sequential question-answering task. A deep neural network is trained on document-title pairs that have the property of decomposability, in which the vocabulary of the document title is a subset of the vocabulary of the document body. To train the model we use a corpus of millions of publicly available document-title pairs: news articles and headlines. We present the results of a randomized double-blind trial in which subjects were unaware of which titles were human or machine-generated. When trained on approximately 1.5 million news articles, the model generates headlines that humans judge to be as good or better than the original human-written headlines in the majority of cases.
DeepAtlas: Joint Semi-Supervised Learning of Image Registration and Segmentation
Deep convolutional neural networks (CNNs) are state-of-the-art for semantic image segmentation, but typically require many labeled training samples. Obtaining 3D segmentations of medical images for supervised training is difficult and labor intensive. Motivated by classical approaches for joint segmentation and registration we therefore propose a deep learning framework that jointly learns networks for image registration and image segmentation. In contrast to previous work on deep unsupervised image registration, which showed the benefit of weak supervision via image segmentations, our approach can use existing segmentations when available and computes them via the segmentation network otherwise, thereby providing the same registration benefit. Conversely, segmentation network training benefits from the registration, which essentially provides a realistic form of data augmentation. Experiments on knee and brain 3D magnetic resonance (MR) images show that our approach achieves large simultaneous improvements of segmentation and registration accuracy (over independently trained networks) and allows training high-quality models with very limited training data. Specifically, in a one-shot-scenario (with only one manually labeled image) our approach increases Dice scores (%) over an unsupervised registration network by 2.7 and 1.8 on the knee and brain images respectively.
LCC: Learning to Customize and Combine Neural Networks for Few-Shot Learning
Meta-learning has been shown to be an effective strategy for few-shot learning. The key idea is to leverage a large number of similar few-shot tasks in order to meta-learn how to best initiate a (single) base-learner for novel few-shot tasks. While meta-learning how to initialize a base-learner has shown promising results, it is well known that hyperparameter settings such as the learning rate and the weighting of the regularization term are important to achieve best performance. We thus propose to also meta-learn these hyperparameters and in fact learn a time- and layer-varying scheme for learning a base-learner on novel tasks. Additionally, we propose to learn not only a single base-learner but an ensemble of several base-learners to obtain more robust results. While ensembles of learners have shown to improve performance in various settings, this is challenging for few-shot learning tasks due to the limited number of training samples. Therefore, our approach also aims to meta-learn how to effectively combine several base-learners. We conduct extensive experiments and report top performance for five-class few-shot recognition tasks on two challenging benchmarks: miniImageNet and Fewshot-CIFAR100 (FC100).
Semantic Adversarial Attacks: Parametric Transformations That Fool Deep Classifiers
Deep neural networks have been shown to exhibit an intriguing vulnerability to adversarial input images corrupted with imperceptible perturbations. However, the majority of adversarial attacks assume global, fine-grained control over the image pixel space. In this paper, we consider a different setting: what happens if the adversary could only alter specific attributes of the input image? These would generate inputs that might be perceptibly different, but still natural-looking and enough to fool a classifier. We propose a novel approach to generate such `semantic’ adversarial examples by optimizing a particular adversarial loss over the range-space of a parametric conditional generative model. We demonstrate implementations of our attacks on binary classifiers trained on face images, and show that such natural-looking semantic adversarial examples exist. We evaluate the effectiveness of our attack on synthetic and real data, and present detailed comparisons with existing attack methods. We supplement our empirical results with theoretical bounds that demonstrate the existence of such parametric adversarial examples.
Clarifying causal mediation analysis for the applied researcher: Defining effects based on what we want to learn
The incorporation of causal inference in mediation analysis has led to theoretical and methodological advancements — effect definitions with causal interpretation, clarification of assumptions required for effect identification, and an expanding array of options for effect estimation. However, the literature on these results is fast-growing and complex, which may be confusing to researchers unfamiliar with causal inference or unfamiliar with mediation. The goal of this paper is to help ease the understanding and adoption of causal mediation analysis. It starts by highlighting a key difference between the causal inference and traditional approaches to mediation analysis and making a case for the need for explicit causal thinking and the causal inference approach in mediation analysis. It then explains in as-plain-as-possible language existing effect types, paying special attention to motivating these effects with different types of research questions, and using concrete examples for illustration. This presentation differentiates two perspectives (or purposes of analysis): the explanatory perspective (aiming to explain the total effect) and the interventional perspective (asking questions about hypothetical interventions on the exposure and mediator, or hypothetically modified exposures). For the latter perspective, the paper proposes leveraging a general class of interventional effects that contains as special cases most of the usual effect types — interventional direct and indirect effects, controlled direct effects and also a generalized interventional direct effect type, as well as the total effect and overall effect. This general class allows flexible effect definitions which better match many research questions than the standard interventional direct and indirect effects.
ZK-GanDef: A GAN based Zero Knowledge Adversarial Training Defense for Neural Networks
Neural Network classifiers have been used successfully in a wide range of applications. However, their underlying assumption of attack free environment has been defied by adversarial examples. Researchers tried to develop defenses; however, existing approaches are still far from providing effective solutions to this evolving problem. In this paper, we design a generative adversarial net (GAN) based zero knowledge adversarial training defense, dubbed ZK-GanDef, which does not consume adversarial examples during training. Therefore, ZK-GanDef is not only efficient in training but also adaptive to new adversarial examples. This advantage comes at the cost of small degradation in test accuracy compared to full knowledge approaches. Our experiments show that ZK-GanDef enhances test accuracy on adversarial examples by up-to 49.17% compared to zero knowledge approaches. More importantly, its test accuracy is close to that of the state-of-the-art full knowledge approaches (maximum degradation of 8.46%), while taking much less training time.
Towards Open Intent Discovery for Conversational Text
Detecting and identifying user intent from text, both written and spoken, plays an important role in modelling and understand dialogs. Existing research for intent discovery model it as a classification task with a predefined set of known categories. To generailze beyond these preexisting classes, we define a new task of \textit{open intent discovery}. We investigate how intent can be generalized to those not seen during training. To this end, we propose a two-stage approach to this task – predicting whether an utterance contains an intent, and then tagging the intent in the input utterance. Our model consists of a bidirectional LSTM with a CRF on top to capture contextual semantics, subject to some constraints. Self-attention is used to learn long distance dependencies. Further, we adapt an adversarial training approach to improve robustness and perforamce across domains. We also present a dataset of 25k real-life utterances that have been labelled via crowd sourcing. Our experiments across different domains and real-world datasets show the effectiveness of our approach, with less than 100 annotated examples needed per unique domain to recognize diverse intents. The approach outperforms state-of-the-art baselines by 5-15% F1 score points.
Robust Exploration with Tight Bayesian Plausibility Sets
Optimism about the poorly understood states and actions is the main driving force of exploration for many provably-efficient reinforcement learning algorithms. We propose optimism in the face of sensible value functions (OFVF)- a novel data-driven Bayesian algorithm to constructing Plausibility sets for MDPs to explore robustly minimizing the worst case exploration cost. The method computes policies with tighter optimistic estimates for exploration by introducing two new ideas. First, it is based on Bayesian posterior distributions rather than distribution-free bounds. Second, OFVF does not construct plausibility sets as simple confidence intervals. Confidence intervals as plausibility sets are a sufficient but not a necessary condition. OFVF uses the structure of the value function to optimize the location and shape of the plausibility set to guarantee upper bounds directly without necessarily enforcing the requirement for the set to be a confidence interval. OFVF proceeds in an episodic manner, where the duration of the episode is fixed and known. Our algorithm is inherently Bayesian and can leverage prior information. Our theoretical analysis shows the robustness of OFVF, and the empirical results demonstrate its practical promise.
A Decomposition Analysis of Diffusion over a Large Network
Diffusion over a causal network refers to the phenomenon of a change of state of a cross-sectional unit in one period leading to a change of state of its causal neighbors in the next period. One may estimate or test for diffusion by estimating a cross-sectionally aggregated correlation between neighbors over time from data. However, the estimated diffusion can be misleading if the diffusion is confounded by omitted covariates. This paper provides a method of decomposition analysis to measure the role of the covariates on the estimated diffusion, and develops an asymptotic inference procedure for the decomposition analysis in such a situation. This paper also presents results from a Monte Carlo study on the small sample performance of the inference procedure.
Deep Representation Learning for Social Network Analysis
Social network analysis is an important problem in data mining. A fundamental step for analyzing social networks is to encode network data into low-dimensional representations, i.e., network embeddings, so that the network topology structure and other attribute information can be effectively preserved. Network representation leaning facilitates further applications such as classification, link prediction, anomaly detection and clustering. In addition, techniques based on deep neural networks have attracted great interests over the past a few years. In this survey, we conduct a comprehensive review of current literature in network representation learning utilizing neural network models. First, we introduce the basic models for learning node representations in homogeneous networks. Meanwhile, we will also introduce some extensions of the base models in tackling more complex scenarios, such as analyzing attributed networks, heterogeneous networks and dynamic networks. Then, we introduce the techniques for embedding subgraphs. After that, we present the applications of network representation learning. At the end, we discuss some promising research directions for future work.
A New Class of Time Dependent Latent Factor Models with Applications
In many applications, observed data are influenced by some combination of latent causes. For example, suppose sensors are placed inside a building to record responses such as temperature, humidity, power consumption and noise levels. These random, observed responses are typically affected by many unobserved, latent factors (or features) within the building such as the number of individuals, the turning on and off of electrical devices, power surges, etc. These latent factors are usually present for a contiguous period of time before disappearing; further, multiple factors could be present at a time. This paper develops new probabilistic methodology and inference methods for random object generation influenced by latent features exhibiting temporal persistence. Every datum is associated with subsets of a potentially infinite number of hidden, persistent features that account for temporal dynamics in an observation. The ensuing class of dynamic models constructed by adapting the Indian Buffet Process — a probability measure on the space of random, unbounded binary matrices — finds use in a variety of applications arising in operations, signal processing, biomedicine, marketing, image analysis, etc. Illustrations using synthetic and real data are provided.
Semantic variation operators for multidimensional genetic programming
Multidimensional genetic programming represents candidate solutions as sets of programs, and thereby provides an interesting framework for exploiting building block identification. Towards this goal, we investigate the use of machine learning as a way to bias which components of programs are promoted, and propose two semantic operators to choose where useful building blocks are placed during crossover. A forward stagewise crossover operator we propose leads to significant improvements on a set of regression problems, and produces state-of-the-art results in a large benchmark study. We discuss this architecture and others in terms of their propensity for allowing heuristic search to utilize information during the evolutionary process. Finally, we look at the collinearity and complexity of the data representations that result from these architectures, with a view towards disentangling factors of variation in application.
Ridge regularization for Mean Squared Error Reduction in Regression with Weak Instruments
In this paper, I show that classic two-stage least squares (2SLS) estimates are highly unstable with weak instruments. I propose a ridge estimator (ridge IV) and show that it is asymptotically normal even with weak instruments, whereas 2SLS is severely distorted and un-bounded. I motivate the ridge IV estimator as a convex optimization problem with a GMM objective function and an L2 penalty. I show that ridge IV leads to sizable mean squared error reductions theoretically and validate these results in a simulation study inspired by data designs of papers published in the American Economic Review.
Creative Procedural-Knowledge Extraction From Web Design Tutorials
Complex design tasks often require performing diverse actions in a specific order. To (semi-)autonomously accomplish these tasks, applications need to understand and learn a wide range of design procedures, i.e., Creative Procedural-Knowledge (CPK). Prior knowledge base construction and mining have not typically addressed the creative fields, such as design and arts. In this paper, we formalize an ontology of CPK using five components: goal, workflow, action, command and usage; and extract components’ values from online design tutorials. We scraped 19.6K tutorial-related webpages and built a web application for professional designers to identify and summarize CPK components. The annotated dataset consists of 819 unique commands, 47,491 actions, and 2,022 workflows and goals. Based on this dataset, we propose a general CPK extraction pipeline and demonstrate that existing text classification and sequence-to-sequence models are limited in identifying, predicting and summarizing complex operations described in heterogeneous styles. Through quantitative and qualitative error analysis, we discuss CPK extraction challenges that need to be addressed by future research.
One-dimensional Deep Image Prior for Time Series Inverse Problems
We extend the Deep Image Prior (DIP) framework to one-dimensional signals. DIP is using a randomly initialized convolutional neural network (CNN) to solve linear inverse problems by optimizing over weights to fit the observed measurements. Our main finding is that properly tuned one-dimensional convolutional architectures provide an excellent Deep Image Prior for various types of temporal signals including audio, biological signals, and sensor measurements. We show that our network can be used in a variety of recovery tasks including missing value imputation, blind denoising, and compressed sensing from random Gaussian projections. The key challenge is how to avoid overfitting by carefully tuning early stopping, total variation, and weight decay regularization. Our method requires up to 4 times fewer measurements than Lasso and outperforms NLM-VAMP for random Gaussian measurements on audio signals, has similar imputation performance to a Kalman state-space model on a variety of data, and outperforms wavelet filtering in removing additive noise from air-quality sensor readings.
Ontology-based Design of Experiments on Big Data Solutions
Big data solutions are designed to cope with data of huge Volume and wide Variety, that need to be ingested at high Velocity and have potential Veracity issues, challenging characteristics that are usually referred to as the ‘4Vs of Big Data’. In order to evaluate possibly complex big data solutions, stress tests require to assess a large number of combinations of sub-components jointly with the possible big data variations. A formalization of the Design of Experiments (DoE) on big data solutions is aimed at ensuring the reproducibility of the experiments, facilitating their partitioning in sub-experiments and guaranteeing the consistency of their outcomes in a global assessment. In this paper, an ontology-based approach is proposed to support the evaluation of a big data system in two ways. Firstly, the approach formalizes a decomposition and recombination of the big data solution, allowing for the aggregation of component evaluation results at inter-component level. Secondly, existing work on DoE is translated into an ontology for supporting the selection of experiments. The proposed ontology-based approach offers the possibility to combine knowledge from the evaluation domain and the application domain. It exploits domain and inter-domain specific restrictions on the factor combinations in order to reduce the number of experiments. Contrary to existing approaches, the proposed use of ontologies is not limited to the assertional description and exploitation of past experiments but offers richer terminological descriptions for the development of a DoE from scratch. As an application example, a maritime big data solution to the problem of detecting and predicting vessel suspicious behaviour through mobility analysis is selected. The article is concluded with a sketch of future works.
DDLSTM: Dual-Domain LSTM for Cross-Dataset Action Recognition
Domain alignment in convolutional networks aims to learn the degree of layer-specific feature alignment beneficial to the joint learning of source and target datasets. While increasingly popular in convolutional networks, there have been no previous attempts to achieve domain alignment in recurrent networks. Similar to spatial features, both source and target domains are likely to exhibit temporal dependencies that can be jointly learnt and aligned. In this paper we introduce Dual-Domain LSTM (DDLSTM), an architecture that is able to learn temporal dependencies from two domains concurrently. It performs cross-contaminated batch normalisation on both input-to-hidden and hidden-to-hidden weights, and learns the parameters for cross-contamination, for both single-layer and multi-layer LSTM architectures. We evaluate DDLSTM on frame-level action recognition using three datasets, taking a pair at a time, and report an average increase in accuracy of 3.5%. The proposed DDLSTM architecture outperforms standard, fine-tuned, and batch-normalised LSTMs.
ConvLab: Multi-Domain End-to-End Dialog System Platform
We present ConvLab, an open-source multi-domain end-to-end dialog system platform, that enables researchers to quickly set up experiments with reusable components and compare a large set of different approaches, ranging from conventional pipeline systems to end-to-end neural models, in common environments. ConvLab offers a set of fully annotated datasets and associated pre-trained reference models. As a showcase, we extend the MultiWOZ dataset with user dialog act annotations to train all component models and demonstrate how ConvLab makes it easy and effortless to conduct complicated experiments in multi-domain end-to-end dialog settings.
Tex2Shape: Detailed Full Human Body Geometry from a Single Image
We present a simple yet effective method to infer detailed full human body shape from only a single photograph. Our model can infer full-body shape including face, hair, and clothing including wrinkles at interactive frame-rates. Results feature details even on parts that are occluded in the input image. Our main idea is to turn shape regression into an aligned image-to-image translation problem. The input to our method is a partial texture map of the visible region obtained from off-the-shelf methods. From a partial texture, we estimate detailed normal and vector displacement maps, which can be applied to a low-resolution smooth body model to add detail and clothing. Despite being trained purely with synthetic data, our model generalizes well to real-world photographs. Numerous results demonstrate the versatility and robustness of our method.
Fooling automated surveillance cameras: adversarial patches to attack person detection
Adversarial attacks on machine learning models have seen increasing interest in the past years. By making only subtle changes to the input of a convolutional neural network, the output of the network can be swayed to output a completely different result. The first attacks did this by changing pixel values of an input image slightly to fool a classifier to output the wrong class. Other approaches have tried to learn ‘patches’ that can be applied to an object to fool detectors and classifiers. Some of these approaches have also shown that these attacks are feasible in the real-world, i.e. by modifying an object and filming it with a video camera. However, all of these approaches target classes that contain almost no intra-class variety (e.g. stop signs). The known structure of the object is then used to generate an adversarial patch on top of it. In this paper, we present an approach to generate adversarial patches to targets with lots of intra-class variety, namely persons. The goal is to generate a patch that is able successfully hide a person from a person detector. An attack that could for instance be used maliciously to circumvent surveillance systems, intruders can sneak around undetected by holding a small cardboard plate in front of their body aimed towards the surveillance camera. From our results we can see that our system is able significantly lower the accuracy of a person detector. Our approach also functions well in real-life scenarios where the patch is filmed by a camera. To the best of our knowledge we are the first to attempt this kind of attack on targets with a high level of intra-class variety like persons.
Analytical Methods for Interpretable Ultradense Word Embeddings
Word embeddings are useful for a wide variety of tasks, but they lack interpretability. By rotating word spaces, interpretable dimensions can be identified while preserving the information contained in the embeddings without any loss. In this work, we investigate three methods for making word spaces interpretable by rotation: Densifier (Rothe et al., 2016), linear SVMs and DensRay, a new method we propose. While DensRay is very closely related to the Densifier, it can be computed in closed form, is hyperparameter-free and thus more robust than the Densifier. We evaluate the methods on lexicon induction and set-based word analogy and conclude that analytical methods such as DensRay and SVMs are preferable. For word analogy we propose a new method to solve the task which outperforms the previous state of the art by large margins.
Global Hashing System for Fast Image Search
Hashing methods have been widely investigated for fast approximate nearest neighbor searching in large data sets. Most existing methods use binary vectors in lower dimensional spaces to represent data points that are usually real vectors of higher dimensionality. We divide the hashing process into two steps. Data points are first embedded in a low-dimensional space, and the global positioning system method is subsequently introduced but modified for binary embedding. We devise dataindependent and data-dependent methods to distribute the satellites at appropriate locations. Our methods are based on finding the tradeoff between the information losses in these two steps. Experiments show that our data-dependent method outperforms other methods in different-sized data sets from 100k to 10M. By incorporating the orthogonality of the code matrix, both our data-independent and data-dependent methods are particularly impressive in experiments on longer bits.
Out-of-Distribution Detection for Generalized Zero-Shot Action Recognition
Generalized zero-shot action recognition is a challenging problem, where the task is to recognize new action categories that are unavailable during the training stage, in addition to the seen action categories. Existing approaches suffer from the inherent bias of the learned classifier towards the seen action categories. As a consequence, unseen category samples are incorrectly classified as belonging to one of the seen action categories. In this paper, we set out to tackle this issue by arguing for a separate treatment of seen and unseen action categories in generalized zero-shot action recognition. We introduce an out-of-distribution detector that determines whether the video features belong to a seen or unseen action category. To train our out-of-distribution detector, video features for unseen action categories are synthesized using generative adversarial networks trained on seen action category features. To the best of our knowledge, we are the first to propose an out-of-distribution detector based GZSL framework for action recognition in videos. Experiments are performed on three action recognition datasets: Olympic Sports, HMDB51 and UCF101. For generalized zero-shot action recognition, our proposed approach outperforms the baseline (f-CLSWGAN) with absolute gains (in classification accuracy) of 7.0%, 3.4%, and 4.9%, respectively, on these datasets.
Knowledge-rich Image Gist Understanding Beyond Literal Meaning
We investigate the problem of understanding the message (gist) conveyed by images and their captions as found, for instance, on websites or news articles. To this end, we propose a methodology to capture the meaning of image-caption pairs on the basis of large amounts of machine-readable knowledge that has previously been shown to be highly effective for text understanding. Our method identifies the connotation of objects beyond their denotation: where most approaches to image understanding focus on the denotation of objects, i.e., their literal meaning, our work addresses the identification of connotations, i.e., iconic meanings of objects, to understand the message of images. We view image understanding as the task of representing an image-caption pair on the basis of a wide-coverage vocabulary of concepts such as the one provided by Wikipedia, and cast gist detection as a concept-ranking problem with image-caption pairs as queries. To enable a thorough investigation of the problem of gist understanding, we produce a gold standard of over 300 image-caption pairs and over 8,000 gist annotations covering a wide variety of topics at different levels of abstraction. We use this dataset to experimentally benchmark the contribution of signals from heterogeneous sources, namely image and text. The best result with a Mean Average Precision (MAP) of 0.69 indicate that by combining both dimensions we are able to better understand the meaning of our image-caption pairs than when using language or vision information alone. We test the robustness of our gist detection approach when receiving automatically generated input, i.e., using automatically generated image tags or generated captions, and prove the feasibility of an end-to-end automated process.
A Theoretically Sound Upper Bound on the Triplet Loss for Improving the Efficiency of Deep Distance Metric Learning
We propose a method that substantially improves the efficiency of deep distance metric learning based on the optimization of the triplet loss function. One epoch of such training process based on a naive optimization of the triplet loss function has a run-time complexity O(N^3), where N is the number of training samples. Such optimization scales poorly, and the most common approach proposed to address this high complexity issue is based on sub-sampling the set of triplets needed for the training process. Another approach explored in the field relies on an ad-hoc linearization (in terms of N) of the triplet loss that introduces class centroids, which must be optimized using the whole training set for each mini-batch – this means that a naive implementation of this approach has run-time complexity O(N^2). This complexity issue is usually mitigated with poor, but computationally cheap, approximate centroid optimization methods. In this paper, we first propose a solid theory on the linearization of the triplet loss with the use of class centroids, where the main conclusion is that our new linear loss represents a tight upper-bound to the triplet loss. Furthermore, based on the theory above, we propose a training algorithm that no longer requires the centroid optimization step, which means that our approach is the first in the field with a guaranteed linear run-time complexity. We show that the training of deep distance metric learning methods using the proposed upper-bound is substantially faster than triplet-based methods, while producing competitive retrieval accuracy results on benchmark datasets (CUB-200-2011 and CAR196).
Societal Controversies in Wikipedia Articles
Collaborative content creation inevitably reaches situations where different points of view lead to conflict. We focus on Wikipedia, the free encyclopedia anyone may edit, where disputes about content in controversial articles often reflect larger societal debates. While Wikipedia has a public edit history and discussion section for every article, the substance of these sections is difficult to phantom for Wikipedia users interested in the development of an article and in locating which topics were most controversial. In this paper we present Contropedia, a tool that augments Wikipedia articles and gives insight into the development of controversial topics. Contropedia uses an efficient language agnostic measure based on the edit history that focuses on wiki links to easily identify which topics within a Wikipedia article have been most controversial and when.
edGNN: a Simple and Powerful GNN for Directed Labeled Graphs
The ability of a graph neural network (GNN) to leverage both the graph topology and graph labels is fundamental to building discriminative node and graph embeddings. Building on previous work, we theoretically show that edGNN, our model for directed labeled graphs, is as powerful as the Weisfeiler–Lehman algorithm for graph isomorphism. Our experiments support our theoretical findings, confirming that graph neural networks can be used effectively for inference problems on directed graphs with both node and edge labels. Code available at
https://…/edGNN.
A Progressive Visual Analytics Tool for Incremental Experimental Evaluation
This paper presents a visual tool, AVIATOR, that integrates the progressive visual analytics paradigm in the IR evaluation process. This tool serves to speed-up and facilitate the performance assessment of retrieval models enabling a result analysis through visual facilities. AVIATOR goes one step beyond the common ‘compute wait visualize’ analytics paradigm, introducing a continuous evaluation mechanism that minimizes human and computational resource consumption.
Memory and Parallelism Analysis Using a Platform-Independent Approach
Emerging computing architectures such as near-memory computing (NMC) promise improved performance for applications by reducing the data movement between CPU and memory. However, detecting such applications is not a trivial task. In this ongoing work, we extend the state-of-the-art platform-independent software analysis tool with NMC related metrics such as memory entropy, spatial locality, data-level, and basic-block-level parallelism. These metrics help to identify the applications more suitable for NMC architectures.
Why do some probabilistic forecasts lack reliability?
In this work, we investigate the reliability of the probabilistic binary forecast. We mathematically prove that a necessary, but not sufficient, condition for achieving a reliable probabilistic forecast is maximizing the Peirce skill score (PSS) at the threshold probability of the climatological base rate. The condition is confirmed by using artificially synthesized forecast-outcome pair data and previously published probabilistic solar flare forecast models. The condition gives a partial answer as to why some probabilistic forecast system lack reliability, because the system, which does not satisfy the proved condition, can never be reliable. Therefore, the proved condition is very important for the developers of a probabilistic forecast system. The result implies that those who want to develop a reliable probabilistic forecast system must adjust or train the system so as to maximize PSS near the threshold probability of the climatological base rate.
Like this:
Like Loading...