Forecasting Economics and Financial Time Series: ARIMA vs. LSTM
A Multi-perspective Approach To Anomaly Detection For Self-aware Embodied Agents
Serverless Data Analytics with Flint
Differential Privacy for Growing Databases
Decentralization Meets Quantization
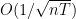 where
where  is the number of workers and
is the number of workers and  is the number of iterations, matching the {\rc convergence} rate for full precision, centralized training. We evaluate our algorithms on training deep learning models, and find that our proposed algorithm outperforms the best of merely decentralized and merely quantized algorithm significantly for networks with {\em both} high latency and low bandwidth.
is the number of iterations, matching the {\rc convergence} rate for full precision, centralized training. We evaluate our algorithms on training deep learning models, and find that our proposed algorithm outperforms the best of merely decentralized and merely quantized algorithm significantly for networks with {\em both} high latency and low bandwidth.
When Does Machine Learning FAIL? Generalized Transferability for Evasion and Poisoning Attacks
Deep Component Analysis via Alternating Direction Neural Networks
Learning over Knowledge-Base Embeddings for Recommendation
Variational Knowledge Graph Reasoning
Sparse Regularization via Convex Analysis
Unsupervised Semantic Deep Hashing
• A Low-rank Tensor Regularization Strategy for Hyperspectral Unmixing
• Halving the bounds for the Markov, Chebyshev, and Chernoff Inequalities using smoothing
• Geometric Adaptive Control for a Quadrotor UAV with Wind Disturbance Rejection
• Inference for case-control studies with incident and prevalent cases
• Graphs, Ultrafilters and Colourability
• Adversarial Logit Pairing
• A Generalised Method for Empirical Game Theoretic Analysis
• Spread of Information with Confirmation Bias in Cyber-Social Networks
• Distributed Optimization for Second-Order Multi-Agent Systems with Dynamic Event-Triggered Communication
• A prediction criterion for working correlation structure selection in GEE
• The $α$-normal labeling method for computing the $p$-spectral radii of uniform hypergraphs
• Improving the efficiency and robustness of nested sampling using posterior repartitioning
• Corpus Statistics in Text Classification of Online Data
• Phylogeny-based tumor subclone identification using a Bayesian feature allocation model
• Combinatorial proofs of two Euler type identities due to Andrews
• Reviving and Improving Recurrent Back-Propagation
• Decision support with text-based emotion recognition: Deep learning for affective computing
• Evaluating Conditional Cash Transfer Policies with Machine Learning Methods
• Three Études on a sequence transformation pipeline
• The 21 reducible polars of Klein’s quartic
• Learning to Segment via Cut-and-Paste
• Coding for Channels with SNR Variation: Spatial Coupling and Efficient Interleaving
• Leveraging Sparsity to Speed Up Polynomial Feature Expansions of CSR Matrices Using $K$-Simplex Numbers
• A New Result on the Complexity of Heuristic Estimates for the A* Algorithm
• A Novel Blaschke Unwinding Adaptive Fourier Decomposition based Signal Compression Algorithm with Application on ECG Signals
• Replica Symmetry Breaking in Bipartite Spin Glasses and Neural Networks
• Datalog: Bag Semantics via Set Semantics
• On Polyhedral Estimation of Signals via Indirect Observations
• Frequency-Domain Decoupling for MIMO-GFDM Spatial Multiplexing
• Note: Variational Encoding of Protein Dynamics Benefits from Maximizing Latent Autocorrelation
• Constrained Deep Learning using Conditional Gradient and Applications in Computer Vision
• Experiments with Neural Networks for Small and Large Scale Authorship Verification
• Generalization of a Real-Analysis Result to a Class of Topological Vector Spaces
• Learning to Cluster for Proposal-Free Instance Segmentation
• Mean Reverting Portfolios via Penalized OU-Likelihood Estimation
• Toward Understanding the Impact of User Participation in Autonomous Ridesharing Systems
• Optimizing Information Freshness in Wireless Networks under General Interference Constraints
• Distributed Scheduling Algorithms for Optimizing Information Freshness in Wireless Networks
• Optimizing Age of Information in Wireless Networks with Perfect Channel State Information
• Variational Inference as an alternative to MCMC for parameter estimation and model selection
• Finite-Size Scaling Regarding Interaction in the Many-Body Localization Transition
• Queuing Theory Guided Intelligent Traffic Scheduling through Video Analysis using Dirichlet Process Mixture Model
• Asynchronous Distributed Method of Multipliers for Constrained Nonconvex Optimization
• Robust event-stream pattern tracking based on correlative filter
• Evolving Deep Convolutional Neural Networks by Variable-length Particle Swarm Optimization for Image Classification
• A simple algorithm for Max Cut
• Variational Bayesian Inference of Line Spectral Estimation with Multiple Measurement Vectors
• Argumentation theory for mathematical argument
• Weakly Supervised Salient Object Detection Using Image Labels
• A simulated annealing procedure based on the ABC Shadow algorithm for statistical inference of point processes
• Learning Unsupervised Visual Grounding Through Semantic Self-Supervision
• Covering Arrays for Equivalence Classes of Words
• MergeNet: A Deep Net Architecture for Small Obstacle Discovery
• Hidden Integrality of SDP Relaxation for Sub-Gaussian Mixture Models
• On weak universality of three-dimensional Larger than Life cellular automaton
• Optimal Designs for the Generalized Partial Credit Model
• Provable Convex Co-clustering of Tensors
• Signal detection via Phi-divergences for general mixtures
• Learning Mixtures of Product Distributions via Higher Multilinear Moments
• Stochastic model-based minimization of weakly convex functions
• SeqFace: Make full use of sequence information for face recognitio
• Topology Estimation using Graphical Models in Multi-Phase Power Distribution Grids
• Dear Sir or Madam, May I introduce the YAFC Corpus: Corpus, Benchmarks and Metrics for Formality Style Transfer
• Optimal Design of Nonlinear Multifactor Experiments
• The Graph Structure of Chebyshev Polynomials over Finite Fields and Applications
• Adaptive strategy for superpixel-based region-growing image segmentation
• Convolutional Point-set Representation: A Convolutional Bridge Between a Densely Annotated Image and 3D Face Alignment
• The parametrix method for parabolic SPDEs
• Low-Order Control Design using a Reduced-Order Model with a Stability Constraint on the Full-Order Model
• On Mahalanobis distance in functional settings
• Fusion of an Ensemble of Augmented Image Detectors for Robust Object Detection
• Consistent estimation of treatment effects under heterogeneous heteroskedasticity
• Multi-device, Multi-tenant Model Selection with GP-EI
• Viewpoint: Artificial Intelligence and Labour
• Computing the Best Approximation Over the Intersection of a Polyhedral Set and the Doubly Nonnegative Cone
• A Dual Approach to Scalable Verification of Deep Networks
• Splittable and unsplittable graphs and configurations
• Orthogonal Representations for Output System Pairs
• On the Fenchel Duality between Strong Convexity and Lipschitz Continuous Gradient
• Multi-user Multi-task Offloading and Resource Allocation in Mobile Cloud Systems
• A two-stage estimation procedure for non-linear structural equation models
• Aging is a (log-)Poisson Process, not a Renewal Process
• Learning Long Term Dependencies via Fourier Recurrent Units
• Structural query-by-committee
• Early Hospital Mortality Prediction using Vital Signals
• Layer structure of irreducible Lie algebra modules
• Deep Learning for Nonlinear Diffractive Imaging
• Facial Landmarks Detection by Self-Iterative Regression based Landmarks-Attention Network
• Optimizing the Efficiency of First-order Methods for Decreasing the Gradient of Smooth Convex Functions
• Two new classes of quantum MDS codes
• Energy-aware networked control systems under temporal logic specifications
• Dynamic Trajectory Model for Analysis of Traffic States using DPMM
• Characterizations of the Logistic and Related Distributions
• Learning recurrent dynamics in spiking networks
• The Automatic Identification of Butterfly Species
• Cross-modality image synthesis from unpaired data using CycleGAN: Effects of gradient consistency loss and training data size
• A Guided FP-growth algorithm for fast mining of frequent itemsets from big data
• Complexity problems in enumerative combinatorics
• Adaptive prior probabilities via optimization of risk and entropy
• Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains
• The Web as a Knowledge-base for Answering Complex Questions
• Computing and Testing Pareto Optimal Committees
• Approximating the Likelihood in Approximate Bayesian Computation
• Line Artist: A Multiple Style Sketch to Painting Synthesis Scheme
• Ratio-Preserving Half-Cylindrical Warps for Natural Image Stitching
• Sdf-GAN: Semi-supervised Depth Fusion with Multi-scale Adversarial Networks
• An Introduction to the Moebius Function
• Testing for equal correlation matrices with application to paired gene expression data
• Damped Anderson acceleration with restarts and monotonicity control for accelerating EM and EM-like algorithms
• A View-based Programmable Architecture for Controlling and Integrating Decentralized Data
• Rare Feature Selection in High Dimensions
• Scenario-Based Uncertainty Set for Two-Stage Robust Energy and Reserve Scheduling: A Data-Driven Approach
• A Review of Conjectured Laws of Total Mass of Bacry-Muzy GMC Measures on the Interval and Circle and Their Applications
• Supervised learning magnetic skyrmion phases
• Sub-Riemannian Geodesics on SU(n)/S(U(n-1)xU(1)) and Optimal Control of Three Level Quantum Systems
• Controllability of Symmetric Spin Networks
• On Infinite Divisibility of the Distribution of Some Inverse Subordinators
• Hierarchical Predictive Control Algorithms for Optimal Design and Operation of Microgrids
• Descent distribution on Catalan words avoiding a pattern of length at most three
• An Improved Welfare Guarantee for First Price Auctions
• Almost all string graphs are intersection graphs of plane convex sets
• A Dynamic Additive and Multiplicative Effects Model with Application to the United Nations Voting Behaviors
• High Dimensional Linear Regression using Lattice Basis Reduction
• Excluding joint probabilities from quantum theory
• Detection under One-Bit Messaging over Adaptive Networks
• Aggregating Strategies for Long-term Forecasting
• A non-intersecting random walk on the Manhattan lattice and SLE_6
• Combining Probabilistic Load Forecasts
• Discriminative Learning of Latent Features for Zero-Shot Recognition
• A class of asymmetric regression models for left-censored data
• Bayesian ROC surface estimation under verification bias
• Large-Scale Dynamic Predictive Regressions
• A Construction of the Stable Web
• Inventory Control with Modulated Demand and a Partially Observed Modulation Process
• Neural Architecture Construction using EnvelopeNets
• Sentiment Analysis of Code-Mixed Indian Languages: An Overview of SAIL_Code-Mixed Shared Task @ICON-2017
• Experimental Verification of Rate Flexibility and Probabilistic Shaping by 4D Signaling
• A Machine Learning Approach for Power Allocation in HetNets Considering QoS
• Towards an Efficient Anomaly-Based Intrusion Detection for Software-Defined Networks
• STatistical Election to Partition Sequentially (STEPS) and Its Application in Differentially Private Release and Analysis of Youth Voter Registration Data
• Gallai’s path decomposition conjecture for triangle-free planar graphs
• Composable Deep Reinforcement Learning for Robotic Manipulation
• Comparing and Integrating Constraint Programming and Temporal Planning for Quantum Circuit Compilation
• White matter hyperintensity segmentation from T1 and FLAIR images using fully convolutional neural networks enhanced with residual connections
• TOMAAT: volumetric medical image analysis as a cloud service
• The Optimal Compression Rate of Variable-to-Fixed Length Source Coding with a Non-Vanishing Excess-Distortion Probability
• The Cohomology for Wu Characteristics
• Towards ‘simultaneous selective inference’: post-hoc bounds on the false discovery proportion
• Depth-aware CNN for RGB-D Segmentation
• Nonlocal Low-Rank Tensor Factor Analysis for Image Restoration
• On Optimal Pricing of Services in On-demand Labor Platforms
• Attention-GAN for Object Transfiguration in Wild Images
• Revisiting RCNN: On Awakening the Classification Power of Faster RCNN
• Computational topology and the Unique Games Conjecture
• Alive Caricature from 2D to 3D
• Stochastic maximum principle, dynamic programming principle, and their relationship for fully coupled forward-backward stochastic control systems
• Acoustic feature learning cross-domain articulatory measurements
• On certain unimodal sequences and strict partitions
• Centralized Caching with Unequal Cache Sizes
• Local martingales associated with SLE with internal symmetry
• Weakly Supervised Object Localization on grocery shelves using simple FCN and Synthetic Dataset
• ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation
• Swapping Colored Tokens on Graphs
• Artificial Intelligence Enabled Software Defined Networking: A Comprehensive Overview
• Rescaled weighted determinantal random balls
• Nonparametric forecasting of multivariate probability density functions
• A counterexample to Las Vergnas’ strong map conjecture on realizable oriented matroids
• Exact confirmation of 1D nonlinear fluctuating hydrodynamics for a two-species exclusion process
• Linear-time geometric algorithm for evaluating Bézier curves
• Cloud Provider Capacity Augmentation Through Automated Resource Bartering
• The square negative correlation on l_p^n balls
• An Adaptable System to Support Provenance Management for the Public Policy-Making Process in Smart Cities
• Confounder Detection in High Dimensional Linear Models using First Moments of Spectral Measures
• An improved isomorphism test for bounded-tree-width graphs
• On the hierarchical structure of Pareto critical sets
• Cloud Infrastructure Provenance Collection and Management to Reproduce Scientific Workflow Execution
• Symbol-Level Precoding Design for Max-Min SINR in Multiuser MISO Broadcast Channels
• Parameterized complexity of fair deletion problems II
• The tree of numerical semigroups with low multiplicity
• Lossless Analog Compression
• A Mixture of Views Network with Applications to the Classification of Breast Microcalcifications
• Limit Theorems for Cylindrical Martingale Problems associated with Lévy Generators
• Cyclic Sieving and Cluster Duality for Grassmannian
• Aerial LaneNet: Lane Marking Semantic Segmentation in Aerial Imagery using Wavelet-Enhanced Cost-sensitive Symmetric Fully Convolutional Neural Networks
• Auxiliary information : the raking-ratio empirical process
• Universal features of price formation in financial markets: perspectives from Deep Learning
• Cloud Workload Prediction based on Workflow Execution Time Discrepancies
• Explicit formula for the density of local times of Markov Jump Processes
• Differentiability of SDEs with drifts of super-linear growth
• Deja Vu: Motion Prediction in Static Images
• Asymmetric kernel in Gaussian Processes for learning target variance
• Entropy solutions for stochastic porous media equations
• On the importance of single directions for generalization
• Featureless: Bypassing feature extraction in action categorization
• A modern maximum-likelihood theory for high-dimensional logistic regression
• Polyglot Semantic Parsing in APIs
• Comparing Dynamics: Deep Neural Networks versus Glassy Systems
• What Doubling Tricks Can and Can’t Do for Multi-Armed Bandits
• The environmental footprint of a distributed cloud storage
• Exact Distance Oracles Using Hopsets
• Improving Transferability of Adversarial Examples with Input Diversity
• Quantifying coherence with quantum addition
• Robust Optimization and Control for Electricity Generation and Transmission
• Synthesis of Logical Clifford Operators via Symplectic Geometry
• Numerical Integration on Graphs: where to sample and how to weigh
• Estimating the intrinsic dimension of datasets by a minimal neighborhood information
• Stochastic evolution equations with singular drift and gradient noise via curvature and commutation conditions
• Radio bearing of sources with directional antennas in urban environment
• Live Target Detection with Deep Learning Neural Network and Unmanned Aerial Vehicle on Android Mobile Device
• Bayesian design of experiments for intractable likelihood models using coupled auxiliary models and multivariate emulation
• An efficient algorithm for packing cuts and (2,3)-metrics in a planar graph with three holes
• A note on vague convergence of measures
• Brownian Motions on Star Graphs with Non-Local Boundary Conditions
• Factorised spatial representation learning: application in semi-supervised myocardial segmentation
• Controlling Decoding for More Abstractive Summaries with Copy-Based Networks
• On the $k$-independence number of graphs
• Projective Splitting with Forward Steps: Asynchronous and Block-Iterative Operator Splitting
• Time-Domain Multi-Beam Selection and Its Performance Improvement for mmWave Systems
• Attack-Resilient H2, H-infinity, and L1 State Estimator
• Optimal link prediction with matrix logistic regression
• Simple random search provides a competitive approach to reinforcement learning
• Learning Region Features for Object Detection
• Setting up a Reinforcement Learning Task with a Real-World Robot
• D$^2$: Decentralized Training over Decentralized Data
• Testing normality via a distributional fixed point property in the Stein characterization