Novelty Detection with GAN
The ability of a classifier to recognize unknown inputs is important for many classification-based systems. We discuss the problem of simultaneous classification and novelty detection, i.e. determining whether an input is from the known set of classes and from which specific class, or from an unknown domain and does not belong to any of the known classes. We propose a method based on the Generative Adversarial Networks (GAN) framework. We show that a multi-class discriminator trained with a generator that generates samples from a mixture of nominal and novel data distributions is the optimal novelty detector. We approximate that generator with a mixture generator trained with the Feature Matching loss and empirically show that the proposed method outperforms conventional methods for novelty detection. Our findings demonstrate a simple, yet powerful new application of the GAN framework for the task of novelty detection.
• Relational Neural Expectation Maximization: Unsupervised Discovery of Objects and their Interactions
Compressing Neural Networks using the Variational Information Bottleneck
Neural networks can be compressed to reduce memory and computational requirements, or to increase accuracy by facilitating the use of a larger base architecture. In this paper we focus on pruning individual neurons, which can simultaneously trim model size, FLOPs, and run-time memory. To improve upon the performance of existing compression algorithms we utilize the information bottleneck principle instantiated via a tractable variational bound. Minimization of this information theoretic bound reduces the redundancy between adjacent layers by aggregating useful information into a subset of neurons that can be preserved. In contrast, the activations of disposable neurons are shut off via an attractive form of sparse regularization that emerges naturally from this framework, providing tangible advantages over traditional sparsity penalties without contributing additional tuning parameters to the energy landscape. We demonstrate state-of-the-art compression rates across an array of datasets and network architectures.
Extractive Text Summarization using Neural Networks
Text Summarization has been an extensively studied problem. Traditional approaches to text summarization rely heavily on feature engineering. In contrast to this, we propose a fully data-driven approach using feedforward neural networks for single document summarization. We train and evaluate the model on standard DUC 2002 dataset which shows results comparable to the state of the art models. The proposed model is scalable and is able to produce the summary of arbitrarily sized documents by breaking the original document into fixed sized parts and then feeding it recursively to the network.
Semi-Supervised Learning Enabled by Multiscale Deep Neural Network Inversion
Deep Neural Networks (DNNs) provide state-of-the-art solutions in several difficult machine perceptual tasks. However, their performance relies on the availability of a large set of labeled training data, which limits the breadth of their applicability. Hence, there is a need for new {\em semi-supervised learning} methods for DNNs that can leverage both (a small amount of) labeled and unlabeled training data. In this paper, we develop a general loss function enabling DNNs of any topology to be trained in a semi-supervised manner without extra hyper-parameters. As opposed to current semi-supervised techniques based on topology-specific or unstable approaches, ours is both robust and general. We demonstrate that our approach reaches state-of-the-art performance on the SVHN (
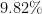
test error, with
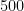
labels and wide Resnet) and CIFAR10 (16.38% test error, with 8000 labels and sigmoid convolutional neural network) data sets.
Improved Explainability of Capsule Networks: Relevance Path by Agreement
Recent advancements in signal processing and machine learning domains have resulted in an extensive surge of interest in deep learning models due to their unprecedented performance and high accuracy for different and challenging problems of significant engineering importance. However, when such deep learning architectures are utilized for making critical decisions such as the ones that involve human lives (e.g., in medical applications), it is of paramount importance to understand, trust, and in one word ‘explain’ the rational behind deep models’ decisions. Currently, deep learning models are typically considered as black-box systems, which do not provide any clue on their internal processing actions. Although some recent efforts have been initiated to explain behavior and decisions of deep networks, explainable artificial intelligence (XAI) domain is still in its infancy. In this regard, we consider capsule networks (referred to as CapsNets), which are novel deep structures; recently proposed as an alternative counterpart to convolutional neural networks (CNNs), and posed to change the future of machine intelligence. In this paper, we investigate and analyze structures and behaviors of the CapsNets and illustrate potential explainability properties of such networks. Furthermore, we show possibility of transforming deep learning architectures in to transparent networks via incorporation of capsules in different layers instead of convolution layers of the CNNs.
Collective Entity Disambiguation with Structured Gradient Tree Boosting
We present a gradient-tree-boosting-based structured learning model for jointly disambiguating named entities in a document. Gradient tree boosting is a widely used machine learning algorithm that underlies many top-performing natural language processing systems. Surprisingly, most works limit the use of gradient tree boosting as a tool for regular classification or regression problems, despite the structured nature of language. To the best of our knowledge, our work is the first one that employs the structured gradient tree boosting (SGTB) algorithm for collective entity disambiguation. By defining global features over previous disambiguation decisions and jointly modeling them with local features, our system is able to produce globally optimized entity assignments for mentions in a document. Exact inference is prohibitively expensive for our globally normalized model. To solve this problem, we propose Bidirectional Beam Search with Gold path (BiBSG), an approximate inference algorithm that is a variant of the standard beam search algorithm. BiBSG makes use of global information from both past and future to perform better local search. Experiments on standard benchmark datasets show that SGTB significantly improves upon published results. Specifically, SGTB outperforms the previous state-of-the-art neural system by near 1\% absolute accuracy on the popular AIDA-CoNLL dataset.
Apache Calcite: A Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources
Apache Calcite is a foundational software framework that provides query processing, optimization, and query language support to many popular open-source data processing systems such as Apache Hive, Apache Storm, Apache Flink, Druid, and MapD. Calcite’s architecture consists of a modular and extensible query optimizer with hundreds of built-in optimization rules, a query processor capable of processing a variety of query languages, an adapter architecture designed for extensibility, and support for heterogeneous data models and stores (relational, semi-structured, streaming, and geospatial). This flexible, embeddable, and extensible architecture is what makes Calcite an attractive choice for adoption in big-data frameworks. It is an active project that continues to introduce support for the new types of data sources, query languages, and approaches to query processing and optimization.
Escort: Efficient Sparse Convolutional Neural Networks on GPUs
Deep neural networks have achieved remarkable accuracy in many artificial intelligence applications, e.g. computer vision, at the cost of a large number of parameters and high computational complexity. Weight pruning can compress DNN models by removing redundant parameters in the networks, but it brings sparsity in the weight matrix, and therefore makes the computation inefficient on GPUs. Although pruning can remove more than 80% of the weights, it actually hurts inference performance (speed) when running models on GPUs. Two major problems cause this unsatisfactory performance on GPUs. First, lowering convolution onto matrix multiplication reduces data reuse opportunities and wastes memory bandwidth. Second, the sparsity brought by pruning makes the computation irregular, which leads to inefficiency when running on massively parallel GPUs. To overcome these two limitations, we propose Escort, an efficient sparse convolutional neural networks on GPUs. Instead of using the lowering method, we choose to compute the sparse convolutions directly. We then orchestrate the parallelism and locality for the direct sparse convolution kernel, and apply customized optimization techniques to further improve performance. Evaluation on NVIDIA GPUs show that Escort can improve sparse convolution speed by 2.63x and 3.07x, and inference speed by 1.38x and 1.60x, compared to CUBLAS and CUSPARSE respectively.
RRR: Rank-Regret Representative
We propose the rank-regret representative as a way of choosing a small subset of the database guaranteed to contain at least one of the top-k of any linear ranking function. We provide the techniques for finding such set and conduct experiments on real datasets to confirm the efficiency and effectiveness of our proposal.
Tensor Decomposition for Compressing Recurrent Neural Network
In the machine learning fields, Recurrent Neural Network (RNN) has become a popular algorithm for sequential data modeling. However, behind the impressive performance, RNNs require a large number of parameters for both training and inference. In this paper, we are trying to reduce the number of parameters and maintain the expressive power from RNN simultaneously. We utilize several tensor decompositions method including CANDECOMP/PARAFAC (CP), Tucker decomposition and Tensor Train(TT) to re-parameterize the Gated Recurrent Unit (GRU) RNN. We evaluate all tensor-based RNNs performance on sequence modeling tasks with a various number of parameters. Based on our experiment results, TT-GRU achieved the best results in a various number of parameters compared to other decomposition methods.
Convolutional Neural Networks with Alternately Updated Clique
Improving information flow in deep networks helps to ease the training difficulties and utilize parameters more efficiently. Here we propose a new convolutional neural network architecture with alternately updated clique (CliqueNet). In contrast to prior networks, there are both forward and backward connections between any two layers in the same block. The layers are constructed as a loop and are updated alternately. The CliqueNet has some unique properties. For each layer, it is both the input and output of any other layer in the same block, so that the information flow among layers is maximized. During propagation, the newly updated layers are concatenated to re-update previously updated layer, and parameters are reused for multiple times. This recurrent feedback structure is able to bring higher level visual information back to refine low-level filters and achieve spatial attention. We analyze the features generated at different stages and observe that using refined features leads to a better result. We adopt a multi-scale feature strategy that effectively avoids the progressive growth of parameters. Experiments on image recognition datasets including CIFAR-10, CIFAR-100, SVHN and ImageNet show that our proposed models achieve the state-of-the-art performance with fewer parameters.
Orion+: Automated Problem Diagnosis in Computing Systems by Mining Metric Data
This work presents the suspicious code at a finer granularity of call stack rather than code region, which was being returned by Orion. Call stack based comparison returns call stacks that are most impacted by the bug and save developer time to debug from scratch. This solution has polynomial complexity and hence can be implemented practically.
Exactly Robust Kernel Principal Component Analysis
We propose a novel method called robust kernel principal component analysis (RKPCA) to decompose a partially corrupted matrix as a sparse matrix plus a high or full-rank matrix whose columns are drawn from a nonlinear low-dimensional latent variable model. RKPCA can be applied to many problems such as noise removal and subspace clustering and is so far the only unsupervised nonlinear method robust to sparse noises. We also provide theoretical guarantees for RKPCA. The optimization of RKPCA is challenging because it involves nonconvex and indifferentiable problems simultaneously. We propose two nonconvex optimization algorithms for RKPCA: alternating direction method of multipliers with backtracking line search and proximal linearized minimization with adaptive step size. Comparative studies on synthetic data and nature images corroborate the effectiveness and superiority of RKPCA in noise removal and robust subspace clustering.
Learning by Playing – Solving Sparse Reward Tasks from Scratch
We propose Scheduled Auxiliary Control (SAC-X), a new learning paradigm in the context of Reinforcement Learning (RL). SAC-X enables learning of complex behaviors – from scratch – in the presence of multiple sparse reward signals. To this end, the agent is equipped with a set of general auxiliary tasks, that it attempts to learn simultaneously via off-policy RL. The key idea behind our method is that active (learned) scheduling and execution of auxiliary policies allows the agent to efficiently explore its environment – enabling it to excel at sparse reward RL. Our experiments in several challenging robotic manipulation settings demonstrate the power of our approach.
• Dominance phenomena: mutation, scattering and cluster algebras
• Generalized Byzantine-tolerant SGD
• Latent-space Physics: Towards Learning the Temporal Evolution of Fluid Flow
• Towards a Socially Optimal Multi-Modal Routing Platform
• On the structure of the fundamental subspaces of acyclic matrices with $0$ in the diagonal
• Spectral analysis of the trap model on sparse networks
• Augmented CycleGAN: Learning Many-to-Many Mappings from Unpaired Data
• Volume of small balls and sub-Riemannian curvature in 3D contact manifolds
• Markov equivalence of marginalized local independence graphs
• ADMM-based Networked Stochastic Variational Inference
• Tell Me Where to Look: Guided Attention Inference Network
• Mirrored Langevin Dynamics
• Role colouring graphs in hereditary classes
• Safety Control Synthesis with Input Limits: a Hybrid Approach
• Incremental Strong Connectivity and 2-Connectivity in Directed Graphs
• Exploiting the Natural Dynamics of Series Elastic Robots by Actuator-Centered Sequential Linear Programming
• Fractional Programming for Communication Systems–Part I: Power Control and Beamforming
• Fractional Programming for Communication Systems–Part II: Uplink Scheduling via Matching
• Local Distributed Algorithms in Highly Dynamic Networks
• Brain Tumor Type Classification via Capsule Networks
• Behavioral Learning of Aircraft Landing Sequencing Using a Society of Probabilistic Finite State Machines
• Networking the Boids is More Robust Against Adversarial Learning
• Asymptotic behavior of Rényi entropy in the central limit theorem
• Clustering of Naturalistic Driving Encounters Using Unsupervised Learning
• Var-CNN and DynaFlow: Improved Attacks and Defenses for Website Fingerprinting
• Investigating Human Priors for Playing Video Games
• Central moment inequalities using Stein’s method
• The existence of geodesics in Wasserstein spaces over path groups and loop groups
• Parametrized Accelerated Methods Free of Condition Number
• An EMG Gesture Recognition System with Flexible High-Density Sensors and Brain-Inspired High-Dimensional Classifier
• DeepSOFA: A Real-Time Continuous Acuity Score Framework using Deep Learning
• Neural Aesthetic Image Reviewer
• Sample size for a non-inferiority clinical trial with time-to-event data in the presence of competing risks
• IM2HEIGHT: Height Estimation from Single Monocular Imagery via Fully Residual Convolutional-Deconvolutional Network
• Joint Event Detection and Description in Continuous Video Streams
• $L_p$-Norm Constrained Coding With Frank-Wolfe Network
• Theory of Metal-Insulator Transitions in Graphite under High Magnetic Field
• Semi-Analytic Resampling in Lasso
• Spectral Efficiency of Mixed-ADC Massive MIMO
• Effective versions of two theorems of Rado
• Deep Reinforcement Learning for Vision-Based Robotic Grasping: A Simulated Comparative Evaluation of Off-Policy Methods
• Next Generation New Radio Small Cell Enhancement: Architectural Options, Functionality and Performance Aspects
• Selective Experience Replay for Lifelong Learning
• Solving for high dimensional committor functions using artificial neural networks
• Medical Exam Question Answering with Large-scale Reading Comprehension
• When fast and slow interfaces grow together: connection to the half-space problem of the Kardar-Parisi-Zhang class
• Multichannel Interpolation for Periodic Signals via FFT, Error Analysis and Image Scaling
• Brief Announcement: Semi-MapReduce Meets Congested Clique
• Limit theory for an AR(1) model with intercept and a possible infinite variance
• Edge Partitions of Optimal $2$-plane and $3$-plane Graphs
• Avoiding overfitting of multilayer perceptrons by training derivatives
• Bahadur representations for the bootstrap median absolute deviation and the application to projection depth weighted mean
• Online Non-preemptive Scheduling on Unrelated Machines with Rejections
• Fast Maximum Likelihood estimation via Equilibrium Expectation for Large Network Data
• A Model for Medical Diagnosis Based on Plantar Pressure
• A Hardware-Efficient Analog Network Structure for Hybrid Precoding in Millimeter Wave Systems
• Neural Photometric Stereo Reconstruction for General Reflectance Surfaces
• Reconsidering Linear Transmit Signal Processing in 1-Bit Quantized Multi-User MISO Systems
• Extreme-value copulas associated with the expected scaled maximum of independent random variables
• A flexible and computationally tractable discrete distribution derived from a stationary renewal process
• Fast Lempel-Ziv Decompression in Linear Space
• Learning to Adapt Structured Output Space for Semantic Segmentation
• Efficient Black-Box Reductions for Separable Cost Sharing
• Regression Monte Carlo for Microgrid Management
• General Video Game AI: a Multi-Track Framework for Evaluating Agents, Games and Content Generation Algorithms
• Deep-6DPose: Recovering 6D Object Pose from a Single RGB Image
• CoMP in the Sky: UAV Placement and Movement Optimization for Multi-User Communications
• Extreme statistics and index distribution in the classical $1d$ Coulomb gas
• i2kit: A Tool for Immutable Infrastructure Deployments based on Lightweight Virtual Machines specialized to run Containers
• Push Forward: Global Fixed-Priority Scheduling of Arbitrary-Deadline Sporadic Task Systems
• Parameterized Aspects of Strong Subgraph Closure
• Non-magic Hypergraphs
• A Bayesian Model for Activities Recommendation and Event Structure Optimization Using Visitors Tracking
• Survivable Network Design for Group Connectivity in Low-Treewidth Graphs
• Massive MIMO for Ultra-reliable Communications with Constellations for Dual Coherent-noncoherent Detection
• Short Packet Structure for Ultra-Reliable Machine-type Communication: Tradeoff between Detection and Decoding
• Distance entropy cartography characterises centrality in complex networks
• On the Sublinear Convergence of Randomly Perturbed Alternating Gradient Descent to Second Order Stationary Solutions
• Fine-grained wound tissue analysis using deep neural network
• A Simple Method to improve Initialization Robustness for Active Contours driven by Local Region Fitting Energy
• Low-Overhead Coordination in Sub-28 Millimeter-Wave Networks
• On the Benefits of Asymmetric Coded Cache Placement in Combination Networks with End-User Caches
• Coexistence in competing species models
• HSI-CNN: A Novel Convolution Neural Network for Hyperspectral Image
• Caching in Combination Networks: A Novel Delivery by Leveraging the Network Topology
• A Novel Asymmetric Coded Placement in Combination Networks with end-user Caches
• An Approximate Pareto Set for Minimizing the Maximum Lateness and Makespan on Parallel Machines
• Partial Identification of Expectations with Interval Data
• Pop Music Highlighter: Marking the Emotion Keypoints
• Epidemiologic analyses with error-prone exposures: Review of current practice and recommendations
• Learning Discriminative Multilevel Structured Dictionaries for Supervised Image Classification
• Predictive Uncertainty Estimation via Prior Networks
• Brain Tumor Segmentation and Radiomics Survival Prediction: Contribution to the BRATS 2017 Challenge
• Decision functions from supervised machine learning algorithms as collective variables for accelerating molecular simulations
• Set systems with distinct sumsets
• Stochastic Dynamic Programming Heuristics for Influence Maximization-Revenue Optimization
• Toll Caps in Privatized Road Networks
• On the Lie bracket approximation approach to distributed optimization: Extensions and limitations
• Application of Rényi and Tsallis Entropies to Topic Modeling Optimization
• Approaching near-perfect state discrimination of photonic Bell states through the use of unentangled ancilla photons
• Maximum likelihood estimation of a finite mixture of logistic regression models in a continuous data stream
• Thresholds of Braided Convolutional Codes on the AWGN Channel
• Memory-based Parameter Adaptation
• A Frequent Itemset Hiding Toolbox
• Computational Theories of Curiosity-Driven Learning
• Dynamic Pricing with Variable Order Sizes for a Model with Constant Demand Elasticity
• Using Deep Learning for Segmentation and Counting within Microscopy Data
• Automatic topography of high-dimensional data sets by non-parametric Density Peak clustering
• A Variational Inequality Perspective on Generative Adversarial Nets
• Equi-coverage Contours in Cellular Networks
• Retrieval and Registration of Long-Range Overlapping Frames for Scalable Mosaicking of In Vivo Fetoscopy
• General-type discrete self-adjoint Dirac systems: explicit solutions of direct and inverse problems, asymptotics of Verblunsky-type coefficients and stability of solving inverse problem
• Characterizing Demand Graphs for (Fixed-Parameter) Shallow-Light Steiner Network
• Simultaneously Self-Attending to All Mentions for Full-Abstract Biological Relation Extraction
• Statistical shape analysis in a Bayesian framework for shapes in two and three dimensions
• Near-Optimal Sample Complexity Bounds for Maximum Likelihood Estimation of Multivariate Log-concave Densities
• Modeling Activity Tracker Data Using Deep Boltzmann Machines
• Evaluating Overfit and Underfit in Models of Network Community Structure
• Stereoscopic Neural Style Transfer
• Model-Ensemble Trust-Region Policy Optimization
Like this:
Like Loading...