Causal Queries from Observational Data in Biological Systems via Bayesian Networks: An Empirical Study in Small Networks
Biological networks are a very convenient modelling and visualisation tool to discover knowledge from modern high-throughput genomics and postgenomics data sets. Indeed, biological entities are not isolated, but are components of complex multi-level systems. We go one step further and advocate for the consideration of causal representations of the interactions in living systems.We present the causal formalism and bring it out in the context of biological networks, when the data is observational. We also discuss its ability to decipher the causal information flow as observed in gene expression. We also illustrate our exploration by experiments on small simulated networks as well as on a real biological data set.
Using Quantum Mechanics to Cluster Time Series
In this article we present a method by which we can reduce a time series into a single point in
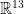
. We have chosen 13 dimensions so as to prevent too many points from being labeled as ‘noise.’ When using a Euclidean (or Mahalanobis) metric, a simple clustering algorithm will with near certainty label the majority of points as ‘noise.’ On pure physical considerations, this is not possible. Included in our 13 dimensions are four parameters which describe the coefficients of a cubic polynomial attached to a Gaussian picking up a general trend, four parameters picking up periodicity in a time series, two each for amplitude of a wave and period of a wave, and the final five report the ‘leftover’ noise of the detrended and aperiodic time series. Of the final five parameters, four are the centralized probabilistic moments, and the final for the relative size of the series. The first main contribution of this work is to apply a theorem of quantum mechanics about the completeness of the solutions to the quantum harmonic oscillator on

to estimating trends in time series. The second main contribution is the method of fitting parameters. After many numerical trials, we realized that methods such a Newton-Rhaphson and Levenberg-Marquardt converge extremely fast if the initial guess is good. Thus we guessed many initial points in our parameter space and computed only a few iterations, a technique common in Keogh’s work on time series clustering. Finally, we have produced a model which gives incredibly accurate results quickly. We ackowledge that there are faster methods as well of more accurate methods, but this work shows that we can still increase computation speed with little, if any, cost to accuracy in the sense of data clustering.
Work Stealing with latency
We study in this paper the impact of communication latency on the classical Work Stealing load balancing algorithm. Our approach considers existing performance models and the underlying algorithms. We introduce a latency parameter in the model and study its overall impact by careful observations of simulation results. Using this method we are able to derive a new expression of the expected running time of divisible load applications. This expression enables us to predict under which conditions a given run will yield acceptable performance. For instance, we can easily calibrate the maximal number of processors one should use for a given work platform combination. We also consider the impact of several algorithmic variants like simultaneous transfers of work or thresholds for avoiding useless transfers. All our results are validated through simulation on a wide range of parameters.
CYCLOSA: Decentralizing Private Web Search Through SGX-Based Browser Extensions
By regularly querying Web search engines, users (unconsciously) disclose large amounts of their personal data as part of their search queries, among which some might reveal sensitive information (e.g. health issues, sexual, political or religious preferences). Several solutions exist to allow users querying search engines while improving privacy protection. However, these solutions suffer from a number of limitations: some are subject to user re-identification attacks, while others lack scalability or are unable to provide accurate results. This paper presents CYCLOSA, a secure, scalable and accurate private Web search solution. CYCLOSA improves security by relying on trusted execution environments (TEEs) as provided by Intel SGX. Further, CYCLOSA proposes a novel adaptive privacy protection solution that reduces the risk of user re- identification. CYCLOSA sends fake queries to the search engine and dynamically adapts their count according to the sensitivity of the user query. In addition, CYCLOSA meets scalability as it is fully decentralized, spreading the load for distributing fake queries among other nodes. Finally, CYCLOSA achieves accuracy of Web search as it handles the real query and the fake queries separately, in contrast to other existing solutions that mix fake and real query results.
SecureStreams: A Reactive Middleware Framework for Secure Data Stream Processing
The growing adoption of distributed data processing frameworks in a wide diversity of application domains challenges end-to-end integration of properties like security, in particular when considering deployments in the context of large-scale clusters or multi-tenant Cloud infrastructures. This paper therefore introduces SecureStreams, a reactive middleware framework to deploy and process secure streams at scale. Its design combines the high-level reactive dataflow programming paradigm with Intel’s low-level software guard extensions (SGX) in order to guarantee privacy and integrity of the processed data. The experimental results of SecureStreams are promising: while offering a fluent scripting language based on Lua, our middleware delivers high processing throughput, thus enabling developers to implement secure processing pipelines in just few lines of code.
Dynamic Control Flow in Large-Scale Machine Learning
Many recent machine learning models rely on fine-grained dynamic control flow for training and inference. In particular, models based on recurrent neural networks and on reinforcement learning depend on recurrence relations, data-dependent conditional execution, and other features that call for dynamic control flow. These applications benefit from the ability to make rapid control-flow decisions across a set of computing devices in a distributed system. For performance, scalability, and expressiveness, a machine learning system must support dynamic control flow in distributed and heterogeneous environments. This paper presents a programming model for distributed machine learning that supports dynamic control flow. We describe the design of the programming model, and its implementation in TensorFlow, a distributed machine learning system. Our approach extends the use of dataflow graphs to represent machine learning models, offering several distinctive features. First, the branches of conditionals and bodies of loops can be partitioned across many machines to run on a set of heterogeneous devices, including CPUs, GPUs, and custom ASICs. Second, programs written in our model support automatic differentiation and distributed gradient computations, which are necessary for training machine learning models that use control flow. Third, our choice of non-strict semantics enables multiple loop iterations to execute in parallel across machines, and to overlap compute and I/O operations. We have done our work in the context of TensorFlow, and it has been used extensively in research and production. We evaluate it using several real-world applications, and demonstrate its performance and scalability.
SecureCloud: Secure Big Data Processing in Untrusted Clouds
We present the SecureCloud EU Horizon 2020 project, whose goal is to enable new big data applications that use sensitive data in the cloud without compromising data security and privacy. For this, SecureCloud designs and develops a layered architecture that allows for (i) the secure creation and deployment of secure micro-services; (ii) the secure integration of individual micro-services to full-fledged big data applications; and (iii) the secure execution of these applications within untrusted cloud environments. To provide security guarantees, SecureCloud leverages novel security mechanisms present in recent commodity CPUs, in particular, Intel’s Software Guard Extensions (SGX). SecureCloud applies this architecture to big data applications in the context of smart grids. We describe the SecureCloud approach, initial results, and considered use cases.
Simplified SPARQL REST API – CRUD on JSON Object Graphs via URI Paths
Within the Semantic Web community, SPARQL is one of the predominant languages to query and update RDF knowledge. However, the complexity of SPARQL, the underlying graph structure and various encodings are common sources of confusion for Semantic Web novices. In this paper we present a general purpose approach to convert any given SPARQL endpoint into a simple to use REST API. To lower the initial hurdle, we represent the underlying graph as an interlinked view of nested JSON objects that can be traversed by the API path.
Noisin: Unbiased Regularization for Recurrent Neural Networks
Recurrent neural networks (RNNs) are powerful models of sequential data. They have been successfully used in domains such as text and speech. However, RNNs are susceptible to overfitting; regularization is important. In this paper we develop Noisin, a new method for regularizing RNNs. Noisin injects random noise into the hidden states of the RNN and then maximizes the corresponding marginal likelihood of the data. We show how Noisin applies to any RNN and we study many different types of noise. Noisin is unbiased–it preserves the underlying RNN on average. We characterize how Noisin regularizes its RNN both theoretically and empirically. On language modeling benchmarks, Noisin improves over dropout by as much as 12.2% on the Penn Treebank and 9.4% on the Wikitext-2 dataset. We also compared the state-of-the-art language model of Yang et al. 2017, both with and without Noisin. On the Penn Treebank, the method with Noisin more quickly reaches state-of-the-art performance.
SURREAL: SUbgraph Robust REpresentAtion Learning
The success of graph embeddings or node representation learning in a variety of downstream tasks, such as node classification, link prediction, and recommendation systems, has led to their popularity in recent years. Representation learning algorithms aim to preserve local and global network structure by identifying node neighborhood notions. However, many existing algorithms generate embeddings that fail to properly preserve the network structure, or lead to unstable representations due to random processes (e.g., random walks to generate context) and, thus, cannot generate to multi-graph problems. In this paper, we propose a robust graph embedding using connection subgraphs algorithm, entitled: SURREAL, a novel, stable graph embedding algorithmic framework. SURREAL learns graph representations using connection subgraphs by employing the analogy of graphs with electrical circuits. It preserves both local and global connectivity patterns, and addresses the issue of high-degree nodes. Further, it exploits the strength of weak ties and meta-data that have been neglected by baselines. The experiments show that SURREAL outperforms state-of-the-art algorithms by up to 36.85% on multi-label classification problem. Further, in contrast to baselines, SURREAL, being deterministic, is completely stable.
How deep should be the depth of convolutional neural networks: a backyard dog case study
We present a straightforward non-iterative method for shallowing of deep Convolutional Neural Network (CNN) by combination of several layers of CNNs with Advanced Supervised Principal Component Analysis (ASPCA) of their outputs. We tested this new method on a practically important case of `friend-or-foe’ face recognition. This is the backyard dog problem: the dog should (i) distinguish the members of the family from possible strangers and (ii) identify the members of the family. Our experiments revealed that the method is capable of drastically reducing the depth of deep learning CNNs, albeit at the cost of mild performance deterioration.
Lifted Neural Networks
We describe a novel family of models of multi- layer feedforward neural networks in which the activation functions are encoded via penalties in the training problem. Our approach is based on representing a non-decreasing activation function as the argmin of an appropriate convex optimization problem. The new framework allows for algorithms such as block-coordinate descent methods to be applied, in which each step is composed of a simple (no hidden layer) supervised learning problem that is parallelizable across data points and/or layers. Experiments indicate that the proposed models provide excellent initial guesses for weights for standard neural networks. In addition, the model provides avenues for interesting extensions, such as robustness against noisy inputs and optimizing over parameters in activation functions.
A Deep Learning Model with Hierarchical LSTMs and Supervised Attention for Anti-Phishing
Anti-phishing aims to detect phishing content/documents in a pool of textual data. This is an important problem in cybersecurity that can help to guard users from fraudulent information. Natural language processing (NLP) offers a natural solution for this problem as it is capable of analyzing the textual content to perform intelligent recognition. In this work, we investigate state-of-the-art techniques for text categorization in NLP to address the problem of anti-phishing for emails (i.e, predicting if an email is phishing or not). These techniques are based on deep learning models that have attracted much attention from the community recently. In particular, we present a framework with hierarchical long short-term memory networks (H-LSTMs) and attention mechanisms to model the emails simultaneously at the word and the sentence level. Our expectation is to produce an effective model for anti-phishing and demonstrate the effectiveness of deep learning for problems in cybersecurity.
Transferring GANs: generating images from limited data
Transferring the knowledge of pretrained networks to new domains by means of finetuning is a widely used practice for applications based on discriminative models. To the best of our knowledge this practice has not been studied within the context of generative deep networks. Therefore, we study domain adaptation applied to image generation with generative adversarial networks. We evaluate several aspects of domain adaptation, including the impact of target domain size, the relative distance between source and target domain, and the initialization of conditional GANs. Our results show that using knowledge from pretrained networks can shorten the convergence time and can significantly improve the quality of the generated images, especially when the target data is limited. We show that these conclusions can also be drawn for conditional GANs even when the pretrained model was trained without conditioning. Our results also suggest that density may be more important than diversity and a dataset with one or few densely sampled classes may be a better source model than more diverse datasets such as ImageNet or Places.
A brief introduction to the Grey Machine Learning
This paper presents a brief introduction to the key points of the Grey Machine Learning (GML) based on the kernels. The general formulation of the grey system models have been firstly summarized, and then the nonlinear extension of the grey models have been developed also with general formulations. The kernel implicit mapping is used to estimate the nonlinear function of the GML model, by extending the nonparametric formulation of the LSSVM, the estimation of the nonlinear function of the GML model can also be expressed by the kernels. A short discussion on the priority of this new framework to the existing grey models and LSSVM have also been discussed in this paper. And the perspectives and future orientations of this framework have also been presented.
Equity of Attention: Amortizing Individual Fairness in Rankings
Rankings of people and items are at the heart of selection-making, match-making, and recommender systems, ranging from employment sites to sharing economy platforms. As ranking positions influence the amount of attention the ranked subjects receive, biases in rankings can lead to unfair distribution of opportunities and resources, such as jobs or income. This paper proposes new measures and mechanisms to quantify and mitigate unfairness from a bias inherent to all rankings, namely, the position bias, which leads to disproportionately less attention being paid to low-ranked subjects. Our approach differs from recent fair ranking approaches in two important ways. First, existing works measure unfairness at the level of subject groups while our measures capture unfairness at the level of individual subjects, and as such subsume group unfairness. Second, as no single ranking can achieve individual attention fairness, we propose a novel mechanism that achieves amortized fairness, where attention accumulated across a series of rankings is proportional to accumulated relevance. We formulate the challenge of achieving amortized individual fairness subject to constraints on ranking quality as an online optimization problem and show that it can be solved as an integer linear program. Our experimental evaluation reveals that unfair attention distribution in rankings can be substantial, and demonstrates that our method can improve individual fairness while retaining high ranking quality.
The conformable fractional grey system model
The fractional order grey models (FGM) have appealed considerable interest of research in recent years due to its higher effectiveness and flexibility than the conventional grey models and other prediction models. However, the definitions of the fractional order accumulation (FOA) and difference (FOD) is computationally complex, which leads to difficulties for the theoretical analysis and applications. In this paper, the new definition of the FOA are proposed based on the definitions of Conformable Fractional Derivative, which is called the Conformable Fractional Accumulation (CFA), along with its inverse operation, the Conformable Fractional Difference (CFD). Then the new Conformable Fractional Grey Model (CFGM) based on CFA and CFD is introduced with detailed modelling procedures. The feasibility and simplicity and the CFGM are shown in the numerical example. And the at last the comprehensive real-world case studies of natural gas production forecasting in 11 countries are presented, and results show that the CFGM is much more effective than the existing FGM model in the 165 subcases.
Unsupervised learning for concept detection in medical images: a comparative analysis
As digital medical imaging becomes more prevalent and archives increase in size, representation learning exposes an interesting opportunity for enhanced medical decision support systems. On the other hand, medical imaging data is often scarce and short on annotations. In this paper, we present an assessment of unsupervised feature learning approaches for images in the biomedical literature, which can be applied to automatic biomedical concept detection. Six unsupervised representation learning methods were built, including traditional bags of visual words, autoencoders, and generative adversarial networks. Each model was trained, and their respective feature space evaluated using images from the ImageCLEF 2017 concept detection task. We conclude that it is possible to obtain more powerful representations with modern deep learning approaches, in contrast with previously popular computer vision methods. Although generative adversarial networks can provide good results, they are harder to succeed in highly varied data sets. The possibility of semi-supervised learning, as well as their use in medical information retrieval problems, are the next steps to be strongly considered.
Failure Prediction for Autonomous Driving
The primary focus of autonomous driving research is to improve driving accuracy. While great progress has been made, state-of-the-art algorithms still fail at times. Such failures may have catastrophic consequences. It therefore is important that automated cars foresee problems ahead as early as possible. This is also of paramount importance if the driver will be asked to take over. We conjecture that failures do not occur randomly. For instance, driving models may fail more likely at places with heavy traffic, at complex intersections, and/or under adverse weather/illumination conditions. This work presents a method to learn to predict the occurrence of these failures, i.e. to assess how difficult a scene is to a given driving model and to possibly give the human driver an early headsup. A camera-based driving model is developed and trained over real driving datasets. The discrepancies between the model’s predictions and the human `ground-truth’ maneuvers were then recorded, to yield the `failure’ scores. Experimental results show that the failure score can indeed be learned and predicted. Thus, our prediction method is able to improve the overall safety of an automated driving model by alerting the human driver timely, leading to better human-vehicle collaborative driving.
• Two theorems about the P versus NP problem
• Sustainable Cloud Computing: Foundations and Future Directions
• Moderate deviations for the $L_1$-norm of kernel density estimators
• Robustness of sentence length measures in written texts
• Optimal Capital Injections with the Risk of Ruin: A Stochastic Differential Game of Impulse Control and Stopping Approach
• Facial Landmark Point Localization using Coarse-to-Fine Deep Recurrent Neural Network
• An efficient algorithm to test forcibly-biconnectedness of graphical degree sequences
• Data-Driven Exploration of Factors Affecting Federal Student Loan Repayment
• Domination Critical Knodel Graphs
• The truncated 0-stable subordinator, renewal theorems, and disordered systems
• Polynomial data compression for large-scale physics experiments
• On the stability of many-body localization in $d>1$
• Improved decoding of Folded Reed-Solomon and Multiplicity Codes
• Improved Detection Performance of Passive Radars Exploiting Known Communication Signal Form
• The Bott-Brion-Dehn-Ehrhart-Euler-Khovanskii-Maclaurin-Puhklikov-Sommerville-Vergne formula for simple lattice polytopes
• Front propagation for reaction-diffusion equations in composite structures
• Robust OFDM integrated radar and communications waveform design
• Advanced Target Detection via Molecular Communication
• Convergence of the Iterates in Mirror Descent Methods
• On the Impact of Unknown Signals in Passive Radar with Direct Path and Reflected Path Observations
• Distributed and Multi-layer UAV Network for the Next-generation Wireless Communication
• Fast and Scalable Expansion of Natural Language Understanding Functionality for Intelligent Agents
• Approximating $(k,\ell)$-center clustering for curves
• Finite-Time Resilient Formation Control with Bounded Inputs
• A Reinforcement Learning Approach to Interactive-Predictive Neural Machine Translation
• An End-to-end Approach for Handling Unknown Slot Values in Dialogue State Tracking
• Pixel-wise Attentional Gating for Parsimonious Pixel Labeling
• The genus of complete 3-uniform hypergraphs
• The number of s-separated k-sets in various circles
• IBBE-SGX: Cryptographic Group Access Control using Trusted Execution Environments
• Apply Chinese Radicals Into Neural Machine Translation: Deeper Than Character Level
• Efficient methods for the estimation of the multinomial parameter for the two-trait group testing model
• Local angles and dimension estimation from data on manifolds
• Fairness in Multiterminal Data Compression: A Splitting Method for The Egalitarian Solution
• When Politicians Talk About Politics: Identifying Political Tweets of Brazilian Congressmen
• Quadratic ideals and Rogers-Ramanujan recursions
• Pytrec_eval: An Extremely Fast Python Interface to trec_eval
• A Customer Choice Model with HALO Effect
• On Spectral Radius of Biased Random Walks on Infinite Graphs
• Uniform spanning forests associated with biased random walks on Euclidean lattices
• Distribution Assertive Regression
• Recent Progress on Graph Partitioning Problems Using Evolutionary Computation
• Estimating Learnability in the Sublinear Data Regime
• BelMan: Bayesian Bandits on the Belief–Reward Manifold
• Is Information in the Brain Represented in Continuous or Discrete Form?
• A software framework for embedded nonlinear model predictive control using a gradient-based augmented Lagrangian approach (GRAMPC)
• Algorithm for Hamilton-Jacobi equations in density space via a generalized Hopf formula
• On the isotopism classes of Budaghyan-Helleseth commutative semifields
• Estimation of Extreme Survival Probabilities with Cox Model
• On the integral modulus of infinitely divisible distributions
• Delay Performance of the Multiuser MISO Downlink
• Cross-lingual Candidate Search for Biomedical Concept Normalization
• Sharp Convergence Rates for Langevin Dynamics in the Nonconvex Setting
• Propagation of Chaos for Stochastic Spatially Structured Neuronal Networks with Fully Path Dependent Delays and Monotone Coefficients driven by Jump Diffusion Noise
• Differential stability of convex optimization problems with possibly empty solution sets
• Characterizing Asynchronous Message-Passing Models Through Rounds
• On the Q-linear convergence of Distributed Generalized ADMM under non-strongly convex function components
• Approximating Performance Measures for Slowly Changing Non-stationary Markov Chains
• Dynamic Power Allocation for Smart Grids via ADMM
• Intracranial Error Detection via Deep Learning
• Upping the Ante: Towards a Better Benchmark for Chinese-to-English Machine Translation
• Distribution Dependent SDEs with Singular Coefficients
• Lower and Upper Bound for Computing the Size of All Second Neighbourhoods
• Combinatorial Pure Exploration with Continuous and Separable Reward Functions and Its Applications (Extended Version)
• Strong subgraph $k$-arc-connectivity
• Cliques in rank-1 random graphs: the role of inhomogeneity
• Stein’s method for diffusive limit of Markov processes
• A Convex Approximation of the Relaxed Binaural Beamforming Optimization Problem
• Solving a Conjecture on Identification in Hamming Graphs
• Partitioning Edge-Coloured Complete Symmetric Digraphs into Monochromatic Complete Subgraphs
• Beyond the Click-Through Rate: Web Link Selection with Multi-level Feedback
• Feature extraction with regularized siamese networks for outlier detection: application to lesion screening in medical imaging
• Regularity of solutions of the Stein equation and rates in the multivariate central limit theorem
• Regularization of ill-posed problems with non-negative solutions
• Axiomatic Approach to Variable Kernel Density Estimation
• On the Secrecy Performance of SWIPT Receiver Architectures with Multiple Eavesdroppers
• Coherent multiple scattering of light in dimension 2+1
• X-Search: Revisiting Private Web Search using Intel SGX
• Classification of Epileptic EEG Signals by Wavelet based CFC
• Quasi-sure duality for multi-dimensional martingale optimal transport
• Morphism extension classes of countable $L$-colored graphs
• To Centralize or Not to Centralize: A Tale of Swarm Coordination
• Assessing Data Usefulness for Failure Analysis in Anonymized System Logs
• Eulerian polynomials on segmented permutations
• Noise as a resource
• Stochastic Geometry-based Uplink Analysis of Massive MIMO Systems with Fractional Pilot Reuse
• An Observable Canonical Form for a Rational System on a Variety
• Polynomials and tensors of bounded strength
• Extreme Adaptation for Personalized Neural Machine Translation
• Object and Text-guided Semantics for CNN-based Activity Recognition
• Global testing under the sparse alternatives for single index models
• Inductive Certificate Synthesis for Control Design
• A New Perspective on FO Model Checking of Dense Graph Classes
• Positioning of High-speed Trains using 5G New Radio Synchronization Signals
• Ultra Low Power Deep-Learning-powered Autonomous Nano Drones
• On estimands and the analysis of adverse events in the presence of varying follow-up times within the benefit assessment of therapies
• Towards a Spectrum of Graph Convolutional Networks
• Valid Inference for $L_2$-Boosting
• Lasso, knockoff and Gaussian covariates: a comparison
• Mixture Envelope Model for Heterogeneous Genomics Data Analysis
• Bayesian active learning for choice models with deep Gaussian processes
• Algorithmic Decision Making in the Presence of Unmeasured Confounding
• Hedging parameter selection for basis pursuit
• Automatic Estimation of Modulation Transfer Functions
• Detecting Mutations by eBWT
• The repair problem for Reed-Solomon codes: Optimal repair of single and multiple erasures, asymptotically optimal node size
• Population-calibrated multiple imputation for a binary/categorical covariate in categorical regression models
Like this:
Like Loading...