Model Selection using Multi-Objective Optimization
Choices in scientific research and management require balancing multiple, often competing objectives. Multiple-objective optimization (MOO) provides a unifying framework for solving multiple objective problems. Model selection is a critical component to scientific inference and prediction and concerns balancing the competing objectives of model fit and model complexity. The tradeoff between model fit and model complexity provides a basis for describing the model-selection problem within the MOO framework. We discuss MOO and two strategies for solving the MOO problem; modeling preferences pre-optimization and post-optimization. Most model selection methods are consistent with solving MOO problems via specification of preferences pre-optimization. We reconcile these methods within the MOO framework. We also consider model selection using post-optimization specification of preferences. That is, by first identifying Pareto optimal solutions, and then selecting among them. We demonstrate concepts with an ecological application of model selection using avian species richness data in the continental United States.
Law and Adversarial Machine Learning
When machine learning systems fail because of adversarial manipulation, what kind of legal relief can society expect? Through scenarios grounded in adversarial ML literature, we explore how some aspects of computer crime, copyright, and tort law interface with perturbation, poisoning and model stealing, model inversion attacks to show how some attacks are more likely to result in liability than others. We end with a call for action to ML researchers to invest in transparent benchmarks of attacks and defenses; architect ML systems with forensics in mind and finally, think more about adversarial machine learning in the context of civil liberties. The paper is targeted towards ML researchers who have no legal background.
Batch-Parallel Euler Tour Trees
The dynamic trees problem is to maintain a forest undergoing edge insertions and deletions while supporting queries for information such as connectivity. There are many existing data structures for this problem, but few of them are capable of exploiting parallelism in the batch-setting, in which large batches of edges are inserted or deleted from the forest at once. In this paper, we demonstrate that the Euler tour tree, an existing sequential dynamic trees data structure, can be parallelized in the batch setting. For a batch of

updates over a forest of

vertices, our parallel Euler tour trees perform

expected work with
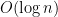
depth with high probability. Our work bound is asymptotically optimal, and we improve on the depth bound achieved by Acar et al. for the batch-parallel dynamic trees problem. The main building block for parallelizing Euler tour trees is a batch-parallel skip list data structure, which we believe may be of independent interest. Euler tour trees require a sequence data structure capable of joins and splits. Sequentially, balanced binary trees are used, but they are difficult to join or split in parallel. We show that skip lists, on the other hand, support batches of joins or splits of size
over
elements with
work in expectation and
depth with high probability. We also achieve the same efficiency bounds for augmented skip lists, which allows us to augment our Euler tour trees to support subtree queries. Our data structures achieve between 67–96x self-relative speedup on 72 cores with hyper-threading on large batch sizes. Our data structures also outperform the fastest existing sequential dynamic trees data structures empirically.
Fault Diagnosis and Bad Data Detection of Power Transmission Network – A Time Domain Approach
Fault analysis and bad data are often processed in separate manners. In this paper it is proved that fault as well as bad current measurement data can be modeled as control failure for the power transmission network and any fault on the transmission line can be treated as multiple bad data. Subsequently a linear observer theory is designed in order to identify the fault type and bad data simultaneously. The state space model based observer theory allows a particular failure mode manifest itself as residual which remains in a fixed direction. Moreover coordinate transformation is performed to allow the residual for each failure mode to generate specific geometry characteristic in separate output dimensions. The design approach based on the observer theory is presented in this paper. The design allows 1) bad data detection for current measurement, and 2) fault location, and fault resistance estimation (as a byproduct) where the fault location accuracy is not affected by fault resistance. However it loses freedom in designing the eigenvalues in the excessive subspace. While the theoretical framework is general, the analysis and design are dedicated to transmission lines.
Expedition: A Time-Aware Exploratory Search System Designed for Scholars
Archives are an important source of study for various scholars. Digitization and the web have made archives more accessible and led to the development of several time-aware exploratory search systems. However these systems have been designed for more general users rather than scholars. Scholars have more complex information needs in comparison to general users. They also require support for corpus creation during their exploration process. In this paper we present Expedition – a time-aware exploratory search system that addresses the requirements and information needs of scholars. Expedition possesses a suite of ad-hoc and diversity based retrieval models to address complex information needs; a newspaper-style user interface to allow for larger textual previews and comparisons; entity filters to more naturally refine a result list and an interactive annotated timeline which can be used to better identify periods of importance.
Between a ROC and a Hard Place: Using prevalence plots to understand the likely real world performance of biomarkers in the clinic
The Receiver Operating Characteristic (ROC) curve and the Area Under the Curve (AUC) of the ROC curve are widely used to compare the performance of diagnostic and prognostic assays. The ROC curve has the advantage that it is independent of disease prevalence. However, in this note we remind readers that the performance of an assay upon translation to the clinic is critically dependent upon that very same prevalence. Without an understanding of prevalence in the test population, even robust bioassays with excellent ROC characteristics may perform poorly in the clinic. Instead, simple plots of candidate assay performance as a function of prevalence rate give a more realistic understanding of the likely real-world performance and a greater understanding of the likely impact of variation in that prevalence on translational performance in the clinic.
A Gaussian Process perspective on Convolutional Neural Networks
In this paper we cast the well-known convolutional neural network in a Gaussian process perspective. In this way we hope to gain additional insights into the performance of convolutional networks, in particular understand under what circumstances they tend to perform well and what assumptions are implicitly made in the network. While for feedforward networks the properties of convergence to Gaussian processes have been studied extensively, little is known about situations in which the output from a convolutional network approaches a multivariate normal distribution. In the convolutional net the sum is computed over variables which are not necessarily identically distributed, rendering the general central limit theorem useless. Nevertheless we can apply a Lyapunov-type bound on the distance between the Gaussian process and convolutional network output, and use this bound to study the properties under which the convolutional network behaves approximately like a Gaussian process, so that this behavior -depending on the application- can be either obtained or avoided.
The anatomy of Reddit: An overview of academic research
Online forums provide rich environments where users may post questions and comments about different topics. Understanding how people behave in online forums may shed light on the fundamental mechanisms by which collective thinking emerges in a group of individuals, but it has also important practical applications, for instance to improve user experience, increase engagement or automatically identify bullying. Importantly, the datasets generated by the activity of the users are often openly available for researchers, in contrast to other sources of data in computational social science. In this survey, we map the main research directions that arose in recent years and focus primarily on the most popular platform, Reddit. We distinguish and categorise research depending on their focus on the posts or on the users, and point to different types of methodologies to extract information from the structure and dynamics of the system. We emphasize the diversity and richness of the research in terms of questions and methods, and suggest future avenues of research.
Time Averages of Stochastic Processes: a Martingale Approach
This work shows how exponential concentration inequalities for time averages of stochastic processes over a finite time interval can be obtained from a martingale representation formula. The approach relies on mixing properties of the underlying process, applies to a wide range of initial conditions and makes no assumptions on stationarity or time-homogeneity. A direct method is presented for diffusion processes and discrete-time Markov processes. For general square-integrable processes the constants in the concentration inequalities can be expressed in terms of the quadratic variation of a family of auxiliary martingale. For continuous-time Markov processes they admit a natural expression in terms of the squared field operator applied to the semigroup. The paper concludes with two examples: the squared Ornstein-Uhlenbeck process and the
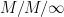
queue.
Stochastic Control with Stale Information-Part I: Fully Observable Systems
In this study, we adopt age of information as a measure of the staleness of information, and take initial steps towards analyzing the control performance of stochastic systems with stale information. Our goals are to cast light on a fundamental limit on the information staleness that is required for a certain level of the control performance and to specify the corresponding stalest information pattern. In the asymptotic regime, such a limit asserts a critical information staleness that is required for stabilization. We achieve these goals by formulating the problem as a stochastic optimization problem and characterizing the associated optimal solutions. These solutions are in fact a control policy, which specifies the control inputs of the plant, and a queuing policy, which specifies the staleness of information at the controller.
Reversible Recurrent Neural Networks
Recurrent neural networks (RNNs) provide state-of-the-art performance in processing sequential data but are memory intensive to train, limiting the flexibility of RNN models which can be trained. Reversible RNNs—RNNs for which the hidden-to-hidden transition can be reversed—offer a path to reduce the memory requirements of training, as hidden states need not be stored and instead can be recomputed during backpropagation. We first show that perfectly reversible RNNs, which require no storage of the hidden activations, are fundamentally limited because they cannot forget information from their hidden state. We then provide a scheme for storing a small number of bits in order to allow perfect reversal with forgetting. Our method achieves comparable performance to traditional models while reducing the activation memory cost by a factor of 10–15. We extend our technique to attention-based sequence-to-sequence models, where it maintains performance while reducing activation memory cost by a factor of 5–10 in the encoder, and a factor of 10–15 in the decoder.
• Antimagic orientations of disconnected even regular graphs
• Subgradient Descent Learns Orthogonal Dictionaries
• Joint modelling of progression-free and overall survival and computation of correlation measures
• OFDM based Sparse Time Dispersive Channel Estimation with Additional Spectral Knowledge
• Numerical approximation of optimal convex shapes
• Birkhoff sums of infinite observables and anomalous time-scaling of extreme events in infinite systems
• Note on (active-)QRAM-style data access as a quantum circuit
• Quenched normal approximation for random sequences of transformations
• Cheeger estimates of Dirichlet-to-Neumann operators on infinite subgraphs of graphs
• Geometry and clustering with metrics derived from separable Bregman divergences
• Relevance of backtracking paths in epidemic spreading on networks
• Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
• On the Convergence of the Polarization Process in the Noisiness/Weak-$\ast$ Topology
• Quantum Advantage for the LOCAL Model in Distributed Computing
• If $A+A$ is small then $AAA$ is superquadratic
• A support theorem for SLE curves
• An improved bound for the size of the set $A/A+A$
• Asymptotic observability identity for the heat equation in R^d
• Path-space moderate deviations for a class of Curie-Weiss models with dissipation
• On Policies for Single-leg Revenue Management with Limited Demand Information
• Periodic triangulations of $\mathbb{Z}^n$
• Inference in MCMC step selection models
• Spectral bounds for vanishing of cohomology and the neighborhood complex of a random graph
• Building Reality Checks into the Translational Pathway for Diagnostic and Prognostic Models
• On the Sample Complexity of PAC Learning Quantum Process
• Learning Neural Emotion Analysis from 100 Observations: The Surprising Effectiveness of Pre-Trained Word Representations
• Tensor Matched Kronecker-Structured Subspace Detection for Missing Information
• Signature moments to characterize laws of stochastic processes
• Fréchet Distance Under Translation: Conditional Hardness and an Algorithm via Offline Dynamic Grid Reachability
• Random Sampling: Practice Makes Imperfect
• Kazhdan groups have cost 1
Like this:
Like Loading...