Anomaly Detection for Network Connection Logs
We leverage a streaming architecture based on ELK, Spark and Hadoop in order to collect, store, and analyse database connection logs in near real-time. The proposed system investigates outliers using unsupervised learning; widely adopted clustering and classification algorithms for log data, highlighting the subtle variances in each model by visualisation of outliers. Arriving at a novel solution to evaluate untagged, unfiltered connection logs, we propose an approach that can be extrapolated to a generalised system of analysing connection logs across a large infrastructure comprising thousands of individual nodes and generating hundreds of lines in logs per second.
Hybrid Microaggregation for Privacy-Preserving Data Mining
k-Anonymity by microaggregation is one of the most commonly used anonymization techniques. This success is owe to the achievement of a worth of interest tradeoff between information loss and identity disclosure risk. However, this method may have some drawbacks. On the disclosure limitation side, there is a lack of protection against attribute disclosure. On the data utility side, dealing with a real datasets is a challenging task to achieve. Indeed, the latter are characterized by their large number of attributes and the presence of noisy data, such that outliers or, even, data with missing values. Generating an anonymous individual data useful for data mining tasks, while decreasing the influence of noisy data is a compelling task to achieve. In this paper, we introduce a new microaggregation method, called HM-PFSOM, based on fuzzy possibilistic clustering. Our proposed method operates through an hybrid manner. This means that the anonymization process is applied per block of similar data. Thus, we can help to decrease the information loss during the anonymization process. The HMPFSOM approach proposes to study the distribution of confidential attributes within each sub-dataset. Then, according to the latter distribution, the privacy parameter k is determined, in such a way to preserve the diversity of confidential attributes within the anonymized microdata. This allows to decrease the disclosure risk of confidential information.
Overcoming Catastrophic Forgetting by Soft Parameter Pruning
Catastrophic forgetting is a challenge issue in continual learning when a deep neural network forgets the knowledge acquired from the former task after learning on subsequent tasks. However, existing methods try to find the joint distribution of parameters shared with all tasks. This idea can be questionable because this joint distribution may not present when the number of tasks increase. On the other hand, It also leads to ‘long-term’ memory issue when the network capacity is limited since adding tasks will ‘eat’ the network capacity. In this paper, we proposed a Soft Parameters Pruning (SPP) strategy to reach the trade-off between short-term and long-term profit of a learning model by freeing those parameters less contributing to remember former task domain knowledge to learn future tasks, and preserving memories about previous tasks via those parameters effectively encoding knowledge about tasks at the same time. The SPP also measures the importance of parameters by information entropy in a label free manner. The experiments on several tasks shows SPP model achieved the best performance compared with others state-of-the-art methods. Experiment results also indicate that our method is less sensitive to hyper-parameter and better generalization. Our research suggests that a softer strategy, i.e. approximate optimize or sub-optimal solution, will benefit alleviating the dilemma of memory. The source codes are available at
https://…/Learning_by_memory.
Auto-tuning TensorFlow Threading Model for CPU Backend
TensorFlow is a popular deep learning framework used by data scientists to solve a wide-range of machine learning and deep learning problems such as image classification and speech recognition. It also operates at a large scale and in heterogeneous environments — it allows users to train neural network models or deploy them for inference using GPUs, CPUs and deep learning specific custom-designed hardware such as TPUs. Even though TensorFlow supports a variety of optimized backends, realizing the best performance using a backend may require additional efforts. For instance, getting the best performance from a CPU backend requires careful tuning of its threading model. Unfortunately, the best tuning approach used today is manual, tedious, time-consuming, and, more importantly, may not guarantee the best performance. In this paper, we develop an automatic approach, called TensorTuner, to search for optimal parameter settings of TensorFlow’s threading model for CPU backends. We evaluate TensorTuner on both Eigen and Intel’s MKL CPU backends using a set of neural networks from TensorFlow’s benchmarking suite. Our evaluation results demonstrate that the parameter settings found by TensorTuner produce 2% to 123% performance improvement for the Eigen CPU backend and 1.5% to 28% performance improvement for the MKL CPU backend over the performance obtained using their best-known parameter settings. This highlights the fact that the default parameter settings in Eigen CPU backend are not the ideal settings; and even for a carefully hand-tuned MKL backend, the settings may be sub-optimal. Our evaluations also revealed that TensorTuner is efficient at finding the optimal settings — it is able to converge to the optimal settings quickly by pruning more than 90% of the parameter search space.
Graphical Models for Extremes
Conditional independence, graphical models and sparsity are key notions for parsimonious statistical models and for understanding the structural relationships in the data. The theory of multivariate and spatial extremes describes the risk of rare events through asymptotically justified limit models such as max-stable and multivariate Pareto distributions. Statistical modeling in this field has been limited to moderate dimensions so far, partly owing to complicated likelihoods and a lack of understanding of the underlying probabilistic structures. We introduce a general theory of conditional independence for multivariate Pareto distributions that allows to define graphical models and sparsity for extremes. A Hammersley-Clifford theorem links this new notion to the factorization of densities of extreme value models on graphs. For the popular class of H\’usler-Reiss distributions we show that, similarly to the Gaussian case, the sparsity pattern of a general extremal graphical model can be read off from suitable inverse covariance matrices. New parametric models can be built in a modular way and statistical inference can be simplified to lower-dimensional margins. We discuss learning of minimum spanning trees and model selection for extremal graph structures, and illustrate their use with an application to flood risk assessment on the Danube river.
RobustSTL: A Robust Seasonal-Trend Decomposition Algorithm for Long Time Series
Decomposing complex time series into trend, seasonality, and remainder components is an important task to facilitate time series anomaly detection and forecasting. Although numerous methods have been proposed, there are still many time series characteristics exhibiting in real-world data which are not addressed properly, including 1) ability to handle seasonality fluctuation and shift, and abrupt change in trend and reminder; 2) robustness on data with anomalies; 3) applicability on time series with long seasonality period. In the paper, we propose a novel and generic time series decomposition algorithm to address these challenges. Specifically, we extract the trend component robustly by solving a regression problem using the least absolute deviations loss with sparse regularization. Based on the extracted trend, we apply the the non-local seasonal filtering to extract the seasonality component. This process is repeated until accurate decomposition is obtained. Experiments on different synthetic and real-world time series datasets demonstrate that our method outperforms existing solutions.
InferLine: ML Inference Pipeline Composition Framework
The dominant cost in production machine learning workloads is not training individual models but serving predictions from increasingly complex prediction pipelines spanning multiple models, machine learning frameworks, and parallel hardware accelerators. Due to the complex interaction between model configurations and parallel hardware, prediction pipelines are challenging to provision and costly to execute when serving interactive latency-sensitive applications. This challenge is exacerbated by the unpredictable dynamics of bursty workloads. In this paper we introduce InferLine, a system which efficiently provisions and executes ML inference pipelines subject to end-to-end latency constraints by proactively optimizing and reactively controlling per-model configuration in a fine-grained fashion. Unpredictable changes in the serving workload are dynamically and cost-optimally accommodated with minimal service level degradation. InferLine introduces (1) automated model profiling and pipeline lineage extraction, (2) a fine-grain, cost-minimizing pipeline configuration planner, and (3) a fine-grain reactive controller. InferLine is able to configure and deploy prediction pipelines across a wide range of workload patterns and latency goals. It outperforms coarse-grained configuration alternatives by up 7.6x in cost while achieving up to 32x lower SLO miss rate on real workloads and generalizes across state-of-the-art model serving frameworks.
Mapping RDF Graphs to Property Graphs
Increasing amounts of scientific and social data are published in the Resource Description Framework (RDF). Although the RDF data can be queried using the SPARQL language, even the SPARQL-based operation has a limitation in implementing traversal or analytical algorithms. Recently, a variety of graph database implementations dedicated to analyses on the property graph model have emerged. However, the RDF model and the property graph model are not interoperable. Here, we developed a framework based on the Graph to Graph Mapping Language (G2GML) for mapping RDF graphs to property graphs to make the most of accumulated RDF data. Using this framework, graph data described in the RDF model can be converted to the property graph model and can be loaded to several graph database engines for further analysis. Future works include implementing and utilizing graph algorithms to make the most of the accumulated data in various analytical engines.
Feature Matters: A Stage-by-Stage Approach for Knowledge Transfer
Convolutional Neural Networks (CNNs) become deeper and deeper in recent years, making the study of model acceleration imperative. It is a common practice to employ a shallow network, called student, to learn from a deep one, which is termed as teacher. Prior work made many attempts to transfer different types of knowledge from teacher to student, however, there are two problems remaining unsolved. Firstly, the knowledge used by existing methods is usually manually defined, which may not be consistent with the information learned by the original model. Secondly, there lacks an effective training scheme for the transfer process, leading to degradation of performance. In this work, we argue that feature is the most important knowledge from teacher. It is sufficient for student to achieve appealing performance by just learning similar features as teacher without any processing. Based on this discovery, we further present an efficient learning strategy, which is to make student mimic features of teacher stage by stage. Extensive experiments suggest that the proposed approach significantly narrows down the gap between student and teacher, and shows strong stability on various tasks, ie classification and detection, outperforming the state-of-the-art methods.
Attention Boosted Sequential Inference Model
Attention mechanism has been proven effective on natural language processing. This paper proposes an attention boosted natural language inference model named aESIM by adding word attention and adaptive direction-oriented attention mechanisms to the traditional Bi-LSTM layer of natural language inference models, e.g. ESIM. This makes the inference model aESIM has the ability to effectively learn the representation of words and model the local subsentential inference between pairs of premise and hypothesis. The empirical studies on the SNLI, MultiNLI and Quora benchmarks manifest that aESIM is superior to the original ESIM model.
spGARCH: An R-Package for Spatial and Spatiotemporal ARCH models
In this paper, a general overview on spatial and spatiotemporal ARCH models is provided. In particular, we distinguish between three different spatial ARCH-type models. In addition to the original definition of Otto et al. (2016), we introduce an exponential spatial ARCH model in this paper. For this new model, maximum-likelihood estimators for the parameters are proposed. In addition, we consider a new complex-valued definition of the spatial ARCH process. From a practical point of view, the use of the R-package spGARCH is demonstrated. To be precise, we show how the proposed spatial ARCH models can be simulated and summarize the variety of spatial models, which can be estimated by the estimation functions provided in the package. Eventually, we apply all procedures to a real-data example.
MedSim: A Novel Semantic Similarity Measure in Bio-medical Knowledge Graphs
We present MedSim, a novel semantic SIMilarity method based on public well-established bio-MEDical knowledge graphs (KGs) and large-scale corpus, to study the therapeutic substitution of antibiotics. Besides hierarchy and corpus of KGs, MedSim further interprets medicine characteristics by constructing multi-dimensional medicine-specific feature vectors. Dataset of 528 antibiotic pairs scored by doctors is applied for evaluation and MedSim has produced statistically significant improvement over other semantic similarity methods. Furthermore, some promising applications of MedSim in drug substitution and drug abuse prevention are presented in case study.
A Knowledge Graph Based Solution for Entity Discovery and Linking in Open-Domain Questions
Named entity discovery and linking is the fundamental and core component of question answering. In Question Entity Discovery and Linking (QEDL) problem, traditional methods are challenged because multiple entities in one short question are difficult to be discovered entirely and the incomplete information in short text makes entity linking hard to implement. To overcome these difficulties, we proposed a knowledge graph based solution for QEDL and developed a system consists of Question Entity Discovery (QED) module and Entity Linking (EL) module. The method of QED module is a tradeoff and ensemble of two methods. One is the method based on knowledge graph retrieval, which could extract more entities in questions and guarantee the recall rate, the other is the method based on Conditional Random Field (CRF), which improves the precision rate. The EL module is treated as a ranking problem and Learning to Rank (LTR) method with features such as semantic similarity, text similarity and entity popularity is utilized to extract and make full use of the information in short texts. On the official dataset of a shared QEDL evaluation task, our approach could obtain 64.44% F1 score of QED and 64.86% accuracy of EL, which ranks the 2nd place and indicates its practical use for QEDL problem.
Constructing Ontology-Based Cancer Treatment Decision Support System with Case-Based Reasoning
Decision support is a probabilistic and quantitative method designed for modeling problems in situations with ambiguity. Computer technology can be employed to provide clinical decision support and treatment recommendations. The problem of natural language applications is that they lack formality and the interpretation is not consistent. Conversely, ontologies can capture the intended meaning and specify modeling primitives. Disease Ontology (DO) that pertains to cancer’s clinical stages and their corresponding information components is utilized to improve the reasoning ability of a decision support system (DSS). The proposed DSS uses Case-Based Reasoning (CBR) to consider disease manifestations and provides physicians with treatment solutions from similar previous cases for reference. The proposed DSS supports natural language processing (NLP) queries. The DSS obtained 84.63% accuracy in disease classification with the help of the ontology.
Correlation Clustering in Data Streams
Clustering is a fundamental tool for analyzing large data sets. A rich body of work has been devoted to designing data-stream algorithms for the relevant optimization problems such as

-center,
-median, and
-means. Such algorithms need to be both time and and space efficient. In this paper, we address the problem of correlation clustering in the dynamic data stream model. The stream consists of updates to the edge weights of a graph on

nodes and the goal is to find a node-partition such that the end-points of negative-weight edges are typically in different clusters whereas the end-points of positive-weight edges are typically in the same cluster. We present polynomial-time,
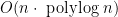
-space approximation algorithms for natural problems that arise. We first develop data structures based on linear sketches that allow the ‘quality’ of a given node-partition to be measured. We then combine these data structures with convex programming and sampling techniques to solve the relevant approximation problem. Unfortunately, the standard LP and SDP formulations are not obviously solvable in

-space. Our work presents space-efficient algorithms for the convex programming required, as well as approaches to reduce the adaptivity of the sampling.
Inflection-Tolerant Ontology-Based Named Entity Recognition for Real-Time Applications
A growing number of applications users daily interact with have to operate in (near) real-time: chatbots, digital companions, knowledge work support systems — just to name a few. To perform the services desired by the user, these systems have to analyze user activity logs or explicit user input extremely fast. In particular, text content (e.g. in form of text snippets) needs to be processed in an information extraction task. Regarding the aforementioned temporal requirements, this has to be accomplished in just a few milliseconds, which limits the number of methods that can be applied. Practically, only very fast methods remain, which on the other hand deliver worse results than slower but more sophisticated Natural Language Processing (NLP) pipelines. In this paper, we investigate and propose methods for real-time capable Named Entity Recognition (NER). As a first improvement step we address are word variations induced by inflection, for example present in the German language. Our approach is ontology-based and makes use of several language information sources like Wiktionary. We evaluated it using the German Wikipedia (about 9.4B characters), for which the whole NER process took considerably less than an hour. Since precision and recall are higher than with comparably fast methods, we conclude that the quality gap between high speed methods and sophisticated NLP pipelines can be narrowed a bit more without losing too much runtime performance.
Like this:
Like Loading...