A partial correlation vine based approach for modeling and forecasting multivariate volatility time-series
A novel approach for dynamic modeling and forecasting of realized covariance matrices is proposed. Realized variances and realized correlation matrices are jointly estimated. The one-to-one relationship between a positive definite correlation matrix and its associated set of partial correlations corresponding to any vine specification is used. A method to select a vine structure, which allows for parsimonious time-series modeling, is introduced. The predicted partial correlations have a clear practical interpretation. Being algebraically independent they do not underlie any algebraic constraint. The forecasting performance is evaluated through investigation of six-dimensional real data and is compared to Cholesky decomposition based benchmark models.
Tunability: Importance of Hyperparameters of Machine Learning Algorithms
Modern machine learning algorithms for classification or regression such as gradient boosting, random forest and neural networks involve a number of parameters that have to be fixed before running them. Such parameters are commonly denoted as hyperparameters in machine learning, a terminology we also adopt here. The term tuning parameter is also frequently used to denote parameters that should be carefully tuned, i.e. optimized with respect to performance. The users of these algorithms can use defaults of these hyperparameters that are specified in the employed software package, set them to alternative specific values or use a tuning strategy to choose them appropriately for the specific dataset at hand. In this context, we define tunability as the amount of performance gain that can be achieved by setting the considered hyperparameter to the best possible value instead of the default value. The goal of this paper is two-fold. Firstly, we formalize the problem of tuning from a statistical point of view and suggest general measures quantifying the tunability of hyperparameters of algorithms. Secondly, we conduct a large-scale benchmarking study based on 38 datasets from the OpenML platform (Vanschoren et al., 2013) using six of the most common machine learning algorithms for classification and regression and apply our measures to assess the tunability of their parameters. The results yield interesting insights into the investigated hyperparameters that in some cases allow general conclusions on their tunability. Our results may help users of the algorithms to decide whether it is worth to conduct a possibly time consuming tuning strategy, to focus on the most important hyperparameters and to chose adequate hyperparameter spaces for tuning.
The Emergence of Spectral Universality in Deep Networks
Recent work has shown that tight concentration of the entire spectrum of singular values of a deep network’s input-output Jacobian around one at initialization can speed up learning by orders of magnitude. Therefore, to guide important design choices, it is important to build a full theoretical understanding of the spectra of Jacobians at initialization. To this end, we leverage powerful tools from free probability theory to provide a detailed analytic understanding of how a deep network’s Jacobian spectrum depends on various hyperparameters including the nonlinearity, the weight and bias distributions, and the depth. For a variety of nonlinearities, our work reveals the emergence of new universal limiting spectral distributions that remain concentrated around one even as the depth goes to infinity.
Human Perceptions of Fairness in Algorithmic Decision Making: A Case Study of Criminal Risk Prediction
As algorithms are increasingly used to make important decisions that affect human lives, ranging from social benefit assignment to predicting risk of criminal recidivism, concerns have been raised about the fairness of algorithmic decision making. Most prior works on algorithmic fairness normatively prescribe how fair decisions ought to be made. In contrast, here, we descriptively survey users for how they perceive and reason about fairness in algorithmic decision making. A key contribution of this work is the framework we propose to understand why people perceive certain features as fair or unfair to be used in algorithms. Our framework identifies eight properties of features, such as relevance, volitionality and reliability, as latent considerations that inform people’s moral judgments about the fairness of feature use in decision-making algorithms. We validate our framework through a series of scenario-based surveys with 576 people. We find that, based on a person’s assessment of the eight latent properties of a feature in our exemplar scenario, we can accurately (> 85%) predict if the person will judge the use of the feature as fair. Our findings have important implications. At a high-level, we show that people’s unfairness concerns are multi-dimensional and argue that future studies need to address unfairness concerns beyond discrimination. At a low-level, we find considerable disagreements in people’s fairness judgments. We identify root causes of the disagreements, and note possible pathways to resolve them.
Shampoo: Preconditioned Stochastic Tensor Optimization
Preconditioned gradient methods are among the most general and powerful tools in optimization. However, preconditioning requires storing and manipulating prohibitively large matrices. We describe and analyze a new structure-aware preconditioning algorithm, called Shampoo, for stochastic optimization over tensor spaces. Shampoo maintains a set of preconditioning matrices, each of which operates on a single dimension, contracting over the remaining dimensions. We establish convergence guarantees in the stochastic convex setting, the proof of which builds upon matrix trace inequalities. Our experiments with state-of-the-art deep learning models show that Shampoo is capable of converging considerably faster than commonly used optimizers. Although it involves a more complex update rule, Shampoo’s runtime per step is comparable to that of simple gradient methods such as SGD, AdaGrad, and Adam.
Learning for Convex Optimization
In many engineered systems, optimization is used for decision making at time-scales ranging from real-time operation to long-term planning. This process often involves solving similar optimization problems over and over again with slightly modified input parameters, often under stringent time requirements. We consider the problem of using the information available through this solution process to directly learn the optimal solution as a function of the input parameters, thus reducing the need of solving computationally expensive large-scale parametric programs in real time. Our proposed method is based on learning relevant sets of active constraints, from which the optimal solution can be obtained efficiently. Using active sets as features preserves information about the physics of the system, enables more interpretable learning policies, and inherently accounts for relevant safety constraints. Further, the number of relevant active sets is finite, which make them simpler objects to learn. To learn the relevant active sets, we propose a streaming algorithm backed up by theoretical results. Through extensive experiments on benchmarks of the Optimal Power Flow problem, we observe that often only a few active sets are relevant in practice, suggesting that this is the appropriate level of abstraction for a learning algorithm to target.
Modeling Others using Oneself in Multi-Agent Reinforcement Learning
We consider the multi-agent reinforcement learning setting with imperfect information in which each agent is trying to maximize its own utility. The reward function depends on the hidden state (or goal) of both agents, so the agents must infer the other players’ hidden goals from their observed behavior in order to solve the tasks. We propose a new approach for learning in these domains: Self Other-Modeling (SOM), in which an agent uses its own policy to predict the other agent’s actions and update its belief of their hidden state in an online manner. We evaluate this approach on three different tasks and show that the agents are able to learn better policies using their estimate of the other players’ hidden states, in both cooperative and adversarial settings.
Directional Statistics-based Deep Metric Learning for Image Classification and Retrieval
Deep distance metric learning (DDML), which is proposed to learn image similarity metrics in an end-to-end manner based on the convolution neural network, has achieved encouraging results in many computer vision tasks.

-normalization in the embedding space has been used to improve the performance of several DDML methods. However, the commonly used Euclidean distance is no longer an accurate metric for
-normalized embedding space, i.e., a hyper-sphere. Another challenge of current DDML methods is that their loss functions are usually based on rigid data formats, such as the triplet tuple. Thus, an extra process is needed to prepare data in specific formats. In addition, their losses are obtained from a limited number of samples, which leads to a lack of the global view of the embedding space. In this paper, we replace the Euclidean distance with the cosine similarity to better utilize the
-normalization, which is able to attenuate the curse of dimensionality. More specifically, a novel loss function based on the von Mises-Fisher distribution is proposed to learn a compact hyper-spherical embedding space. Moreover, a new efficient learning algorithm is developed to better capture the global structure of the embedding space. Experiments for both classification and retrieval tasks on several standard datasets show that our method achieves state-of-the-art performance with a simpler training procedure. Furthermore, we demonstrate that, even with a small number of convolutional layers, our model can still obtain significantly better classification performance than the widely used softmax loss.
Multi-Observation Regression
Recent work introduced loss functions which measure the error of a prediction based on multiple simultaneous observations or outcomes. In this paper, we explore the theoretical and practical questions that arise when using such multi-observation losses for regression on data sets of
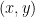
pairs. When a loss depends on only one observation, the average empirical loss decomposes by applying the loss to each pair, but for the multi-observation case, empirical loss is not even well-defined, and the possibility of statistical guarantees is unclear without several
pairs with exactly the same

value. We propose four algorithms formalizing the concept of empirical risk minimization for this problem, two of which have statistical guarantees in settings allowing both slow and fast convergence rates, but which are out-performed empirically by the other two. Empirical results demonstrate practicality of these algorithms in low-dimensional settings, while lower bounds demonstrate intrinsic difficulty in higher dimensions. Finally, we demonstrate the potential benefit of the algorithms over natural baselines that use traditional single-observation losses via both lower bounds and simulations.
Link Prediction Based on Graph Neural Networks
Traditional methods for link prediction can be categorized into three main types: graph structure feature-based, latent feature-based, and explicit feature-based. Graph structure feature methods leverage some handcrafted node proximity scores, e.g., common neighbors, to estimate the likelihood of links. Latent feature methods rely on factorizing networks’ matrix representations to learn an embedding for each node. Explicit feature methods train a machine learning model on two nodes’ explicit attributes. Each of the three types of methods has its unique merits. In this paper, we propose SEAL (learning from Subgraphs, Embeddings, and Attributes for Link prediction), a new framework for link prediction which combines the power of all the three types into a single graph neural network (GNN). GNN is a new type of neural network which directly accepts graphs as input and outputs their labels. In SEAL, the input to the GNN is a local subgraph around each target link. We prove theoretically that our local subgraphs also reserve a great deal of high-order graph structure features related to link existence. Another key feature is that our GNN can naturally incorporate latent features and explicit features. It is achieved by concatenating node embeddings (latent features) and node attributes (explicit features) in the node information matrix for each subgraph, thus combining the three types of features to enhance GNN learning. Through extensive experiments, SEAL shows unprecedentedly strong performance against a wide range of baseline methods, including various link prediction heuristics and network embedding methods.
Real-Time Bidding with Multi-Agent Reinforcement Learning in Display Advertising
Real-time advertising allows advertisers to bid for each impression for a visiting user. To optimize a specific goal such as maximizing the revenue led by ad placements, advertisers not only need to estimate the relevance between the ads and user’s interests, but most importantly require a strategic response with respect to other advertisers bidding in the market. In this paper, we formulate bidding optimization with multi-agent reinforcement learning. To deal with a large number of advertisers, we propose a clustering method and assign each cluster with a strategic bidding agent. A practical Distributed Coordinated Multi-Agent Bidding (DCMAB) has been proposed and implemented to balance the tradeoff between the competition and cooperation among advertisers. The empirical study on our industry-scaled real-world data has demonstrated the effectiveness of our modeling methods. Our results show that a cluster based bidding would largely outperform single-agent and bandit approaches, and the coordinated bidding achieves better overall objectives than the purely self-interested bidding agents.
L1-Norm Batch Normalization for Efficient Training of Deep Neural Networks
Batch Normalization (BN) has been proven to be quite effective at accelerating and improving the training of deep neural networks (DNNs). However, BN brings additional computation, consumes more memory and generally slows down the training process by a large margin, which aggravates the training effort. Furthermore, the nonlinear square and root operations in BN also impede the low bit-width quantization techniques, which draws much attention in deep learning hardware community. In this work, we propose an L1-norm BN (L1BN) with only linear operations in both the forward and the backward propagations during training. L1BN is shown to be approximately equivalent to the original L2-norm BN (L2BN) by multiplying a scaling factor. Experiments on various convolutional neural networks (CNNs) and generative adversarial networks (GANs) reveal that L1BN maintains almost the same accuracies and convergence rates compared to L2BN but with higher computational efficiency. On FPGA platform, the proposed signum and absolute operations in L1BN can achieve 1.5

speedup and save 50\% power consumption, compared with the original costly square and root operations, respectively. This hardware-friendly normalization method not only surpasses L2BN in speed, but also simplify the hardware design of ASIC accelerators with higher energy efficiency. Last but not the least, L1BN promises a fully quantized training of DNNs, which is crucial to future adaptive terminal devices.
Matching Convolutional Neural Networks without Priors about Data
We propose an extension of Convolutional Neural Networks (CNNs) to graph-structured data, including strided convolutions and data augmentation on graphs. Our method matches the accuracy of state-of-the-art CNNs when applied on images, without any prior about their 2D regular structure. On fMRI data, we obtain a significant gain in accuracy compared with existing graph-based alternatives.
Blockchain Abstract Data Type
Blockchains (e.g. Bitcoin, Algorand, Byzcoin, Hyperledger, RedBelly etc) became a game changer in the distributed storage area due to their ability to mimic the functioning of a classical traditional ledger such as transparency and falsification-proof of documentation in an untrusted environment where the computation is distributed, the set of participants to the system are not known and it varies during the execution. However, the massive integration of distributed ledgers in industrial applications strongly depends on the formal guaranties of the quality of services offered by these applications, especially in terms of consistency. Our work continues the line of recent distributed computing community effort dedicated to the theoretical aspects of blockchains. This paper is the first to specify the distributed shared ledgers as a composition of \emph{abstract data types} all together with an hierarchy of \emph{consistency criteria} that formally characterizes the histories admissible for distributed programs that use them. Our work extends the consistency criteria theory with new consistency definitions that capture the eventual convergence process in blockchain systems. Furthermore, we map representative existing blockchains from both academia and industry in our framework. Finally, we identify the necessary communication conditions in order to implement the new defined consistency criteria.
A Mathematical Framework for Deep Learning in Elastic Source Imaging
An inverse elastic source problem with sparse measurements is of concern. A generic mathematical framework is proposed which incorporates a low- dimensional manifold regularization in the conventional source reconstruction algorithms thereby enhancing their performance with sparse datasets. It is rigorously established that the proposed framework is equivalent to the so-called \emph{deep convolutional framelet expansion} in machine learning literature for inverse problems. Apposite numerical examples are furnished to substantiate the efficacy of the proposed framework.
• Non-ergodic delocalized states for efficient population transfer within a narrow band of the energy landscape
• Constructing exact representations of quantum many-body systems with deep neural networks
• Reinforcement and Imitation Learning for Diverse Visuomotor Skills
• Conjugate Bayes for probit regression via unified skew-normals
• A Robust Real-Time Automatic License Plate Recognition based on the YOLO Detector
• Optimal Investment Decision Under Switching regimes of Subsidy Support
• i3PosNet: Instrument Pose Estimation from X-Ray
• Near-Linear Time Local Polynomial Nonparametric Estimation
• A graph-theoretic framework for algorithmic design of experiments
• Data-dependent PAC-Bayes priors via differential privacy
• Fractal Universality in Near-Threshold Magnetic Lanthanide Dimers
• Volatility estimation in fractional Ornstein-Uhlenbeck models
• ADMM for Multiaffine Constrained Optimization
• All nearest neighbor calculation based on Delaunay graphs
• Subsequential tightness of the maximum of two dimensional Ginzburg-Landau fields
• Aggregative Coarsening for Multilevel Hypergraph Partitioning
• MILE: A Multi-Level Framework for Scalable Graph Embedding
• Multiscale Planar Graph Generation
• On tradeoffs between width- and fill-like graph parameters
• Simultaneous cores with restrictions and a question of Zaleski and Zeilberger
• Partition-crossing hypergraphs
• Searching for and quantifying non-convexity of functions
• Bayesian shape modelling of cross-sectional geological data
• Selecting optimal subgroups for treatment using many covariates
• Optimizing over a Restricted Policy Class in Markov Decision Processes
• Shaping Influence and Influencing Shaping: A Computational Red Teaming Trust-based Swarm Intelligence Model
• ABC Samplers
• On the Suitability of $L_p$-norms for Creating and Preventing Adversarial Examples
• Translating and Segmenting Multimodal Medical Volumes with Cycle- and Shape-Consistency Generative Adversarial Network
• Learning Binary Latent Variable Models: A Tensor Eigenpair Approach
• Semantic segmentation of trajectories with agent models
• Computational Red Teaming in a Sudoku Solving Context: Neural Network Based Skill Representation and Acquisition
• Treedepth Bounds in Linear Colorings
• Sufficient variable screening via directional regression with censored response
• Propagation of chaos for the Keller-Segel equation over bounded domains
• A Multi-Disciplinary Review of Knowledge Acquisition Methods: From Human to Autonomous Eliciting Agents
• Single-View Food Portion Estimation: Learning Image-to-Energy Mappings Using Generative Adversarial Networks
• Hydrodynamic limits for long-range asymmetric interacting particle systems
• A guide to Brownian motion and related stochastic processes
• Probability Maximization with Random Linear Inequalities: Alternative Formulations and Stochastic Approximation Schemes
• Network Representation Using Graph Root Distributions
• A note on passing from a quasi-symmetric function expansion to a Schur function expansion of a symmetric function
• Simpler Specifications and Easier Proofs of Distributed Algorithms Using History Variables
• Adaptive sliding mode control without knowledge of uncertainty bounds
• Robust GANs against Dishonest Adversaries
• Boosting Cooperative Coevolution for Large Scale Optimization with a Fine-Grained Computation Resource Allocation Strategy
• Phenotype-based and Self-learning Inter-individual Sleep Apnea Screening with a Level IV Monitoring System
• Understanding and Enhancing the Transferability of Adversarial Examples
• Fully Dynamic Maximal Independent Set with Sublinear Update Time
• Robust Actor-Critic Contextual Bandit for Mobile Health (mHealth) Interventions
• Overview of Approximate Bayesian Computation
• Recurrent Residual Module for Fast Inference in Videos
• High-dimensional ABC
• Modelling and Analysis of Temporal Preference Drifts Using A Component-Based Factorised Latent Approach
• Network-Clustered Multi-Modal Bug Localization
• Online learning with kernel losses
• Sharp oracle inequalities for stationary points of nonconvex penalized M-estimators
• Cognitive Radar Antenna Selection via Deep Learning
• ReHAR: Robust and Efficient Human Activity Recognition
• Surrogate Model Assisted Cooperative Coevolution for Large Scale Optimization
• Accelerating Asynchronous Algorithms for Convex Optimization by Momentum Compensation
• Skew hook formula for $d$-complete posets
• A new class of refined Eulerian polynomials
• Train Feedfoward Neural Network with Layer-wise Adaptive Rate via Approximating Back-matching Propagation
• Generalized Binary Search For Split-Neighborly Problems
• How (Not) To Train Your Neural Network Using the Information Bottleneck Principle
• On multi-step prediction models for receding horizon control
• Large Deviation Principles for countable Markov shifts
• Gaussian meta-embeddings for efficient scoring of a heavy-tailed PLDA model
• Mixed Supervised Object Detection with Robust Objectness Transfer
• Time-sensitive Customer Churn Prediction based on PU Learning
• Quantifying Acoustophoretic Separation of Microparticle Populations by Mean-and-Covariance Dynamics for Gaussians in Mixture Models
• Bioinformatics and Medicine in the Era of Deep Learning
• Constructing Representative Scenarios to Approximate Robust Combinatorial Optimization Problems
• Optimal subspace codes in ${\rm PG}(4,q)$
• Identification of LTV Dynamical Models with Smooth or Discontinuous Time Evolution by means of Convex Optimization
• Polar codes for empirical coordination over noisy channels with strictly causal encoding
• How to generate all possible rational Wilf-Zeilberger pairs?
• Atoms for signed permutations
• Optimal Impulse Control of Dynamical Systems
• Human-in-the-Loop Synthesis for Partially Observable Markov Decision Processes
• Trimmed Lévy Processes and their Extremal Components
• Coarse to fine non-rigid registration: a chain of scale-specific neural networks for multimodal image alignment with application to remote sensing
• Cooperative MIMO Precoding with Distributed CSI: A Hierarchical Approach
• A unified framework for designing EPTAS’s for load balancing on parallel machines
• Estimates of Potential functions of random walks on $Z$ with zero mean and infinite variance and their applications
• Spatio-Temporal Graph Convolution for Skeleton Based Action Recognition
• Isomorphism classification of infinite Sierpinski carpet graphs
• Computing the Wiener index in Sierpinski carpet graphs
• Adversarial Active Learning for Deep Networks: a Margin Based Approach
• Graph-based Image Anomaly Detection
• Constructing graphs with limited resources
• Solving Inverse Computational Imaging Problems using Deep Pixel-level Prior
• On (shape-)Wilf-equivalence for words
• The Tutte polynomial via lattice point counting
• A unifying framework for the modelling and analysis of STR DNA samples arising in forensic casework
• On the random version of the Erdős matching conjecture
• Interval Linear Programming under Transformations: Optimal Solutions and Optimal Value Range
• $\ell_0$TV: A Sparse Optimization Method for Impulse Noise Image Restoration
• Reproducible Floating-Point Aggregation in RDBMSs
• Live Blog Corpus for Summarization
• Multiple structural transitions in interacting networks
• A Kolmogorov-Smirnov type test for two inter-dependent random variables
• Instance Optimal Decoding and the Restricted Isometry Property
• Discovering Bayesian Market Views for Intelligent Asset Allocation
• Multi-task Learning of Pairwise Sequence Classification Tasks Over Disparate Label Spaces
• Extracting V2V Encountering Scenarios from Naturalistic Driving Database
• The Price of Stability of Weighted Congestion Games
• Convolutional Neural Networks for Toxic Comment Classification
• Classifying Idiomatic and Literal Expressions Using Topic Models and Intensity of Emotions
• Breaking the $1/\sqrt{n}$ Barrier: Faster Rates for Permutation-based Models in Polynomial Time
• A Hybrid Word-Character Model for Abstractive Summarization
• Realization of shift graphs as disjointness graphs of 1-intersecting curves in the plane
• Real-World Repetition Estimation by Div, Grad and Curl
• Fusion of Multispectral Data Through Illumination-aware Deep Neural Networks for Pedestrian Detection
• Mono-Camera 3D Multi-Object Tracking Using Deep Learning Detections and PMBM Filtering
• Identifying groups of variables with the potential of being large simultaneously
• Spanning trees in a Claw-free graph whose stems have at most $k$ branch vertices
• Formal Semantics of the Language Cypher
• Neural Stereoscopic Image Style Transfer
• 3D Object Super-Resolution
• Deep Learning Architectures for Face Recognition in Video Surveillance
• Follow Up on Detecting Deficiencies: An Optimal Group Testing Algorithm
• Exact Simulation of reciprocal Archimedean copulas
• Optimization over the Boolean Hypercube via Sums of Nonnegative Circuit Polynomials
• A combinatorial characterization of Hurewicz cofibrations between finite topological spaces
• No-go for quantum seals
• Stochastic Control of Computation Offloading to a Helper with a Dynamically Loaded CPU
• Integrating Latent Classes in the Bayesian Shared Parameter Joint Model of Longitudinal and Survival Outcomes
• Pathwise mild solutions for quasilinear stochastic partial differential equations
• Simultaneous Traffic Sign Detection and Boundary Estimation using Convolutional Neural Network
• Golden Angle Modulation: Approaching the AWGN Capacity
• On optimal designs for non-regular models
• Loss Surfaces, Mode Connectivity, and Fast Ensembling of DNNs
• The Mirage of Action-Dependent Baselines in Reinforcement Learning
• Improving OCR Accuracy on Early Printed Books using Deep Convolutional Networks
• Coding Theory using Linear Complexity of Finite Sequences
• Generating High Quality Visible Images from SAR Images Using CNNs
• Improving OCR Accuracy on Early Printed Books by combining Pretraining, Voting, and Active Learning
• Parameterized Complexity of Diameter
• Domain Modelling in Computational Persuasion for Behaviour Change in Healthcare
• CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes
• Nonasymptotic Gaussian Approximation for Linear Systems with Stable Noise [Preliminary Version]
• Reconstruction of partially sampled multi-band images – Application to STEM-EELS imaging
• Asymptotic representation theory and the spectrum of a random geometric graph on a compact Lie group
• On Coded Caching with Heterogeneous Distortion Requirements
• Symmetric functions and the principal case of the Frankl-Füredi conjecture
Like this:
Like Loading...