A Multilevel Approach for the Performance Analysis of Parallel Algorithms
We provide a multilevel approach for analysing performances of parallel algorithms. The main outcome of such approach is that the algorithm is described by using a set of operators which are related to each other according to the problem decomposition. Decomposition level determines the granularity of the algorithm. A set of block matrices (decomposition and execution) highlights fundamental characteristics of the algorithm, such as inherent parallelism and sources of overheads.
Exploring Communities in Large Profiled Graphs
Given a graph

and a vertex
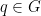
, the community search (CS) problem aims to efficiently find a subgraph of
whose vertices are closely related to

. Communities are prevalent in social and biological networks, and can be used in product advertisement and social event recommendation. In this paper, we study profiled community search (PCS), where CS is performed on a profiled graph. This is a graph in which each vertex has labels arranged in a hierarchical manner. Extensive experiments show that PCS can identify communities with themes that are common to their vertices, and is more effective than existing CS approaches. As a naive solution for PCS is highly expensive, we have also developed a tree index, which facilitate efficient and online solutions for PCS.
Supplementary Notes: Segment Parameter Labelling in MCMC Change Detection
This work addresses the problem of segmentation in time series data with respect to a statistical parameter of interest in Bayesian models. It is common to assume that the parameters are distinct within each segment. As such, many Bayesian change point detection models do not exploit the segment parameter patterns, which can improve performance. This work proposes a Bayesian change point detection algorithm that makes use of repetition in segment parameters, by introducing segment class labels that utilise a Dirichlet process prior.
Multi-Agent Pathfinding (MAPF) with Continuous Time
MAPF is the problem of finding paths for multiple agents such that every agent reaches its goal and the agents do not collide. Most prior work on MAPF were on grid, assumed all actions cost the same, agents do not have a volume, and considered discrete time steps. In this work we propose a MAPF algorithm that do not assume any of these assumptions, is complete, and provides provably optimal solutions. This algorithm is based on a novel combination of SIPP, a continuous time single agent planning algorithms, and CBS, a state of the art multi-agent pathfinding algorithm. We analyze this algorithm, discuss its pros and cons, and evaluate it experimentally on several standard benchmarks.
The information-theoretic value of unlabeled data in semi-supervised learning
We quantify the separation between the numbers of labeled examples required to learn in two settings: Settings with and without the knowledge of the distribution of the unlabeled data. More specifically, we prove a separation by
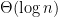
multiplicative factor for the class of projections over the Boolean hypercube of dimension

. We prove that there is no separation for the class of all functions on domain of any size. Learning with the knowledge of the distribution (a.k.a. fixed-distribution learning) can be viewed as an idealized scenario of semi-supervised learning where the number of unlabeled data points is so great that the unlabeled distribution is known exactly. For this reason, we call the separation the value of unlabeled data.
Trends in Demand, Growth, and Breadth in Scientific Computing Training Delivered by a High-Performance Computing Center
We analyze the changes in the training and educational efforts of the SciNet HPC Consortium, a Canadian academic High Performance Computing center, in the areas of Scientific Computing and High-Performance Computing, over the last six years. Initially, SciNet offered isolated training events on how to use HPC systems and write parallel code, but the training program now consists of a broad range of workshops and courses that users can take toward certificates in scientific computing, data science, or high-performance computing. Using data on enrollment, attendence, and certificate numbers from SciNet’s education website, used by almost 1800 users so far, we extract trends on the growth, demand, and breadth of SciNet’s training program. Among the results are a steady overall growth, a sharp and steady increase in the demand for data science training, and a wider participation of ‘non-traditional’ computing disciplines, which has motivated an increasingly broad spectrum of training offerings. Of interest is also that many of the training initiatives have evolved into courses that can be taken as part of the graduate curriculum at the University of Toronto.
Artificial Neural Networks
These are lecture notes for my course on Artificial Neural Networks that I have given at Chalmers (FFR135) and Gothenburg University (FIM720). This course describes the use of neural networks in machine learning: deep learning, recurrent networks, and other supervised and unsupervised machine-learning algorithms.
Ensemble Kalman Methods With Constraints
Ensemble Kalman methods constitute an increasingly important tool in both state and parameter estimation problems. Their popularity stems from the derivative-free nature of the methodology which may be readily applied when computer code is available for the underlying state-space dynamics (for state estimation) or for the parameter-to-observable map (for parameter estimation). There are many applications in which it is desirable to enforce prior information in the form of equality or inequality constraints on the state or parameter. This paper establishes a general framework for doing so, describing a widely applicable methodology, a theory which justifies the methodology, and a set of numerical experiments exemplifying it.
Evolving embodied intelligence from materials to machines
Natural lifeforms specialise to their environmental niches across many levels; from low-level features such as DNA and proteins, through to higher-level artefacts including eyes, limbs, and overarching body plans. We propose Multi-Level Evolution (MLE), a bottom-up automatic process that designs robots across multiple levels and niches them to tasks and environmental conditions. MLE concurrently explores constituent molecular and material ‘building blocks’, as well as their possible assemblies into specialised morphological and sensorimotor configurations. MLE provides a route to fully harness a recent explosion in available candidate materials and ongoing advances in rapid manufacturing processes. We outline a feasible MLE architecture that realises this vision, highlight the main roadblocks and how they may be overcome, and show robotic applications to which MLE is particularly suited. By forming a research agenda to stimulate discussion between researchers in related fields, we hope to inspire the pursuit of multi-level robotic design all the way from material to machine.
Efficient Matrix Profile Computation Using Different Distance Functions
Matrix profile has been recently proposed as a promising technique to the problem of all-pairs-similarity search on time series. Efficient algorithms have been proposed for computing it, e.g., STAMP, STOMP and SCRIMP++. All these algorithms use the z-normalized Euclidean distance to measure the distance between subsequences. However, as we observed, for some datasets other Euclidean measurements are more useful for knowledge discovery from time series. In this paper, we propose efficient algorithms for computing matrix profile for a general class of Euclidean distances. We first propose a simple but efficient algorithm called AAMP for computing matrix profile with the ‘pure’ (non-normalized) Euclidean distance. Then, we extend our algorithm for the p-norm distance. We also propose an algorithm, called ACAMP, that uses the same principle as AAMP, but for the case of z-normalized Euclidean distance. We implemented our algorithms, and evaluated their performance through experimentation. The experiments show excellent performance results. For example, they show that AAMP is very efficient for computing matrix profile for non-normalized Euclidean distances. The results also show that the ACAMP algorithm is significantly faster than SCRIMP++ (the state of the art matrix profile algorithm) for the case of z-normalized Euclidean distance.
AI Coding: Learning to Construct Error Correction Codes
In this paper, we investigate an artificial-intelligence (AI) driven approach to design error correction codes (ECC). Classic error correction code was designed upon coding theory that typically defines code properties (e.g., hamming distance, subchannel reliability, etc.) to reflect code performance. Its code design is to optimize code properties. However, an AI-driven approach doesn’t necessarily rely on coding theory any longer. Specifically, we propose a constructor-evaluator framework, in which the code constructor is realized by AI algorithms and the code evaluator provides code performance metric measurements. The code constructor keeps improving the code construction to maximize code performance that is evaluated by the code evaluator. As examples, we construct linear block codes and polar codes with reinforcement learning (RL) and evolutionary algorithms. The results show that comparable code performance can be achieved with respect to the existing codes. It is noteworthy that our method can provide superior performances where existing classic constructions fail to achieve optimum for a specific decoder (e.g., list decoding for polar codes).
SAFE: Scale Aware Feature Encoder for Scene Text Recognition
In this paper, we address the problem of having characters with different scales in scene text recognition. We propose a novel scale aware feature encoder (SAFE) that is designed specifically for encoding characters with different scales. SAFE is composed of a multi-scale convolutional encoder and a scale attention network. The multi-scale convolutional encoder targets at extracting character features under multiple scales, and the scale attention network is responsible for selecting features from the most relevant scale(s). SAFE has two main advantages over the traditional single-CNN encoder used in current state-of-the-art text recognizers. First, it explicitly tackles the scale problem by extracting scale-invariant features from the characters. This allows the recognizer to put more effort in handling other challenges in scene text recognition, like those caused by view distortion and poor image quality. Second, it can transfer the learning of feature encoding across different character scales. This is particularly important when the training set has a very unbalanced distribution of character scales, as training with such a dataset will make the encoder biased towards extracting features from the predominant scale. To evaluate the effectiveness of SAFE, we design a simple text recognizer named scale-spatial attention network (S-SAN) that employs SAFE as its feature encoder, and carry out experiments on six public benchmarks. Experimental results demonstrate that S-SAN can achieve state-of-the-art (or, in some cases, extremely competitive) performance without any post-processing.
Conditional Optimal Stopping: A Time-Inconsistent Optimization
Inspired by recent work of P.-L. Lions on conditional optimal control, we introduce a problem of optimal stopping under bounded rationality: the objective is the expected payoff at the time of stopping, conditioned on another event. For instance, an agent may care only about states where she is still alive at the time of stopping, or a company may condition on not being bankrupt. We observe that conditional optimization is time-inconsistent due to the dynamic change of the conditioning probability and develop an equilibrium approach in the spirit of R. H. Strotz’ work for sophisticated agents in discrete time. Equilibria are found to be essentially unique in the case of a finite time horizon whereas an infinite horizon gives rise to non-uniqueness and other interesting phenomena. We also introduce a theory which generalizes the classical Snell envelope approach for optimal stopping by considering a pair of processes with Snell-type properties.
AuxNet: Auxiliary tasks enhanced Semantic Segmentation for Automated Driving
Decision making in automated driving is highly specific to the environment and thus semantic segmentation plays a key role in recognizing the objects in the environment around the car. Pixel level classification once considered a challenging task which is now becoming mature to be productized in a car. However, semantic annotation is time consuming and quite expensive. Synthetic datasets with domain adaptation techniques have been used to alleviate the lack of large annotated datasets. In this work, we explore an alternate approach of leveraging the annotations of other tasks to improve semantic segmentation. Recently, multi-task learning became a popular paradigm in automated driving which demonstrates joint learning of multiple tasks improves overall performance of each tasks. Motivated by this, we use auxiliary tasks like depth estimation to improve the performance of semantic segmentation task. We propose adaptive task loss weighting techniques to address scale issues in multi-task loss functions which become more crucial in auxiliary tasks. We experimented on automotive datasets including SYNTHIA and KITTI and obtained 3% and 5% improvement in accuracy respectively.
EAT-NAS: Elastic Architecture Transfer for Accelerating Large-scale Neural Architecture Search
Neural architecture search (NAS) methods have been proposed to release human experts from tedious architecture engineering. However, most current methods are constrained in small-scale search due to the issue of computational resources. Meanwhile, directly applying architectures searched on small datasets to large-scale tasks often bears no performance guarantee. This limitation impedes the wide use of NAS on large-scale tasks. To overcome this obstacle, we propose an elastic architecture transfer mechanism for accelerating large-scale neural architecture search (EAT-NAS). In our implementations, architectures are first searched on a small dataset (the width and depth of architectures are taken into consideration as well), e.g., CIFAR-10, and the best is chosen as the basic architecture. Then the whole architecture is transferred with elasticity. We accelerate the search process on a large-scale dataset, e.g., the whole ImageNet dataset, with the help of the basic architecture. What we propose is not only a NAS method but a mechanism for architecture-level transfer. In our experiments, we obtain two final models EATNet-A and EATNet-B that achieve competitive accuracies, 73.8% and 73.7% on ImageNet, respectively, which also surpass the models searched from scratch on ImageNet under the same settings. For computational cost, EAT-NAS takes only less than 5 days on 8 TITAN X GPUs, which is significantly less than the computational consumption of the state-of-the-art large-scale NAS methods.
A Learning Framework for An Accurate Prediction of Rainfall Rates
The present work is aimed to examine the potential of advanced machine learning strategies to predict the monthly rainfall (precipitation) for the Indus Basin, using climatological variables such as air temperature, geo-potential height, relative humidity and elevation. In this work, the focus is on thirteen geographical locations, called index points, within the basin. Arguably, not all of the hydrological components are relevant to the precipitation rate, and therefore, need to be filtered out, leading to a lower-dimensional feature space. Towards this goal, we adopted the gradient boosting method to extract the most contributive features for precipitation rate prediction. Five state-of-the-art machine learning methods have then been trained where pearson correlation coefficient and mean absolute error have been reported as the prediction performance criteria. The Random Forest regression model outperformed the other regression models achieving the maximum pearson correlation coefficient and minimum mean absolute error for most of the index points. Our results suggest the relative humidity (for pressure levels of 300 mb and 150 mb, respectively), the u-direction wind (for pressure level of 700 mb), air temperature (for pressure levels of 150 mb and 10 mb, respectively) as the top five influencing features for accurate forecasting the precipitation rate.
Applying SVGD to Bayesian Neural Networks for Cyclical Time-Series Prediction and Inference
A regression-based BNN model is proposed to predict spatiotemporal quantities like hourly rider demand with calibrated uncertainties. The main contributions of this paper are (i) A feed-forward deterministic neural network (DetNN) architecture that predicts cyclical time series data with sensitivity to anomalous forecasting events; (ii) A Bayesian framework applying SVGD to train large neural networks for such tasks, capable of producing time series predictions as well as measures of uncertainty surrounding the predictions. Experiments show that the proposed BNN reduces average estimation error by 10% across 8 U.S. cities compared to a fine-tuned multilayer perceptron (MLP), and 4% better than the same network architecture trained without SVGD.
Diverse mini-batch Active Learning
We study the problem of reducing the amount of labeled training data required to train supervised classification models. We approach it by leveraging Active Learning, through sequential selection of examples which benefit the model most. Selecting examples one by one is not practical for the amount of training examples required by the modern Deep Learning models. We consider the mini-batch Active Learning setting, where several examples are selected at once. We present an approach which takes into account both informativeness of the examples for the model, as well as the diversity of the examples in a mini-batch. By using the well studied K-means clustering algorithm, this approach scales better than the previously proposed approaches, and achieves comparable or better performance.
Like this:
Like Loading...