Incorporating Privileged Information to Unsupervised Anomaly Detection
We introduce a new unsupervised anomaly detection ensemble called SPI which can harness privileged information – data available only for training examples but not for (future) test examples. Our ideas build on the Learning Using Privileged Information (LUPI) paradigm pioneered by Vapnik et al. [19,17], which we extend to unsupervised learning and in particular to anomaly detection. SPI (for Spotting anomalies with Privileged Information) constructs a number of frames/fragments of knowledge (i.e., density estimates) in the privileged space and transfers them to the anomaly scoring space through ‘imitation’ functions that use only the partial information available for test examples. Our generalization of the LUPI paradigm to unsupervised anomaly detection shepherds the field in several key directions, including (i) domain knowledge-augmented detection using expert annotations as PI, (ii) fast detection using computationally-demanding data as PI, and (iii) early detection using ‘historical future’ data as PI. Through extensive experiments on simulated and real datasets, we show that augmenting privileged information to anomaly detection significantly improves detection performance. We also demonstrate the promise of SPI under all three settings (i-iii); with PI capturing expert knowledge, computationally expensive features, and future data on three real world detection tasks.
Clustering With Pairwise Relationships: A Generative Approach
Semi-supervised learning (SSL) has become important in current data analysis applications, where the amount of unlabeled data is growing exponentially and user input remains limited by logistics and expense. Constrained clustering, as a subclass of SSL, makes use of user input in the form of relationships between data points (e.g., pairs of data points belonging to the same class or different classes) and can remarkably improve the performance of unsupervised clustering in order to reflect user-defined knowledge of the relationships between particular data points. Existing algorithms incorporate such user input, heuristically, as either hard constraints or soft penalties, which are separate from any generative or statistical aspect of the clustering model; this results in formulations that are suboptimal and not sufficiently general. In this paper, we propose a principled, generative approach to probabilistically model, without ad hoc penalties, the joint distribution given by user-defined pairwise relations. The proposed model accounts for general underlying distributions without assuming a specific form and relies on expectation-maximization for model fitting. For distributions in a standard form, the proposed approach results in a closed-form solution for updated parameters.
Examining the Use of Neural Networks for Feature Extraction: A Comparative Analysis using Deep Learning, Support Vector Machines, and K-Nearest Neighbor Classifiers
Neural networks in many varieties are touted as very powerful machine learning tools because of their ability to distill large amounts of information from different forms of data, extracting complex features and enabling powerful classification abilities. In this study, we use neural networks to extract features from both images and numeric data and use these extracted features as inputs for other machine learning models, namely support vector machines (SVMs) and k-nearest neighbor classifiers (KNNs), in order to see if neural-network-extracted features enhance the capabilities of these models. We tested 7 different neural network architectures in this manner, 4 for images and 3 for numeric data, training each for varying lengths of time and then comparing the results of the neural network independently to those of an SVM and KNN on the data, and finally comparing these results to models of SVM and KNN trained using features extracted via the neural network architecture. This process was repeated on 3 different image datasets and 2 different numeric datasets. The results show that, in many cases, the features extracted using the neural network significantly improve the capabilities of SVMs and KNNs compared to running these algorithms on the raw features, and in some cases also surpass the performance of the neural network alone. This in turn suggests that it may be a reasonable practice to use neural networks as a means to extract features for classification by other machine learning models for some datasets.
Semi-Orthogonal Non-Negative Matrix Factorization
Non-negative Matrix Factorization (NMF) is a popular clustering and dimension reduction method by decomposing a non-negative matrix into the product of two lower dimension matrices composed of basis vectors. In this paper, we propose a semi-orthogonal NMF method that enforces one of the matrices to be orthogonal with mixed signs, thereby guarantees the rank of the factorization. Our method preserves strict orthogonality by implementing the Cayley transformation to force the solution path to be exactly on the Stiefel manifold, as opposed to the approximated orthogonality solutions in existing literature. We apply a line search update scheme along with an SVD-based initialization which produces a rapid convergence of the algorithm compared to other existing approaches. In addition, we present formulations of our method to incorporate both continuous and binary design matrices. Through various simulation studies, we show that our model has an advantage over other NMF variations regarding the accuracy of the factorization, rate of convergence, and the degree of orthogonality while being computationally competitive. We also apply our method to a text-mining data on classifying triage notes, and show the effectiveness of our model in reducing classification error compared to the conventional bag-of-words model and other alternative matrix factorization approaches.
Matrix Completion with Nonuniform Sampling: Theories and Methods
Prevalent matrix completion theories reply on an assumption that the locations of missing data are distributed independently and randomly (i.e., uniform sampling). Nevertheless, the reason for an observation being missing often depends on the unseen observations themselves, and thus the locations of the missing data in practice usually occur in a correlated fashion (i.e., nonuniform sampling) rather than independently. To break through the limits of uniform sampling, we introduce in this work a new hypothesis called isomeric condition, which is provably weaker than the assumption of uniform sampling. Equipped with this new tool, we prove a collection of theorems for missing data recovery as well as matrix completion. In particular, we prove that the exact solutions that identify the target matrix are included as critical points by the commonly used bilinear programs. Even more, when an extra condition called relative well-conditionedness is obeyed as well, we prove that the local optimality of the exact solutions is guaranteed in a deterministic fashion. Among other things, we study in detail a Schatten quasi-norm induced method termed isomeric dictionary pursuit (IsoDP), and we show that IsoDP exhibits some distinct behaviors absent in the traditional bilinear programs.
Implementation of Stochastic Quasi-Newton’s Method in PyTorch
In this paper, we implement the Stochastic Damped LBFGS (SdLBFGS) for stochastic non-convex optimization. We make two important modifications to the original SdLBFGS algorithm. First, by initializing the Hessian at each step using an identity matrix, the algorithm converges better than original algorithm. Second, by performing direction normalization we could gain stable optimization procedure without line search. Experiments on minimizing a 2D non-convex function shows that our improved algorithm converges better than original algorithm, and experiments on the CIFAR10 and MNIST datasets show that our improved algorithm works stably and gives comparable or even better testing accuracies than first order optimizers SGD, Adagrad, and second order optimizers LBFGS in PyTorch.
Multimodal Machine Translation with Reinforcement Learning
Multimodal machine translation is one of the applications that integrates computer vision and language processing. It is a unique task given that in the field of machine translation, many state-of-the-arts algorithms still only employ textual information. In this work, we explore the effectiveness of reinforcement learning in multimodal machine translation. We present a novel algorithm based on the Advantage Actor-Critic (A2C) algorithm that specifically cater to the multimodal machine translation task of the EMNLP 2018 Third Conference on Machine Translation (WMT18). We experiment our proposed algorithm on the Multi30K multilingual English-German image description dataset and the Flickr30K image entity dataset. Our model takes two channels of inputs, image and text, uses translation evaluation metrics as training rewards, and achieves better results than supervised learning MLE baseline models. Furthermore, we discuss the prospects and limitations of using reinforcement learning for machine translation. Our experiment results suggest a promising reinforcement learning solution to the general task of multimodal sequence to sequence learning.
Weakly-supervised Contextualization of Knowledge Graph Facts
Knowledge graphs (KGs) model facts about the world, they consist of nodes (entities such as companies and people) that are connected by edges (relations such as founderOf). Facts encoded in KGs are frequently used by search applications to augment result pages. When presenting a KG fact to the user, providing other facts that are pertinent to that main fact can enrich the user experience and support exploratory information needs. KG fact contextualization is the task of augmenting a given KG fact with additional and useful KG facts. The task is challenging because of the large size of KGs, discovering other relevant facts even in a small neighborhood of the given fact results in an enormous amount of candidates. We introduce a neural fact contextualization method (NFCM) to address the KG fact contextualization task. NFCM first generates a set of candidate facts in the neighborhood of a given fact and then ranks the candidate facts using a supervised learning to rank model. The ranking model combines features that we automatically learn from data and that represent the query-candidate facts with a set of hand-crafted features we devised or adjusted for this task. In order to obtain the annotations required to train the learning to rank model at scale, we generate training data automatically using distant supervision on a large entity-tagged text corpus. We show that ranking functions learned on this data are effective at contextualizing KG facts. Evaluation using human assessors shows that it significantly outperforms several competitive baselines.
A Graph-to-Sequence Model for AMR-to-Text Generation
The problem of AMR-to-text generation is to recover a text representing the same meaning as an input AMR graph. The current state-of-the-art method uses a sequence-to-sequence model, leveraging LSTM for encoding a linearized AMR structure. Although being able to model non-local semantic information, a sequence LSTM can lose information from the AMR graph structure, and thus faces challenges with large graphs, which result in long sequences. We introduce a neural graph-to-sequence model, using a novel LSTM structure for directly encoding graph-level semantics. On a standard benchmark, our model shows superior results to existing methods in the literature.
Complete Analysis of a Random Forest Model
Random forests have become an important tool for improving accuracy in regression problems since their popularization by (Breiman, 2001) and others. In this paper, we revisit a random forest model originally proposed by (Breiman, 2004) and later studied by (Biau, 2012), where a feature is selected at random and the split occurs at the midpoint of the block containing the chosen feature. If the regression function is sparse and depends only on a small, unknown subset of
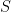
out of
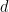
features, we show that given
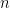
observations, this random forest model outputs a predictor that has a mean-squared prediction error of order

. When
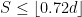
, this rate is better than the minimax optimal rate

for
-dimensional, Lipschitz function classes. As a consequence of our analysis, we show that the variance of the forest decays with the depth of the tree at a rate that is independent of the ambient dimension, even when the trees are fully grown. In particular, if

(resp.

) is the average (resp. maximum) number of observations per leaf node, we show that the variance of this forest is
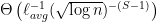
, which for the case of

, is similar in form to the lower bound

of (Lin and Jeon, 2006) for any random forest model with a nonadaptive splitting scheme. We also show that the bias is tight for any linear model with nonzero parameter vector. Thus, we completely characterize the fundamental limits of this random forest model. Our new analysis also implies that better theoretical performance can be achieved if the trees are grown less aggressively (i.e., grown to a shallower depth) than previous work would otherwise recommend.
Provenance for Interactive Visualizations
We highlight the connections between data provenance and interactive visualizations. To do so, we first incrementally add interactions to a visualization and show how these interactions are readily expressible in terms of provenance. We then describe how an interactive visualization system that natively supports provenance can be easily extended with novel interactions.
Stochastic Quasi-Gradient Methods: Variance Reduction via Jacobian Sketching
We develop a new family of variance reduced stochastic gradient descent methods for minimizing the average of a very large number of smooth functions. Our method –JacSketch– is motivated by novel developments in randomized numerical linear algebra, and operates by maintaining a stochastic estimate of a Jacobian matrix composed of the gradients of individual functions. In each iteration, JacSketch efficiently updates the Jacobian matrix by first obtaining a random linear measurement of the true Jacobian through (cheap) sketching, and then projecting the previous estimate onto the solution space of a linear matrix equation whose solutions are consistent with the measurement. The Jacobian estimate is then used to compute a variance-reduced unbiased estimator of the gradient. Our strategy is analogous to the way quasi-Newton methods maintain an estimate of the Hessian, and hence our method can be seen as a stochastic quasi-gradient method. We prove that for smooth and strongly convex functions, JacSketch converges linearly with a meaningful rate dictated by a single convergence theorem which applies to general sketches. We also provide a refined convergence theorem which applies to a smaller class of sketches. This enables us to obtain sharper complexity results for variants of JacSketch with importance sampling. By specializing our general approach to specific sketching strategies, JacSketch reduces to the stochastic average gradient (SAGA) method, and several of its existing and many new minibatch, reduced memory, and importance sampling variants. Our rate for SAGA with importance sampling is the current best-known rate for this method, resolving a conjecture by Schmidt et al (2015). The rates we obtain for minibatch SAGA are also superior to existing rates.
• Distributed Monitoring of Election Winners
• Beamforming Design for Max-Min Fair SWIPT in Green Cloud-RAN with Wireless Fronthaul
• MIMO-OTFS in High-Doppler Fading Channels: Signal Detection and Channel Estimation
• Target Apps Selection: Towards a Unified Search Framework for Mobile Devices
• Zero-shot Sequence Labeling: Transferring Knowledge from Sentences to Tokens
• Generalized Center Problems with Outliers
• Multi-Passage Machine Reading Comprehension with Cross-Passage Answer Verification
• Tensor-Based Channel Estimation for Dual-Polarized Massive MIMO Systems
• The Exact Computational Complexity of Evolutionarily Stable Strategies
• Residual Ratio Thresholding for Model Order Selection
• A Markovian genomic concatenation model guided by persymmetric matrices
• Discrete Factorization Machines for Fast Feature-based Recommendation
• Statistical Inference and Exact Saddle Point Approximations
• Sidorenko’s conjecture for higher tree decompositions
• Acquisition and use of knowledge over a restricted domain by intelligent agents
• Reachability Analysis of Deep Neural Networks with Provable Guarantees
• On Facility Location with General Lower Bounds
• Multidimensional Realization Theory and Polynomial System Solving
• Identities involving Narayana numbers
• Bayesian Regularization for Graphical Models with Unequal Shrinkage
• Russian word sense induction by clustering averaged word embeddings
• Semi-random graph process
• Active disturbance rejection for precise positioning of dual-stage hard disk drives
• Construction of the Literature Graph in Semantic Scholar
• Automated Diagnosis of Clinic Workflows
• Breaking NLI Systems with Sentences that Require Simple Lexical Inferences
• On the $f$-Matrices of Pascal-like Triangles Defined by Riordan Arrays
• Coherence Modeling of Asynchronous Conversations: A Neural Entity Grid Approach
• Mobile recommender systems: Identifying the major concepts
• S4ND: Single-Shot Single-Scale Lung Nodule Detection
• Proto-exact categories of matroids, Hall algebras, and K-theory
• Multi-Domain Neural Machine Translation
• DocFace: Matching ID Document Photos to Selfies
• Unique rectification in $d$-complete posets: towards the $K$-theory of Kac-Moody flag varieties
• The State of the Art in Developing Fuzzy Ontologies: A Survey
• A random effects stochastic block model for joint community detection in multiple networks with applications to neuroimaging
• DIRECT: Deep Discriminative Embedding for Clustering of LIGO Data
• Unified Management and Optimization of Edge-Cloud IoT Applications
• Linear Programming Formulation of Long Run Average Optimal Control Problem
• Stabilization of parallel-flow heat exchangers with arbitrary delayed boundary feedback
• Single-Anchor Two-Way Localization Bounds for 5G mmWave Systems: Two Protocols
• Exploiting Physical-Layer Security for Multiuser Multicarrier Computation Offloading
• Linear Quadratic Synchronization of Multi-Agent Systems: A Distributed Optimization Approach
• Learning Matching Models with Weak Supervision for Response Selection in Retrieval-based Chatbots
• An Axiomatic Analysis of Diversity Evaluation Metrics: Introducing the Rank-Biased Utility Metric
• Skeleton-Based Action Recognition with Spatial Reasoning and Temporal Stack Learning
• Sharp Attention Network via Adaptive Sampling for Person Re-identification
• The existence and uniqueness of viscosity solutions to generalized Hamilton-Jacobi-Bellman equations
• A Hierarchical Matcher using Local Classifier Chains
• Nonovershooting Cooperative Output Regulation for Linear Multi-Agent Systems
• Quantum Circuits for Toom-Cook Multiplication
• Deep Reinforcement Learning for Page-wise Recommendations
• An Additive Approximation to Multiplicative Noise
• (Nearly) Efficient Algorithms for the Graph Matching Problem on Correlated Random Graphs
• Efficient active learning of sparse halfspaces
• Fine-grained Complexity Meets IP = PSPACE
• Full explicit consistency constraints in uncalibrated multiple homography estimation
• Adaptive Polarization Control for Coherent Optical Links with Polarization Multiplexed Carrier
• Treewidth, crushing, and hyperbolic volume
• Planning and Learning with Stochastic Action Sets
• Hyperplane arrangements in CoCoA
• t-spread strongly stable monomial ideals
• Elastic Registration of Medical Images With GANs
• Consistency and differences between centrality metrics across distinct classes of networks
• Robust Design of Power Minimizing Symbol-Level Precoder under Channel Uncertainty
• Billion-scale Network Embedding with Iterative Random Projection
• A Review on Facial Micro-Expressions Analysis: Datasets, Features and Metrics
• Relating Eye-Tracking Measures With Changes In Knowledge on Search Tasks
• Stay On-Topic: Generating Context-specific Fake Restaurant Reviews
• Acyclic Strategy for Silent Self-Stabilization in Spanning Forests
• Ranking for Relevance and Display Preferences in Complex Presentation Layouts
• A Combinatorial Game and an Efficiently Computable Shift Rule for the Prefer Max De Bruijn Sequence
• Numerical Probabilistic Approach to MFG
• Soft Maximin Aggregation of Heterogeneous Array Data
• Improving Knowledge Graph Embedding Using Simple Constraints
• Prioritizing network communities
• Neighborhood preferences for minimal dominating sets enumeration
• Nonparametric regression estimation for quasi-associated Hilbertian processes
• Covert Communication over Adversarially Jammed Channels
• Convergence Rate Analysis for Periodic Gossip Algorithms in Wireless Sensor Networks
• The generalized connectivity of $(n,k)$-bubble-sort graphs
• Paraphrase to Explicate: Revealing Implicit Noun-Compound Relations
• Unpaired Multi-Domain Image Generation via Regularized Conditional GANs
• $(Δ+1)$ Coloring in the Congested Clique Model
• Deep Ordinal Hashing with Spatial Attention
• On a class of Markov BSDEs with generalized driver
• Sentence-State LSTM for Text Representation
• Comparative evaluation of instrument segmentation and tracking methods in minimally invasive surgery
• MEGAN: Mixture of Experts of Generative Adversarial Networks for Multimodal Image Generation
• Classifying Big Data over Networks via the Logistic Network Lasso
• Dual-Polarization FBMC for Improved Performance in Wireless Communication Systems
• Drifted Brownian motions governed by fractional tempered derivatives
• Long-Term Human Motion Prediction by Modeling Motion Context and Enhancing Motion Dynamic
• Generalized Random Gilbert-Varshamov Codes
• On the maximum number of maximum independent sets
• Detecting Traffic Lights by Single Shot Detection
• A Penalty Method Based Approach for Autonomous Navigation using Nonlinear Model Predictive Control
• Storage Scheduling with Stochastic Uncertainties: Feasibility and Cost of Imbalances
• Online Best Reply Algorithms for Resource Allocation Problems
• Degrees of Freedom of the Bursty MIMO X Channel with Instantaneous Topological Information
• Lifting method for analyzing distributed synchronization on the unit sphere
• Near-drowning Early Prediction Technique Using Novel Equations (NEPTUNE) for Swimming Pools
• A probabilistic framework for handwritten text line segmentation
• Non-Monochromatic and Conflict-Free Coloring on Tree Spaces and Planar Network Spaces
• On the association and other forms of positive dependence for Feller processes
• Robustness of shape-restricted regression estimators: an envelope perspective
• Trajectory Representation and Landmark Projection for Continuous-Time Structure from Motion
• Learning Gene Regulatory Networks with High-Dimensional Heterogeneous Data
• Skeleton-Based Relational Modeling for Action Recognition
• Distributed Capacity of A Multiple Access Channel
• Capturing points with a rotating polygon (and a 3D extension)
• Computational Complexity of Space-Bounded Real Numbers
• Optimal Pricing in Repeated Posted-Price Auctions
• 30m resolution Global Annual Burned Area Mapping based on Landsat images and Google Earth Engine
• Extinction transitions in correlated external noise
• Reflection negative kernels and fractional Brownian motion
• Superconducting Optoelectronic Neurons II: Receiver Circuits
• Toward Human-in-the-Loop Supervisory Control for Cyber-Physical Networks
• Learning Multiple Gene Regulatory Networks in Type 1 Diabetes through a Fast Bayesian Integrative Method
• Computing the Shattering Coefficient of Supervised Learning Algorithms
• Viscosity Solutions to Master Equations and McKean-Vlasov SDEs with Closed-loop Controls
• On Redundant Observability: From Security Index to Attack Detection and Resilient State Estimation
• Label Refinery: Improving ImageNet Classification through Label Progression
• Wavelet Decomposition of Gradient Boosting
Like this:
Like Loading...