A Parallel Random Forest Algorithm for Big Data in a Spark Cloud Computing Environment
With the emergence of the big data age, the issue of how to obtain valuable knowledge from a dataset efficiently and accurately has attracted increasingly attention from both academia and industry. This paper presents a Parallel Random Forest (PRF) algorithm for big data on the Apache Spark platform. The PRF algorithm is optimized based on a hybrid approach combining data-parallel and task-parallel optimization. From the perspective of data-parallel optimization, a vertical data-partitioning method is performed to reduce the data communication cost effectively, and a data-multiplexing method is performed is performed to allow the training dataset to be reused and diminish the volume of data. From the perspective of task-parallel optimization, a dual parallel approach is carried out in the training process of RF, and a task Directed Acyclic Graph (DAG) is created according to the parallel training process of PRF and the dependence of the Resilient Distributed Datasets (RDD) objects. Then, different task schedulers are invoked for the tasks in the DAG. Moreover, to improve the algorithm’s accuracy for large, high-dimensional, and noisy data, we perform a dimension-reduction approach in the training process and a weighted voting approach in the prediction process prior to parallelization. Extensive experimental results indicate the superiority and notable advantages of the PRF algorithm over the relevant algorithms implemented by Spark MLlib and other studies in terms of the classification accuracy, performance, and scalability.
The UCR Time Series Archive
The UCR Time Series Archive – introduced in 2002, has become an important resource in the time series data mining community, with at least one thousand published papers making use of at least one dataset from the archive. The original incarnation of the archive had sixteen datasets but since that time, it has gone through periodic expansions. The last expansion took place in the summer of 2015 when the archive grew from 45 datasets to 85 datasets. This paper introduces and will focus on the new data expansion from 85 to 128 datasets. Beyond expanding this valuable resource, this paper offers pragmatic advice to anyone who may wish to evaluate a new algorithm on the archive. Finally, this paper makes a novel and yet actionable claim: of the hundreds of papers that show an improvement over the standard baseline (1-Nearest Neighbor classification), a large fraction may be misattributing the reasons for their improvement. Moreover, they may have been able to achieve the same improvement with a much simpler modification, requiring just a single line of code.
A Periodicity-based Parallel Time Series Prediction Algorithm in Cloud Computing Environments
In the era of big data, practical applications in various domains continually generate large-scale time-series data. Among them, some data show significant or potential periodicity characteristics, such as meteorological and financial data. It is critical to efficiently identify the potential periodic patterns from massive time-series data and provide accurate predictions. In this paper, a Periodicity-based Parallel Time Series Prediction (PPTSP) algorithm for large-scale time-series data is proposed and implemented in the Apache Spark cloud computing environment. To effectively handle the massive historical datasets, a Time Series Data Compression and Abstraction (TSDCA) algorithm is presented, which can reduce the data scale as well as accurately extracting the characteristics. Based on this, we propose a Multi-layer Time Series Periodic Pattern Recognition (MTSPPR) algorithm using the Fourier Spectrum Analysis (FSA) method. In addition, a Periodicity-based Time Series Prediction (PTSP) algorithm is proposed. Data in the subsequent period are predicted based on all previous period models, in which a time attenuation factor is introduced to control the impact of different periods on the prediction results. Moreover, to improve the performance of the proposed algorithms, we propose a parallel solution on the Apache Spark platform, using the Streaming real-time computing module. To efficiently process the large-scale time-series datasets in distributed computing environments, Distributed Streams (DStreams) and Resilient Distributed Datasets (RDDs) are used to store and calculate these datasets. Extensive experimental results show that our PPTSP algorithm has significant advantages compared with other algorithms in terms of prediction accuracy and performance.
The Wasserstein transform
We introduce the Wasserstein transform, a method for enhancing and denoising datasets defined on general metric spaces. The construction draws inspiration from Optimal Transportation ideas. We establish precise connections with the mean shift family of algorithms and establish the stability of both our method and mean shift under data perturbation.
Identification of Causal Diffusion Effects Using Stationary Causal Directed Acyclic Graphs
Although social scientists have long been interested in the process through which ideas and behavior diffuse, the identification of causal diffusion effects, also known as peer effects, remains challenging. Many scholars consider the commonly used assumption of no omitted confounders to be untenable due to contextual confounding and homophily bias. To address this long-standing identification problem, I introduce a class of stationary causal directed acyclic graphs (DAGs), which represent the time-invariant nonparametric causal structure. I first show that this stationary causal DAG implies a new statistical test that can detect a wide range of biases, including the two types mentioned above. The proposed test allows researchers to empirically assess the contentious assumption of no omitted confounders. In addition, I develop a difference-in-difference style estimator that can directly correct biases under an additional parametric assumption. Leveraging the proposed methods, I study the spatial diffusion of hate crimes in Germany. After correcting large upward bias in existing studies, I find hate crimes diffuse only to areas that have a high proportion of school dropouts. To highlight the general applicability of the proposed approach, I also analyze the network diffusion of human rights norms. The proposed methodology is implemented in a forthcoming open source software package.
Applications of Deep Reinforcement Learning in Communications and Networking: A Survey
This paper presents a comprehensive literature review on applications of deep reinforcement learning in communications and networking. Modern networks, e.g., Internet of Things (IoT) and Unmanned Aerial Vehicle (UAV) networks, become more decentralized and autonomous. In such networks, network entities need to make decisions locally to maximize the network performance under uncertainty of network environment. Reinforcement learning has been efficiently used to enable the network entities to obtain the optimal policy including, e.g., decisions or actions, given their states when the state and action spaces are small. However, in complex and large-scale networks, the state and action spaces are usually large, and the reinforcement learning may not be able to find the optimal policy in reasonable time. Therefore, deep reinforcement learning, a combination of reinforcement learning with deep learning, has been developed to overcome the shortcomings. In this survey, we first give a tutorial of deep reinforcement learning from fundamental concepts to advanced models. Then, we review deep reinforcement learning approaches proposed to address emerging issues in communications and networking. The issues include dynamic network access, data rate control, wireless caching, data offloading, network security, and connectivity preservation which are all important to next generation networks such as 5G and beyond. Furthermore, we present applications of deep reinforcement learning for traffic routing, resource sharing, and data collection. Finally, we highlight important challenges, open issues, and future research directions of applying deep reinforcement learning.
A Self-Organizing Tensor Architecture for Multi-View Clustering
In many real-world applications, data are often unlabeled and comprised of different representations/views which often provide information complementary to each other. Although several multi-view clustering methods have been proposed, most of them routinely assume one weight for one view of features, and thus inter-view correlations are only considered at the view-level. These approaches, however, fail to explore the explicit correlations between features across multiple views. In this paper, we introduce a tensor-based approach to incorporate the higher-order interactions among multiple views as a tensor structure. Specifically, we propose a multi-linear multi-view clustering (MMC) method that can efficiently explore the full-order structural information among all views and reveal the underlying subspace structure embedded within the tensor. Extensive experiments on real-world datasets demonstrate that our proposed MMC algorithm clearly outperforms other related state-of-the-art methods.
Urban Swarms: A new approach for autonomous waste management
Modern cities are growing ecosystems that face new challenges due to the increasing population demands. One of the many problems they face nowadays is waste management, which has become a pressing issue requiring new solutions. Swarm robotics systems have been attracting an increasing amount of attention in the past years and they are expected to become one of the main driving factors for innovation in the field of robotics. The research presented in this paper explores the feasibility of a swarm robotics system in an urban environment. By using bio-inspired foraging methods such as multi-place foraging and stigmergy-based navigation, a swarm of robots is able to improve the efficiency and autonomy of the urban waste management system in a realistic scenario. To achieve this, a diverse set of simulation experiments was conducted using real-world GIS data and implementing different garbage collection scenarios driven by robot swarms. Results presented in this research show that the proposed system outperforms current approaches. Moreover, results not only show the efficiency of our solution, but also give insights about how to design and customize these systems.
Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training
Recent deep networks achieved state of the art performance on a variety of semantic segmentation tasks. Despite such progress, these models often face challenges in real world `wild tasks’ where large difference between labeled training/source data and unseen test/target data exists. In particular, such difference is often referred to as `domain gap’, and could cause significantly decreased performance which cannot be easily remedied by further increasing the representation power. Unsupervised domain adaptation (UDA) seeks to overcome such problem without target domain labels. In this paper, we propose a novel UDA framework based on an iterative self-training procedure, where the problem is formulated as latent variable loss minimization, and can be solved by alternatively generating pseudo labels on target data and re-training the model with these labels. On top of self-training, we also propose a novel class-balanced self-training framework to avoid the gradual dominance of large classes on pseudo-label generation, and introduce spatial priors to refine generated labels. Comprehensive experiments show that the proposed methods achieve state of the art semantic segmentation performance under multiple major UDA settings.
Entropic Variable Boosting for Explainability and Interpretability in Machine Learning
In this paper, we present a new explainability formalism to make clear the impact of each variable on the predictions given by black-box decision rules. Our method consists in evaluating the decision rules on test samples generated in such a way that each variable is stressed incrementally while preserving the original distribution of the machine learning problem. We then propose a new computation-ally efficient algorithm to stress the variables, which only reweights the reference observations and predictions. This makes our methodology scalable to large datasets. Results obtained on standard machine learning datasets are presented and discussed.
Unsupervised Neural Text Simplification
The paper presents a first attempt towards unsupervised neural text simplification that relies only on unlabeled text corpora. The core framework is comprised of a shared encoder and a pair of attentional-decoders that gains knowledge of both text simplification and complexification through discriminator-based-losses, back-translation and denoising. The framework is trained using unlabeled text collected from en-Wikipedia dump. Our analysis (both quantitative and qualitative involving human evaluators) on a public test data shows the efficacy of our model to perform simplification at both lexical and syntactic levels, competitive to existing supervised methods. We open source our implementation for academic use.
HierLPR: Decision making in hierarchical multi-label classification with local precision rates
In this article we propose a novel ranking algorithm, referred to as HierLPR, for the multi-label classification problem when the candidate labels follow a known hierarchical structure. HierLPR is motivated by a new metric called eAUC that we design to assess the ranking of classification decisions. This metric, associated with the hit curve and local precision rate, emphasizes the accuracy of the first calls. We show that HierLPR optimizes eAUC under the tree constraint and some light assumptions on the dependency between the nodes in the hierarchy. We also provide a strategy to make calls for each node based on the ordering produced by HierLPR, with the intent of controlling FDR or maximizing F-score. The performance of our proposed methods is demonstrated on synthetic datasets as well as a real example of disease diagnosis using NCBI GEO datasets. In these cases, HierLPR shows a favorable result over competing methods in the early part of the precision-recall curve.
An Upper Bound for Random Measurement Error in Causal Discovery
Causal discovery algorithms infer causal relations from data based on several assumptions, including notably the absence of measurement error. However, this assumption is most likely violated in practical applications, which may result in erroneous, irreproducible results. In this work we show how to obtain an upper bound for the variance of random measurement error from the covariance matrix of measured variables and how to use this upper bound as a correction for constraint-based causal discovery. We demonstrate a practical application of our approach on both simulated data and real-world protein signaling data.
Variational Noise-Contrastive Estimation
Unnormalised latent variable models are a broad and flexible class of statistical models. However, learning their parameters from data is intractable, and few estimation techniques are currently available for such models. To increase the number of techniques in our arsenal, we propose variational noise-contrastive estimation (VNCE), building on NCE which is a method that only applies to unnormalised models. The core idea is to use a variational lower bound to the NCE objective function, which can be optimised in the same fashion as the evidence lower bound (ELBO) in standard variational inference (VI). We prove that VNCE can be used for both parameter estimation of unnormalised models and posterior inference of latent variables. The developed theory shows that VNCE has the same level of generality as standard VI, meaning that advances made there can be directly imported to the unnormalised setting. We validate VNCE on toy models and apply it to a realistic problem of estimating an undirected graphical model from incomplete data.
Modelling and Enactment of Data-aware Processes
During the last two decades, increasing attention has been given to the challenging problem of resolving the dichotomy between business process management and master data management. Consequently, a substantial number of data-centric models of dynamic systems have been brought forward. However, the control-flow abstractions they adopt are ad-hoc, and so are the data models they use. At the same time, contemporary process management systems rely on well-established formalisms for representing the control-flow and typically employ full-fledged relational databases for storing master data. Nevertheless, they miss a conceptually clean representation of the task and condition logic, that is, of how data are queried and updated by the process. In this paper, we address such issues by proposing a general, pristine approach to model processes operating on top of the standard relational technology. Specifically, we propose a declarative language based on SQL that supports the conceptual modelling of control-flow conditions and of persistent data updates with external inputs. We show how this language can be automatically translated into a concrete procedural SQL dialect, consequently providing in-database process execution support. We then report on how we made the language operational into a concrete prototype, which provides a plethora of functionalities to specify and enact process models, inspect their execution state, and construct their state space. Notably, the proposed approach can be seen as the concrete counterpart of one of the most well-established formal frameworks for data-aware processes, thus enjoying all the formal properties and verifiability conditions studied therein.
Determining the Number of Components in PLS Regression on Incomplete Data
Partial least squares regression—or PLS—is a multivariate method in which models are estimated using either the SIMPLS or NIPALS algorithm. PLS regression has been extensively used in applied research because of its effectiveness in analysing relationships between an outcome and one or several components. Note that the NIPALS algorithm is able to provide estimates on incomplete data. Selection of the number of components used to build a representative model in PLS regression is an important problem. However, how to deal with missing data when using PLS regression remains a matter of debate. Several approaches have been proposed in the literature, including the
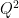
criterion, and the AIC and BIC criteria. Here we study the behavior of the NIPALS algorithm when used to fit a PLS regression for various proportions of missing data and for different types of missingness. We compare criteria for selecting the number of components for a PLS regression on incomplete data and on imputed datasets using three imputation methods: multiple imputation by chained equations, k-nearest neighbor imputation, and singular value decomposition imputation. Various criteria were tested with different proportions of missing data (ranging from 5% to 50%) under different missingness assumptions. Q2-leave-one-out component selection methods gave more reliable results than AIC and BIC-based ones.
KTAN: Knowledge Transfer Adversarial Network
To reduce the large computation and storage cost of a deep convolutional neural network, the knowledge distillation based methods have pioneered to transfer the generalization ability of a large (teacher) deep network to a light-weight (student) network. However, these methods mostly focus on transferring the probability distribution of the softmax layer in a teacher network and thus neglect the intermediate representations. In this paper, we propose a knowledge transfer adversarial network to better train a student network. Our technique holistically considers both intermediate representations and probability distributions of a teacher network. To transfer the knowledge of intermediate representations, we set high-level teacher feature maps as a target, toward which the student feature maps are trained. Specifically, we arrange a Teacher-to-Student layer for enabling our framework suitable for various student structures. The intermediate representation helps the student network better understand the transferred generalization as compared to the probability distribution only. Furthermore, we infuse an adversarial learning process by employing a discriminator network, which can fully exploit the spatial correlation of feature maps in training a student network. The experimental results demonstrate that the proposed method can significantly improve the performance of a student network on both image classification and object detection tasks.
Private Machine Learning in TensorFlow using Secure Computation
We present a framework for experimenting with secure multi-party computation directly in TensorFlow. By doing so we benefit from several properties valuable to both researchers and practitioners, including tight integration with ordinary machine learning processes, existing optimizations for distributed computation in TensorFlow, high-level abstractions for expressing complex algorithms and protocols, and an expanded set of familiar tooling. We give an open source implementation of a state-of-the-art protocol and report on concrete benchmarks using typical models from private machine learning.
Contextual Topic Modeling For Dialog Systems
Accurate prediction of conversation topics can be a valuable signal for creating coherent and engaging dialog systems. In this work, we focus on context-aware topic classification methods for identifying topics in free-form human-chatbot dialogs. We extend previous work on neural topic classification and unsupervised topic keyword detection by incorporating conversational context and dialog act features. On annotated data, we show that incorporating context and dialog acts leads to relative gains in topic classification accuracy by 35% and on unsupervised keyword detection recall by 11% for conversational interactions where topics frequently span multiple utterances. We show that topical metrics such as topical depth is highly correlated with dialog evaluation metrics such as coherence and engagement implying that conversational topic models can predict user satisfaction. Our work for detecting conversation topics and keywords can be used to guide chatbots towards coherent dialog.
Coded Caching for Heterogeneous Systems: An Optimization Perspective
In cache-aided networks, the server populates the cache memories at the users during low-traffic periods, in order to reduce the delivery load during peak-traffic hours. In turn, there exists a fundamental trade-off between the delivery load on the server and the cache sizes at the users. In this paper, we study this trade-off in a multicast network where the server is connected to users with unequal cache sizes. We propose centralized uncoded placement and linear delivery schemes which are optimized by solving a linear program. Additionally, we derive a lower bound on the delivery memory trade-off with uncoded placement that accounts for the heterogeneity in cache sizes. We explicitly characterize this trade-off for the case of three end-users, as well as an arbitrary number of end-users when the total memory size at the users is small, and when it is large. Next, we consider a system where the server is connected to the users via rate limited links of different capacities and the server assigns the users’ cache sizes subject to a total cache budget. We characterize the optimal cache sizes that minimize the delivery completion time with uncoded placement and linear delivery. In particular, the optimal memory allocation balances between assigning larger cache sizes to users with low capacity links and uniform memory allocation.
• Description of sup- and inf-preserving aggregation functions via families of clusters in data tables
• Alignments as Compositional Structures
• Responsible team players wanted: an analysis of soft skill requirements in job advertisements
• MaaSim: A Liveability Simulation for Improving the Quality of Life in Cities
• Thou shalt not say ‘at random’ in vain: Bertrand’s paradox exposed
• From Deep to Physics-Informed Learning of Turbulence: Diagnostics
• AutoGraph: Imperative-style Coding with Graph-based Performance
• Deep Diabetologist: Learning to Prescribe Hyperglycemia Medications with Hierarchical Recurrent Neural Networks
• Information-Theoretic Extensions of the Shannon-Nyquist Sampling Theorem
• k-RNN: Extending NN-heuristics for the TSP
• The Institutional Approach
• The loss surface of deep linear networks viewed through the algebraic geometry lens
• Towards Optimal Running Times for Optimal Transport
• Further Results on Existentially Closed Graphs Arising from Block Designs
• RIn-Close_CVC2: an even more efficient enumerative algorithm for biclustering of numerical datasets
• Exponential Convergence Rates for Stochastically Ordered Markov Processes with Random Initial Conditions
• Video Segmentation using Teacher-Student Adaptation in a Human Robot Interaction (HRI) Setting
• Implied and Realized Volatility: A Study of the Ratio Distribution
• A natural 4-parameter family of covariance functions for stationary Gaussian processes
• A Bi-layered Parallel Training Architecture for Large-scale Convolutional Neural Networks
• PepCVAE: Semi-Supervised Targeted Design of Antimicrobial Peptide Sequences
• A Convolutional Autoencoder Approach to Learn Volumetric Shape Representations for Brain Structures
• Forman’s Ricci curvature – From networks to hypernetworks
• On mean decomposition for summarizing conditional distributions
• Extremal decomposition for random Gibbs measures
• A Disease Diagnosis and Treatment Recommendation System Based on Big Data Mining and Cloud Computing
• Distributed Learning over Unreliable Networks
• Finite sample expressive power of small-width ReLU networks
• Simulation and Real-World Evaluation of Attack Detection Schemes
• Multi-Agent Fully Decentralized Off-Policy Learning with Linear Convergence Rates
• Stability of the potential function
• LadderNet: Multi-path networks based on U-Net for medical image segmentation
• Openness and Impact of Leading Scientific Countries
• The Matching Augmentation Problem: A $\frac74$-Approximation Algorithm
• When Can We Answer Queries Using Result-Bounded Data Interfaces?
• Finding Maximal Sets of Laminar 3-Separators in Planar Graphs in Linear Time
• Superimposed frame synchronization optimization for Finite block-length regime
• Deformations of closed measures and variational characterization of measures invariant under the Euler-Lagrange flow
• A Novel Focal Tversky loss function with improved Attention U-Net for lesion segmentation
• On Statistical Learning of Simplices: Unmixing Problem Revisited
• Phase Reduction of Stochastic Biochemical Oscillators
• Distributed $k$-Clustering for Data with Heavy Noise
• Fast Blind MIMO Decoding through Vertex Hopping
• Optimum Overflow Thresholds in Variable-Length Source Coding Allowing Non-Vanishing Error Probability
• Hamiltonian decomposition of the Cayley graph on the dihedral group $D_{2p}$ where $p$ is a prime
• Power-law distributions in geoscience revisited
• Differentially Private Double Spectrum Auction with Approximate Social Welfare Maximization
• Hierarchical Network Item Response Modeling for Discovering Differences Between Innovation and Regular School Systems in Korea
• Automatic Brain Tumor Segmentation using Convolutional Neural Networks with Test-Time Augmentation
• Profile-Based Ad Hoc Social Networking Using Wi-Fi Direct on the Top of Android
• Robust Transmissions in Wireless Powered Multi-Relay Networks with Chance Interference Constraints
• Solving Linear Programs in the Current Matrix Multiplication Time
• Two-component Mixture Model in the Presence of Covariates
• Trust Region Policy Optimization of POMDPs
• Decoupling Semantic Context and Color Correlation with multi-class cross branch regularization
• Structured gene-environment interaction analysis
• Tight Competitive Ratios of Classic Matching Algorithms in the Fully Online Model
• Distributionally Robust Reduced Rank Regression and Principal Component Analysis in High Dimensions
• Tracking Influential Nodes in Time-Decaying Dynamic Interaction Networks
• Spatial Multiple Access (SMA): Enhancing performances of MIMO-NOMA systems
• Concentration of the Frobenius norms of pseudoinverses
• Global well-posedness for the defocusing mass-critical stochastic nonlinear Schrödinger equation on $\mathbb{R}$ at $L^2$ regularity
• Unsupervised Domain Adaptation for Learning Eye Gaze from a Million Synthetic Images: An Adversarial Approach
• Generalized Lyapunov criteria on finite-time stability of stochastic nonlinear systems
• Multi-scale approach for analyzing convective heat transfer flow in background-oriented Schlieren technique
• On Socially Optimal Traffic Flow in the Presence of Random Users
• A tangent method derivation of the arctic curve for q-weighted paths with arbitrary starting points
• Semantic Parsing for Task Oriented Dialog using Hierarchical Representations
• Existence and regularity of optimal shapes for elliptic operators with drift
• Accurate and Scalable Image Clustering Based On Sparse Representation of Camera Fingerprint
• A Temporally Sensitive Submodularity Framework for Timeline Summarization
• Some properties of a class of refined Eulerian polynomials
• S-Net: A Scalable Convolutional Neural Network for JPEG Compression Artifact Reduction
• LeukoNet: DCT-based CNN architecture for the classification of normal versus Leukemic blasts in B-ALL Cancer
• Reflected backward stochastic differential equations with two optional barriers
• Inglenook Shunting Puzzles
• A generalized conservation property for the heat semigroup on weighted manifolds
• Interrogation of spline surfaces with application to isogeometric design and analysis of lattice-skin structures
• Complexity of computing the anti-Ramsey numbers
• Optimal control of a non-smooth quasilinear elliptic equation
• Optical Font Recognition in Smartphone-Captured Images, and its Applicability for ID Forgery Detection
• A mathematical theory of imperfect communication: Energy efficiency considerations in multi-level coding
• On a Conjecture for Dynamic Priority Queues and Nash Equilibrium for Quality of Service Sensitive Markets
• A new determinant for the $Q$-enumeration of alternating sign matrices
• Challenging nostalgia and performance metrics in baseball
• Augmenting Adjusted Plus-Minus in Soccer with FIFA Ratings
• Adaptivity of deep ReLU network for learning in Besov and mixed smooth Besov spaces: optimal rate and curse of dimensionality
• Implicit Dual-domain Convolutional Network for Robust Color Image Compression Artifact Reduction
• Finding Average Regret Ratio Minimizing Set in Database
• Abelian Noncyclic Orbit Codes and Multishot Subspace Codes
• Locally Private Mean Estimation: Z-test and Tight Confidence Intervals
• Wave to pulse generation. From oscillatory synapse to train of action potentials
• On estimation of biconvex sets
• Expectation Propagation for Poisson Data
• Discourse Embellishment Using a Deep Encoder-Decoder Network
• Good Initializations of Variational Bayes for Deep Models
• Using Pseudocodewords to Transmit Information
• Dictionary Learning Phase Retrieval from Noisy Diffraction Patterns
• Deconstructing the Blockchain to Approach Physical Limits
• Stochastic Distance Transform
• Robust Distributed Cooperative RSS-based Localization for Directed Graphs in Mixed LoS/NLoS Environments
• DeepLens: Shallow Depth Of Field From A Single Image
• First-order and second-order variants of the gradient descent: a unified framework
• Salience Biased Loss for Object Detection in Aerial Images
• Subcritical random hypergraphs, high-order components, and hypertrees
• Best-of-two-worlds analysis of online search
• Adversarial TableQA: Attention Supervision for Question Answering on Tables
• Invariant spanning double rays in amenable groups
• Hölder continuity of the solutions to a class of SPDEs arising from multidimensional superprocesses in random environment
• Approximate Dynamic Programming for Planning a Ride-Sharing System using Autonomous Fleets of Electric Vehicles
• Hausdorff dimension of pinned distance sets and the $L^2$-method
• Is It Possible to Stabilize Disrete-time Parameterized Uncertain Systems Growing Exponentially Fast?
• Bilinear Adaptive Generalized Vector Approximate Message Passing
• Impact of model misspecification in shared frailty survival models
• A Non-Intrusive Low-Rank Approximation Method for Assessing the Probabilistic Available Transfer Capability
• Multiline queues with spectral parameters
• Planning in Stochastic Environments with Goal Uncertainty
• Ratio List Decoding
• Fast deep reinforcement learning using online adjustments from the past
• Exploiting Correlation in Finite-Armed Structured Bandits
• Exploiting High-Level Semantics for No-Reference Image Quality Assessment of Realistic Blur Images
• Testing Matrix Rank, Optimally
• Gradient Agreement as an Optimization Objective for Meta-Learning
• Thermodynamics and Feature Extraction by Machine Learning
• Near-critical percolation with heavy-tailed impurities, forest fires and frozen percolation
• Convolutional Collaborative Filter Network for Video Based Recommendation Systems
Like this:
Like Loading...