Machine learning 2.0 : Engineering Data Driven AI Products
ML 2.0: In this paper, we propose a paradigm shift from the current practice of creating machine learning models – which requires months-long discovery, exploration and ‘feasibility report’ generation, followed by re-engineering for deployment – in favor of a rapid, 8-week process of development, understanding, validation and deployment that can executed by developers or subject matter experts (non-ML experts) using reusable APIs. This accomplishes what we call a ‘minimum viable data-driven model,’ delivering a ready-to-use machine learning model for problems that haven’t been solved before using machine learning. We provide provisions for the refinement and adaptation of the ‘model,’ with strict enforcement and adherence to both the scaffolding/abstractions and the process. We imagine that this will bring forth the second phase in machine learning, in which discovery is subsumed by more targeted goals of delivery and impact.
Multi-distance Support Matrix Machines
Real-world data such as digital images, MRI scans and electroencephalography signals are naturally represented as matrices with structural information. Most existing classifiers aim to capture these structures by regularizing the regression matrix to be low-rank or sparse. Some other methodologies introduce factorization technique to explore nonlinear relationships of matrix data in kernel space. In this paper, we propose a multi-distance support matrix machine (MDSMM), which provides a principled way of solving matrix classification problems. The multi-distance is introduced to capture the correlation within matrix data, by means of intrinsic information in rows and columns of input data. A complex hyperplane is established upon these values to separate distinct classes. We further study the generalization bounds for i.i.d. processes and non i.i.d. process based on both SVM and SMM classifiers. For typical hypothesis classes where matrix norms are constrained, MDSMM achieves a faster learning rate than traditional classifiers. We also provide a more general approach for samples without prior knowledge. We demonstrate the merits of the proposed method by conducting exhaustive experiments on both simulation study and a number of real-word datasets.
Elastic Neural Networks: A Scalable Framework for Embedded Computer Vision
We propose a new framework for image classification with deep neural networks. The framework introduces intermediate outputs to the computational graph of a network. This enables flexible control of the computational load and balances the tradeoff between accuracy and execution time. Moreover, we present an interesting finding that the intermediate outputs can act as a regularizer at training time, improving the prediction accuracy. In the experimental section we demonstrate the performance of our proposed framework with various commonly used pretrained deep networks in the use case of apparent age estimation.
Evenly Cascaded Convolutional Networks
In this paper we demonstrate that state-of-the-art convolutional neural networks can be constructed using a cascade algorithm for deep networks, inspired by the cascade algorithm in wavelet analysis. For each network layer the cascade algorithm creates two streams of features from the previous layer: one stream modulates the existing features producing low-level features, the other stream produces new features of a higher level. We evenly structure our network by resizing feature map dimensions by a consistent ratio. Our network produces humanly interpretable features maps, a result whose intuition can be understood in the context of scale-space theory. We demonstrate that our cascaded design facilitates the training process through providing easily trainable shortcuts. We report new state-of-the-art results for small networks – a consequence of our architecture’s simple structure and direct training, without the need for additional treatment such as pruning or compression. Our 6-cascading-layer design with under 500k parameters achieves 95.24% and 78.99% accuracy on CIFAR-10 and CIFAR-100 datasets, respectively.
How To Backdoor Federated Learning
Federated learning enables multiple participants to jointly construct a deep learning model without sharing their private training data with each other. For example, multiple smartphones can jointly train a predictive keyboard model without revealing what individual users type into their phones. We demonstrate that any participant in federated learning can introduce hidden backdoor functionality into the joint global model, e.g., to ensure that an image classifier assigns an attacker-chosen label to images with certain features, or that a next-word predictor completes certain sentences with an attacker-chosen word. We design and evaluate a new ‘constrain-and-scale’ model-poisoning methodology and show that it greatly outperforms data poisoning. An attacker selected just once, in a single round of federated learning, can cause the global model to reach 100% accuracy on the backdoor task. We evaluate the attack under different assumptions and attack scenarios for standard federated learning tasks. We also show how to evade anomaly detection-based defenses by incorporating the evasion into the loss function when training the attack model.
ColdRoute: Effective Routing of Cold Questions in Stack Exchange Sites
Routing questions in Community Question Answer services (CQAs) such as Stack Exchange sites is a well-studied problem. Yet, cold-start — a phenomena observed when a new question is posted is not well addressed by existing approaches. Additionally, cold questions posted by new askers present significant challenges to state-of-the-art approaches. We propose ColdRoute to address these challenges. ColdRoute is able to handle the task of routing cold questions posted by new or existing askers to matching experts. Specifically, we use Factorization Machines on the one-hot encoding of critical features such as question tags and compare our approach to well-studied techniques such as CQARank and semantic matching (LDA, BoW, and Doc2Vec). Using data from eight stack exchange sites, we are able to improve upon the routing metrics (Precision
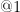
, Accuracy, MRR) over the state-of-the-art models such as semantic matching by
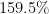
,
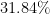
, and
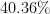
for cold questions posted by existing askers, and
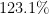
,

, and

for cold questions posted by new askers respectively.
Automated Directed Fairness Testing
Fairness is a critical trait in decision making. As machine-learning models are increasingly being used in sensitive application domains (e.g. education and employment) for decision making, it is crucial that the decisions computed by such models are free of unintended bias. But how can we automatically validate the fairness of arbitrary machine-learning models For a given machine-learning model and a set of sensitive input parameters, our AEQUITAS approach automatically discovers discriminatory inputs that highlight fairness violation. At the core of AEQUITAS are three novel strategies to employ probabilistic search over the input space with the objective of uncovering fairness violation. Our AEQUITAS approach leverages inherent robustness property in common machine-learning models to design and implement scalable test generation methodologies. An appealing feature of our generated test inputs is that they can be systematically added to the training set of the underlying model and improve its fairness. To this end, we design a fully automated module that guarantees to improve the fairness of the underlying model. We implemented AEQUITAS and we have evaluated it on six state-of-the-art classifiers, including a classifier that was designed with fairness constraints. We show that AEQUITAS effectively generates inputs to uncover fairness violation in all the subject classifiers and systematically improves the fairness of the respective models using the generated test inputs. In our evaluation, AEQUITAS generates up to 70% discriminatory inputs (w.r.t. the total number of inputs generated) and leverages these inputs to improve the fairness up to 94%.
FATE: Fast and Accurate Timing Error Prediction Framework for Low Power DNN Accelerator Design
Deep neural networks (DNN) are increasingly being accelerated on application-specific hardware such as the Google TPU designed especially for deep learning. Timing speculation is a promising approach to further increase the energy efficiency of DNN accelerators. Architectural exploration for timing speculation requires detailed gate-level timing simulations that can be time-consuming for large DNNs that execute millions of multiply-and-accumulate (MAC) operations. In this paper we propose FATE, a new methodology for fast and accurate timing simulations of DNN accelerators like the Google TPU. FATE proposes two novel ideas: (i) DelayNet, a DNN based timing model for MAC units; and (ii) a statistical sampling methodology that reduces the number of MAC operations for which timing simulations are performed. We show that FATE results in between 8 times-58 times speed-up in timing simulations, while introducing less than 2% error in classification accuracy estimates. We demonstrate the use of FATE by comparing to conventional DNN accelerator that uses 2’s complement (2C) arithmetic with an alternative implementation that uses signed magnitude representations (SMR). We show that that the SMR implementation provides 18% more energy savings for the same classification accuracy than 2C, a result that might be of independent interest.
Active Testing: An Efficient and Robust Framework for Estimating Accuracy
Much recent work on visual recognition aims to scale up learning to massive, noisily-annotated datasets. We address the problem of scaling-up the evaluation of such models to large-scale datasets with noisy labels. Current protocols for doing so require a human user to either vet (re-annotate) a small fraction of the test set and ignore the rest, or else correct errors in annotation as they are found through manual inspection of results. In this work, we re-formulate the problem as one of active testing, and examine strategies for efficiently querying a user so as to obtain an accurate performance estimate with minimal vetting. We demonstrate the effectiveness of our proposed active testing framework on estimating two performance metrics, Precision@K and mean Average Precision, for two popular computer vision tasks, multi-label classification and instance segmentation. We further show that our approach is able to save significant human annotation effort and is more robust than alternative evaluation protocols.
Deep Reasoning with Knowledge Graph for Social Relationship Understanding
Social relationships (e.g., friends, couple etc.) form the basis of the social network in our daily life. Automatically interpreting such relationships bears a great potential for the intelligent systems to understand human behavior in depth and to better interact with people at a social level. Human beings interpret the social relationships within a group not only based on the people alone, and the interplay between such social relationships and the contextual information around the people also plays a significant role. However, these additional cues are largely overlooked by the previous studies. We found that the interplay between these two factors can be effectively modeled by a novel structured knowledge graph with proper message propagation and attention. And this structured knowledge can be efficiently integrated into the deep neural network architecture to promote social relationship understanding by an end-to-end trainable Graph Reasoning Model (GRM), in which a propagation mechanism is learned to propagate node message through the graph to explore the interaction between persons of interest and the contextual objects. Meanwhile, a graph attentional mechanism is introduced to explicitly reason about the discriminative objects to promote recognition. Extensive experiments on the public benchmarks demonstrate the superiority of our method over the existing leading competitors.
Balanced Distribution Adaptation for Transfer Learning
Transfer learning has achieved promising results by leveraging knowledge from the source domain to annotate the target domain which has few or none labels. Existing methods often seek to minimize the distribution divergence between domains, such as the marginal distribution, the conditional distribution or both. However, these two distances are often treated equally in existing algorithms, which will result in poor performance in real applications. Moreover, existing methods usually assume that the dataset is balanced, which also limits their performances on imbalanced tasks that are quite common in real problems. To tackle the distribution adaptation problem, in this paper, we propose a novel transfer learning approach, named as Balanced Distribution \underline{A}daptation~(BDA), which can adaptively leverage the importance of the marginal and conditional distribution discrepancies, and several existing methods can be treated as special cases of BDA. Based on BDA, we also propose a novel Weighted Balanced Distribution Adaptation~(W-BDA) algorithm to tackle the class imbalance issue in transfer learning. W-BDA not only considers the distribution adaptation between domains but also adaptively changes the weight of each class. To evaluate the proposed methods, we conduct extensive experiments on several transfer learning tasks, which demonstrate the effectiveness of our proposed algorithms over several state-of-the-art methods.
Relational Constraints for Metric Learning on Relational Data
Most of metric learning approaches are dedicated to be applied on data described by feature vectors, with some notable exceptions such as times series, trees or graphs. The objective of this paper is to propose a metric learning algorithm that specifically considers relational data. The proposed approach can take benefit from both the topological structure of the data and supervised labels. For selecting relative constraints representing the relational information, we introduce a link-strength function that measures the strength of relationship links between entities by the side-information of their common parents. We show the performance of the proposed method with two different classical metric learning algorithms, which are ITML (Information Theoretic Metric Learning) and LSML (Least Squares Metric Learning), and test on several real-world datasets. Experimental results show that using relational information improves the quality of the learned metric.
The Interplay between Lexical Resources and Natural Language Processing
Incorporating linguistic, world and common sense knowledge into AI/NLP systems is currently an important research area, with several open problems and challenges. At the same time, processing and storing this knowledge in lexical resources is not a straightforward task. This tutorial proposes to address these complementary goals from two methodological perspectives: the use of NLP methods to help the process of constructing and enriching lexical resources and the use of lexical resources for improving NLP applications. Two main types of audience can benefit from this tutorial: those working on language resources who are interested in becoming acquainted with automatic NLP techniques, with the end goal of speeding and/or easing up the process of resource curation; and on the other hand, researchers in NLP who would like to benefit from the knowledge of lexical resources to improve their systems and models. The slides of the tutorial are available at
https://…/lr-nlp
Neural Lattice Decoders
Lattice decoders constructed with neural networks are presented. Firstly, we show how the fundamental parallelotope is used as a compact set for the approximation by a neural lattice decoder. Secondly, we introduce the notion of Voronoi-reduced lattice basis. As a consequence, a first optimal neural lattice decoder is built from Boolean equations and the facets of the Voronoi region. This decoder needs no learning. Finally, we present two neural decoders with learning. It is shown that L1 regularization and a priori information about the lattice structure lead to a simplification of the model.
• Adaptive Optimal Transport
• Framework for the hybrid parallelisation of simulation codes
• cilantro: a lean, versatile, and efficient library for point cloud data processing
• Antithetic and Monte Carlo kernel estimators for partial rankings
• Towards Mixed Optimization for Reinforcement Learning with Program Synthesis
• A polynomial time log barrier method for problems with nonconvex constraints
• New Representation of Levy Stochastic Area, Based on Legendre polynomials
• Learning to Drive in a Day
• Optimization of neural networks via finite-value quantum fluctuations
• The Bretton Woods Experience and ERM
• Maastricht and Monetary Cooperation
• A Piecewise Deterministic Markov Process via $(r,θ)$ swaps in hyperspherical coordinates
• Heat kernel for Liouville Brownian motion and Liouville graph distance
• Dynamic Prediction Length for Time Series with Sequence to Sequence Networks
• Confounding variables can degrade generalization performance of radiological deep learning models
• Liver Lesion Detection from Weakly-labeled Multi-phase CT Volumes with a Grouped Single Shot MultiBox Detector
• Dynamic Swarm Dispersion in Particle Swarm Optimization for Mining Unsearched Area in Solution Space (DSDPSO)
• Policy Optimization With Penalized Point Probability Distance: An Alternative To Proximal Policy Optimization
• Generative discriminative models for multivariate inference and statistical mapping in medical imaging
• Channel Agnostic End-to-End Learning based Communication Systems with Conditional GAN
• Speeding up the Metabolism in E-commerce by Reinforcement Mechanism Design
• Quantum critical phenomena of excitonic insulating transition in two dimensions
• Multi-Stage Complex Contagions in Random Multiplex Networks
• Adversarial Perturbations Against Real-Time Video Classification Systems
• Estimation of Large Motion in Lung CT by Integrating Regularized Keypoint Correspondences into Dense Deformable Registration
• Exact solution to an extremal problem on graphic sequences with a realization containing every $2$-tree on $k$ vertices
• Zero-determinant strategies in repeated incomplete-information games: Consistency of payoff relations
• On the vertex cover number of 3 uniform hypergraph
• Information theoretic limits of state-dependent networks
• Perfectly Controllable Multi-Agent Networks
• The perfect matching association scheme
• Tap-based User Authentication for Smartwatches
• Exit problems for positive self-similar Markov processes with one-sided jumps
• An initial study on estimating area of a leaf using image processing
• A Simple but Effective Classification Model for Grammatical Error Correction
• Rate of Convergence to the Circular Law via Smoothing Inequalities for Log-Potentials
• The size distribution of cities: a kinetic explanation
• Estimating Phenotypic Traits From UAV Based RGB Imagery
• Leveraging Uncertainty Estimates for Predicting Segmentation Quality
• Knowledge-Embedded Representation Learning for Fine-Grained Image Recognition
• COSMO: Contextualized Scene Modeling with Boltzmann Machines
• Optimal Assignments with Supervisions
• Women also Snowboard: Overcoming Bias in Captioning Models (Extended Abstract)
• Extremes of Gaussian chaos processes with Trend
• Orientations and bijections for toroidal maps with prescribed face-degrees and essential girth
• Stochastic model specification in Markov switching vector error correction models
• SphereReID: Deep Hypersphere Manifold Embedding for Person Re-Identification
• One-point function estimates for loop-erased random walk in three dimensions
• Punctuation Prediction Model for Conversational Speech
• Eigenvectors of Laplacian or signless Laplacian of Hypergraphs Associated with Zero Eigenvalue
• Clustering with Temporal Constraints on Spatio-Temporal Data of Human Mobility
• Realisation of groups as automorphism groups in categories
• A Broader View on Bias in Automated Decision-Making: Reflecting on Epistemology and Dynamics
• Studio2Shop: from studio photo shoots to fashion articles
• Stringy $E$-functions of canonical toric Fano threefolds and their applications
• weight-importance sparse training in keyword spotting
• Inference, Learning, and Population Size: Projectivity for SRL Models
• Strategic behaviour and indicative price diffusion in Paris Stock Exchange auctions
• Classifying neuromorphic data using a deep learning framework for image classification
• Edge metric dimension of some generalized Petersen graphs
• Dynamic load balancing strategies for hierarchical p-FEM solvers
• Sample Efficient Semantic Segmentation using Rotation Equivariant Convolutional Networks
• Lattice Path Matroids are 3-Colorable
• Duality Respecting Representations and Compatible Complexity Measures for Gammoids
• Lifted Marginal MAP Inference
• The Complexity of Approximately Counting Retractions
• Well-Scaling Procedure for Deciding Gammoid Class-Membership of Matroids
• Logical Explanations for Deep Relational Machines Using Relevance Information
• A Pulmonary Nodule Detection Model Based on Progressive Resolution and Hierarchical Saliency
• Heavy Arc Orientations of Gammoids
• Crowd Counting using Deep Recurrent Spatial-Aware Network
• Semantic Query Language for Temporal Genealogical Trees
• Probabilistic Databases with an Infinite Open-World Assumption
• Multi-modal Egocentric Activity Recognition using Audio-Visual Features
• Synchronization of periodic self-oscillators interacting via memristor-based coupling
• Knowledge Compilation with Continuous Random Variables and its Application in Hybrid Probabilistic Logic Programming
• A new decision theoretic sampling plan for type-I and type-I hybrid censored samples from the exponential distribution
• Some upper bounds on ordinal-valued Ramsey numbers for colourings of pairs
• An isoperimetric inequality for Hamming balls and local expansion in hypercubes
• More on Equienergetic Threshold Graphs
• Mixing of the Square Plaquette Model on a Critical Length Scale
• Adaptation to Easy Data in Prediction with Limited Advice
• Mammography Dual View Mass Correspondence
• Block-Value Symmetries in Probabilistic Graphical Models
• Fast Hermite interpolation and evaluation over finite fields of characteristic two
• Distributed Ledger Technology, Cyber-Physical Systems, and Social Compliance
• A Neural Approach to Language Variety Translation
• PointSIFT: A SIFT-like Network Module for 3D Point Cloud Semantic Segmentation
• On the Tradeoff Between Accuracy and Complexity in Blind Detection of Polar Codes
• Finite big Ramsey degrees in universal structures
• Appearance-Based 3D Gaze Estimation with Personal Calibration
• Introducing the Simulated Flying Shapes and Simulated Planar Manipulator Datasets
• Transparent, Efficient, and Robust Word Embedding Access with WOMBAT
• Gaussian Signalling for Covert Communications
• The relativistic discriminator: a key element missing from standard GAN
• An Algorithmic Framework For Differentially Private Data Analysis on Trusted Processors
• Improving Goal-Oriented Visual Dialog Agents via Advanced Recurrent Nets with Tempered Policy Gradient
• Treating Interference as Noise in Cellular Networks: A Stochastic Geometry Approach
• Fusing First-order Knowledge Compilation and the Lifted Junction Tree Algorithm
• Preventing Unnecessary Groundings in the Lifted Dynamic Junction Tree Algorithm
• Training a Neural Network in a Low-Resource Setting on Automatically Annotated Noisy Data
• Online Label Recovery for Deep Learning-based Communication through Error Correcting Codes
• Understanding the Effectiveness of Lipschitz Constraint in Training of GANs via Gradient Analysis
• Waveform to Single Sinusoid Regression to Estimate the F0 Contour from Noisy Speech Using Recurrent Deep Neural Networks
• Semidefinite Approximations of Invariant Measures for Polynomial Systems
• LeapsAndBounds: A Method for Approximately Optimal Algorithm Configuration
• Role of thermal expansion heterogeneity in the cryogenic rejuvenation of metallic glasses
• Moments of general time dependent branching processes with applications
• A high-performance interactive computing framework for engineering applications
• Path Finding for the Coalition of Co-operative Agents Acting in the Environment with Destructible Obstacles
• Representation Mapping: A Novel Approach to Generate High-Quality Multi-Lingual Emotion Lexicons
• Dynamics of beryllium-7 specific activity in relation to meteorological variables, tropopause height, teleconnection indices and sunspot number
• Ambient Hidden Space of Generative Adversarial Networks
• Rule Algebras for Adhesive Categories
• A Unified Approach to Quantifying Algorithmic Unfairness: Measuring Individual & Group Unfairness via Inequality Indices
• Pragmatic approach to structured data querying via natural language interface
• Hypergraph Lagrangians: Resolving the Frankl-Füredi conjecture
• Efficient Computation of Feedback Control for Constrained Systems
• Deepcode: Feedback Codes via Deep Learning
• Classifying Data with Local Hamiltonians
Like this:
Like Loading...