Looking Deeper into Deep Learning Model: Attribution-based Explanations of TextCNN
Layer-wise Relevance Propagation (LRP) and saliency maps have been recently used to explain the predictions of Deep Learning models, specifically in the domain of text classification. Given different attribution-based explanations to highlight relevant words for a predicted class label, experiments based on word deleting perturbation is a common evaluation method. This word removal approach, however, disregards any linguistic dependencies that may exist between words or phrases in a sentence, which could semantically guide a classifier to a particular prediction. In this paper, we present a feature-based evaluation framework for comparing the two attribution methods on customer reviews (public data sets) and Customer Due Diligence (CDD) extracted reports (corporate data set). Instead of removing words based on the relevance score, we investigate perturbations based on embedded features removal from intermediate layers of Convolutional Neural Networks. Our experimental study is carried out on embedded-word, embedded-document, and embedded-ngrams explanations. Using the proposed framework, we provide a visualization tool to assist analysts in reasoning toward the model’s final prediction.
Stovepiping and Malicious Software: A Critical Review of AGI Containment
Awareness of the possible impacts associated with artificial intelligence has risen in proportion to progress in the field. While there are tremendous benefits to society, many argue that there are just as many, if not more, concerns related to advanced forms of artificial intelligence. Accordingly, research into methods to develop artificial intelligence safely is increasingly important. In this paper, we provide an overview of one such safety paradigm: containment with a critical lens aimed toward generative adversarial networks and potentially malicious artificial intelligence. Additionally, we illuminate the potential for a developmental blindspot in the stovepiping of containment mechanisms.
How Do Fairness Definitions Fare? Examining Public Attitudes Towards Algorithmic Definitions of Fairness
What is the best way to define algorithmic fairness? There has been much recent debate on algorithmic fairness. While many definitions of fairness have been proposed in the computer science literature, there is no clear agreement over a particular definition. In this work, we investigate ordinary people’s perceptions of three of these fairness definitions. Across two online experiments, we test which definitions people perceive to be the fairest in the context of loan decisions, and whether those fairness perceptions change with the addition of sensitive information (i.e., race of the loan applicants). We find a clear preference for one definition, and the general results seem to align with the principle of affirmative action.
A Primal Decomposition Method with Suboptimality Bounds for Distributed Mixed-Integer Linear Programming
In this paper we deal with a network of agents seeking to solve in a distributed way Mixed-Integer Linear Programs (MILPs) with a coupling constraint (modeling a limited shared resource) and local constraints. MILPs are NP-hard problems and several challenges arise in a distributed framework, so that looking for suboptimal solutions is of interest. To achieve this goal, the presence of a linear coupling calls for tailored decomposition approaches. We propose a fully distributed algorithm based on a primal decomposition approach and a suitable tightening of the coupling constraints. Agents repeatedly update local allocation vectors, which converge to an optimal resource allocation of an approximate version of the original problem. Based on such allocation vectors, agents are able to (locally) compute a mixed-integer solution, which is guaranteed to be feasible after a sufficiently large time. Asymptotic and finite-time suboptimality bounds are established for the computed solution. Numerical simulations highlight the efficacy of the proposed methodology.
On the Statistical and Information-theoretic Characteristics of Deep Network Representations
It has been common to argue or imply that a regularizer can be used to alter a statistical property of a hidden layer’s representation and thus improve generalization or performance of deep networks. For instance, dropout has been known to improve performance by reducing co-adaptation, and representational sparsity has been argued as a good characteristic because many data-generation processes have a small number of factors that are independent. In this work, we analytically and empirically investigate the popular characteristics of learned representations, including correlation, sparsity, dead unit, rank, and mutual information, and disprove many of the \textit{conventional wisdom}. We first show that infinitely many Identical Output Networks (IONs) can be constructed for any deep network with a linear layer, where any invertible affine transformation can be applied to alter the layer’s representation characteristics. The existence of ION proves that the correlation characteristics of representation is irrelevant to the performance. Extensions to ReLU layers are provided, too. Then, we consider sparsity, dead unit, and rank to show that only loose relationships exist among the three characteristics. It is shown that a higher sparsity or additional dead units do not imply a better or worse performance when the rank of representation is fixed. We also develop a rank regularizer and show that neither representation sparsity nor lower rank is helpful for improving performance even when the data-generation process has a small number of independent factors. Mutual information

and

are investigated, and we show that regularizers can affect
and thus indirectly influence the performance. Finally, we explain how a rich set of regularizers can be used as a powerful tool for performance tuning.
Practical Bayesian Learning of Neural Networks via Adaptive Subgradient Methods
We introduce a novel framework for the estimation of the posterior distribution of the weights of a neural network, based on a new probabilistic interpretation of adaptive subgradient algorithms such as AdaGrad and Adam. Having a confidence measure of the weights allows several shortcomings of neural networks to be addressed. In particular, the robustness of the network can be improved by performing weight pruning based on signal-to-noise ratios from the weight posterior distribution. Using the MNIST dataset, we demonstrate that the empirical performance of Badam, a particular instance of our framework based on Adam, is competitive in comparison to related Bayesian approaches such as Bayes By Backprop.
Benchmarking Deep Sequential Models on Volatility Predictions for Financial Time Series
Volatility is a quantity of measurement for the price movements of stocks or options which indicates the uncertainty within financial markets. As an indicator of the level of risk or the degree of variation, volatility is important to analyse the financial market, and it is taken into consideration in various decision-making processes in financial activities. On the other hand, recent advancement in deep learning techniques has shown strong capabilities in modelling sequential data, such as speech and natural language. In this paper, we empirically study the applicability of the latest deep structures with respect to the volatility modelling problem, through which we aim to provide an empirical guidance for the theoretical analysis of the marriage between deep learning techniques and financial applications in the future. We examine both the traditional approaches and the deep sequential models on the task of volatility prediction, including the most recent variants of convolutional and recurrent networks, such as the dilated architecture. Accordingly, experiments with real-world stock price datasets are performed on a set of 1314 daily stock series for 2018 days of transaction. The evaluation and comparison are based on the negative log likelihood (NLL) of real-world stock price time series. The result shows that the dilated neural models, including dilated CNN and Dilated RNN, produce most accurate estimation and prediction, outperforming various widely-used deterministic models in the GARCH family and several recently proposed stochastic models. In addition, the high flexibility and rich expressive power are validated in this study.
Fast determinantal point processes via distortion-free intermediate sampling
Given a fixed
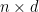
matrix

, where

, we study the complexity of sampling from a distribution over all subsets of rows where the probability of a subset is proportional to the squared volume of the parallelopiped spanned by the rows (a.k.a. a determinantal point process). In this task, it is important to minimize the preprocessing cost of the procedure (performed once) as well as the sampling cost (performed repeatedly). To that end, we propose a new determinantal point process algorithm which has the following two properties, both of which are novel: (1) a preprocessing step which runs in time

, and (2) a sampling step which runs in
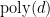
time, independent of the number of rows

. We achieve this by introducing a new regularized determinantal point process (R-DPP), which serves as an intermediate distribution in the sampling procedure by reducing the number of rows from
to
. Crucially, this intermediate distribution does not distort the probabilities of the target sample. Our key novelty in defining the R-DPP is the use of a Poisson random variable for controlling the probabilities of different subset sizes, leading to new determinantal formulas such as the normalization constant for this distribution. Our algorithm has applications in many diverse areas where determinantal point processes have been used, such as machine learning, stochastic optimization, data summarization and low-rank matrix reconstruction.
Estimation of Structural Break Point in Linear Regression Models
This paper proposes a point estimator of the break location for a one-time structural break in linear regression models. If the break magnitude is small, the least-squares estimator of the break date has two modes at ends of the finite sample period, regardless of the true break location. I suggest a modification of the least-squares objective function to solve this problem. The modified objective function incorporates estimation uncertainty that varies across potential break dates. The new break point estimator is consistent and has a unimodal finite sample distribution under a small break magnitude. A limit distribution is provided under a in-fill asymptotic framework which verifies that the new estimator outperforms the least-squares estimator.
Incorporating Relevant Knowledge in Context Modeling and Response Generation
To sustain engaging conversation, it is critical for chatbots to make good use of relevant knowledge. Equipped with a knowledge base, chatbots are able to extract conversation-related attributes and entities to facilitate context modeling and response generation. In this work, we distinguish the uses of attribute and entity and incorporate them into the encoder-decoder architecture in different manners. Based on the augmented architecture, our chatbot, namely Mike, is able to generate responses by referring to proper entities from the collected knowledge. To validate the proposed approach, we build a movie conversation corpus on which the proposed approach significantly outperforms other four knowledge-grounded models.
Ball: An R package for detecting distribution difference and association in metric spaces
The rapid development of modern technology facilitates the appearance of numerous unprecedented complex data which do not satisfy the axioms of Euclidean geometry, while most of the statistical hypothesis tests are available in Euclidean or Hilbert spaces. To properly analyze the data of more complicated structures, efforts have been made to solve the fundamental test problems in more general spaces. In this paper, a publicly available R package Ball is provided to implement Ball statistical test procedures for K-sample distribution comparison and test of mutual independence in metric spaces, which extend the test procedures for two sample distribution comparison and test of independence. The tailormade algorithms as well as engineering techniques are employed on the Ball package to speed up computation to the best of our ability. Two real data analyses and several numerical studies have been performed and the results certify the powerfulness of Ball package in analyzing complex data, e.g., spherical data and symmetric positive matrix data.
DeepSaucer: Unified Environment for Verifying Deep Neural Networks
In recent years, a number of methods for verifying DNNs have been developed. Because the approaches of the methods differ and have their own limitations, we think that a number of verification methods should be applied to a developed DNN. To apply a number of methods to the DNN, it is necessary to translate either the implementation of the DNN or the verification method so that one runs in the same environment as the other. Since those translations are time-consuming, a utility tool, named DeepSaucer, which helps to retain and reuse implementations of DNNs, verification methods, and their environments, is proposed. In DeepSaucer, code snippets of loading DNNs, running verification methods, and creating their environments are retained and reused as software assets in order to reduce cost of verifying DNNs. The feasibility of DeepSaucer is confirmed by implementing it on the basis of Anaconda, which provides virtual environment for loading a DNN and running a verification method. In addition, the effectiveness of DeepSaucer is demonstrated by usecase examples.
EA-LSTM: Evolutionary Attention-based LSTM for Time Series Prediction
Time series prediction with deep learning methods, especially long short-term memory neural networks (LSTMs), have scored significant achievements in recent years. Despite the fact that the LSTMs can help to capture long-term dependencies, its ability to pay different degree of attention on sub-window feature within multiple time-steps is insufficient. To address this issue, an evolutionary attention-based LSTM training with competitive random search is proposed for multivariate time series prediction. By transferring shared parameters, an evolutionary attention learning approach is introduced to the LSTMs model. Thus, like that for biological evolution, the pattern for importance-based attention sampling can be confirmed during temporal relationship mining. To refrain from being trapped into partial optimization like traditional gradient-based methods, an evolutionary computation inspired competitive random search method is proposed, which can well configure the parameters in the attention layer. Experimental results have illustrated that the proposed model can achieve competetive prediction performance compared with other baseline methods.
Encoding Implicit Relation Requirements for Relation Extraction: A Joint Inference Approach
Relation extraction is the task of identifying predefined relationship between entities, and plays an essential role in information extraction, knowledge base construction, question answering and so on. Most existing relation extractors make predictions for each entity pair locally and individually, while ignoring implicit global clues available across different entity pairs and in the knowledge base, which often leads to conflicts among local predictions from different entity pairs. This paper proposes a joint inference framework that employs such global clues to resolve disagreements among local predictions. We exploit two kinds of clues to generate constraints which can capture the implicit type and cardinality requirements of a relation. Those constraints can be examined in either hard style or soft style, both of which can be effectively explored in an integer linear program formulation. Experimental results on both English and Chinese datasets show that our proposed framework can effectively utilize those two categories of global clues and resolve the disagreements among local predictions, thus improve various relation extractors when such clues are applicable to the datasets. Our experiments also indicate that the clues learnt automatically from existing knowledge bases perform comparably to or better than those refined by human.
Skeptical Deep Learning with Distribution Correction
Recently deep neural networks have been successfully used for various classification tasks, especially for problems with massive perfectly labeled training data. However, it is often costly to have large-scale credible labels in real-world applications. One solution is to make supervised learning robust with imperfectly labeled input. In this paper, we develop a distribution correction approach that allows deep neural networks to avoid overfitting imperfect training data. Specifically, we treat the noisy input as samples from an incorrect distribution, which will be automatically corrected during our training process. We test our approach on several classification datasets with elaborately generated noisy labels. The results show significantly higher prediction and recovery accuracy with our approach compared to alternative methods.
A Very Brief and Critical Discussion on AutoML
This contribution presents a very brief and critical discussion on automated machine learning (AutoML), which is categorized here into two classes, referred to as narrow AutoML and generalized AutoML, respectively. The conclusions yielded from this discussion can be summarized as follows: (1) most existent research on AutoML belongs to the class of narrow AutoML; (2) advances in narrow AutoML are mainly motivated by commercial needs, while any possible benefit obtained is definitely at a cost of increase in computing burdens; (3)the concept of generalized AutoML has a strong tie in spirit with artificial general intelligence (AGI), also called ‘strong AI’, for which obstacles abound for obtaining pivotal progresses.
Long Short-Term Memory with Dynamic Skip Connections
In recent years, long short-term memory (LSTM) has been successfully used to model sequential data of variable length. However, LSTM can still experience difficulty in capturing long-term dependencies. In this work, we tried to alleviate this problem by introducing a dynamic skip connection, which can learn to directly connect two dependent words. Since there is no dependency information in the training data, we propose a novel reinforcement learning-based method to model the dependency relationship and connect dependent words. The proposed model computes the recurrent transition functions based on the skip connections, which provides a dynamic skipping advantage over RNNs that always tackle entire sentences sequentially. Our experimental results on three natural language processing tasks demonstrate that the proposed method can achieve better performance than existing methods. In the number prediction experiment, the proposed model outperformed LSTM with respect to accuracy by nearly 20%.
Deep Ensemble Bayesian Active Learning : Addressing the Mode Collapse issue in Monte Carlo dropout via Ensembles
In image classification tasks, the ability of deep CNNs to deal with complex image data has proven to be unrivalled. However, they require large amounts of labeled training data to reach their full potential. In specialised domains such as healthcare, labeled data can be difficult and expensive to obtain. Active Learning aims to alleviate this problem, by reducing the amount of labelled data needed for a specific task while delivering satisfactory performance. We propose DEBAL, a new active learning strategy designed for deep neural networks. This method improves upon the current state-of-the-art deep Bayesian active learning method, which suffers from the mode collapse problem. We correct for this deficiency by making use of the expressive power and statistical properties of model ensembles. Our proposed method manages to capture superior data uncertainty, which translates into improved classification performance. We demonstrate empirically that our ensemble method yields faster convergence of CNNs trained on the MNIST and CIFAR-10 datasets.
Stratified Constructive Disjunction and Negation in Constraint Programming
Constraint Programming (CP) is a powerful declarative programming paradigm combining inference and search in order to find solutions to various type of constraint systems. Dealing with highly disjunctive constraint systems is notoriously difficult in CP. Apart from trying to solve each disjunct independently from each other, there is little hope and effort to succeed in constructing intermediate results combining the knowledge originating from several disjuncts. In this paper, we propose If Then Else (ITE), a lightweight approach for implementing stratified constructive disjunction and negation on top of an existing CP solver, namely SICStus Prolog clp(FD). Although constructive disjunction is known for more than three decades, it does not have straightforward implementations in most CP solvers. ITE is a freely available library proposing stratified and constructive reasoning for various operators, including disjunction and negation, implication and conditional. Our preliminary experimental results show that ITE is competitive with existing approaches that handle disjunctive constraint systems.
Evidence Transfer for Improving Clustering Tasks Using External Categorical Evidence
In this paper we introduce evidence transfer for clustering, a deep learning method that can incrementally manipulate the latent representations of an autoencoder, according to external categorical evidence, in order to improve a clustering outcome. It is deployed on a baseline solution to reduce the cross entropy between the external evidence and an extension of the latent space. By evidence transfer we define the process by which the categorical outcome of an external, auxiliary task is exploited to improve a primary task, in this case representation learning for clustering. Our proposed method makes no assumptions regarding the categorical evidence presented, nor the structure of the latent space. We compare our method, against the baseline solution by performing k-means clustering before and after its deployment. Experiments with three different kinds of evidence show that our method effectively manipulates the latent representations when introduced with real corresponding evidence, while remaining robust when presented with low quality evidence.
A Hierarchical Framework for Relation Extraction with Reinforcement Learning
Most existing methods determine relation types only after all the entities have been recognized, thus the interaction between relation types and entity mentions is not fully modeled. This paper presents a novel paradigm to deal with relation extraction by regarding the related entities as the arguments of a relation. We apply a hierarchical reinforcement learning (HRL) framework in this paradigm to enhance the interaction between entity mentions and relation types. The whole extraction process is decomposed into a hierarchy of two-level RL policies for relation detection and entity extraction respectively, so that it is more feasible and natural to deal with overlapping relations. Our model was evaluated on public datasets collected via distant supervision, and results show that it gains better performance than existing methods and is more powerful for extracting overlapping relations.
Sequential Subspace Changepoint Detection
We consider the sequential changepoint detection problem of detecting changes that are characterized by a subspace structure which is manifested in the covariance matrix. In particular, the covariance structure changes from an identity matrix to an unknown spiked covariance model. We consider three sequential changepoint detection procedures: The exact cumulative sum (CUSUM) that assumes knowledge of all parameters, the largest eigenvalue procedure and a novel Subspace-CUSUM algorithm with the last two being used for the case when unknown parameters are present. By leveraging the extreme eigenvalue distribution from random matrix theory and modeling the non-negligible temporal correlation in the sequence of detection statistics due to the sliding window approach, we provide theoretical approximations to the average run length (ARL) and the expected detection delay (EDD) for the largest eigenvalue procedure. The three methods are compared to each other using simulations.
A Convergence Theory for Deep Learning via Over-Parameterization
Deep neural networks (DNNs) have demonstrated dominating performance in many fields, e.g., computer vision, natural language progressing, and robotics. Since AlexNet, the neural networks used in practice are going wider and deeper. On the theoretical side, a long line of works have been focusing on why we can train neural networks when there is only one hidden layer. The theory of multi-layer neural networks remains somewhat unsettled. We present a new theory to understand the convergence of training DNNs. We only make two assumptions: the inputs do not degenerate and the network is over-parameterized. The latter means the number of hidden neurons is sufficiently large: polynomial in
, the number of training samples and in

, the number of layers. We show on the training dataset, starting from randomly initialized weights, simple algorithms such as stochastic gradient descent attain 100% accuracy in classification tasks, or minimize
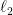
regression loss in linear convergence rate, with a number of iterations that only scale polynomial in
and
. Our theory applies to the widely-used but non-smooth ReLU activation, and to any smooth and possibly non-convex loss functions. In terms of network architectures, our theory at least applies to fully-connected neural networks, convolutional neural networks (CNN), and residual neural networks (ResNet).
Deep Compression of Sum-Product Networks on Tensor Networks
Sum-product networks (SPNs) represent an emerging class of neural networks with clear probabilistic semantics and superior inference speed over graphical models. This work reveals a strikingly intimate connection between SPNs and tensor networks, thus leading to a highly efficient representation that we call tensor SPNs (tSPNs). For the first time, through mapping an SPN onto a tSPN and employing novel optimization techniques, we demonstrate remarkable parameter compression with negligible loss in accuracy.
A generic framework for privacy preserving deep learning
We detail a new framework for privacy preserving deep learning and discuss its assets. The framework puts a premium on ownership and secure processing of data and introduces a valuable representation based on chains of commands and tensors. This abstraction allows one to implement complex privacy preserving constructs such as Federated Learning, Secure Multiparty Computation, and Differential Privacy while still exposing a familiar deep learning API to the end-user. We report early results on the Boston Housing and Pima Indian Diabetes datasets. While the privacy features apart from Differential Privacy do not impact the prediction accuracy, the current implementation of the framework introduces a significant overhead in performance, which will be addressed at a later stage of the development. We believe this work is an important milestone introducing the first reliable, general framework for privacy preserving deep learning.
An Overview of Computational Approaches for Analyzing Interpretation
It is said that beauty is in the eye of the beholder. But how exactly can we characterize such discrepancies in interpretation? For example, are there any specific features of an image that makes person A regard an image as beautiful while person B finds the same image displeasing? Such questions ultimately aim at explaining our individual ways of interpretation, an intention that has been of fundamental importance to the social sciences from the beginning. More recently, advances in computer science brought up two related questions: First, can computational tools be adopted for analyzing ways of interpretation? Second, what if the ‘beholder’ is a computer model, i.e., how can we explain a computer model’s point of view? Numerous efforts have been made regarding both of these points, while many existing approaches focus on particular aspects and are still rather separate. With this paper, in order to connect these approaches we introduce a theoretical framework for analyzing interpretation, which is applicable to interpretation of both human beings and computer models. We give an overview of relevant computational approaches from various fields, and discuss the most common and promising application areas. The focus of this paper lies on interpretation of text and image data, while many of the presented approaches are applicable to other types of data as well.
Understanding and Predicting Links in Graphs: A Persistent Homology Perspective
Persistent Homology is a powerful tool in Topological Data Analysis (TDA) to capture topological properties of data succinctly at different spatial resolutions. For graphical data, shape, and structure of the neighborhood of individual data items (nodes) is an essential means of characterizing their properties. In this paper, we propose the use of persistent homology methods to capture structural and topological properties of graphs and use it to address the problem of link prediction. We evaluate our approach on seven different real-world datasets and offer directions for future work.
Automated Multi-Label Classification based on ML-Plan
Automated machine learning (AutoML) has received increasing attention in the recent past. While the main tools for AutoML, such as Auto-WEKA, TPOT, and auto-sklearn, mainly deal with single-label classification and regression, there is very little work on other types of machine learning tasks. In particular, there is almost no work on automating the engineering of machine learning applications for multi-label classification. This paper makes two contributions. First, it discusses the usefulness and feasibility of an AutoML approach for multi-label classification. Second, we show how the scope of ML-Plan, an AutoML-tool for multi-class classification, can be extended towards multi-label classification using MEKA, which is a multi-label extension of the well-known Java library WEKA. The resulting approach recursively refines MEKA’s multi-label classifiers, which sometimes nest another multi-label classifier, up to the selection of a single-label base learner provided by WEKA. In our evaluation, we find that the proposed approach yields superb results and performs significantly better than a set of baselines.
• An estimation of the greedy algorithm’s accuracy for a set cover problem instance
• New Tribonacci Recurrence Relations and Addition Formulas
• Attitude and Angular Velocity Tracking for a Rigid Body using Geometric Methods on the Two-Sphere (Stability Proof)
• Broadcasting on Random Directed Acyclic Graphs
• On contraction analysis for hybrid systems
• Satyam: Democratizing Groundtruth for Machine Vision
• Collaboratively Learning the Best Option on Graphs, Using Bounded Local Memory
• The Evolution of Gene Dominance through the Baldwin Effect
• Federated Byzantine Quorum Systems (Extended Version)
• Voronoi Partition-based Scenario Reduction for Fast Sampling-based Stochastic Reachability Computation of LTI Systems
• Spiral Fermi Surfaces in Quasicrystals and Twisted Bilayer Graphene: Signatures in Quantum Oscillations
• Plug-In Stochastic Gradient Method
• SpeedReader: Reader Mode Made Fast and Private
• Gender Effect on Face Recognition for a Large Longitudinal Database
• Comparison of partition functions in a space-time random environment
• New CleverHans Feature: Better Adversarial Robustness Evaluations with Attack Bundling
• Variational Bayesian hierarchical regression for data analysis
• Can Deep Learning Outperform Modern Commercial CT Image Reconstruction Methods?
• NEMGAN: Noise Engineered Mode-matching GAN
• Deep Learning Predicts Hip Fracture using Confounding Patient and Healthcare Variables
• A Comparison of Lattice-free Discriminative Training Criteria for Purely Sequence-Trained Neural Network Acoustic Models
• Maximizing Diversity of Opinion in Social Networks
• Validating Hyperspectral Image Segmentation
• Learning Energy Based Inpainting for Optical Flow
• Symmetries of the Quaternionic Ginibre Ensemble
• Detecting Backdoor Attacks on Deep Neural Networks by Activation Clustering
• New bounds on the maximum size of Sperner partition systems
• Universal Hard-label Black-Box Perturbations: Breaking Security-Through-Obscurity Defenses
• Close and ordinary social contacts: how important are they in promoting large-scale contagion?
• A Note on the comparison of Nearest Neighbor Gaussian Process (NNGP) based models
• Semantic and Contrast-Aware Saliency
• Securing Behavior-based Opinion Spam Detection
• Analysis of Fleet Modularity in an Artificial Intelligence-Based Attacker-Defender Game
• Density estimation for shift-invariant multidimensional distributions
• A Fundamental Measure of Treatment Effect Heterogeneity
• Inducibility of directed paths
• Adaptive Task Allocation for Mobile Edge Learning
• Imagining an Engineer: On GAN-Based Data Augmentation Perpetuating Biases
• Neural sequence labeling for Vietnamese POS Tagging and NER
• A new insight into the secondary path modeling problem in active noise control
• RSA: Byzantine-Robust Stochastic Aggregation Methods for Distributed Learning from Heterogeneous Datasets
• Typeface Completion with Generative Adversarial Networks
• Towards Instance-Optimal Private Query Release
• Energy-Efficient Offloading in Mobile Edge Computing with Edge-Cloud Collaboration
• M2M-GAN: Many-to-Many Generative Adversarial Transfer Learning for Person Re-Identification
• A Fully Automated System for Sizing Nasal PAP Masks Using Facial Photographs
• Artificial neural networks for density-functional optimizations in fermionic systems
• Nonlinear Modal Decoupling Based Power System Transient Stability Analysis
• Codeword Position Index based Sparse Code Multiple Access System
• Addition-deletion theorem for free hyperplane arrangements and combinatorics
• A Theoretically Guaranteed Deep Optimization Framework for Robust Compressive Sensing MRI
• Can We Use Speaker Recognition Technology to Attack Itself? Enhancing Mimicry Attacks Using Automatic Target Speaker Selection
• Feature Analysis for Classification of Physical Actions using surface EMG Data
• On complexity of cyclic coverings of graphs
• On rationality of generating function for the number of spanning trees in circulant graphs
• Gradient Descent Finds Global Minima of Deep Neural Networks
• A Sufficient Condition for Small-Signal Stability and Construction of Robust Stability Region
• Homomorphism bounds of signed bipartite $K_4$-minor-free graphs and edge-colorings of $2k$-regular $K_4$-minor-free multigraphs
• Football and Beer – a Social Media Analysis on Twitter in Context of the FIFA Football World Cup 2018
• The trouble with tensor ring decompositions
• Neural Stain Normalization and Unsupervised Classification of Cell Nuclei in Histopathological Breast Cancer Images
• Invariant projections for operators that are free over the diagonal
• RoarNet: A Robust 3D Object Detection based on RegiOn Approximation Refinement
• Increased dose rate precision in combined $α$ and $β$ counting in the $μ$Dose system – a probabilistic approach to data analysis
• The Price of Governance: A Middle Ground Solution to Coordination in Organizational Control
• How does stock market volatility react to oil shocks?
• On the Inducibility of Stackelberg Equilibrium for Security Games
• Changing the Image Memorability: From Basic Photo Editing to GANs
• Image-Level Attentional Context Modeling Using Nested-Graph Neural Networks
• Deterministic and stochastic inexact regularization algorithms for nonconvex ptimization with optimal complexity
• Information Theoretic Bounds Based Channel Quantization Design for Emerging Memories
• Minimizing and Computing the Inverse Geodesic Length on Trees
• Multilevel Schwarz preconditioners for singularly perturbed symmetric reaction-diffusion systems
• Unique End of Potential Line
• Computation Load Balancing Real-Time Model Predictive Control in Urban Traffic Networks
• An Average of the Human Ear Canal: Recovering Acoustical Properties via Shape Analysis
• MD-GAN: Multi-Discriminator Generative Adversarial Networks for Distributed Datasets
• Precision of the ENDGame: Mixed-precision arithmetic in the iterative solver of the Unified Model
• Sample-Efficient Policy Learning based on Completely Behavior Cloning
• The invariance principle and the large deviation for the biased random walk on $\mathbb{Z}^d$
• An external validation of Thais’ cardiovascular 10-year risk assessment in the southern Thailand
• Targeting Solutions in Bayesian Multi-Objective Optimization: Sequential and Parallel Versions
• Non-convex Lasso-kind approach to compressed sensing for finite-valued signals
• Multimodal Grounding for Sequence-to-Sequence Speech Recognition
• Learning Semantic Representations for Novel Words: Leveraging Both Form and Context
• Suggesting Cooking Recipes Through Simulation and Bayesian Optimization
• Quasi-Perfect Stackelberg Equilibrium
• A first sketch: Construction of model defect priors inspired by dynamic time warping
• Multimodal One-Shot Learning of Speech and Images
• Cross and Learn: Cross-Modal Self-Supervision
• Parallel processing area extraction and data transfer number reduction for automatic GPU offloading of IoT applications
• Exploiting Capacity of Sewer System Using Unsupervised Learning Algorithms Combined with Dimensionality Reduction
• On arithmetic index in the generalized Thue-Morse word
• Graded Betti numbers of balanced simplicial complexes
• Breaking Landauer’s Limit\\Using Quantum-dot Cellular Automata
• Performance Guarantees for Homomorphisms Beyond Markov Decision Processes
• On Conditional Correlations
• Toward Autonomous Rotation-Aware Unmanned Aerial Grasping
• Central limit theorems for patterns in multiset permutations and set partitions
• Post-randomization Biomarker Effect Modification in an HIV Vaccine Clinical Trial
• Vector Gaussian CEO Problem Under Logarithmic Loss and Applications
• Resolving a Feedback Bottleneck of Multi-Antenna Coded Caching
• Modeling Rape Reporting Delays Using Spatial, Temporal and Social Features
• Matrix Recovery with Implicitly Low-Rank Data
• A Complexity Dichotomy for Critical Values of the b-Chromatic Number of Graphs
• Robust Asynchronous Stochastic Gradient-Push: Asymptotically Optimal and Network-Independent Performance for Strongly Convex Functions
• On a relation between packing and covering densities of convex bodies
• Strongly unimodal systems
• Role of initial conditions in the dynamics of quantum glassy systems
• Insights into Bootstrap Percolation: Its Equivalence with k-core Percolation and the Giant Component
• Uncertainty relations and sparse signal recovery
• Identify, locate and separate: Audio-visual object extraction in large video collections using weak supervision
• Reachability-based safe learning for optimal control problem
• The layer complexity of Arthur-Merlin-like communication
• An output-sensitive polynomial Time Algorithm to partition a Sequence of Integers into Subsets with equal Sums
• Convolutional neural networks in phase space and inverse problems
• Adversarial Uncertainty Quantification in Physics-Informed Neural Networks
• The control set of a linear control system on the two dimensional solvable Lie group
• Representation-Oblivious Error Correction by Natural Redundancy
• The discrete cosine transform on triangles
• Counting the Number of Quasiplatonic Topological Actions of the Cyclic Group on Surfaces
• Splenomegaly Segmentation on Multi-modal MRI using Deep Convolutional Networks
• A Microprocessor implemented in 65nm CMOS with Configurable and Bit-scalable Accelerator for Programmable In-memory Computing
• Polynomial-time Approximation Scheme for Minimum k-cut in Planar and Minor-free Graphs
• Cusp Universality for Random Matrices II: The Real Symmetric Case
• Bernstein-von Mises theorems and uncertainty quantification for linear inverse problems
• Pure $\mathcal{O}$-sequences arising from $2$-dimensional PS ear-decomposable simplicial complexes
• A note on simultaneous representation problem for interval and circular-arc graphs
• On convexity and solution concepts in cooperative interval games
• Block Belief Propagation for Parameter Learning in Markov Random Fields
• Two Party Distribution Testing: Communication and Security
• Benefits of Coded Placement for Networks with Heterogeneous Cache Sizes
Like this:
Like Loading...