Canonical Correlation Analysis of Datasets with a Common Source Graph
Canonical correlation analysis (CCA) is a powerful technique for discovering whether or not hidden sources are commonly present in two (or more) datasets. Its well-appreciated merits include dimensionality reduction, clustering, classification, feature selection, and data fusion. The standard CCA however, does not exploit the geometry of the common sources, which may be available from the given data or can be deduced from (cross-) correlations. In this paper, this extra information provided by the common sources generating the data is encoded in a graph, and is invoked as a graph regularizer. This leads to a novel graph-regularized CCA approach, that is termed graph (g) CCA. The novel gCCA accounts for the graph-induced knowledge of common sources, while minimizing the distance between the wanted canonical variables. Tailored for diverse practical settings where the number of data is smaller than the data vector dimensions, the dual formulation of gCCA is also developed. One such setting includes kernels that are incorporated to account for nonlinear data dependencies. The resultant graph-kernel (gk) CCA is also obtained in closed form. Finally, corroborating image classification tests over several real datasets are presented to showcase the merits of the novel linear, dual, and kernel approaches relative to competing alternatives.
Privacy-preserving Prediction
Ensuring differential privacy of models learned from sensitive user data is an important goal that has been studied extensively in recent years. It is now known that for some basic learning problems, especially those involving high-dimensional data, producing an accurate private model requires much more data than learning without privacy. At the same time, in many applications it is not necessary to expose the model itself. Instead users may be allowed to query the prediction model on their inputs only through an appropriate interface. Here we formulate the problem of ensuring privacy of individual predictions and investigate the overheads required to achieve it in several standard models of classification and regression. We first describe a simple baseline approach based on training several models on disjoint subsets of data and using standard private aggregation techniques to predict. We show that this approach has nearly optimal sample complexity for (realizable) PAC learning of any class of Boolean functions. At the same time, without strong assumptions on the data distribution, the aggregation step introduces a substantial overhead. We demonstrate that this overhead can be avoided for the well-studied class of thresholds on a line and for a number of standard settings of convex regression. The analysis of our algorithm for learning thresholds relies crucially on strong generalization guarantees that we establish for all differentially private prediction algorithms.
How Developers Iterate on Machine Learning Workflows — A Survey of the Applied Machine Learning Literature
Machine learning workflow development is anecdotally regarded to be an iterative process of trial-and-error with humans-in-the-loop. However, we are not aware of quantitative evidence corroborating this popular belief. A quantitative characterization of iteration can serve as a benchmark for machine learning workflow development in practice, and can aid the development of human-in-the-loop machine learning systems. To this end, we conduct a small-scale survey of the applied machine learning literature from five distinct application domains. We collect and distill statistics on the role of iteration within machine learning workflow development, and report preliminary trends and insights from our investigation, as a starting point towards this benchmark. Based on our findings, we finally describe desiderata for effective and versatile human-in-the-loop machine learning systems that can cater to users in diverse domains.
The Uranie platform: an Open-source software for optimisation, meta-modelling and uncertainty analysis
The high-performance computing resources and the constant improvement of both numerical simulation accuracy and the experimental measurements with which they are confronted, bring a new compulsory step to strengthen the credence given to the simulation results: uncertainty quantification. This can have different meanings, according to the requested goals (rank uncertainty sources, reduce them, estimate precisely a critical threshold or an optimal working point) and it could request mathematical methods with greater or lesser complexity. This paper introduces the Uranie platform, an Open-source framework which is currently developed at the Alternative Energies and Atomic Energy Commission (CEA), in the nuclear energy division, in order to deal with uncertainty propagation, surrogate models, optimisation issues, code calibration… This platform benefits from both its dependencies, but also from personal developments, to offer an efficient data handling model, a C++ and Python interpreter, advanced graphical tools, several parallelisation solutions… These methods are very generic and can then be applied to many kinds of code (as Uranie considers them as black boxes) so to many fields of physics as well. In this paper, the example of thermal exchange between a plate-sheet and a fluid is introduced to show how Uranie can be used to perform a large range of analysis. The code used to produce the figures of this paper can be found in
https://…/uranie along with the sources of the platform.
Adversarial Network Compression
Neural network compression has recently received much attention due to the computational requirements of modern deep models. In this work, our objective is to transfer knowledge from a deep and accurate model to a smaller one. Our contributions are threefold: (i) we propose an adversarial network compression approach to train the small student network to mimic the large teacher, without the need for labels during training; (ii) we introduce a regularization scheme to prevent a trivially-strong discriminator without reducing the network capacity and (iii) our approach generalizes on different teacher-student models. In an extensive evaluation on five standard datasets, we show that our student has small accuracy drop, achieves better performance than other knowledge transfer approaches and it surpasses the performance of the same network trained with labels. In addition, we demonstrate state-of-the-art results compared to other compression strategies.
A Study of Clustering Techniques and Hierarchical Matrix Formats for Kernel Ridge Regression
We present memory-efficient and scalable algorithms for kernel methods used in machine learning. Using hierarchical matrix approximations for the kernel matrix the memory requirements, the number of floating point operations, and the execution time are drastically reduced compared to standard dense linear algebra routines. We consider both the general
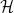
matrix hierarchical format as well as Hierarchically Semi-Separable (HSS) matrices. Furthermore, we investigate the impact of several preprocessing and clustering techniques on the hierarchical matrix compression. Effective clustering of the input leads to a ten-fold increase in efficiency of the compression. The algorithms are implemented using the STRUMPACK solver library. These results confirm that — with correct tuning of the hyperparameters — classification using kernel ridge regression with the compressed matrix does not lose prediction accuracy compared to the exact — not compressed — kernel matrix and that our approach can be extended to

datasets, for which computation with the full kernel matrix becomes prohibitively expensive. We present numerical experiments in a distributed memory environment up to 1,024 processors of the NERSC’s Cori supercomputer using well-known datasets to the machine learning community that range from dimension 8 up to 784.
Machine Speech Chain with One-shot Speaker Adaptation
In previous work, we developed a closed-loop speech chain model based on deep learning, in which the architecture enabled the automatic speech recognition (ASR) and text-to-speech synthesis (TTS) components to mutually improve their performance. This was accomplished by the two parts teaching each other using both labeled and unlabeled data. This approach could significantly improve model performance within a single-speaker speech dataset, but only a slight increase could be gained in multi-speaker tasks. Furthermore, the model is still unable to handle unseen speakers. In this paper, we present a new speech chain mechanism by integrating a speaker recognition model inside the loop. We also propose extending the capability of TTS to handle unseen speakers by implementing one-shot speaker adaptation. This enables TTS to mimic voice characteristics from one speaker to another with only a one-shot speaker sample, even from a text without any speaker information. In the speech chain loop mechanism, ASR also benefits from the ability to further learn an arbitrary speaker’s characteristics from the generated speech waveform, resulting in a significant improvement in the recognition rate.
Normalization of Neural Networks using Analytic Variance Propagation
We address the problem of estimating statistics of hidden units in a neural network using a method of analytic moment propagation. These statistics are useful for approximate whitening of the inputs in front of saturating non-linearities such as a sigmoid function. This is important for initialization of training and for reducing the accumulated scale and bias dependencies (compensating covariate shift), which presumably eases the learning. In batch normalization, which is currently a very widely applied technique, sample estimates of statistics of hidden units over a batch are used. The proposed estimation uses an analytic propagation of mean and variance of the training set through the network. The result depends on the network structure and its current weights but not on the specific batch input. The estimates are suitable for initialization and normalization, efficient to compute and independent of the batch size. The experimental verification well supports these claims. However, the method does not share the generalization properties of BN, to which our experiments give some additional insight.
Feed-forward Uncertainty Propagation in Belief and Neural Networks
We propose a feed-forward inference method applicable to belief and neural networks. In a belief network, the method estimates an approximate factorized posterior of all hidden units given the input. In neural networks the method propagates uncertainty of the input through all the layers. In neural networks with injected noise, the method analytically takes into account uncertainties resulting from this noise. Such feed-forward analytic propagation is differentiable in parameters and can be trained end-to-end. Compared to standard NN, which can be viewed as propagating only the means, we propagate the mean and variance. The method can be useful in all scenarios that require knowledge of the neuron statistics, e.g. when dealing with uncertain inputs, considering sigmoid activations as probabilities of Bernoulli units, training the models regularized by injected noise (dropout) or estimating activation statistics over the dataset (as needed for normalization methods). In the experiments we show the possible utility of the method in all these tasks as well as its current limitations.
End-to-End Multi-Task Learning with Attention
In this paper, we propose a novel multi-task learning architecture, which incorporates recent advances in attention mechanisms. Our approach, the Multi-Task Attention Network (MTAN), consists of a single shared network containing a global feature pool, together with task-specific soft-attention modules, which are trainable in an end-to-end manner. These attention modules allow for learning of task-specific features from the global pool, whilst simultaneously allowing for features to be shared across different tasks. The architecture can be built upon any feed-forward neural network, is simple to implement, and is parameter efficient. Experiments on the CityScapes dataset show that our method outperforms several baselines in both single-task and multi-task learning, and is also more robust to the various weighting schemes in the multi-task loss function. We further explore the effectiveness of our method through experiments over a range of task complexities, and show how our method scales well with task complexity compared to baselines.
• Disease-Atlas: Navigating Disease Trajectories with Deep Learning
• Real-Time Computability of Real Numbers by Chemical Reaction Networks
• A random variant of the game of plates and olives
• Regularization and Computation with high-dimensional spike-and-slab posterior distributions
• Neuroevolution for RTS Micro
• Fast Computation of Robust Subspace Estimators
• Generalized Eulerian Triangles and Some Special Production Matrices
• Multi-Modal Data Augmentation for End-to-end ASR
• Correlation Functions as Nests of Self-Avoiding Paths
• The $1/k$-Eulerian Polynomials as Moments, via Exponential Riordan Arrays
• Co-evolving Real-Time Strategy Game Micro
• Evolutionary Multi-objective Optimization of Real-Time Strategy Micro
• Distributed Majorization-Minimization for Laplacian Regularized Problems
• The balanced 2-median and 2-maxian problems on a tree
• Adaptive Affinity Field for Semantic Segmentation
• Graph Convolutions on Spectral Embeddings: Learning of Cortical Surface Data
• Classification of crystallization outcomes using deep convolutional neural networks
• Structural inpainting
• Dense Subgraphs in Random Graphs
• Sobolev spaces with non-Muckenhoupt weights, fractional elliptic operators, and applications
• Extensions of partial cyclic orders and consecutive coordinate polytopes
• An optimization parameter for seriation of noisy data
• Deep Communicating Agents for Abstractive Summarization
• ClickBAIT-v2: Training an Object Detector in Real-Time
• ASY-SONATA: Achieving Geometric Convergence for Distributed Asynchronous Optimization
• Number of 1-factorizations of regular high-degree graphs
• 1-factorizations of pseudorandom graphs
• Referring Relationships
• Smoothed Online Convex Optimization in High Dimensions via Online Balanced Descent
• InLoc: Indoor Visual Localization with Dense Matching and View Synthesis
• Best finite approximations of Benford’s Law
• Reinforcement learning for non-prehensile manipulation: Transfer from simulation to physical system
• Exploiting Residual Resources to Support High Throughput with Resource Allocation
• On the Algorithmic Power of Spiking Neural Networks
• Topic Modeling Based Multi-modal Depression Detection
• Automatic Stroke Lesions Segmentation in Diffusion-Weighted MRI
• On the control of agents coupled through shared resources
• Exploring Quantum Supremacy in Access Structures of Secret Sharing by Coding Theory
• Cooperative Autonomous Vehicle Speed Optimization near Signalized Intersections
• Supervising Unsupervised Learning with Evolutionary Algorithm in Deep Neural Network
• Lip Movements Generation at a Glance
• A Sherman-Morrison-Woodbury Identity for Rank Augmenting Matrices with Application to Centering
• 3DMV: Joint 3D-Multi-View Prediction for 3D Semantic Scene Segmentation
• Two kinds of generalized connectivity of dual cubes
• A Better Resource Allocation Algorithm with Semi-Bandit Feedback
• The HAM10000 Dataset: A Large Collection of Multi-Source Dermatoscopic Images of Common Pigmented Skin Lesions
• The Effects of JPEG and JPEG2000 Compression on Attacks using Adversarial Examples
• Handling Verb Phrase Anaphora with Dependent Types and Events
• Improving likelihood-based inference in control rate regression
• Robust Video Content Alignment and Compensation for Rain Removal in a CNN Framework
• Exploiting Recurrent Neural Networks and Leap Motion Controller for Sign Language and Semaphoric Gesture Recognition
• BIVAS: A scalable Bayesian method for bi-level variable selection with applications
• Closed Form Expressions for the Probability Density Function of the Interference Power in PPP Networks
• Projected-gradient algorithms for generalized equilibrium seeking in Aggregative Games are preconditioned Forward-Backward methods
• Cameron-Liebler line classes in ${\rm PG}(3,5)$
• Continuous-time integral dynamics for Aggregative Game equilibrium seeking
• Manifolds of isospectral arrow matrices
• Siamese Cookie Embedding Networks for Cross-Device User Matching
• Central limit theorem for descents in conjugacy classes of $S_n$
• Graphite: Iterative Generative Modeling of Graphs
• All hyperbolic Coxeter $n$-cubes
• Optimizing the Drift in a Diffusive Search for a Random Stationary Target
• Learning Pixel-level Semantic Affinity with Image-level Supervision for Weakly Supervised Semantic Segmentation
• On the convergence of discrete-time linear systems: A linear time-varying Mann iteration converges iff the operator is strictly pseudocontractive
• What deep learning can tell us about higher cognitive functions like mindreading?
• Objects Localisation from Motion with Constraints
• Branching Brownian Motion with spatially-homogeneous and point-catalytic branching
• Semitotal domination in trees
• Dietcoin: shortcutting the Bitcoin verification process for your smartphone
• Bundled fragments of first-order modal logic: (un)decidability
• On Degree Properties of Crossing-Critical Families of Graphs
• Quantum algorithms for training Gaussian Processes
• Estimating causal effects of time-dependent exposures on a binary endpoint in a high-dimensional setting
• Context-aware Deep Feature Compression for High-speed Visual Tracking
• Mesoscopic linear statistics of Wigner matrices of mixed symmetry class
• Notes on well-distributed minimal sub-BIBDs for $λ=1$
• Neural Network Architecture for Credibility Assessment of Textual Claims
• FPGA Implementations of 3D-SIMD Processor Architecture for Deep Neural Networks Using Relative Indexed Compressed Sparse Filter Encoding Format and Stacked Filters Stationary Flow
• Joint PLDA for Simultaneous Modeling of Two Factors
• Parity Polytopes and Binarization
• ELEGANT: Exchanging Latent Encodings with GAN for Transferring Multiple Face Attributes
• Image Generation and Translation with Disentangled Representations
• How to ask sensitive multiple choice questions
• Jumps in speeds of hereditary properties in finite relational languages
• Inexact First-Order Primal-Dual Algorithms
• Finitary codings of spatial mixing Markov random fields
• Stochastic Variational Inference with Gradient Linearization
• Differentiability of semigroups of stochastic differential equations with Hölder-continuous diffusion coefficients
• The fifth ‘CHiME’ Speech Separation and Recognition Challenge: Dataset, task and baselines
• Penalization of Galton-Watson processes
• Minkowski content of Brownian cut points
• A Douglas-Rachford splitting for semi-decentralized generalized Nash equilibrium seeking in Monotone Aggregative Games
• Scaling limit of the VRJP in dimension one and Bass-Burdzy flow
• Meta-Learning a Dynamical Language Model
• On Exponential Stabilization of Spin-1/2 Systems
• Framework for ETH-tight Algorithms and Lower Bounds in Geometric Intersection Graphs
• On Learning Graphs with Edge-Detecting Queries
• Quantum Noise Detects Floquet Topological Phases
• Active Metric Learning for Supervised Classification
• A Distributed Extension of the Turing Machine
• Bayesian Regression with Undirected Network Predictors with an Application to Brain Connectome Data
• Cubical rectangles and rectangular lattices
• Rainbow factors in hypergraphs
• A Mixed-Logical-Dynamical model for Automated Driving on highways
• Qubit-qudit separability/PPT-probability investigations, including Lovas-Andai formula advancements
• Motion Guided LIDAR-camera Autocalibration and Accelerated Depth Super Resolution
• Pose2Seg: Human Instance Segmentation Without Detection
• One-step dispatching policy improvement in multiple-server queueing systems with Poisson arrivals
• On merging constraint and optimal control-Lyapunov functions
• Weakly-Supervised Action Segmentation with Iterative Soft Boundary Assignment
• Darling-Kac theorem for renewal shifts in the absence of regular variation
• Semi-supervised learning for structured regression on partially observed attributed graphs
• Extendibility limits the performance of quantum processors
• Existence and uniqueness of mild solution to stochastic heat equation with white and fractional noises
• The edge-vertex inequality in a planar graph and a bipartition for the class of all planar graphs
• Application of Variance-Based Sensitivity Analysis to a Large System Dynamics Model
• An Approach for Finding Permutations Quickly: Fusion and Dimension matching
• Deeply Supervised Semantic Model for Click-Through Rate Prediction in Sponsored Search
• Solving the OSCAR and SLOPE Models Using a Semismooth Newton-Based Augmented Lagrangian Method
• Intertwiners between Induced Representations (with Applications to the Theory of Equivariant Neural Networks)
• Power grid transient stabilization using Koopman model predictive control
• Poincare type inequalities for a pure jump Markov process
• Pseudo-marginal Bayesian inference for supervised Gaussian process latent variable models
• On Model Selection with Summary Statistics
• Investigating the hybrid textures of neutrino mass matrix for near maximal atmospheric neutrino mixing
• Unsupervised Predictive Memory in a Goal-Directed Agent
• Approximation of the interface condition for stochastic Stefan-type problems
Like this:
Like Loading...