Text-mining and ontologies: new approaches to knowledge discovery of microbial diversity
Microbiology research has access to a very large amount of public information on the habitats of microorganisms. Many areas of microbiology research uses this information, primarily in biodiversity studies. However the habitat information is expressed in unstructured natural language form, which hinders its exploitation at large-scale. It is very common for similar habitats to be described by different terms, which makes them hard to compare automatically, e.g. intestine and gut. The use of a common reference to standardize these habitat descriptions as claimed by (Ivana et al., 2010) is a necessity. We propose the ontology called OntoBiotope that we have been developing since 2010. The OntoBiotope ontology is in a formal machine-readable representation that enables indexing of information as well as conceptualization and reasoning.
Bivariate Causal Discovery and its Applications to Gene Expression and Imaging Data Analysis
The mainstream of research in genetics, epigenetics and imaging data analysis focuses on statistical association or exploring statistical dependence between variables. Despite their significant progresses in genetic research, understanding the etiology and mechanism of complex phenotypes remains elusive. Using association analysis as a major analytical platform for the complex data analysis is a key issue that hampers the theoretic development of genomic science and its application in practice. Causal inference is an essential component for the discovery of mechanical relationships among complex phenotypes. Many researchers suggest making the transition from association to causation. Despite its fundamental role in science, engineering and biomedicine, the traditional methods for causal inference require at least three variables. However, quantitative genetic analysis such as QTL, eQTL, mQTL, and genomic-imaging data analysis requires exploring the causal relationships between two variables. This paper will focus on bivariate causal discovery. We will introduce independence of cause and mechanism (ICM) as a basic principle for causal inference, algorithmic information theory and additive noise model (ANM) as major tools for bivariate causal discovery. Large-scale simulations will be performed to evaluate the feasibility of the ANM for bivariate causal discovery. To further evaluate their performance for causal inference, the ANM will be applied to the construction of gene regulatory networks. Also, the ANM will be applied to trait-imaging data analysis to illustrate three scenarios: presence of both causation and association, presence of association while absence of causation, and presence of causation, while lack of association between two variables.
Graphlets versus node2vec and struc2vec in the task of network alignment
Network embedding aims to represent each node in a network as a low-dimensional feature vector that summarizes the given node’s (extended) network neighborhood. The nodes’ feature vectors can then be used in various downstream machine learning tasks. Recently, many embedding methods that automatically learn the features of nodes have emerged, such as node2vec and struc2vec, which have been used in tasks such as node classification, link prediction, and node clustering, mainly in the social network domain. There are also other embedding methods that explicitly look at the connections between nodes, i.e., the nodes’ network neighborhoods, such as graphlets. Graphlets have been used in many tasks such as network comparison, link prediction, and network clustering, mainly in the computational biology domain. Even though the two types of embedding methods (node2vec/struct2vec versus graphlets) have a similar goal — to represent nodes as features vectors, no comparisons have been made between them, possibly because they have originated in the different domains. Therefore, in this study, we compare graphlets to node2vec and struc2vec, and we do so in the task of network alignment. In evaluations on synthetic and real-world biological networks, we find that graphlets are both more accurate and faster than node2vec and struc2vec.
Distributed Deep Forest and its Application to Automatic Detection of Cash-out Fraud
Internet companies are facing the need of handling large scale machine learning applications in a daily basis, and distributed system which can handle extra-large scale tasks is needed. Deep forest is a recently proposed deep learning framework which uses tree ensembles as its building blocks and it has achieved highly competitive results on various domains of tasks. However, it has not been tested on extremely large scale tasks. In this work, based on our parameter server system and platform of artificial intelligence, we developed the distributed version of deep forest with an easy-to-use GUI. To the best of our knowledge, this is the first implementation of distributed deep forest. To meet the need of real-world tasks, many improvements are introduced to the original deep forest model. We tested the deep forest model on an extra-large scale task, i.e., automatic detection of cash-out fraud, with more than 100 millions of training samples. Experimental results showed that the deep forest model has the best performance according to the evaluation metrics from different perspectives even with very little effort for parameter tuning. This model can block fraud transactions in a large amount of money \footnote{detail is business confidential} each day. Even compared with the best deployed model, deep forest model can additionally bring into a significant decrease of economic loss.
Adaptive Selection of Deep Learning Models on Embedded Systems
The recent ground-breaking advances in deep learning networks ( DNNs ) make them attractive for embedded systems. However, it can take a long time for DNNs to make an inference on resource-limited embedded devices. Offloading the computation into the cloud is often infeasible due to privacy concerns, high latency, or the lack of connectivity. As such, there is a critical need to find a way to effectively execute the DNN models locally on the devices. This paper presents an adaptive scheme to determine which DNN model to use for a given input, by considering the desired accuracy and inference time. Our approach employs machine learning to develop a predictive model to quickly select a pre-trained DNN to use for a given input and the optimization constraint. We achieve this by first training off-line a predictive model, and then use the learnt model to select a DNN model to use for new, unseen inputs. We apply our approach to the image classification task and evaluate it on a Jetson TX2 embedded deep learning platform using the ImageNet ILSVRC 2012 validation dataset. We consider a range of influential DNN models. Experimental results show that our approach achieves a 7.52% improvement in inference accuracy, and a 1.8x reduction in inference time over the most-capable single DNN model.
Argument Harvesting Using Chatbots
Much research in computational argumentation assumes that arguments and counterarguments can be obtained in some way. Yet, to improve and apply models of argument, we need methods for acquiring them. Current approaches include argument mining from text, hand coding of arguments by researchers, or generating arguments from knowledge bases. In this paper, we propose a new approach, which we call argument harvesting, that uses a chatbot to enter into a dialogue with a participant to get arguments and counterarguments from him or her. Because it is automated, the chatbot can be used repeatedly in many dialogues, and thereby it can generate a large corpus. We describe the architecture of the chatbot, provide methods for managing a corpus of arguments and counterarguments, and an evaluation of our approach in a case study concerning attitudes of women to participation in sport.
PALM: An Incremental Construction of Hyperplanes for Data Stream Regression
Data stream has been the underlying challenge in the age of big data because it calls for real-time data processing with the absence of a retraining process and/or an iterative learning approach. In realm of fuzzy system community, data stream is handled by algorithmic development of self-adaptive neurofuzzy systems (SANFS) characterized by the single-pass learning mode and the open structure property which enables effective handling of fast and rapidly changing natures of data streams. The underlying bottleneck of SANFSs lies in its design principle which involves a high number of free parameters (rule premise and rule consequent) to be adapted in the training process. This figure can even double in the case of type-2 fuzzy system. In this work, a novel SANFS, namely parsimonious learning machine (PALM), is proposed. PALM features utilization of a new type of fuzzy rule based on the concept of hyperplane clustering which significantly reduces the number of network parameters because it has no rule premise parameters. PALM is proposed in both type-1 and type-2 fuzzy systems where all of which characterize a fully dynamic rule-based system. That is, it is capable of automatically generating, merging and tuning the hyperplane based fuzzy rule in the single pass manner. The efficacy of PALM has been evaluated through numerical study with six real-world and synthetic data streams from public database and our own real-world project of autonomous vehicles. The proposed model showcases significant improvements in terms of computational complexity and number of required parameters against several renowned SANFSs, while attaining comparable and often better predictive accuracy.
State Gradients for RNN Memory Analysis
We present a framework for analyzing what the state in RNNs remembers from its input embeddings. Our approach is inspired by backpropagation, in the sense that we compute the gradients of the states with respect to the input embeddings. The gradient matrix is decomposed with Singular Value Decomposition to analyze which directions in the embedding space are best transferred to the hidden state space, characterized by the largest singular values. We apply our approach to LSTM language models and investigate to what extent and for how long certain classes of words are remembered on average for a certain corpus. Additionally, the extent to which a specific property or relationship is remembered by the RNN can be tracked by comparing a vector characterizing that property with the direction(s) in embedding space that are best preserved in hidden state space.
Scripting Relational Database Engine Using Transducer
We allow database user to script a parallel relational database engine with a procedural language. Procedural language code is executed as a user defined relational query operator called transducer. Transducer is tightly integrated with relation engine, including query optimizer, query executor and can be executed in parallel like other query operators. With transducer, we can efficiently execute queries that are very difficult to express in SQL. As example, we show how to run time series and graph queries, etc, within a parallel relational database.
An $O(N)$ Sorting Algorithm: Machine Learning Sorting
We propose an
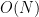
sorting algorithm based on Machine Learning method, which shows a huge potential for sorting big data. This sorting algorithm can be applied to parallel sorting and is suitable for GPU or TPU acceleration. Furthermore, we apply this algorithm to sparse hash table.
Iteratively Trained Interactive Segmentation
Deep learning requires large amounts of training data to be effective. For the task of object segmentation, manually labeling data is very expensive, and hence interactive methods are needed. Following recent approaches, we develop an interactive object segmentation system which uses user input in the form of clicks as the input to a convolutional network. While previous methods use heuristic click sampling strategies to emulate user clicks during training, we propose a new iterative training strategy. During training, we iteratively add clicks based on the errors of the currently predicted segmentation. We show that our iterative training strategy together with additional improvements to the network architecture results in improved results over the state-of-the-art.
Novel Deep Learning Model for Traffic Sign Detection Using Capsule Networks
Convolutional neural networks are the most widely used deep learning algorithms for traffic signal classification till date but they fail to capture pose, view, orientation of the images because of the intrinsic inability of max pooling layer.This paper proposes a novel method for Traffic sign detection using deep learning architecture called capsule networks that achieves outstanding performance on the German traffic sign dataset.Capsule network consists of capsules which are a group of neurons representing the instantiating parameters of an object like the pose and orientation by using the dynamic routing and route by agreement algorithms.unlike the previous approaches of manual feature extraction,multiple deep neural networks with many parameters,our method eliminates the manual effort and provides resistance to the spatial variances.CNNs can be fooled easily using various adversary attacks and capsule networks can overcome such attacks from the intruders and can offer more reliability in traffic sign detection for autonomous vehicles.Capsule network have achieved the state-of-the-art accuracy of 97.6% on German Traffic Sign Recognition Benchmark dataset (GTSRB).
Cross-lingual Document Retrieval using Regularized Wasserstein Distance
Many information retrieval algorithms rely on the notion of a good distance that allows to efficiently compare objects of different nature. Recently, a new promising metric called Word Mover’s Distance was proposed to measure the divergence between text passages. In this paper, we demonstrate that this metric can be extended to incorporate term-weighting schemes and provide more accurate and computationally efficient matching between documents using entropic regularization. We evaluate the benefits of both extensions in the task of cross-lingual document retrieval (CLDR). Our experimental results on eight CLDR problems suggest that the proposed methods achieve remarkable improvements in terms of Mean Reciprocal Rank compared to several baselines.
• A Performance Evaluation of Convolutional Neural Networks for Face Anti Spoofing
• The Power of Genetic Algorithms: what remains of the pMSSM
• Nonparametric optimization of short-term confidence bands for wind power generation
• The thickness of Schubert cells as incidence structures
• Dark Matter Model or Mass, but Not Both: Assessing Near-Future Direct Searches with Benchmark-free Forecasting
• A 1.5-Approximation for Path TSP
• Boosting up Scene Text Detectors with Guided CNN
• Compactness and Density Estimates for Weighted Fractional Heat Semigroups
• Unsupervised Deep Representations for Learning Audience Facial Behaviors
• Towards integrable structure in 3d Ising model
• Hypermatrix Representation of Unbalanced Power Distribution Systems
• Neural Best-Buddies: Sparse Cross-Domain Correspondence
• Deep Representation Learning for Domain Adaptation of Semantic Image Segmentation
• Towards Budget-Driven Hardware Optimization for Deep Convolutional Neural Networks using Stochastic Computing
• Precise Limit Theorems for Lacunary Series
• Beating Fredman-Komlós for perfect $k$-hashing
• Training Recurrent Neural Networks via Dynamical Trajectory-Based Optimization
• Partial Parking Functions
• Nearly-Optimal Mergesorts: Fast, Practical Sorting Methods That Optimally Adapt to Existing Runs
• Computational Social Choice Meets Databases
• On the Classification of SSVEP-Based Dry-EEG Signals via Convolutional Neural Networks
• Extracting structured dynamical systems using sparse optimization with very few samples
• Intertopic Distances as Leading Indicators
• Erasure Correction for Noisy Radio Networks
• Achieving Super-Resolution with Redundant Sensing
• Unifying Data, Model and Hybrid Parallelism in Deep Learning via Tensor Tiling
• Joint Embedding of Words and Labels for Text Classification
• The Cavender-Farris-Neyman Model with a Molecular Clock
• Density Forecasts in Panel Data Models: A Semiparametric Bayesian Perspective
• The Hidden Subgroup Problem and Post-quantum Group-based Cryptography
• On the Rainbow Turán number of paths
• On the tightest interval-valued state estimator for linear systems
• Deep Neural Machine Translation with Weakly-Recurrent Units
• Analysis of a Mode Clustering Diagram
• On the approximation guarantee of obviously strategyproof mechanisms
• Sentiment-driven Community Profiling and Detection on Social Media
• An Unsupervised Clustering-Based Short-Term Solar Forecasting Methodology Using Multi-Model Machine Learning Blending
• Avoiding long Berge cycles
• The Kashaev equation and related recurrences
• Learning to Grasp Without Seeing
• Robust Model-Based Clustering of Voting Records
• Extremal Spectral Gaps for Periodic Schrödinger Operators
• Behavior Analysis of NLI Models: Uncovering the Influence of Three Factors on Robustness
• ProCal: A Low-Cost and Programmable Calibration Tool for IoT Devices
• An Adaptive Population Size Differential Evolution with Novel Mutation Strategy for Constrained Optimization
• Deep RNNs Encode Soft Hierarchical Syntax
• Infinite Limits of Finite-Dimensional Permutation Structures, and their Automorphism Groups: Between Model Theory and Combinatorics
• Human-Machine Collaborative Optimization via Apprenticeship Scheduling
• Retinal Vessel Segmentation Based on Conditional Deep Convolutional Generative Adversarial Networks
• Efficiency in Micro-Behaviors and FL Bias
• Cutoff for the Swendsen-Wang dynamics on the lattice
• Trajectory tracking with an aggregation of domestic hot water heaters: Combining model-based and model-free control in a commercial deployment
• Neural Machine Translation for Bilingually Scarce Scenarios: A Deep Multi-task Learning Approach
• Stochastic Approximation for Risk-aware Markov Decision Processes
• Just-in-Time Reconstruction: Inpainting Sparse Maps using Single View Depth Predictors as Priors
• A Robust Circle-criterion Observer-based Estimator for Discrete-time Nonlinear Systems in the Presence of Sensor Attacks and Measurement Noise
• On Fundamental Operations for Multimodular Functions
• Convex Programming Based Spectral Clustering
• Reciprocal Attention Fusion for Visual Question Answering
• Stingray Detection of Aerial Images Using Augmented Training Images Generated by A Conditional Generative Model
• OpSets: Sequential Specifications for Replicated Datatypes (Extended Version)
• FCFS Parallel Service Systems and Matching Models
• Neural Open Information Extraction
• Measuring heterogeneity in urban expansion via spatial entropy
• Leveraging Grammar and Reinforcement Learning for Neural Program Synthesis
• The risk of sub-optimal use of Open Source NLP Software: UKB is inadvertently state-of-the-art in knowledge-based WSD
• Field Trial of Alien Wavelengths on GARR Optical Network
• An implicit sweeping process approach to quasistatic evolution variational inequalities
• Piecewise classifier mappings: Learning fine-grained learners for novel categories with few examples
• A family of four-variable expanders with quadratic growth
• A Tube-based Robust MPC for a Fixed-wing UAV: an Application for Precision Farming
• Cooperative Control of Heterogeneous Connected Vehicles with Directed Acyclic Interactions
• Maximum entropy approach to link prediction in bipartite networks
• Blockage Modeling for Inter-layer UAVs Communications in Urban Environments
• Weakly and Semi Supervised Human Body Part Parsing via Pose-Guided Knowledge Transfer
• Localization transition for light scattering by atoms in an external magnetic field
• Branching-stable point measures and processes
• Towards scalable pattern-based optimization for dense linear algebra
• Channel Model in Urban Environment for Unmanned Aerial Vehicle Communications
• Quantitative Projection Coverage for Testing ML-enabled Autonomous Systems
• Multi-version Coding with Side Information
• Asymptotics of principal evaluations of Schubert polynomials for layered permutations
• Random Conductance Models with Stable-like Jumps I: Quenched Invariance Principle
• Rate optimal estimation of quadratic functionals in inverse problems with partially unknown operator and application to testing problems
• Taking the edge off quantization: projected back projection in dithered compressive sensing
• Response of solar irradiance to sunspot area variations
• Distributed Path Selection Strategies for Integrated Access and Backhaul at mmWaves
• Trajectory Design for Distributed Estimation in UAV Enabled Wireless Sensor Network
• On the stationary distribution of the block counting process for population models with mutation and selection
• On the Parameterized Complexity of Graph Modification to First-Order Logic Properties
• Revisiting the Hamiltonian Theme in the Square of a Block: The General Case
• Exploiting Images for Video Recognition with Hierarchical Generative Adversarial Networks
• Weakly Supervised Domain-Specific Color Naming Based on Attention
• Approximating the position of a hidden agent in a graph
• False Discovery Rate Control Under Reduced Precision Computation
• A Sensorimotor Perspective on Grounding the Semantic of Simple Visual Features
• Decision problems for Clark-congruential languages
• Coverage Probability Analysis of UAV Cellular Networks in Urban Environments
• PAD-Net: Multi-Tasks Guided Prediction-and-Distillation Network for Simultaneous Depth Estimation and Scene Parsing
• An Integrated Market for Electricity and Natural Gas Systems with Stochastic Power Producers
• Deep Hierarchical Reinforcement Learning Algorithm in Partially Observable Markov Decision Processes
• Covariate-Adjusted Tensor Classification in High-Dimensions
• Capturing Complementarity in Set Functions by Going Beyond Submodularity/Subadditivity
• Peacock: Probe-Based Scheduling of Jobs by Rotating Between Elastic Queues
• Bootstrapping Multilingual Intent Models via Machine Translation for Dialog Automation
• Sobolev spaces and calculus of variations on fractals
• Network-based indicators of Bitcoin bubbles
• On a strong form of propagation of chaos for McKean-Vlasov equations
• Non-Stationary Texture Synthesis by Adversarial Expansion
• Interactive Reinforcement Learning with Dynamic Reuse of Prior Knowledge from Human/Agent’s Demonstration
• Integral-Type Event-Triggered Receding Horizon Control of Nonlinear Systems with Additive Disturbance
• Cell-free Massive MIMO Networks: Optimal Power Control against Active Eavesdropping
• Augmented Skeleton Space Transfer for Depth-based Hand Pose Estimation
• Dynamical Liouville
• Examining Gender and Race Bias in Two Hundred Sentiment Analysis Systems
• Social networks and geography: a view from the periphery
Like this:
Like Loading...