Mining Sub-Interval Relationships In Time Series Data
Time-series data is being increasingly collected and stud- ied in several areas such as neuroscience, climate science, transportation, and social media. Discovery of complex patterns of relationships between individual time-series, using data-driven approaches can improve our understanding of real-world systems. While traditional approaches typically study relationships between two entire time series, many interesting relationships in real-world applications exist in small sub-intervals of time while remaining absent or feeble during other sub-intervals. In this paper, we define the notion of a sub-interval relationship (SIR) to capture inter- actions between two time series that are prominent only in certain sub-intervals of time. We propose a novel and efficient approach to find most interesting SIR in a pair of time series. We evaluate our proposed approach on two real-world datasets from climate science and neuroscience domain and demonstrated the scalability and computational efficiency of our proposed approach. We further evaluated our discovered SIRs based on a randomization based procedure. Our results indicated the existence of several such relationships that are statistically significant, some of which were also found to have physical interpretation.
Efficient GAN-Based Anomaly Detection
Generative adversarial networks (GANs) are able to model the complex highdimensional distributions of real-world data, which suggests they could be effective for anomaly detection. However, few works have explored the use of GANs for the anomaly detection task. We leverage recently developed GAN models for anomaly detection, and achieve state-of-the-art performance on image and network intrusion datasets, while being several hundred-fold faster at test time than the only published GAN-based method.
Statistical Reasoning: Choosing and Checking the Ingredients, Inferences Based on a Measure of Statistical Evidence with Some Applications
The features of a logically sound approach to a theory of statistical reasoning are discussed. A particular approach that satisfies these criteria is reviewed. This is seen to involve selection of a model, model checking, elicitation of a prior, checking the prior for bias, checking for prior-data conflict and estimation and hypothesis assessment inferences based on a measure of evidence. A long-standing anomalous example is resolved by this approach to inference and an application is made to a practical problem of considerable importance which, among other novel aspects of the analysis, involves the development of a relevant elicitation algorithm.
Characterizing and Learning Equivalence Classes of Causal DAGs under Interventions
We consider the problem of learning causal DAGs in the setting where both observational and interventional data is available. This setting is common in biology, where gene regulatory networks can be intervened on using chemical reagents or gene deletions. Hauser and B\’uhlmann (2012) previously characterized the identifiability of causal DAGs under perfect interventions, which eliminate dependencies between targeted variables and their direct causes. In this paper, we extend these identifiability results to general interventions, which may modify the dependencies between targeted variables and their causes without eliminating them. We define and characterize the interventional Markov equivalence class that can be identified from general (not necessarily perfect) intervention experiments. We also propose the first provably consistent algorithm for learning DAGs in this setting and evaluate our algorithm on simulated and biological datasets.
Directional and Causal Information Flow in EEG for Assessing Perceived Audio Quality
In this paper, electroencephalography (EEG) measurements are used to infer change in cortical functional connectivity in response to change in audio stimulus. Experiments are conducted wherein the EEG activity of human subjects is recorded as they listen to audio sequences whose quality varies with time. A causal information theoretic framework is then proposed to measure the information flow between EEG sensors appropriately grouped into different regions of interest (ROI) over the cortex. A new causal bidirectional information (CBI) measure is defined as an improvement over standard directed information measures for the purposes of identifying connectivity between ROIs in a generalized cortical network setting. CBI can be intuitively interpreted as a causal bidirectional modification of directed information, and inherently calculates the divergence of the observed data from a multiple access channel with feedback. Further, we determine the analytical relationship between the different causal measures and compare how well they are able to distinguish between the perceived audio quality. The connectivity results inferred indicate a significant change in the rate of information flow between ROIs as the subjects listen to different audio qualities, with CBI being the best in discriminating between the perceived audio quality, compared to using standard directed information measures.
Anomaly Detection using One-Class Neural Networks
We propose a one-class neural network (OC-NN) model to detect anomalies in complex data sets. OC-NN combines the ability of deep networks to extract progressively rich representation of data with the one-class objective of creating a tight envelope around normal data. The OC-NN approach breaks new ground for the following crucial reason: data representation in the hidden layer is driven by the OC-NN objective and is thus customized for anomaly detection. This is a departure from other approaches which use a hybrid approach of learning deep features using an autoencoder and then feeding the features into a separate anomaly detection method like one-class SVM (OC-SVM). The hybrid OC-SVM approach is suboptimal because it is unable to influence representational learning in the hidden layers. A comprehensive set of experiments demonstrate that on complex data sets (like CIFAR and PFAM), OC-NN significantly outperforms existing state-of-the-art anomaly detection methods.
Rare events and Poisson point processes
The aim of the present work is to show that the results obtained earlier on the approximation of distributions of sums of independent terms by the accompanying compound Poisson laws may be interpreted as rather sharp quantitative estimates for the closeness between the sample containing independent observations of rare events and the Poisson point process which is obtained after a Poissonization of the initial sample.
Analysis of Cause-Effect Inference via Regression Errors
We address the problem of inferring the causal relation between two variables by comparing the least-squares errors of the predictions in both possible causal directions. Under the assumption of an independence between the function relating cause and effect, the conditional noise distribution, and the distribution of the cause, we show that the errors are smaller in causal direction if both variables are equally scaled and the causal relation is close to deterministic. Based on this, we provide an easily applicable algorithm that only requires a regression in both possible causal directions and a comparison of the errors. The performance of the algorithm is compared with different related causal inference methods in various artificial and real-world data sets.
MAVIS: Managing Datacenters using Smartphones
Distributed monitoring plays a crucial role in managing the activities of cloud-based datacenters. System administrators have long relied on monitoring systems such as Nagios and Ganglia to obtain status alerts on their desktop-class machines. However, the popularity of mobile devices is pushing the community to develop datacenter monitoring solutions for smartphone-class devices. Here we lay out desirable characteristics of such smartphone-based monitoring and identify quantitatively the shortcomings from directly applying existing solutions to this domain. Then we introduce a possible design that addresses some of these shortcomings and provide results from an early prototype, called MAVIS, using one month of monitoring data from approximately 3,000 machines hosted by Purdue’s central IT organization.
Towards Ultra-High Performance and Energy Efficiency of Deep Learning Systems: An Algorithm-Hardware Co-Optimization Framework
Hardware accelerations of deep learning systems have been extensively investigated in industry and academia. The aim of this paper is to achieve ultra-high energy efficiency and performance for hardware implementations of deep neural networks (DNNs). An algorithm-hardware co-optimization framework is developed, which is applicable to different DNN types, sizes, and application scenarios. The algorithm part adopts the general block-circulant matrices to achieve a fine-grained tradeoff between accuracy and compression ratio. It applies to both fully-connected and convolutional layers and contains a mathematically rigorous proof of the effectiveness of the method. The proposed algorithm reduces computational complexity per layer from O(

) to O(

) and storage complexity from O(
) to O(

), both for training and inference. The hardware part consists of highly efficient Field Programmable Gate Array (FPGA)-based implementations using effective reconfiguration, batch processing, deep pipelining, resource re-using, and hierarchical control. Experimental results demonstrate that the proposed framework achieves at least 152X speedup and 71X energy efficiency gain compared with IBM TrueNorth processor under the same test accuracy. It achieves at least 31X energy efficiency gain compared with the reference FPGA-based work.
PRUNE: Dynamic and Decidable Dataflow for Signal Processing on Heterogeneous Platforms
The majority of contemporary mobile devices and personal computers are based on heterogeneous computing platforms that consist of a number of CPU cores and one or more Graphics Processing Units (GPUs). Despite the high volume of these devices, there are few existing programming frameworks that target full and simultaneous utilization of all CPU and GPU devices of the platform. This article presents a dataflow-flavored Model of Computation (MoC) that has been developed for deploying signal processing applications to heterogeneous platforms. The presented MoC is dynamic and allows describing applications with data dependent run-time behavior. On top of the MoC, formal design rules are presented that enable application descriptions to be simultaneously dynamic and decidable. Decidability guarantees compile-time application analyzability for deadlock freedom and bounded memory. The presented MoC and the design rules are realized in a novel Open Source programming environment ‘PRUNE’ and demonstrated with representative application examples from the domains of image processing, computer vision and wireless communications. Experimental results show that the proposed approach outperforms the state-of-the-art in analyzability, flexibility and performance.
Differentially Private Generative Adversarial Network
Generative Adversarial Network (GAN) and its variants have recently attracted intensive research interests due to their elegant theoretical foundation and excellent empirical performance as generative models. These tools provide a promising direction in the studies where data availability is limited. One common issue in GANs is that the density of the learned generative distribution could concentrate on the training data points, meaning that they can easily remember training samples due to the high model complexity of deep networks. This becomes a major concern when GANs are applied to private or sensitive data such as patient medical records, and the concentration of distribution may divulge critical patient information. To address this issue, in this paper we propose a differentially private GAN (DPGAN) model, in which we achieve differential privacy in GANs by adding carefully designed noise to gradients during the learning procedure. We provide rigorous proof for the privacy guarantee, as well as comprehensive empirical evidence to support our analysis, where we demonstrate that our method can generate high quality data points at a reasonable privacy level.
Bridging Cognitive Programs and Machine Learning
While great advances are made in pattern recognition and machine learning, the successes of such fields remain restricted to narrow applications and seem to break down when training data is scarce, a shift in domain occurs, or when intelligent reasoning is required for rapid adaptation to new environments. In this work, we list several of the shortcomings of modern machine-learning solutions, specifically in the contexts of computer vision and in reinforcement learning and suggest directions to explore in order to try to ameliorate these weaknesses.
CapsuleGAN: Generative Adversarial Capsule Network
We present Generative Adversarial Capsule Network (CapsuleGAN), a framework that uses capsule networks (CapsNets) instead of the standard convolutional neural networks (CNNs) as discriminators within the generative adversarial network (GAN) setting, while modeling image data. We provide guidelines for designing CapsNet discriminators and the updated GAN objective function, which incorporates the CapsNet margin loss, for training CapsuleGAN models. We show that CapsuleGAN outperforms convolutional-GAN at modeling image data distribution on the MNIST dataset of handwritten digits, evaluated on the generative adversarial metric and at semi-supervised image classification.
Towards Principled Design of Deep Convolutional Networks: Introducing SimpNet
Major winning Convolutional Neural Networks (CNNs), such as VGGNet, ResNet, DenseNet, \etc, include tens to hundreds of millions of parameters, which impose considerable computation and memory overheads. This limits their practical usage in training and optimizing for real-world applications. On the contrary, light-weight architectures, such as SqueezeNet, are being proposed to address this issue. However, they mainly suffer from low accuracy, as they have compromised between the processing power and efficiency. These inefficiencies mostly stem from following an ad-hoc designing procedure. In this work, we discuss and propose several crucial design principles for an efficient architecture design and elaborate intuitions concerning different aspects of the design procedure. Furthermore, we introduce a new layer called {\it SAF-pooling} to improve the generalization power of the network while keeping it simple by choosing best features. Based on such principles, we propose a simple architecture called {\it SimpNet}. We empirically show that SimpNet provides a good trade-off between the computation/memory efficiency and the accuracy solely based on these primitive but crucial principles. SimpNet outperforms the deeper and more complex architectures such as VGGNet, ResNet, WideResidualNet \etc, on several well-known benchmarks, while having 2 to 25 times fewer number of parameters and operations. We obtain state-of-the-art results (in terms of a balance between the accuracy and the number of involved parameters) on standard datasets, such as CIFAR10, CIFAR100, MNIST and SVHN. The implementations are available at \href{url}{
https://…/SimpNet}.
Machine learning for Internet of Things data analysis: A survey
Rapid developments in hardware, software, and communication technologies have allowed the emergence of Internet-connected sensory devices that provide observation and data measurement from the physical world. By 2020, it is estimated that the total number of Internet-connected devices being used will be between 25 and 50 billion. As the numbers grow and technologies become more mature, the volume of data published will increase. Internet-connected devices technology, referred to as Internet of Things (IoT), continues to extend the current Internet by providing connectivity and interaction between the physical and cyber worlds. In addition to increased volume, the IoT generates Big Data characterized by velocity in terms of time and location dependency, with a variety of multiple modalities and varying data quality. Intelligent processing and analysis of this Big Data is the key to developing smart IoT applications. This article assesses the different machine learning methods that deal with the challenges in IoT data by considering smart cities as the main use case. The key contribution of this study is presentation of a taxonomy of machine learning algorithms explaining how different techniques are applied to the data in order to extract higher level information. The potential and challenges of machine learning for IoT data analytics will also be discussed. A use case of applying Support Vector Machine (SVM) on Aarhus Smart City traffic data is presented for a more detailed exploration.
HybridSVD: When Collaborative Information is Not Enough
We propose a hybrid algorithm for top-
recommendation task that allows to incorporate both user and item side information within the standard collaborative filtering approach. The algorithm extends PureSVD — one of the state-of-the-art latent factor models — by exploiting a generalized formulation of the singular value decomposition. This allows to inherit key advantages of the classical algorithm such as highly efficient Lanczos-based optimization procedure, minimal parameter tuning during a model selection phase and a quick folding-in computation to generate recommendations instantly even in a highly dynamic online environment. Within the generalized formulation itself we provide an efficient scheme for side information fusion which avoids undesirable computational overhead and addresses the scalability question. Evaluation of the model is performed in both standard and cold-start scenarios using the datasets with different sparsity levels. We demonstrate in which cases our approach outperforms conventional methods and also provide some intuition on when it may give no significant improvement.
RadialGAN: Leveraging multiple datasets to improve target-specific predictive models using Generative Adversarial Networks
Training complex machine learning models for prediction often requires a large amount of data that is not always readily available. Leveraging these external datasets from related but different sources is therefore an important task if good predictive models are to be built for deployment in settings where data can be rare. In this paper we propose a novel approach to the problem in which we use multiple GAN architectures to learn to translate from one dataset to another, thereby allowing us to effectively enlarge the target dataset, and therefore learn better predictive models than if we simply used the target dataset. We show the utility of such an approach, demonstrating that our method improves the prediction performance on the target domain over using just the target dataset and also show that our framework outperforms several other benchmarks on a collection of real-world medical datasets.
DA-GAN: Instance-level Image Translation by Deep Attention Generative Adversarial Networks (with Supplementary Materials)
Unsupervised image translation, which aims in translating two independent sets of images, is challenging in discovering the correct correspondences without paired data. Existing works build upon Generative Adversarial Network (GAN) such that the distribution of the translated images are indistinguishable from the distribution of the target set. However, such set-level constraints cannot learn the instance-level correspondences (e.g. aligned semantic parts in object configuration task). This limitation often results in false positives (e.g. geometric or semantic artifacts), and further leads to mode collapse problem. To address the above issues, we propose a novel framework for instance-level image translation by Deep Attention GAN (DA-GAN). Such a design enables DA-GAN to decompose the task of translating samples from two sets into translating instances in a highly-structured latent space. Specifically, we jointly learn a deep attention encoder, and the instancelevel correspondences could be consequently discovered through attending on the learned instance pairs. Therefore, the constraints could be exploited on both set-level and instance-level. Comparisons against several state-ofthe- arts demonstrate the superiority of our approach, and the broad application capability, e.g, pose morphing, data augmentation, etc., pushes the margin of domain translation problem.
Tiny SSD: A Tiny Single-shot Detection Deep Convolutional Neural Network for Real-time Embedded Object Detection
Object detection is a major challenge in computer vision, involving both object classification and object localization within a scene. While deep neural networks have been shown in recent years to yield very powerful techniques for tackling the challenge of object detection, one of the biggest challenges with enabling such object detection networks for widespread deployment on embedded devices is high computational and memory requirements. Recently, there has been an increasing focus in exploring small deep neural network architectures for object detection that are more suitable for embedded devices, such as Tiny YOLO and SqueezeDet. Inspired by the efficiency of the Fire microarchitecture introduced in SqueezeNet and the object detection performance of the single-shot detection macroarchitecture introduced in SSD, this paper introduces Tiny SSD, a single-shot detection deep convolutional neural network for real-time embedded object detection that is composed of a highly optimized, non-uniform Fire sub-network stack and a non-uniform sub-network stack of highly optimized SSD-based auxiliary convolutional feature layers designed specifically to minimize model size while maintaining object detection performance. The resulting Tiny SSD possess a model size of 2.3MB (~26X smaller than Tiny YOLO) while still achieving an mAP of 61.3% on VOC 2007 (~4.2% higher than Tiny YOLO). These experimental results show that very small deep neural network architectures can be designed for real-time object detection that are well-suited for embedded scenarios.
Goal-Oriented Optimal Design of Experiments for Large-Scale Bayesian Linear Inverse Problems
We develop a framework for goal oriented optimal design of experiments (GOODE) for large-scale Bayesian linear inverse problems governed by PDEs. This framework differs from classical Bayesian optimal design of experiments (ODE) in the following sense: we seek experimental designs that minimize the posterior uncertainty in a predicted quantity of interest (QoI) rather than the estimated parameter itself. This is suitable for scenarios in which the solution of an inverse problem is an intermediate step and the estimated parameter is then used to compute a prediction QoI. In such problems, a GOODE approach has two benefits: the designs can avoid wastage of experimental resources by a targeted collection of data, and the resulting design criteria are computationally easier to evaluate due to the often low dimensionality of prediction QoIs. We present two modified design criteria, A-GOODE and D-GOODE, which are natural analogues of classical Bayesian A- and D-optimal criteria. We analyze the connections to other ODE criteria, and provide interpretations for the GOODE criteria by using tools from information theory. Then, we develop an efficient gradient-based optimization framework for solving the GOODE optimization problems. Additionally, we present comprehensive numerical experiments testing the various aspects of the presented approach. The driving application is the optimal placement of sensors to identify the source of contaminants in a diffusion and transport problem. We enforce sparsity of the sensor placements using an
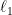
-norm penalty approach, and propose a practical strategy for specifying the associated penalty parameter.
Human and Smart Machine Co-Learning with Brain Computer Interface
Machine learning has become a very popular approach for cybernetics systems, and it has always been considered important research in the Computational Intelligence area. Nevertheless, when it comes to smart machines, it is not just about the methodologies. We need to consider systems and cybernetics as well as include human in the loop. The purpose of this article is as follows: (1) To integrate the open source Facebook AI Research (FAIR) DarkForest program of Facebook with Item Response Theory (IRT), to the new open learning system, namely, DDF learning system; (2) To integrate DDF Go with Robot namely Robotic DDF Go system; (3) To invite the professional Go players to attend the activity to play Go games on site with a smart machine. The research team will apply this technology to education, such as, playing games to enhance the children concentration on learning mathematics, languages, and other topics. With the detected brainwaves, the robot will be able to speak some words that are very much to the point for the students and to assist the teachers in classroom in the future.
Heron Inference for Bayesian Graphical Models
Bayesian graphical models have been shown to be a powerful tool for discovering uncertainty and causal structure from real-world data in many application fields. Current inference methods primarily follow different kinds of trade-offs between computational complexity and predictive accuracy. At one end of the spectrum, variational inference approaches perform well in computational efficiency, while at the other end, Gibbs sampling approaches are known to be relatively accurate for prediction in practice. In this paper, we extend an existing Gibbs sampling method, and propose a new deterministic Heron inference (Heron) for a family of Bayesian graphical models. In addition to the support for nontrivial distributability, one more benefit of Heron is that it is able to not only allow us to easily assess the convergence status but also largely improve the running efficiency. We evaluate Heron against the standard collapsed Gibbs sampler and state-of-the-art state augmentation method in inference for well-known graphical models. Experimental results using publicly available real-life data have demonstrated that Heron significantly outperforms the baseline methods for inferring Bayesian graphical models.
On the Decidability of Reachability in Linear Time-Invariant Systems
We consider the decidability of state-to-state reachability in linear time-invariant control systems, with control sets defined by boolean combinations of linear inequalities. Decidability of the sub-problem in which control sets are linear subspaces is a fundamental result in control theory. We first show that reachability is undecidable if the set of controls is a finite union of affine subspaces. We then consider two simple subclasses of control sets—unions of two affine subspaces and bounded convex polytopes respectively—and show that in these two cases the reachability problem for LTI systems is as hard as certain longstanding open decision problems concerning linear recurrence sequences. Finally we present some spectral assumptions on the transition matrix of an LTI system under which reachability becomes decidable with bounded convex polytopes as control sets.
Deep Echo State Networks for Diagnosis of Parkinson’s Disease
In this paper, we introduce a novel approach for diagnosis of Parkinson’s Disease (PD) based on deep Echo State Networks (ESNs). The identification of PD is performed by analyzing the whole time-series collected from a tablet device during the sketching of spiral tests, without the need for feature extraction and data preprocessing. We evaluated the proposed approach on a public dataset of spiral tests. The results of experimental analysis show that DeepESNs perform significantly better than shallow ESN model. Overall, the proposed approach obtains state-of-the-art results in the identification of PD on this kind of temporal data.
• Self-organization on Riemannian manifolds
• Four moments theorems on Markov chaos
• Gradient descent with identity initialization efficiently learns positive definite linear transformations by deep residual networks
• Examining the rank of Semi-definite Programming for Power System State Estimation
• A problem in control of elastodynamics with piezoelectric effects
• Extreme Value Analysis of Solar Flare Events
• Counting Homomorphisms to Trees Modulo a Prime
• Information-theoretic Limits for Community Detection in Network Models
• Sub-tree counts on hyperbolic random geometric graphs
• Modeling the Formation of Social Conventions in Multi-Agent Populations
• Scenarios: A New Representation for Complex Scene Understanding
• Simple Bounds for Transaction Costs
• The Mean-Field Approximation: Information Inequalities, Algorithms, and Complexity
• The Vertex Sample Complexity of Free Energy is Polynomial
• Fast, Trainable, Multiscale Denoising
• Interaction Matters: A Note on Non-asymptotic Local Convergence of Generative Adversarial Networks
• Implicit Robot-Human Communication in Adversarial and Collaborative Environments
• Discriminative Modeling of Social Influence for Prediction and Explanation in Event Cascades
• Reactive Reinforcement Learning in Asynchronous Environments
• Real-Time 3D Shape of Micro-Details
• On the Turán density of $\{1, 3\}$-Hypergraphs
• Scalable Inference for Space-Time Gaussian Cox Processes
• A Likelihood-Free Inference Framework for Population Genetic Data using Exchangeable Neural Networks
• A dimension reduction framework for personalized dose finding
• Ad Hoc Table Retrieval using Semantic Similarity
• Tractable and Robust Modeling of Building Flexibility Using Coarse Data
• Random Relation Algebras
• Matrix variate Birnbaum-Saunders distribution under elliptical models
• An Alternative View: When Does SGD Escape Local Minima?
• Semi-supervised multi-task learning for lung cancer diagnosis
• CREPE: A Convolutional Representation for Pitch Estimation
• Towards Realisation of Heterogeneous Earth-Observation Sensor Database Framework for the Sensor Observation Service based on PostGIS
• Building a Word Segmenter for Sanskrit Overnight
• Optimal Single Sample Tests for Structured versus Unstructured Network Data
• Tests about R multivariate simple linear models
• A Re-solving Heuristic for Dynamic Resource Allocation with Uniformly Bounded Revenue Loss
• HWNet v2: An Efficient Word Image Representation for Handwritten Documents
• Can Network Embedding of Distributional Thesaurus be Combined with Word Vectors for Better Representation?
• Multiple Object Trajectography Using Particle Swarm Optimization Combined to Hungarian Method
• Coplanar Low-Thrust Transfer with Eclipses Using Analytical Costate Guess
• Numerical solution of boundary value problems for the eikonal equation in an anisotropic medium
• Approximate Set Union Via Approximate Randomization
• Sentiment Analysis on Speaker Specific Speech Data
• Multi-Pass Streaming Algorithms for Monotone Submodular Function Maximization
• A New De-blurring Technique for License Plate Images with Robust Length Estimation
• HyP-DESPOT: A Hybrid Parallel Algorithm for Online Planning under Uncertainty
• Fusion of finite set distributions: Pointwise consistency and global cardinality
• A Deep Q-Learning Agent for the L-Game with Variable Batch Training
• Post Selection Inference with Incomplete Maximum Mean Discrepancy Estimator
• Persistence of Small Noise and Random initial conditions in the Wright-Fisher model
• Finding Global Optima in Nonconvex Stochastic Semidefinite Optimization with Variance Reduction
• Multiple boundary representations of $λ$-harmonic functions on trees
• Global-scale phylogenetic linguistic inference from lexical resources
• Geometric ergodicity of Polya-Gamma Gibbs sampler for Bayesian logistic regression with a flat prior
• Exact and Consistent Interpretation for Piecewise Linear Neural Networks: A Closed Form Solution
• A Collaborative Computer Aided Diagnosis (C-CAD) System with Eye-Tracking, Sparse Attentional Model, and Deep Learning
• An analysis of training and generalization errors in shallow and deep networks
• Lower Bounds on Sparse Spanners, Emulators, and Diameter-reducing shortcuts
• Hydrodynamic limit of rank-based models with common noise
• Similarities on Graphs: Kernels versus Proximity Measures
• Greening Geographical Power Allocation for Cellular Networks
• Nonconvex Matrix Factorization from Rank-One Measurements
• Unsupervised vehicle recognition using incremental reseeding of acoustic signatures
• Implementation of Neural Network and feature extraction to classify ECG signals
• Faster Algorithms for Integer Programs with Block Structure
• TabVec: Table Vectors for Classification of Web Tables
• Domination of Sample Maxima and Related Extremal Dependence Measures
• Nonparametric estimation of low rank matrix valued function
• Black-Box Reductions for Parameter-free Online Learning in Banach Spaces
• Unimodality of the independence polynomials of non-regular caterpillars
• Exact and Robust Conformal Inference Methods for Predictive Machine Learning With Dependent Data
• Improving the accuracy of the fast inverse square root algorithm
• Links between functions and subdifferentials
• Optimizing Interactive Systems with Data-Driven Objectives
• Out-of-sample extension of graph adjacency spectral embedding
• Nonparametric Testing under Random Projection
• Learning Adversarially Fair and Transferable Representations
• Counting linear extensions of restricted posets
• Autonomous Vehicle Speed Control for Safe Navigation of Occluded Pedestrian Crosswalk
• Large Neighborhood-Based Metaheuristic and Branch-and-Price for the Pickup and Delivery Problem with Split Loads
• Minimum length RNA folding trajectories
• A rank-based Cramér-von-Mises-type test for two samples
• A Pieri-type formula for $K$-$k$-Schur functions and a factorization formula
• Sequence-to-Sequence Prediction of Vehicle Trajectory via LSTM Encoder-Decoder Architecture
• Graphical Models for Non-Negative Data Using Generalized Score Matching
• Resolving Two Conjectures on Staircase Encodings and Boundary Grids of $132$ and $123$-avoiding permutations
• Optimal stopping, randomized stopping and singular control with partial information flow
• Spatial modelling with R-INLA: A review
• Optimizing Spectral Sums using Randomized Chebyshev Expansions
• Convergence of Online Mirror Descent Algorithms
• Geostatistical methods for disease mapping and visualization using data from spatio-temporally referenced prevalence surveys
• On Finding Dense Common Subgraphs
• On the c-concavity with respect to the quadratic cost on a manifold
• Efficient Sparse-Winograd Convolutional Neural Networks
• Node Centralities and Classification Performance for Characterizing Node Embedding Algorithms
• Linear-Time Algorithm for Long LCF with $k$ Mismatches
• Inductive Framework for Multi-Aspect Streaming Tensor Completion with Side Information
• Strong convergence rates of semi-discrete splitting approximations for stochastic Allen–Cahn equation
• Estimation of the linear fractional stable motion
• Scalable Alignment Kernels via Space-Efficient Feature Maps
• Efficient Gaussian Process Classification Using Polya-Gamma Data Augmentation
• Neural Networks with Finite Intrinsic Dimension have no Spurious Valleys
• How local in time is the no-arbitrage property under capital gains taxes ?
• Malliavin calculus for the stochastic Cahn-Hilliard / Allen Cahn equation with unbounded noise diffusion
• Training Big Random Forests with Little Resources
• Visual-Only Recognition of Normal, Whispered and Silent Speech
• An Overview of Physical Layer Security with Finite-Alphabet Signaling
• Using 3D Hahn Moments as A Computational Representation of ATS Drugs Molecular Structure
• Sums, products and ratios along the edges of a graph
• Emergence of oscillatory behaviors for excitable systems with noise and mean-field interaction, a slow-fast dynamics approach
• Improved TDNNs using Deep Kernels and Frequency Dependent Grid-RNNs
• Sim-To-Real Optimization Of Complex Real World Mobile Network with Imperfect Information via Deep Reinforcement Learning from Self-play
• Maximizing the number of edges in three-dimensional colored triangulations whose building blocks are balls
• End-to-end Audiovisual Speech Recognition
• Parabolic orbits of $2$-nilpotent elements for classical groups
• Estimating scale-invariant future in continuous time
• Improving Mild Cognitive Impairment Prediction via Reinforcement Learning and Dialogue Simulation
• DARTS: Deceiving Autonomous Cars with Toxic Signs
• Music Genre Classification using Masked Conditional Neural Networks
• Random time-changes and asymptotic results for a class of continuous-time Markov chains on integers with alternating rates
• Multicritical edge statistics for the momenta of fermions in non-harmonic traps
• Local Optimality and Generalization Guarantees for the Langevin Algorithm via Empirical Metastability
• Capacitated Dynamic Programming: Faster Knapsack and Graph Algorithms
• Deep neural decoders for near term fault-tolerant experiments
• Lifting Private Information Retrieval from Two to any Number of Messages
• Efficient Large-Scale Fleet Management via Multi-Agent Deep Reinforcement Learning
• Fast 5DOF Needle Tracking in iOCT
• Reducing Initial Cell-search Latency in mmWave Networks
• Rescaling nonsmooth optimization using BFGS and Shor updates
• Bayesian Uncertainty Estimation for Batch Normalized Deep Networks
• Circles and crossing planar compact convex sets
• A Generative Modeling Approach to Limited Channel ECG Classification
• Structured Label Inference for Visual Understanding
• Embedding distance graphs in finite field vector spaces
• Local Geometry of One-Hidden-Layer Neural Networks for Logistic Regression
• Robust Fitting in Computer Vision: Easy or Hard?
• Recurrent Binary Embedding for GPU-Enabled Exhaustive Retrieval from Billion-Scale Semantic Vectors
• Memorize or generalize? Searching for a compositional RNN in a haystack
• Online Convex Optimization for Cumulative Constraints
• A Closed-form Solution to Photorealistic Image Stylization
• A multivariate Berry–Esseen theorem with explicit constants
• Simultaneous Modeling of Multiple Complications for Risk Profiling in Diabetes Care
• An Efficient Local Search for the Minimum Independent Dominating Set Problem
• Optimal leader selection and demotion in leader-follower multi-agent systems
• Accelerated Primal-Dual Policy Optimization for Safe Reinforcement Learning
• Finite-Length Construction of High Performance Spatially-Coupled Codes via Optimized Partitioning and Lifting
• Optimal Graph Laplacian
• Committee Scoring Rules: Axiomatic Characterization and Hierarchy
• A positive fraction mutually avoiding sets theorem
• Robust Estimation via Robust Gradient Estimation
• Recommendations with Negative Feedback via Pairwise Deep Reinforcement Learning
• BDA-PCH: Block-Diagonal Approximation of Positive-Curvature Hessian for Training Neural Networks
• Gallai-Ramsey numbers of $C_9$ and $C_{11}$
• On the Optimization of Deep Networks: Implicit Acceleration by Overparameterization
• Reconfiguration of Colorable Sets in Classes of Perfect Graphs
• Modulation Design for Wireless Information and Power Transfer with Nonlinear Energy Harvester Modeling
• Image Forensics: Detecting duplication of scientific images with manipulation-invariant image similarity
• Subspace Network: Deep Multi-Task Censored Regression for Modeling Neurodegenerative Diseases
• Salient Object Detection by Lossless Feature Reflection
• Discrepancy Analysis of a New Randomized Diffusion Algorithm for Weighted Round Matrices
• Average Behavior of Minimal Free Resolutions of Monomial Ideals
• Link Selection for Secure Cooperative Networks with Buffer-Aided Relaying
• Optimal Beamforming for Physical Layer Security in MISO Wireless Networks
• Upper and lower bounds for dynamic data structures on strings
• Weighted Linear Discriminant Analysis based on Class Saliency Information
• Are Generative Classifiers More Robust to Adversarial Attacks?
• Slowest kinetic modes revealed by metabasin renormalization
• A 4-Approximation Algorithm for k-Prize Collecting Steiner Tree Problems
• A Study of Position Bias in Digital Library Recommender Systems
• Power-of-$d$-Choices with Memory: Fluid Limit and Optimality
• Deep Residual Network for Joint Demosaicing and Super-Resolution
• The exact asymptotics for hitting probability of a remote orthant by a multivariate Lévy process: the Cramér case
• Oscillation death induced by time-varying network
• Strong Convexity in Stochastic Programs with Deviation Risk Measures
• A Machine Learning Approach to Air Traffic Route Choice Modelling
• Closing the loop on multisensory interactions: A neural architecture for multisensory causal inference and recalibration
• Singular weighted Sobolev spaces and diffusion processes: an example (due to V.V. Zhikov)
• Learning High-level Representations from Demonstrations
• On the computation of Shannon Entropy from Counting Bloom Filters
• $PI$-eigenfunctions of the Star graphs
• Before Name-calling: Dynamics and Triggers of Ad Hominem Fallacies in Web Argumentation
• Ensemble computation approach to the Hough transform
• A Natural Generalization of Stable Matching Solved via New Insights into Ideal Cuts
• On some random walk problems
• Osteoarthritis Disease Detection System using Self Organizing Maps Method based on Ossa Manus X-Ray
• Robustness of Rotation-Equivariant Networks to Adversarial Perturbations
• Optical tristability and ultrafast Fano switching in nonlinear magneto-plasmonic nanoparticles
• Maximal Exploration of Trees with Energy-Constrained Agents
• On the (in)efficiency of MFG equilibria
• Finding Influential Training Samples for Gradient Boosted Decision Trees
• Simultaneous Compression and Quantization: A Joint Approach for Efficient Unsupervised Hashing
• Control of active power for synchronization and transient stability of power grids
• Matrix Exponential Learning for Resource Allocation with Low Informational Exchange
• Tied Multitask Learning for Neural Speech Translation
• Multi-task, multi-label and multi-domain learning with residual convolutional networks for emotion recognition
• The infinite two-sided loop-erased random walk
• Frequency-Selective Hybrid Beamforming Based on Implicit CSI for Millimeter Wave Systems
• On a new Sheffer class of polynomials related to normal product distribution
• Martingale representation for degenerate diffusions
• A Simple Parallel and Distributed Sampling Technique: Local Glauber Dynamics
• Degeneration in VAE: in the Light of Fisher Information Loss
• Large Scale Automated Forecasting for Monitoring Network Safety and Security
• Further results on random cubic planar graphs
• On Local Distributed Sampling and Counting
• Level convexity as a necessary condition for the relaxation of $L^\infty$-functionals
• Inducibility of Topological Trees
• The Complexity of Drawing a Graph in a Polygonal Region
• Cellular switches orchestrate rhythmic circuits
• Towards Improving Brandes’ Algorithm for Betweenness Centrality
• Discovering Effect Modification and Randomization Inference in Air Pollution Studies
• Sensitivity analyses for average treatment effects when outcome is censored by death in instrumental variable models
• Multithreading for the expression-dag-based number type Real_algebraic
• Disentangling 3D Pose in A Dendritic CNN for Unconstrained 2D Face Alignment
• Two Algorithms to Compute the Maximal Symmetry Group
• Learning Representative Temporal Features for Action Recognition
• When are permutation invariants Cohen-Macaulay over all fields?
• Distributed Recoloring
• Environmental feedback drives cooperation in spatial social dilemmas
• Breaking the Linear-Memory Barrier in MPC: Fast MIS on Trees with $n^{\eps}$ Memory per Machine
• Tail bounds for volume sampled linear regression
• Energy efficiency optimization in MIMO interference channels: A successive pseudoconvex approximation approach
• Network Lifetime Maximization for Cellular-Based M2M Networks
• One-dimensional System Arising in Stochastic Gradient Descent
Like this:
Like Loading...