Anomaly Detection for an E-commerce Pricing System
Online retailers execute a very large number of price updates when compared to brick-and-mortar stores. Even a few mis-priced items can have a significant business impact and result in a loss of customer trust. Early detection of anomalies in an automated real-time fashion is an important part of such a pricing system. In this paper, we describe unsupervised and supervised anomaly detection approaches we developed and deployed for a large-scale online pricing system at Walmart. Our system detects anomalies both in batch and real-time streaming settings, and the items flagged are reviewed and actioned based on priority and business impact. We found that having the right architecture design was critical to facilitate model performance at scale, and business impact and speed were important factors influencing model selection, parameter choice, and prioritization in a production environment for a large-scale system. We conducted analyses on the performance of various approaches on a test set using real-world retail data and fully deployed our approach into production. We found that our approach was able to detect the most important anomalies with high precision.
Utility Mining Across Multi-Dimensional Sequences
Knowledge extraction from database is the fundamental task in database and data mining community, which has been applied to a wide range of real-world applications and situations. Different from the support-based mining models, the utility-oriented mining framework integrates the utility theory to provide more informative and useful patterns. Time-dependent sequence data is commonly seen in real life. Sequence data has been widely utilized in many applications, such as analyzing sequential user behavior on the Web, influence maximization, route planning, and targeted marketing. Unfortunately, all the existing algorithms lose sight of the fact that the processed data not only contain rich features (e.g., occur quantity, risk, profit, etc.), but also may be associated with multi-dimensional auxiliary information, e.g., transaction sequence can be associated with purchaser profile information. In this paper, we first formulate the problem of utility mining across multi-dimensional sequences, and propose a novel framework named MDUS to extract Multi-Dimensional Utility-oriented Sequential useful patterns. Two algorithms respectively named MDUS_EM and MDUS_SD are presented to address the formulated problem. The former algorithm is based on database transformation, and the later one performs pattern joins and a searching method to identify desired patterns across multi-dimensional sequences. Extensive experiments are carried on five real-life datasets and one synthetic dataset to show that the proposed algorithms can effectively and efficiently discover the useful knowledge from multi-dimensional sequential databases. Moreover, the MDUS framework can provide better insight, and it is more adaptable to real-life situations than the current existing models.
Interpreting Active Learning Methods Through Information Losses
We propose a new way of interpreting active learning methods by analyzing the information `lost’ upon sampling a random variable. We use some recent analytical developments of these losses to formally prove that facility location methods reduce these losses under mild assumptions, and to derive a new data dependent bound on information losses that can be used to evaluate other active learning methods. We show that this new bound is extremely tight to experiment, and further show that the bound has a decent predictive power for classification accuracy.
Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression
Intersection over Union (IoU) is the most popular evaluation metric used in the object detection benchmarks. However, there is a gap between optimizing the commonly used distance losses for regressing the parameters of a bounding box and maximizing this metric value. The optimal objective for a metric is the metric itself. In the case of axis-aligned 2D bounding boxes, it can be shown that
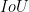
can be directly used as a regression loss. However,
has a plateau making it infeasible to optimize in the case of non-overlapping bounding boxes. In this paper, we address the weaknesses of
by introducing a generalized version as both a new loss and a new metric. By incorporating this generalized
(

) as a loss into the state-of-the art object detection frameworks, we show a consistent improvement on their performance using both the standard,
based, and new,
based, performance measures on popular object detection benchmarks such as PASCAL VOC and MS COCO.
NAS-Bench-101: Towards Reproducible Neural Architecture Search
Recent advances in neural architecture search (NAS) demand tremendous computational resources. This makes it difficult to reproduce experiments and imposes a barrier-to-entry to researchers without access to large-scale computation. We aim to ameliorate these problems by introducing NAS-Bench-101, the first public architecture dataset for NAS research. To build NAS-Bench-101, we carefully constructed a compact, yet expressive, search space, exploiting graph isomorphisms to identify 423k unique convolutional architectures. We trained and evaluated all of these architectures multiple times on CIFAR-10 and compiled the results into a large dataset. All together, NAS-Bench-101 contains the metrics of over 5 million models, the largest dataset of its kind thus far. This allows researchers to evaluate the quality of a diverse range of models in milliseconds by querying the pre-computed dataset. We demonstrate its utility by analyzing the dataset as a whole and by benchmarking a range of architecture optimization algorithms.
Stochastic Prediction of Multi-Agent Interactions from Partial Observations
We present a method that learns to integrate temporal information, from a learned dynamics model, with ambiguous visual information, from a learned vision model, in the context of interacting agents. Our method is based on a graph-structured variational recurrent neural network (Graph-VRNN), which is trained end-to-end to infer the current state of the (partially observed) world, as well as to forecast future states. We show that our method outperforms various baselines on two sports datasets, one based on real basketball trajectories, and one generated by a soccer game engine.
Subjective Databases
Online users are constantly seeking experiences, such as a hotel with clean rooms and a lively bar, or a restaurant for a romantic rendezvous. However, e-commerce search engines only support queries involving objective attributes such as location, price and cuisine, and any experiential data is relegated to text reviews. In order to support experiential queries, a database system needs to model subjective data and also be able to process queries where the user can express varied subjective experiences in words chosen by the user, in addition to specifying predicates involving objective attributes. This paper introduces Opine, a subjective database system that addresses these challenges. We introduce a data model for subjective databases. We describe how Opine translates subjective queries against the subjective database schema, which is done through matching the user query phrases to the underlying schema. We also show how the experiential conditions specified by the user can be combined and the results aggregated and ranked. We demonstrate that subjective databases satisfy user needs more effectively and accurately than alternative techniques through experiments with real data of hotel and restaurant reviews.
Market-Based Model in CR-WSN: A Q-Probabilistic Multi-agent Learning Approach
The ever-increasingly urban populations and their material demands have brought unprecedented burdens to cities. Smart cities leverage emerging technologies like the Internet of Things (IoT), Cognitive Radio Wireless Sensor Network (CR-WSN) to provide better QoE and QoS for all citizens. However, resource scarcity is an important challenge in CR-WSN. Generally, this problem is handled by auction theory or game theory. To make CR-WSN nodes intelligent and more autonomous in resource allocation, we propose a multi-agent reinforcement learning (MARL) algorithm to learn the optimal resource allocation strategy in the oligopoly market model. Firstly, we model a multi-agent scenario, in which the primary users (PUs) is the sellers and the secondary users (SUs) is the buyers. Then, we propose the Q-probabilistic multiagent learning (QPML) and apply it to allocate resources in the market. In the multi-agent interactive learning process, the PUs and SUs learn strategies to maximize their benefits and improve spectrum utilization. Experimental results show the efficiency of our QPML approach, which can also converge quickly.
AntisymmetricRNN: A Dynamical System View on Recurrent Neural Networks
Recurrent neural networks have gained widespread use in modeling sequential data. Learning long-term dependencies using these models remains difficult though, due to exploding or vanishing gradients. In this paper, we draw connections between recurrent networks and ordinary differential equations. A special form of recurrent networks called the AntisymmetricRNN is proposed under this theoretical framework, which is able to capture long-term dependencies thanks to the stability property of its underlying differential equation. Existing approaches to improving RNN trainability often incur significant computation overhead. In comparison, AntisymmetricRNN achieves the same goal by design. We showcase the advantage of this new architecture through extensive simulations and experiments. AntisymmetricRNN exhibits much more predictable dynamics. It outperforms regular LSTM models on tasks requiring long-term memory and matches the performance on tasks where short-term dependencies dominate despite being much simpler.
Optimal Clustering with Missing Values
Missing values frequently arise in modern biomedical studies due to various reasons, including missing tests or complex profiling technologies for different omics measurements. Missing values can complicate the application of clustering algorithms, whose goals are to group points based on some similarity criterion. A common practice for dealing with missing values in the context of clustering is to first impute the missing values, and then apply the clustering algorithm on the completed data. We consider missing values in the context of optimal clustering, which finds an optimal clustering operator with reference to an underlying random labeled point process (RLPP). We show how the missing-value problem fits neatly into the overall framework of optimal clustering by incorporating the missing value mechanism into the random labeled point process and then marginalizing out the missing-value process. In particular, we demonstrate the proposed framework for the Gaussian model with arbitrary covariance structures. Comprehensive experimental studies on both synthetic and real-world RNA-seq data show the superior performance of the proposed optimal clustering with missing values when compared to various clustering approaches. Optimal clustering with missing values obviates the need for imputation-based pre-processing of the data, while at the same time possessing smaller clustering errors.
Algorithms and software for projections onto intersections of convex and non-convex sets with applications to inverse problems
We propose algorithms and software for computing projections onto the intersection of multiple convex and non-convex constraint sets. The software package, called SetIntersectionProjection, is intended for the regularization of inverse problems in physical parameter estimation and image processing. The primary design criterion is working with multiple sets, which allows us to solve inverse problems with multiple pieces of prior knowledge. Our algorithms outperform the well known Dykstra’s algorithm when individual sets are not easy to project onto because we exploit similarities between constraint sets. Other design choices that make the software fast and practical to use, include recently developed automatic selection methods for auxiliary algorithm parameters, fine and coarse grained parallelism, and a multilevel acceleration scheme. We provide implementation details and examples that show how the software can be used to regularize inverse problems. Results show that we benefit from working with all available prior information and are not limited to one or two regularizers because of algorithmic, computational, or hyper-parameter selection issues.
Learning to Find Hard Instances of Graph Problems
Finding hard instances, which need a long time to solve, of graph problems such as the graph coloring problem and the maximum clique problem, is important for (1) building a good benchmark for evaluating the performance of algorithms, and (2) analyzing the algorithms to accelerate them. The existing methods for generating hard instances rely on parameters or rules that are found by domain experts; however, they are specific to the problem. Hence, it is difficult to generate hard instances for general cases. To address this issue, in this paper, we formulate finding hard instances of graph problems as two equivalent optimization problems. Then, we propose a method to automatically find hard instances by solving the optimization problems. The advantage of the proposed algorithm over the existing rule based approach is that it does not require any task specific knowledge. To the best of our knowledge, this is the first non-trivial method in the literature to automatically find hard instances. Through experiments on various problems, we demonstrate that our proposed method can generate instances that are a few to several orders of magnitude harder than the random based approach in many settings. In particular, our method outperforms rule-based algorithms in the 3-coloring problem.
Learning Implicitly Recurrent CNNs Through Parameter Sharing
We introduce a parameter sharing scheme, in which different layers of a convolutional neural network (CNN) are defined by a learned linear combination of parameter tensors from a global bank of templates. Restricting the number of templates yields a flexible hybridization of traditional CNNs and recurrent networks. Compared to traditional CNNs, we demonstrate substantial parameter savings on standard image classification tasks, while maintaining accuracy. Our simple parameter sharing scheme, though defined via soft weights, in practice often yields trained networks with near strict recurrent structure; with negligible side effects, they convert into networks with actual loops. Training these networks thus implicitly involves discovery of suitable recurrent architectures. Though considering only the design aspect of recurrent links, our trained networks achieve accuracy competitive with those built using state-of-the-art neural architecture search (NAS) procedures. Our hybridization of recurrent and convolutional networks may also represent a beneficial architectural bias. Specifically, on synthetic tasks which are algorithmic in nature, our hybrid networks both train faster and extrapolate better to test examples outside the span of the training set.
Detecting Data Errors with Statistical Constraints
A powerful approach to detecting erroneous data is to check which potentially dirty data records are incompatible with a user’s domain knowledge. Previous approaches allow the user to specify domain knowledge in the form of logical constraints (e.g., functional dependency and denial constraints). We extend the constraint-based approach by introducing a novel class of statistical constraints (SCs). An SC treats each column as a random variable, and enforces an independence or dependence relationship between two (or a few) random variables. Statistical constraints are expressive, allowing the user to specify a wide range of domain knowledge, beyond traditional integrity constraints. Furthermore, they work harmoniously with downstream statistical modeling. We develop CODED, an SC-Oriented Data Error Detection system that supports three key tasks: (1) Checking whether an SC is violated or not on a given dataset, (2) Identify the top-k records that contribute the most to the violation of an SC, and (3) Checking whether a set of input SCs have conflicts or not. We present effective solutions for each task. Experiments on synthetic and real-world data illustrate how SCs apply to error detection, and provide evidence that CODED performs better than state-of-the-art approaches.
Structure Tree-LSTM: Structure-aware Attentional Document Encoders
We propose a method to create document representations that reflect their internal structure. We modify Tree-LSTMs to hierarchically merge basic elements like words and sentences into blocks of increasing complexity. Our Structure Tree-LSTM implements a hierarchical attention mechanism over individual components and combinations thereof. We thus emphasize the usefulness of Tree-LSTMs for texts larger than a sentence. We show that structure-aware encoders can be used to improve the performance of document classification. We demonstrate that our method is resilient to changes to the basic building blocks, as it performs well with both sentence and word embeddings. The Structure Tree-LSTM outperforms all the baselines on two datasets when structural clues like sections are available, but also in the presence of mere paragraphs. On a third dataset from the medical domain, our model achieves competitive performance with the state of the art. This result shows the Structure Tree-LSTM can leverage dependency relations other than text structure, such as a set of reports on the same patient.
Learning a Deep ConvNet for Multi-label Classification with Partial Labels
Deep ConvNets have shown great performance for single-label image classification (e.g. ImageNet), but it is necessary to move beyond the single-label classification task because pictures of everyday life are inherently multi-label. Multi-label classification is a more difficult task than single-label classification because both the input images and output label spaces are more complex. Furthermore, collecting clean multi-label annotations is more difficult to scale-up than single-label annotations. To reduce the annotation cost, we propose to train a model with partial labels i.e. only some labels are known per image. We first empirically compare different labeling strategies to show the potential for using partial labels on multi-label datasets. Then to learn with partial labels, we introduce a new classification loss that exploits the proportion of known labels per example. Our approach allows the use of the same training settings as when learning with all the annotations. We further explore several curriculum learning based strategies to predict missing labels. Experiments are performed on three large-scale multi-label datasets: MS COCO, NUS-WIDE and Open Images.
Topological Bayesian Optimization with Persistence Diagrams
Finding an optimal parameter of a black-box function is important for searching stable material structures and finding optimal neural network structures, and Bayesian optimization algorithms are widely used for the purpose. However, most of existing Bayesian optimization algorithms can only handle vector data and cannot handle complex structured data. In this paper, we propose the topological Bayesian optimization, which can efficiently find an optimal solution from structured data using \emph{topological information}. More specifically, in order to apply Bayesian optimization to structured data, we extract useful topological information from a structure and measure the proper similarity between structures. To this end, we utilize persistent homology, which is a topological data analysis method that was recently applied in machine learning. Moreover, we propose the Bayesian optimization algorithm that can handle multiple types of topological information by using a linear combination of kernels for persistence diagrams. Through experiments, we show that topological information extracted by persistent homology contributes to a more efficient search for optimal structures compared to the random search baseline and the graph Bayesian optimization algorithm.
Automated Model Selection with Bayesian Quadrature
We present a novel technique for tailoring Bayesian quadrature (BQ) to model selection. The state-of-the-art for comparing the evidence of multiple models relies on Monte Carlo methods, which converge slowly and are unreliable for computationally expensive models. Previous research has shown that BQ offers sample efficiency superior to Monte Carlo in computing the evidence of an individual model. However, applying BQ directly to model comparison may waste computation producing an overly-accurate estimate for the evidence of a clearly poor model. We propose an automated and efficient algorithm for computing the most-relevant quantity for model selection: the posterior probability of a model. Our technique maximizes the mutual information between this quantity and observations of the models’ likelihoods, yielding efficient acquisition of samples across disparate model spaces when likelihood observations are limited. Our method produces more-accurate model posterior estimates using fewer model likelihood evaluations than standard Bayesian quadrature and Monte Carlo estimators, as we demonstrate on synthetic and real-world examples.
Functional Transparency for Structured Data: a Game-Theoretic Approach
We provide a new approach to training neural models to exhibit transparency in a well-defined, functional manner. Our approach naturally operates over structured data and tailors the predictor, functionally, towards a chosen family of (local) witnesses. The estimation problem is setup as a co-operative game between an unrestricted predictor such as a neural network, and a set of witnesses chosen from the desired transparent family. The goal of the witnesses is to highlight, locally, how well the predictor conforms to the chosen family of functions, while the predictor is trained to minimize the highlighted discrepancy. We emphasize that the predictor remains globally powerful as it is only encouraged to agree locally with locally adapted witnesses. We analyze the effect of the proposed approach, provide example formulations in the context of deep graph and sequence models, and empirically illustrate the idea in chemical property prediction, temporal modeling, and molecule representation learning.
Interaction-aware Factorization Machines for Recommender Systems
Factorization Machine (FM) is a widely used supervised learning approach by effectively modeling of feature interactions. Despite the successful application of FM and its many deep learning variants, treating every feature interaction fairly may degrade the performance. For example, the interactions of a useless feature may introduce noises; the importance of a feature may also differ when interacting with different features. In this work, we propose a novel model named \emph{Interaction-aware Factorization Machine} (IFM) by introducing Interaction-Aware Mechanism (IAM), which comprises the \emph{feature aspect} and the \emph{field aspect}, to learn flexible interactions on two levels. The feature aspect learns feature interaction importance via an attention network while the field aspect learns the feature interaction effect as a parametric similarity of the feature interaction vector and the corresponding field interaction prototype. IFM introduces more structured control and learns feature interaction importance in a stratified manner, which allows for more leverage in tweaking the interactions on both feature-wise and field-wise levels. Besides, we give a more generalized architecture and propose Interaction-aware Neural Network (INN) and DeepIFM to capture higher-order interactions. To further improve both the performance and efficiency of IFM, a sampling scheme is developed to select interactions based on the field aspect importance. The experimental results from two well-known datasets show the superiority of the proposed models over the state-of-the-art methods.
Like this:
Like Loading...