Evolutionary Algorithms
Evolutionary algorithms (EAs) are population-based metaheuristics, originally inspired by aspects of natural evolution. Modern varieties incorporate a broad mixture of search mechanisms, and tend to blend inspiration from nature with pragmatic engineering concerns; however, all EAs essentially operate by maintaining a population of potential solutions and in some way artificially ‘evolving’ that population over time. Particularly well-known categories of EAs include genetic algorithms (GAs), Genetic Programming (GP), and Evolution Strategies (ES). EAs have proven very successful in practical applications, particularly those requiring solutions to combinatorial problems. EAs are highly flexible and can be configured to address any optimization task, without the requirements for reformulation and/or simplification that would be needed for other techniques. However, this flexibility goes hand in hand with a cost: the tailoring of an EA’s configuration and parameters, so as to provide robust performance for a given class of tasks, is often a complex and time-consuming process. This tailoring process is one of the many ongoing research areas associated with EAs.
To Bayes or Not To Bayes That’s no longer the question!
This paper seeks to provide a thorough account of the ubiquitous nature of the Bayesian paradigm in modern statistics, data science and artificial intelligence. Once maligned, on the one hand by those who philosophically hated the very idea of subjective probability used in prior specification, and on the other hand because of the intractability of the computations needed for Bayesian estimation and inference, the Bayesian school of thought now permeates and pervades virtually all areas of science, applied science, engineering, social science and even liberal arts, often in unsuspected ways. Thanks in part to the availability of powerful computing resources, but also to the literally unavoidable inherent presence of the quintessential building blocks of the Bayesian paradigm in all walks of life, the Bayesian way of handling statistical learning, estimation and inference is not only mainstream but also becoming the most central approach to learning from the data. This paper explores some of the most relevant elements to help to the reader appreciate the pervading power and presence of the Bayesian paradigm in statistics, artificial intelligence and data science, with an emphasis on how the Gospel according to Reverend Thomas Bayes has turned out to be the truly good news, and some cases the amazing saving grace, for all who seek to learn statistically from the data. To further help the reader gain deeper and tangible practical insights into the Bayesian machinery, we point to some computational tools designed for the R Statistical Software Environment to help explore Bayesian statistical learning.
Sacrificing Accuracy for Reduced Computation: Cascaded Inference Based on Softmax Confidence
We study the tradeoff between computational effort and accuracy in a cascade of deep neural networks. During inference, early termination in the cascade is controlled by confidence levels derived directly from the softmax outputs of intermediate classifiers. The advantage of early termination is that classification is performed using less computation, thus adjusting the computational effort to the complexity of the input. Moreover, dynamic modification of confidence thresholds allow one to trade accuracy for computational effort without requiring retraining. Basing of early termination on softmax classifier outputs is justified by experimentation that demonstrates an almost linear relation between confidence levels in intermediate classifiers and accuracy. Our experimentation with architectures based on ResNet obtained the following results. (i) A speedup of 1.5 that sacrifices 1.4% accuracy with respect to the CIFAR-10 test set. (ii) A speedup of 1.19 that sacrifices 0.7% accuracy with respect to the CIFAR-100 test set. (iii) A speedup of 2.16 that sacrifices 1.4% accuracy with respect to the SVHN test set.
Hierarchical clustering with deep Q-learning
The reconstruction and analyzation of high energy particle physics data is just as important as the analyzation of the structure in real world networks. In a previous study it was explored how hierarchical clustering algorithms can be combined with kt cluster algorithms to provide a more generic clusterization method. Building on that, this paper explores the possibilities to involve deep learning in the process of cluster computation, by applying reinforcement learning techniques. The result is a model, that by learning on a modest dataset of 10; 000 nodes during 70 epochs can reach 83; 77% precision in predicting the appropriate clusters.
DeepProbLog: Neural Probabilistic Logic Programming
We introduce DeepProbLog, a probabilistic logic programming language that incorporates deep learning by means of neural predicates. We show how existing inference and learning techniques can be adapted for the new language. Our experiments demonstrate that DeepProbLog supports both symbolic and subsymbolic representations and inference, 1) program induction, 2) probabilistic (logic) programming, and 3) (deep) learning from examples. To the best of our knowledge, this work is the first to propose a framework where general-purpose neural networks and expressive probabilistic-logical modeling and reasoning are integrated in a way that exploits the full expressiveness and strengths of both worlds and can be trained end-to-end based on examples.
Linear tSNE optimization for the Web
The t-distributed Stochastic Neighbor Embedding (tSNE) algorithm has become in recent years one of the most used and insightful techniques for the exploratory data analysis of high-dimensional data. tSNE reveals clusters of high-dimensional data points at different scales while it requires only minimal tuning of its parameters. Despite these advantages, the computational complexity of the algorithm limits its application to relatively small datasets. To address this problem, several evolutions of tSNE have been developed in recent years, mainly focusing on the scalability of the similarity computations between data points. However, these contributions are insufficient to achieve interactive rates when visualizing the evolution of the tSNE embedding for large datasets. In this work, we present a novel approach to the minimization of the tSNE objective function that heavily relies on modern graphics hardware and has linear computational complexity. Our technique does not only beat the state of the art, but can even be executed on the client side in a browser. We propose to approximate the repulsion forces between data points using adaptive-resolution textures that are drawn at every iteration with WebGL. This approximation allows us to reformulate the tSNE minimization problem as a series of tensor operation that are computed with TensorFlow.js, a JavaScript library for scalable tensor computations.
Convolutional neural network compression for natural language processing
Convolutional neural networks are modern models that are very efficient in many classification tasks. They were originally created for image processing purposes. Then some trials were performed to use them in different domains like natural language processing. The artificial intelligence systems (like humanoid robots) are very often based on embedded systems with constraints on memory, power consumption etc. Therefore convolutional neural network because of its memory capacity should be reduced to be mapped to given hardware. In this paper, results are presented of compressing the efficient convolutional neural networks for sentiment analysis. The main steps are quantization and pruning processes. The method responsible for mapping compressed network to FPGA and results of this implementation are presented. The described simulations showed that 5-bit width is enough to have no drop in accuracy from floating point version of the network. Additionally, significant memory footprint reduction was achieved (from 85% up to 93%).
Deep Discriminative Latent Space for Clustering
Clustering is one of the most fundamental tasks in data analysis and machine learning. It is central to many data-driven applications that aim to separate the data into groups with similar patterns. Moreover, clustering is a complex procedure that is affected significantly by the choice of the data representation method. Recent research has demonstrated encouraging clustering results by learning effectively these representations. In most of these works a deep auto-encoder is initially pre-trained to minimize a reconstruction loss, and then jointly optimized with clustering centroids in order to improve the clustering objective. Those works focus mainly on the clustering phase of the procedure, while not utilizing the potential benefit out of the initial phase. In this paper we propose to optimize an auto-encoder with respect to a discriminative pairwise loss function during the auto-encoder pre-training phase. We demonstrate the high accuracy obtained by the proposed method as well as its rapid convergence (e.g. reaching above 92% accuracy on MNIST during the pre-training phase, in less than 50 epochs), even with small networks.
Universality of Deep Convolutional Neural Networks
Deep learning has been widely applied and brought breakthroughs in speech recognition, computer vision, and many other domains. The involved deep neural network architectures and computational issues have been well studied in machine learning. But there lacks a theoretical foundation for understanding the approximation or generalization ability of deep learning methods generated by the network architectures such as deep convolutional neural networks having convolutional structures. Here we show that a deep convolutional neural network (CNN) is universal, meaning that it can be used to approximate any continuous function to an arbitrary accuracy when the depth of the neural network is large enough. This answers an open question in learning theory. Our quantitative estimate, given tightly in terms of the number of free parameters to be computed, verifies the efficiency of deep CNNs in dealing with large dimensional data. Our study also demonstrates the role of convolutions in deep CNNs.
Understanding Generalization and Optimization Performance of Deep CNNs
This work aims to provide understandings on the remarkable success of deep convolutional neural networks (CNNs) by theoretically analyzing their generalization performance and establishing optimization guarantees for gradient descent based training algorithms. Specifically, for a CNN model consisting of
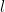
convolutional layers and one fully connected layer, we prove that its generalization error is bounded by

where

denotes freedom degree of the network parameters and

encapsulates architecture parameters including the kernel size

, stride

, pooling size

and parameter magnitude

. To our best knowledge, this is the first generalization bound that only depends on

, tighter than existing ones that all involve an exponential term like

. Besides, we prove that for an arbitrary gradient descent algorithm, the computed approximate stationary point by minimizing empirical risk is also an approximate stationary point to the population risk. This well explains why gradient descent training algorithms usually perform sufficiently well in practice. Furthermore, we prove the one-to-one correspondence and convergence guarantees for the non-degenerate stationary points between the empirical and population risks. It implies that the computed local minimum for the empirical risk is also close to a local minimum for the population risk, thus ensuring the good generalization performance of CNNs.
Clustering by latent dimensions
This paper introduces a new clustering technique, called {\em dimensional clustering}, which clusters each data point by its latent {\em pointwise dimension}, which is a measure of the dimensionality of the data set local to that point. Pointwise dimension is invariant under a broad class of transformations. As a result, dimensional clustering can be usefully applied to a wide range of datasets. Concretely, we present a statistical model which estimates the pointwise dimension of a dataset around the points in that dataset using the distance of each point from its

nearest neighbor. We demonstrate the applicability of our technique to the analysis of dynamical systems, images, and complex human movements.
Designing for Democratization: Introducing Novices to Artificial Intelligence Via Maker Kits
Existing research highlight the myriad of benefits realized when technology is sufficiently democratized and made accessible to non-technical or novice users. However, democratizing complex technologies such as artificial intelligence (AI) remains hard. In this work, we draw on theoretical underpinnings from the democratization of innovation, in exploring the design of maker kits that help introduce novice users to complex technologies. We report on our work designing TJBot: an open source cardboard robot that can be programmed using pre-built AI services. We highlight principles we adopted in this process (approachable design, simplicity, extensibility and accessibility), insights we learned from showing the kit at workshops (66 participants) and how users interacted with the project on GitHub over a 12-month period (Nov 2016 – Nov 2017). We find that the project succeeds in attracting novice users (40\% of users who forked the project are new to GitHub) and a variety of demographics are interested in prototyping use cases such as home automation, task delegation, teaching and learning.
High Quality Bidirectional Generative Adversarial Networks
Generative adversarial networks (GANs) have achieved outstanding success in generating the high quality data. Focusing on the generation process, existing GANs investigate unidirectional mapping from the latent vector to the data. Later, various studies point out that the latent space of GANs is semantically meaningful and can be utilized in advanced data analysis and manipulation. In order to analyze the real data in the latent space of GANs, it is necessary to investigate the inverse generation mapping from the data to the latent vector. To tackle this problem, the bidirectional generative models introduce an encoder to enable the inverse path of generation process. Unfortunately, this effort leads to the degradation of generation quality because the imperfect generator rather interferes the encoder training and vice versa. In this paper, we propose a new inference model that estimates the latent vector from the feature of GAN discriminator. While existing bidirectional models learns the image to latent translation, our algorithm formulates this inference mapping by the feature to latent translation. It is important to note that training of our model is independent of the GAN training. Owing to the attractive nature of this independency, the proposed algorithm can generate the high quality samples identical to those of unidirectional GANs and also reconstruct the original data faithfully. Moreover, our algorithm can be employed to any unidirectional GAN, even the pre-traind GANs.
From statistical inference to a differential learning rule for stochastic neural networks
Stochastic neural networks are a prototypical computational device able to build a probabilistic representation of an ensemble of external stimuli. Building on the relation between inference and learning, we derive a synaptic plasticity rule that relies only on delayed activity correlations, and that shows a number of remarkable features. Our ‘delayed-correlations matching’ (DCM) rule satisfies some basic requirements for biological feasibility: finite and noisy afferent signals, Dale’s principle and asymmetry of synaptic connections, locality of the weight update computations. Nevertheless, the DCM rule is capable of storing a large, extensive number of patterns as attractors in a stochastic recurrent neural network, under general scenarios without requiring any modification: it can deal with correlated patterns, a broad range of architectures (with or without hidden neuronal states), one-shot learning with the palimpsest property, all the while avoiding the proliferation of spurious attractors. When hidden units are present, our learning rule can be employed to construct Boltzman-Machine-like generative models, exploiting the addition of hidden neurons in feature extraction and classification tasks.
NetLSD: Hearing the Shape of a Graph
Comparison among graphs is ubiquitous in graph analytics. However, it is a hard task in terms of the expressiveness of the employed similarity measure and the efficiency of its computation. Ideally, graph comparison should be invariant to the order of nodes and the sizes of compared graphs, adaptive to the scale of graph patterns, and scalable. Unfortunately, these properties have not been addressed together. Graph comparisons still rely on direct approaches, graph kernels, or representation-based methods, which are all inefficient and impractical for large graph collections. In this paper, we propose NetLSD (Network Laplacian Spectral Descriptor), a permutation- and size-invariant, scale-adaptive, and scalably computable graph representation method that allows for straightforward comparisons. NetLSD hears the shape of a graph by extracting a compact signature that inherits the formal properties of the Laplacian spectrum, specifically its heat or wave kernel. To our knowledge, NetLSD is the first expressive graph representation that allows for efficient comparisons of large graphs, our evaluation on a variety of real-world graphs demonstrates that it outperforms previous works in both expressiveness and efficiency.
Measuring Congruence on High Dimensional Time Series
A time series is a sequence of data items; typical examples are videos, stock ticker data, or streams of temperature measurements. Quite some research has been devoted to comparing and indexing simple time series, i.e., time series where the data items are real numbers or integers. However, for many application scenarios, the data items of a time series are not simple, but high-dimensional data points. Motivated by an application scenario dealing with motion gesture recognition, we develop a distance measure (which we call congruence distance) that serves as a model for the approximate congruency of two multi-dimensional time series. This distance measure generalizes the classical notion of congruence from point sets to multi-dimensional time series. We show that, given two input time series

and

, computing the congruence distance of
and
is NP-hard. Afterwards, we present two algorithms that compute an approximation of the congruence distance. We provide theoretical bounds that relate these approximations with the exact congruence distance.
Towards a Theoretical Understanding of Batch Normalization
Normalization techniques such as Batch Normalization have been applied very successfully for training deep neural networks. Yet, despite its apparent empirical benefits, the reasons behind the success of Batch Normalization are mostly hypothetical. We thus aim to provide a more thorough theoretical understanding from an optimization perspective. Our main contribution towards this goal is the identification of various problem instances in the realm of machine learning where, under certain assumptions, Batch Normalization can provably accelerate optimization with gradient-based methods. We thereby turn Batch Normalization from an effective practical heuristic into a provably converging algorithm for these settings. Furthermore, we substantiate our analysis with empirical evidence that suggests the validity of our theoretical results in a broader context.
Strategyproof Linear Regression in High Dimensions
This paper is part of an emerging line of work at the intersection of machine learning and mechanism design, which aims to avoid noise in training data by correctly aligning the incentives of data sources. Specifically, we focus on the ubiquitous problem of linear regression, where strategyproof mechanisms have previously been identified in two dimensions. In our setting, agents have single-peaked preferences and can manipulate only their response variables. Our main contribution is the discovery of a family of group strategyproof linear regression mechanisms in any number of dimensions, which we call generalized resistant hyperplane mechanisms. The game-theoretic properties of these mechanisms — and, in fact, their very existence — are established through a connection to a discrete version of the Ham Sandwich Theorem.
Compact and Computationally Efficient Representation of Deep Neural Networks
Dot product operations between matrices are at the heart of almost any field in science and technology. In many cases, they are the component that requires the highest computational resources during execution. For instance, deep neural networks such as VGG-16 require up to 15 giga-operations in order to perform the dot products present in a single forward pass, which results in significant energy consumption and thus limits their use in resource-limited environments, e.g., on embedded devices or smartphones. One common approach to reduce the complexity of the inference is to prune and quantize the weight matrices of the neural network and to efficiently represent them using sparse matrix data structures. However, since there is no guarantee that the weight matrices exhibit significant sparsity after quantization, the sparse format may be suboptimal. In this paper we present new efficient data structures for representing matrices with low entropy statistics and show that these formats are especially suitable for representing neural networks. Alike sparse matrix data structures, these formats exploit the statistical properties of the data in order to reduce the size and execution complexity. Moreover, we show that the proposed data structures can not only be regarded as a generalization of sparse formats, but are also more energy and time efficient under practically relevant assumptions. Finally, we test the storage requirements and execution performance of the proposed formats on compressed neural networks and compare them to dense and sparse representations. We experimentally show that we are able to attain up to x15 compression ratios, x1.7 speed ups and x20 energy savings when we lossless convert state-of-the-art networks such as AlexNet, VGG-16, ResNet152 and DenseNet into the new data structures.
BRITS: Bidirectional Recurrent Imputation for Time Series
Time series are widely used as signals in many classification/regression tasks. It is ubiquitous that time series contains many missing values. Given multiple correlated time series data, how to fill in missing values and to predict their class labels Existing imputation methods often impose strong assumptions of the underlying data generating process, such as linear dynamics in the state space. In this paper, we propose BRITS, a novel method based on recurrent neural networks for missing value imputation in time series data. Our proposed method directly learns the missing values in a bidirectional recurrent dynamical system, without any specific assumption. The imputed values are treated as variables of RNN graph and can be effectively updated during the backpropagation.BRITS has three advantages: (a) it can handle multiple correlated missing values in time series; (b) it generalizes to time series with nonlinear dynamics underlying; (c) it provides a data-driven imputation procedure and applies to general settings with missing data.We evaluate our model on three real-world datasets, including an air quality dataset, a health-care data, and a localization data for human activity. Experiments show that our model outperforms the state-of-the-art methods in both imputation and classification/regression accuracies.
Adversarial Constraint Learning for Structured Prediction
Constraint-based learning reduces the burden of collecting labels by having users specify general properties of structured outputs, such as constraints imposed by physical laws. We propose a novel framework for simultaneously learning these constraints and using them for supervision, bypassing the difficulty of using domain expertise to manually specify constraints. Learning requires a black-box simulator of structured outputs, which generates valid labels, but need not model their corresponding inputs or the input-label relationship. At training time, we constrain the model to produce outputs that cannot be distinguished from simulated labels by adversarial training. Providing our framework with a small number of labeled inputs gives rise to a new semi-supervised structured prediction model; we evaluate this model on multiple tasks — tracking, pose estimation and time series prediction — and find that it achieves high accuracy with only a small number of labeled inputs. In some cases, no labels are required at all.
Transductive Label Augmentation for Improved Deep Network Learning
A major impediment to the application of deep learning to real-world problems is the scarcity of labeled data. Small training sets are in fact of no use to deep networks as, due to the large number of trainable parameters, they will very likely be subject to overfitting phenomena. On the other hand, the increment of the training set size through further manual or semi-automatic labellings can be costly, if not possible at times. Thus, the standard techniques to address this issue are transfer learning and data augmentation, which consists of applying some sort of ‘transformation’ to existing labeled instances to let the training set grow in size. Although this approach works well in applications such as image classification, where it is relatively simple to design suitable transformation operators, it is not obvious how to apply it in more structured scenarios. Motivated by the observation that in virtually all application domains it is easy to obtain unlabeled data, in this paper we take a different perspective and propose a \emph{label augmentation} approach. We start from a small, curated labeled dataset and let the labels propagate through a larger set of unlabeled data using graph transduction techniques. This allows us to naturally use (second-order) similarity information which resides in the data, a source of information which is typically neglected by standard augmentation techniques. In particular, we show that by using known game theoretic transductive processes we can create larger and accurate enough labeled datasets which use results in better trained neural networks. Preliminary experiments are reported which demonstrate a consistent improvement over standard image classification datasets.
• More Than a Feeling: Learning to Grasp and Regrasp using Vision and Touch
• Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting
• Cost Sharing Games for Energy-Efficient Multi-Hop Broadcast in Wireless Networks
• Reward Constrained Policy Optimization
• Non-bifurcating phylogenetic tree inference via the adaptive LASSO
• Convergence of one-dimensional stationary mean field games with vanishing potential
• Theory and Experiments on Vector Quantized Autoencoders
• Testing Against Independence and a Rényi Information Measure
• Deep Generative Models for Distribution-Preserving Lossy Compression
• A proximal minimization algorithm for structured nonconvex and nonsmooth problems
• A Poisson Gamma Probabilistic Model for Latent Node-group Memberships in Dynamic Networks
• Flexible and accurate inference and learning for deep generative models
• Autoencoding any Data through Kernel Autoencoders
• Online Influence Maximization with Local Observations
• Memory Augmented Self-Play
• A Sequential Embedding Approach for Item Recommendation with Heterogeneous Attributes
• Soft Layer-Specific Multi-Task Summarization with Entailment and Question Generation
• On certain combinatorial expansions of the Legendre-Stirling numbers
• Adversarial Examples in Remote Sensing
• Long-term Large-scale Mapping and Localization Using maplab
• Deeply learning molecular structure-property relationships using graph attention neural network
• Resolving Event Coreference with Supervised Representation Learning and Clustering-Oriented Regularization
• Power domination polynomials of graphs
• Robust and highly adaptable brain-computer interface with convolutional net architecture based on a generative model of neuromagnetic measurements
• The de Bruijn-Erdős theorem from a Hausdorff measure point of view
• GLAC Net: GLocal Attention Cascading Networks for Multi-image Cued Story Generation
• The upper threshold in ballistic annihilation
• Lifelong Learning of Spatiotemporal Representations with Dual-Memory Recurrent Self-Organization
• Lipschitz regularity of deep neural networks: analysis and efficient estimation
• Central Limit Theorems and Minimum-Contrast Estimators for Linear Stochastic Evolution Equations
• The Gaussian Multi-Bubble Conjecture
• Denoising Distant Supervision for Relation Extraction via Instance-Level Adversarial Training
• Discrete flow posteriors for variational inference in discrete dynamical systems
• The unavoidable arrangements of pseudocircles
• Temporal Event Knowledge Acquisition via Identifying Narratives
• Fusion of Methods Based on Minutiae, Ridges and Pores for Robust Fingerprint Recognition
• Note on AR(1)-characterisation of stationary processes and model fitting
• Fast Random Integer Generation in an Interval
• Implicit ridge regularization provided by the minimum-norm least squares estimator when $n\ll p$
• Face hallucination using cascaded super-resolution and identity priors
• Analysis of association football playing styles: an innovative method to cluster networks
• Two types of permutation polynomials with special forms
• Regularity of the vanishing ideal over a bipartite nested ear decomposition
• Attractiveness of Brownian queues in tandem
• Deep Anomaly Detection Using Geometric Transformations
• Online Multi-Object Tracking with Historical Appearance Matching and Scene Adaptive Detection Filtering
• Dirichlet-based Gaussian Processes for Large-scale Calibrated Classification
• Combinatorial Auctions with Endowment Effect
• Quantized Repetitions of the Cuprate Pseudogap Line
• On the number of symbols that forces a transversal
• Tangramob: an agent-based simulation framework for validating urban smart mobility solutions
• Brownian Motions on Metric Graphs with Non-Local Boundary Conditions II: Construction
• Parallel Louvain Community Detection Optimized for GPUs
• Randomized Local Search Heuristics for Submodular Maximization and Covering Problems: Benefits of Heavy-tailed Mutation Operators
• Brownian Polymers in Poissonian Environment: a survey
• Adaptive Network Sparsification via Dependent Variational Beta-Bernoulli Dropout
• Using spike train distances to identify the most discriminative neuronal subpopulation
• Model averaging for robust extrapolation in evidence synthesis
• Block-optimized Variable Bit Rate Neural Image Compression
• Importance Weighted Transfer of Samples in Reinforcement Learning
• High Probability Frequency Moment Sketches
• Training Medical Image Analysis Systems like Radiologists
• Image Distortion Detection using Convolutional Neural Network
• Investigating Label Noise Sensitivity of Convolutional Neural Networks for Fine Grained Audio Signal Labelling
• Less is More: Unified Model for Unsupervised Multi-Domain Image-to-Image Translation
• Non-Gaussianity of van Hove Function and Dynamic Heterogeneity Length Scale
• Equilibrium Restrictions and Approximate Models: Pricing Macroeconomic Risk
• Pairwise likelihood estimation of latent autoregressive count models
• Versatile Auxiliary Regressor with Generative Adversarial network (VAR+GAN)
• Parallel Weight Consolidation: A Brain Segmentation Case Study
• r-instance Learning for Missing People Tweets Identification
• One family, six distributions — A flexible model for insurance claim severity
• A non-invertible cancelable fingerprint template generation based on ridge feature transformation
• A Pragmatic AI Approach to Creating Artistic Visual Variations by Neural Style Transfer
• Inducing Grammars with and for Neural Machine Translation
• A Stochastic Decoder for Neural Machine Translation
• Nonlinear Simplex Regression Models
• Approximating Real-Time Recurrent Learning with Random Kronecker Factors
• Space-Distribution PDEs for Path Independent Additive Functionals of McKean-Vlasov SDEs
• Approximation of Fractional Order Conflict-Controlled Systems
• Bayesian Learning with Wasserstein Barycenters
• A family of graphs that are determined by their normalized Laplacian spectra
• Sigsoftmax: Reanalysis of the Softmax Bottleneck
• The WST-decomposition for partial matrices
• UG18 at SemEval-2018 Task 1: Generating Additional Training Data for Predicting Emotion Intensity in Spanish
• Flexible shrinkage in high-dimensional Bayesian spatial autoregressive models
• Local Rule-Based Explanations of Black Box Decision Systems
• Variational approach to Euclidean QFT
• Real-valued parametric conditioning of an RNN for interactive sound synthesis
• Fast Dynamic Routing Based on Weighted Kernel Density Estimation
• Visual Relationship Detection Based on Guided Proposals and Semantic Knowledge Distillation
• Sequential sampling for optimal weighted least squares approximations in hierarchical spaces
• Classification of Globally Colorized Categories of Partitions
• Interactive Text2Pickup Network for Natural Language based Human-Robot Collaboration
• Uniqueness of the nonlinear Schrödinger Equation driven by jump processes
• On estimation of nonsmooth functionals of sparse normal means
• Deep CT to MR Synthesis using Paired and Unpaired Data
• Phase portrait control for 1D monostable and bistable reaction-diffusion equations
• Keep and Learn: Continual Learning by Constraining the Latent Space for Knowledge Preservation in Neural Networks
• Software-Defined Multi-Cloud Computing: A Vision, Architectural Elements, and Future Directions
• Object-Level Representation Learning for Few-Shot Image Classification
• Intelligent Knowledge Tracing: More Like a Real Learning Process of a Student
• Improving the Resolution of CNN Feature Maps Efficiently with Multisampling
• Learning Instance-Aware Object Detection Using Determinantal Point Processes
• Dual Policy Iteration
• A note on block-and-bridge preserving maximum common subgraph algorithms for outerplanar graphs
• Conditions for the emergence of bulk Fermi arc in disordered Dirac fermions system
• High-dimensional statistical inferences with over-identification: confidence set estimation and specification test
• Deep Adversarial Context-Aware Landmark Detection for Ultrasound Imaging
• De-noising by thresholding operator adapted wavelets
• A neural network trained to predict future video frames mimics critical properties of biological neuronal responses and perception
• How polarization can provide an increase in content dissemination amongst the highly ranked influencers
• Perceive Your Users in Depth: Learning Universal User Representations from Multiple E-commerce Tasks
• A Neurobiological Cross-domain Evaluation Metric for Predictive Coding Networks
• RetainVis: Visual Analytics with Interpretable and Interactive Recurrent Neural Networks on Electronic Medical Records
• Bernstein’s inequality for general Markov chains
• Multi-region segmentation of bladder cancer structures in MRI with progressive dilated convolutional networks
• Distributed Treewidth Computation
• A fast minimal solver for absolute camera pose with unknown focal length and radial distortion from four planar points
• Synergistic Reconstruction and Synthesis via Generative Adversarial Networks for Accelerated Multi-Contrast MRI
• Study of Unique-Word Based GFDM Transmission Systems
• Toward Super-Polynomial Size Lower Bounds for Depth-Two Threshold Circuits
• Converse Theorems for the DMC with Mismatched Decoding
Like this:
Like Loading...