Deep learning for inferring cause of data anomalies
Deep Reinforcement Learning for Multi-Resource Multi-Machine Job Scheduling
Adversarial Attacks Beyond the Image Space
Verifying Neural Networks with Mixed Integer Programming
The Promise and Peril of Human Evaluation for Model Interpretability
Learning to Organize Knowledge with N-Gram Machines
Leave no Trace: Learning to Reset for Safe and Autonomous Reinforcement Learning
Tree-Structured Boosting: Connections Between Gradient Boosted Stumps and Full Decision Trees
FluidNets: Fast & Simple Resource-Constrained Structure Learning of Deep Networks
Interleaver Design for Deep Neural Networks
Decentralized High-Dimensional Bayesian Optimization with Factor Graphs
Prior-aware Dual Decomposition: Document-specific Topic Inference for Spectral Topic Models
Structured Stein Variational Inference for Continuous Graphical Models
Classification with Costly Features using Deep Reinforcement Learning
Deep Approximately Orthogonal Nonnegative Matrix Factorization for Clustering
Bidirectional Conditional Generative Adversarial Networks
 ) conditioned on both latent variables (
) conditioned on both latent variables ( ) and known auxiliary information (
) and known auxiliary information ( ). Another GAN variant, Bidirectional GAN (BiGAN) is a recently developed framework for learning the inverse mapping from to through an encoder trained simultaneously with the generator and the discriminator of an unconditional GAN. We propose the Bidirectional Conditional GAN (BCGAN), which combines cGANs and BiGANs into a single framework with an encoder that learns inverse mappings from to both and , trained simultaneously with the conditional generator and discriminator in an end-to-end setting. We present crucial techniques for training BCGANs, which incorporate an extrinsic factor loss along with an associated dynamically-tuned importance weight. As compared to other encoder-based GANs, BCGANs not only encode more accurately but also utilize and more effectively and in a more disentangled way to generate data samples.
). Another GAN variant, Bidirectional GAN (BiGAN) is a recently developed framework for learning the inverse mapping from to through an encoder trained simultaneously with the generator and the discriminator of an unconditional GAN. We propose the Bidirectional Conditional GAN (BCGAN), which combines cGANs and BiGANs into a single framework with an encoder that learns inverse mappings from to both and , trained simultaneously with the conditional generator and discriminator in an end-to-end setting. We present crucial techniques for training BCGANs, which incorporate an extrinsic factor loss along with an associated dynamically-tuned importance weight. As compared to other encoder-based GANs, BCGANs not only encode more accurately but also utilize and more effectively and in a more disentangled way to generate data samples.
Better Agnostic Clustering Via Relaxed Tensor Norms
 -means clustering based on sum-of-squares norms, a relaxation of the injective tensor norm that is efficiently computable using the Sum-of-Squares algorithm. We give an algorithm based on this relaxation that recovers a faithful approximation to the true means in the given data whenever the low-degree moments of the points in each cluster have bounded sum-of-squares norms. We then prove a sharp upper bound on the sum-of-squares norms for moment tensors of any distribution that satisfies the \emph{Poincare inequality}. The Poincare inequality is a central inequality in probability theory, and a large class of distributions satisfy it including Gaussians, product distributions, strongly log-concave distributions, and any sum or uniformly continuous transformation of such distributions. As an immediate corollary, for any
-means clustering based on sum-of-squares norms, a relaxation of the injective tensor norm that is efficiently computable using the Sum-of-Squares algorithm. We give an algorithm based on this relaxation that recovers a faithful approximation to the true means in the given data whenever the low-degree moments of the points in each cluster have bounded sum-of-squares norms. We then prove a sharp upper bound on the sum-of-squares norms for moment tensors of any distribution that satisfies the \emph{Poincare inequality}. The Poincare inequality is a central inequality in probability theory, and a large class of distributions satisfy it including Gaussians, product distributions, strongly log-concave distributions, and any sum or uniformly continuous transformation of such distributions. As an immediate corollary, for any  , we obtain an efficient algorithm for learning the means of a mixture of arbitrary \Poincare distributions in
, we obtain an efficient algorithm for learning the means of a mixture of arbitrary \Poincare distributions in 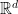 in time
in time 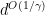 so long as the means have separation
so long as the means have separation 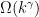 . This in particular yields an algorithm for learning Gaussian mixtures with separation , thus partially resolving an open problem of Regev and Vijayaraghavan \citet{regev2017learning}. Our algorithm works even in the outlier-robust setting where an
. This in particular yields an algorithm for learning Gaussian mixtures with separation , thus partially resolving an open problem of Regev and Vijayaraghavan \citet{regev2017learning}. Our algorithm works even in the outlier-robust setting where an  fraction of arbitrary outliers are added to the data, as long as the fraction of outliers is smaller than the smallest cluster. We, therefore, obtain results in the strong agnostic setting where, in addition to not knowing the distribution family, the data itself may be arbitrarily corrupted.
fraction of arbitrary outliers are added to the data, as long as the fraction of outliers is smaller than the smallest cluster. We, therefore, obtain results in the strong agnostic setting where, in addition to not knowing the distribution family, the data itself may be arbitrarily corrupted.
• Recovering Lexicographic Triangulations
• Fusing Bird View LIDAR Point Cloud and Front View Camera Image for Deep Object Detection
• Learning Discriminative Affine Regions via Discriminability
• Maximum-norm a posteriori error estimates for an optimal control problem
• Manifold learning with bi-stochastic kernels
• Integrating Disparate Sources of Experts for Robust Image Denoising
• Techniques for proving Asynchronous Convergence results for Markov Chain Monte Carlo methods
• Quarnet inference rules for level-1 networks
• 3D object classification and retrieval with Spherical CNNs
• Phonological (un)certainty weights lexical activation
• Information Gathering with Peers: Submodular Optimization with Peer-Prediction Constraints
• Principal Manifolds of Middles: A Framework and Estimation Procedure Using Mixture Densities
• Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks
• Deep supervised learning using local errors
• Improving particle filter performance with a generalized random field model of observation errors
• Backward induction in presence of cycles
• Generation and Consolidation of Recollections for Efficient Deep Lifelong Learning
• Addressing Expensive Multi-objective Games with Postponed Preference Articulation via Memetic Co-evolution
• Image Registration of Very Large Images via Genetic Programming
• A Two-Phase Genetic Algorithm for Image Registration
• Genetic Algorithm-Based Solver for Very Large Multiple Jigsaw Puzzles of Unknown Dimensions and Piece Orientation
• An Automatic Solver for Very Large Jigsaw Puzzles Using Genetic Algorithms
• A Generalized Genetic Algorithm-Based Solver for Very Large Jigsaw Puzzles of Complex Types
• A Genetic Algorithm-Based Solver for Very Large Jigsaw Puzzles
• Approximate Gradient Coding via Sparse Random Graphs
• Separable discrete functions: recognition and sufficient conditions
• Game Theoretic Analysis of Auction Mechanisms Modeled by Constrained Optimization Problems
• Excitation Backprop for RNNs
• Machine Learning Approaches for Traffic Volume Forecasting: A Case Study of the Moroccan Highway Network
• Exact alignment recovery for correlated Erdos Renyi graphs
• A primal-dual algorithm with optimal stepsizes and its application in decentralized consensus optimization
• Measuring Territorial Control in Civil Wars Using Hidden Markov Models: A Data Informatics-Based Approach
• Learning Aggregated Transmission Propagation Networks for Haze Removal and Beyond
• MinimalRNN: Toward More Interpretable and Trainable Recurrent Neural Networks
• Enumeration of Some Closed Knight Paths
• Co-attending Free-form Regions and Detections with Multi-modal Multiplicative Feature Embedding for Visual Question Answering
• Prediction Scores as a Window into Classifier Behavior
• Short proofs for generalizations of the Lovász Local Lemma: Shearer’s condition and cluster expansion
• Scalable Relaxations of Sparse Packing Constraints: Optimal Biocontrol in Predator-Prey Network
• Reduction of total-cost and average-cost MDPs with weakly continuous transition probabilities to discounted MDPs
• Fast Monte Carlo Markov chains for Bayesian shrinkage models with random effects
• A Color Quantization Optimization Approach for Image Representation Learning
• Household poverty classification in data-scarce environments: a machine learning approach
• Convex Set of Doubly Substochastic Matrices
• Acquiring Common Sense Spatial Knowledge through Implicit Spatial Templates
• A novel Topological Model for Nonlinear Analysis and Prediction for Observations with Recurring Patterns
• Low-dimensional Embeddings for Interpretable Anchor-based Topic Inference
• Continuous-state branching processes with competition: Duality and Reflection at Infinity
• Transferable Semi-supervised Semantic Segmentation
• Random Access in Massive MIMO by Exploiting Timing Offsets and Excess Antennas
• Proximal Gradient Method with Extrapolation and Line Search for a Class of Nonconvex and Nonsmooth Problems
• Neural Network Reinforcement Learning for Audio-Visual Gaze Control in Human-Robot Interaction
• Genetic Algorithms for Mentor-Assisted Evaluation Function Optimization
• Simulating Human Grandmasters: Evolution and Coevolution of Evaluation Functions
• Expert-Driven Genetic Algorithms for Simulating Evaluation Functions
• Evaluating Roles of Central Users in Online Communication Networks: A Case Study of #PanamaLeaks
• Local Clustering Coefficient of Spatial Preferential Attachment Model
• DLTK: State of the Art Reference Implementations for Deep Learning on Medical Images
• Style Transfer in Text: Exploration and Evaluation
• From Common to Special: When Multi-Attribute Learning Meets Personalized Opinions
• Bio-Inspired Local Information-Based Control for Probabilistic Swarm Distribution Guidance
• Anonymous Hedonic Game for Task Allocation in a Large-Scale Multiple Agent System
• Automatically Extracting Action Graphs from Materials Science Synthesis Procedures
• Learning Dynamics and the Co-Evolution of Competing Sexual Species
• Fission-fusion dynamics and group-size dependent composition in heterogeneous populations
• Fully Dynamic Almost-Maximal Matching: Breaking the Polynomial Barrier for Worst-Case Time Bounds
• Learning to select computations
• Is China Entering WTO or shijie maoyi zuzhi–a Corpus Study of English Acronyms in Chinese Newspapers
• Inversion of Tchebychev-Tchernov inequality
• Single-Shot Refinement Neural Network for Object Detection
• The Cultural Evolution of National Constitutions
• On the second largest Laplacian eigenvalue of graph
• Collective gradient sensing in fish schools
• Optimal Stopping for Interval Estimation in Bernoulli Trials
• Joint User Scheduling and Beam Selection Optimization for Beam-Based Massive MIMO Downlinks
• Gazing into the Abyss: Real-time Gaze Estimation
• Shifted tableaux crystals
• Superlinear Lower Bounds for Distributed Subgraph Detection
• Run, skeleton, run: skeletal model in a physics-based simulation
• The Bayes Lepski’s Method and Credible Bands through Volume of Tubular Neighborhoods
• Computational Results for Extensive-Form Adversarial Team Games
• Average-case Approximation Ratio of Scheduling without Payments
• Macdonald-positive specializations of the algebra of symmetric functions: Proof of the Kerov conjecture
• Robust Synthetic Control
• Node Profiles of Symmetric Digital Search Trees
• An extension to the theory of controlled Lagrangians using the Helmholtz conditions
• A novel total variation model based on kernel functions and its application
• Approximating geodesics via random points
• A systematic framework to discover pattern for web spam classification
• BPGrad: Towards Global Optimality in Deep Learning via Branch and Pruning
• The Strength of Multi-row Aggregation Cuts for Sign-pattern Integer Programs
• Cyclone: High Availability for Persistent Key Value Stores
• Intelligent Word Embeddings of Free-Text Radiology Reports
• Unsupervised Domain Adaptation for Semantic Segmentation with GANs
• How much is my car worth? A methodology for predicting used cars prices using Random Forest
• MIT Autonomous Vehicle Technology Study: Large-Scale Deep Learning Based Analysis of Driver Behavior and Interaction with Automation
• Enhanced Group Sparse Beamforming for Green Cloud-RAN: A Random Matrix Approach
• Sequential Randomized Matrix Factorization for Gaussian Processes: Efficient Predictions and Hyper-parameter Optimization
• Kill Two Birds with One Stone: Weakly-Supervised Neural Network for Image Annotation and Tag Refinement
• A note on quadratic approximations of logistic log-likelihoods
• Convergence Analysis of the Dynamics of a Special Kind of Two-Layered Neural Networks with $\ell_1$ and $\ell_2$ Regularization
• Probabilistic approach to quantum separation effect for Feynman-Kac semigroup
• Coherence-based Time Series Clustering for Brain Connectivity Visualization
• A Discourse-Level Named Entity Recognition and Relation Extraction Dataset for Chinese Literature Text
• MicroExpNet: An Extremely Small and Fast Model For Expression Recognition From Frontal Face Images
• A note on Hadamard fractional differential equations with varying coefficients and their applications in probability
• Incorporating Syntactic Uncertainty in Neural Machine Translation using a Forest-to-Seuqence Model
• Zero Dynamics for Port-Hamiltonian Systems
• Extremal graphs with respect to the total-eccentricity index
• Image-Image Domain Adaptation with Preserved Self-Similarity and Domain-Dissimilarity for Person Re-identification
• Mixed-integer linear representability, disjunctions, and Chvatal functions — modeling implications
• Universal Cycles of Restricted Words
• Normal Representations of Hyperplane Arrangements Over a Field with $1-ad$ Structure and Convex Positive Bijections
• Two-level schemes for the advection equation
• A Coordinate-wise Optimization Algorithm for Sparse Inverse Covariance Selection
• An Improved Oscillating-Error Classifier with Branching
• A Classifying Variational Autoencoder with Application to Polyphonic Music Generation
• An Approximating Control Design for Optimal Mixing by Stokes Flows
• A New Form of Williamson’s Product Theorem
• Morphisms of open games
• DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks
• Diverse and Accurate Image Description Using a Variational Auto-Encoder with an Additive Gaussian Encoding Space
• The destiny of constant structure discrete time closed semantic systems
• Node Balanced Steady States: Unifying and Generalizing Complex and Detailed Balanced Steady States
• On convergence rate for an infinite-channel queuing system with Poisson input flow
• Does mitigating ML’s disparate impact require disparate treatment?
• Estimation Considerations in Contextual Bandits
• Equiangular tight frames that contain regular simplices
• Second-Order Variational Analysis of Parametric Constraint and Variational Systems
• Superexponential estimates and weighted lower bounds for the square function
• Compression-Based Regularization with an Application to Multi-Task Learning
• Probabilistic and Combinatorial Interpretations of the Bernoulli Symbol
• Eigenvectors distribution and quantum unique ergodicity for deformed Wigner matrices
• A Double Parametric Bootstrap Test for Topic Models
• A note on quasi-convex functions
• The invariant measure and the flow associated to the $Φ^4_3$-quantum field model
• Modeling Epistemological Principles for Bias Mitigation in AI Systems: An Illustration in Hiring Decisions
• Deletion-Robust Submodular Maximization at Scale
• On the Stability of a N-class Aloha Network
• Hello Edge: Keyword Spotting on Microcontrollers
• CleanNet: Transfer Learning for Scalable Image Classifier Training with Label Noise
• Critique of Barbosa’s ‘P != NP Proof’
• Robust Non-line-of-sight Imaging with Single Photon Detectors
• Schlegel Diagram and Optimizable Immediate Snapshot Protocol
• Nonparametric Double Robustness
• Optimal binary linear locally repairable codes with disjoint repair groups
• On the Global Fluctuations of Block Gaussian Matrices
• Spectral-Spatial Feature Extraction and Classification by ANN Supervised with Center Loss in Hyperspectral Imagery
• On $e$-positivity and $e$-unimodality of chromatic quasisymmetric functions
• Interactive, Intelligent Tutoring for Auxiliary Constructions in Geometry Proofs
• Let Features Decide for Themselves: Feature Mask Network for Person Re-identification
• Dynamic Neural Program Embedding for Program Repair
• Parameter Reference Loss for Unsupervised Domain Adaptation
• On the Feasibility of Interference Alignment in Compounded MIMO Broadcast Channels with Antenna Correlation and Mixed User Classes
• Polyhedral parametrizations of canonical bases & cluster duality
• Non-reversible, tuning- and rejection-free Markov chain Monte Carlo via iterated random functions
• Is prioritized sweeping the better episodic control?
• On a stochastic Hardy-Littlewood-Sobolev inequality with application to Strichartz estimates for the white noise dispersion
• Block-Cyclic Stochastic Coordinate Descent for Deep Neural Networks
• Softening and Yielding of Soft Glassy Materials
• Method to Design UF-OFDM Filter and its Analysis
• A new class of tests for multinormality with i.i.d. and Garch data based on the empirical moment generating function
• End-to-end Trained CNN Encode-Decoder Networks for Image Steganography
• List-Decodable Robust Mean Estimation and Learning Mixtures of Spherical Gaussians
• Maximizing Non-monotone/Non-submodular Functions by Multi-objective Evolutionary Algorithms
• Lefschetz and Lower Bound theorems for Minkowski sums
• Model Extraction Warning in MLaaS Paradigm
• Generalized Dual Dynamic Programming for Infinite Horizon Problems in Continuous State and Action Spaces
• Linear-Complexity Relaxed Word Mover’s Distance with GPU Acceleration
• Finite Time Analysis of Optimal Adaptive Policies for Linear-Quadratic Systems
• Stochastic metamorphosis with template uncertainties
• Statistics of the Voronoi cell perimeter in large bi-pointed maps
• Tracking in Aerial Hyperspectral Videos using Deep Kernelized Correlation Filters
• MegDet: A Large Mini-Batch Object Detector
• Optical Character Recognition (OCR) for Telugu: Database, Algorithm and Application
• Face Attention Network: An effective Face Detector for the Occluded Faces
• Finite Horizon Robustness Analysis of LTV Systems Using Integral Quadratic Constraints
• On the optimality of the uniform random strategy
• Light-Head R-CNN: In Defense of Two-Stage Object Detector
• Fast BTG-Forest-Based Hierarchical Sub-sentential Alignment
• Evaluating the Performance of eMTC and NB-IoT for Smart City Applications
• A Separation Between Run-Length SLPs and LZ77
• Positive semi-definite embedding for dimensionality reduction and out-of-sample extensions
• Facets, Tiers and Gems: Ontology Patterns for Hypernormalisation
• Speech recognition for medical conversations
• Backscatter Communications for the Internet of Things: A Stochastic Geometry Approach
• Vision-and-Language Navigation: Interpreting visually-grounded navigation instructions in real environments
• Quantum Query Algorithms are Completely Bounded Forms
• Non-exchangeable random partition models for microclustering
• When Fourth Moments Are Enough
• Learning Steerable Filters for Rotation Equivariant CNNs
• Bitmap Filter: Speeding up Exact Set Similarity Joins with Bitwise Operations
• Optimization-Based Autonomous Racing of 1:43 Scale RC Cars
• Zero-shot Learning via Shared-Reconstruction-Graph Pursuit
• Solution of network localization problem with noisy distances and its convergence
• Performance of In-band Transmission of System Information in Massive MIMO Systems
• Cooperative Games With Bounded Dependency Degree
• Detection of Tooth caries in Bitewing Radiographs using Deep Learning
• A Note on Helffer-Sjöstrand Representation for A Ginzburg-Landau Process
• Cascaded Pyramid Network for Multi-Person Pose Estimation
• Proof Complexity Meets Algebra
• On DNA Codes using the Ring Z4 + wZ4
• Bayesian Active Edge Evaluation on Expensive Graphs
• Robust Decentralized Secondary Frequency Control in Power Systems: Merits and Trade-Offs
• Convergent Block Coordinate Descent for Training Tikhonov Regularized Deep Neural Networks
• Community detection with spiking neural networks for neuromorphic hardware
• Pixel-wise object tracking
• Wasserstein and Kolmogorov error bounds for variance-gamma approximation via Stein’s method I
• Spectral distribution of the free Jacobi process, revisited
• Adaptive M-QAM for Indoor Wireless Environments : Rate & Power Adaptation
• How morphological development can guide evolution
• V2V-PoseNet: Voxel-to-Voxel Prediction Network for Accurate 3D Hand and Human Pose Estimation from a Single Depth Map
• Non-Contextual Modeling of Sarcasm using a Neural Network Benchmark
• Disentangling Factors of Variation by Mixing Them
• Robust Seed Mask Generation for Interactive Image Segmentation
• Outliers in the spectrum for products of independent random matrices
• Informed proposals for local MCMC in discrete spaces
• Modular Continual Learning in a Unified Visual Environment
• Joint Object Category and 3D Pose Estimation from 2D Images
• Action Recognition with Coarse-to-Fine Deep Feature Integration and Asynchronous Fusion
• A local graph rewiring algorithm for sampling spanning trees
• Relaxed Oracles for Semi-Supervised Clustering
• On Convergence of Epanechnikov Mean Shift
• On tight cycles in hypergraphs
• A generalised framework for detailed classification of swimming paths inside the Morris Water Maze
• Subcritical multitype branching process in random environment
• Mixture Models, Robustness, and Sum of Squares Proofs
• Families of nested graphs with compatible symmetric-group actions
• Matrix Factorization for Nonparametric Multi-source Localization Exploiting Unimodal Properties
• SquishedNets: Squishing SqueezeNet further for edge device scenarios via deep evolutionary synthesis
• Glitch Classification and Clustering for LIGO with Deep Transfer Learning