Locally Optimal Control of Complex Networks
It has recently been shown that the minimum energy solution of the control problem for a linear system produces a control trajectory that is nonlocal. An issue then arises when the dynamics represents a linearization of the underlying nonlinear dynamics of the system where the linearization is only valid in a local region of the state space. Here we provide a solution to the problem of optimally controlling a linearized system by deriving a time-varying set that represents all possible control trajectories parameterized by time and energy. As long as the control action terminus is defined within this set, the control trajectory is guaranteed to be local. If the desired terminus of the control action is far from the initial state, a series of local control actions can be performed in series, re-linearizing the dynamics at each new position.
Verifying Equivalence of Database-Driven Applications
This paper addresses the problem of verifying equivalence between a pair of programs that operate over databases with different schemas. This problem is particularly important in the context of web applications, which typically undergo database refactoring either for performance or maintainability reasons. While web applications should have the same externally observable behavior before and after schema migration, there are no existing tools for proving equivalence of such programs. This paper takes a first step towards solving this problem by formalizing the equivalence and refinement checking problems for database-driven applications. We also propose a proof methodology based on the notion of bisimulation invariants over relational algebra with updates and describe a technique for synthesizing such bisimulation invariants. We have implemented the proposed technique in a tool called Mediator for verifying equivalence between database-driven applications written in our intermediate language and evaluate our tool on 21 benchmarks extracted from textbooks and real-world web applications. Our results show that the proposed methodology can successfully verify 20 of these benchmarks.
Solving the ‘false positives’ problem in fraud prediction
In this paper, we present an automated feature engineering based approach to dramatically reduce false positives in fraud prediction. False positives plague the fraud prediction industry. It is estimated that only 1 in 5 declared as fraud are actually fraud and roughly 1 in every 6 customers have had a valid transaction declined in the past year. To address this problem, we use the Deep Feature Synthesis algorithm to automatically derive behavioral features based on the historical data of the card associated with a transaction. We generate 237 features (>100 behavioral patterns) for each transaction, and use a random forest to learn a classifier. We tested our machine learning model on data from a large multinational bank and compared it to their existing solution. On an unseen data of 1.852 million transactions, we were able to reduce the false positives by 54% and provide a savings of 190K euros. We also assess how to deploy this solution, and whether it necessitates streaming computation for real time scoring. We found that our solution can maintain similar benefits even when historical features are computed once every 7 days.
Learning Discrete Weights Using the Local Reparameterization Trick
Recent breakthroughs in computer vision make use of large deep neural networks, utilizing the substantial speedup offered by GPUs. For applications running on limited hardware however, high precision real-time processing can still be a challenge. One approach to solve this problem is learning networks with binary or ternary weights, thus removing the need to calculate multiplications and significantly reduce memory size and access. In this work we introduce LR-nets (Local reparameterization networks), a new method for training neural networks with discrete weights using stochastic parameters. We show how a simple modification to the local reparameterization trick, previously used to train Gaussian distributed weights, allows us to train discrete weights. We tested our method on MNIST, CIFAR-10 and ImageNet, achieving state-of-the-art results compared to previous binary and ternary models.
Towards Black-box Iterative Machine Teaching
In this paper, we make an important step towards the black-box machine teaching by considering the cross-space teaching setting, where the teacher and the learner use different feature representations and the teacher can not fully observe the learner’s model. In such scenario, we study how the teacher is still able to teach the learner to achieve a faster convergence rate than the traditional passive learning. We propose an active teacher model that can actively query the learner (i.e., make the learner take exams) for estimating the learner’s status, and provide the sample complexity for both teaching and query, respectively. In the experiments, we compare the proposed active teacher with the omniscient teacher and verify the effectiveness of the active teacher model.
Stochastic Backward Euler: An Implicit Gradient Descent Algorithm for $k$-means Clustering
In this paper, we propose an implicit gradient descent algorithm for the classic

-means problem. The implicit gradient step or backward Euler is solved via stochastic fixed-point iteration, in which we randomly sample a mini-batch gradient in every iteration. It is the average of the fixed-point trajectory that is carried over to the next gradient step. We draw connections between the proposed stochastic backward Euler and the recent entropy stochastic gradient descent (Entropy-SGD) for improving the training of deep neural networks. Numerical experiments on various synthetic and real datasets show that the proposed algorithm finds the global minimum (or its neighborhood) with high probability, when given the correct number of clusters. The method provides better clustering results compared to
-means algorithms in the sense that it decreased the objective function (the cluster) and is much more robust to initialization.
Text Coherence Analysis Based on Deep Neural Network
In this paper, we propose a novel deep coherence model (DCM) using a convolutional neural network architecture to capture the text coherence. The text coherence problem is investigated with a new perspective of learning sentence distributional representation and text coherence modeling simultaneously. In particular, the model captures the interactions between sentences by computing the similarities of their distributional representations. Further, it can be easily trained in an end-to-end fashion. The proposed model is evaluated on a standard Sentence Ordering task. The experimental results demonstrate its effectiveness and promise in coherence assessment showing a significant improvement over the state-of-the-art by a wide margin.
A Novel Stochastic Stratified Average Gradient Method: Convergence Rate and Its Complexity
SGD (Stochastic Gradient Descent) is a popular algorithm for large scale optimization problems due to its low iterative cost. However, SGD can not achieve linear convergence rate as FGD (Full Gradient Descent) because of the inherent gradient variance. To attack the problem, mini-batch SGD was proposed to get a trade-off in terms of convergence rate and iteration cost. In this paper, a general CVI (Convergence-Variance Inequality) equation is presented to state formally the interaction of convergence rate and gradient variance. Then a novel algorithm named SSAG (Stochastic Stratified Average Gradient) is introduced to reduce gradient variance based on two techniques, stratified sampling and averaging over iterations that is a key idea in SAG (Stochastic Average Gradient). Furthermore, SSAG can achieve linear convergence rate of

at smaller storage and iterative costs, where
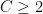
is the category number of training data. This convergence rate depends mainly on the variance between classes, but not on the variance within the classes. In the case of
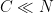
(

is the training data size), SSAG’s convergence rate is much better than SAG’s convergence rate of

. Our experimental results show SSAG outperforms SAG and many other algorithms.
A Generative Restricted Boltzmann Machine Based Method for High-Dimensional Motion Data Modeling
Many computer vision applications involve modeling complex spatio-temporal patterns in high-dimensional motion data. Recently, restricted Boltzmann machines (RBMs) have been widely used to capture and represent spatial patterns in a single image or temporal patterns in several time slices. To model global dynamics and local spatial interactions, we propose to theoretically extend the conventional RBMs by introducing another term in the energy function to explicitly model the local spatial interactions in the input data. A learning method is then proposed to perform efficient learning for the proposed model. We further introduce a new method for multi-class classification that can effectively estimate the infeasible partition functions of different RBMs such that RBM is treated as a generative model for classification purpose. The improved RBM model is evaluated on two computer vision applications: facial expression recognition and human action recognition. Experimental results on benchmark databases demonstrate the effectiveness of the proposed algorithm.
Seamless Paxos Coordinators
The Paxos algorithm requires a single correct coordinator process to operate. After a failure, the replacement of the coordinator may lead to a temporary unavailability of the application implemented atop Paxos. So far, this unavailability has been addressed by reducing the coordinator replacement rate through the use of stable coordinator selection algorithms. We have observed that the cost of recovery of the newly elected coordinator’s state is at the core of this unavailability problem. In this paper we present a new technique to manage coordinator replacement that allows the recovery to occur concurrently with new consensus rounds. Experimental results show that our seamless approach effectively solves the temporary unavailability problem, its adoption entails uninterrupted execution of the application. Our solution removes the restriction that the occurrence of coordinator replacements is something to be avoided, allowing the decoupling of the application execution from the accuracy of the mechanism used to choose a coordinator. This result increases the performance of the application even in the presence of failures, it is of special importance to the autonomous operation of replicated applications that have to adapt to varying network conditions and partial failures.
Deep Neural Network Approximation using Tensor Sketching
Deep neural networks are powerful learning models that achieve state-of-the-art performance on many computer vision, speech, and language processing tasks. In this paper, we study a fundamental question that arises when designing deep network architectures: Given a target network architecture can we design a smaller network architecture that approximates the operation of the target network? The question is, in part, motivated by the challenge of parameter reduction (compression) in modern deep neural networks, as the ever increasing storage and memory requirements of these networks pose a problem in resource constrained environments. In this work, we focus on deep convolutional neural network architectures, and propose a novel randomized tensor sketching technique that we utilize to develop a unified framework for approximating the operation of both the convolutional and fully connected layers. By applying the sketching technique along different tensor dimensions, we design changes to the convolutional and fully connected layers that substantially reduce the number of effective parameters in a network. We show that the resulting smaller network can be trained directly, and has a classification accuracy that is comparable to the original network.
Feature-Guided Black-Box Safety Testing of Deep Neural Networks
Despite the improved accuracy of deep neural networks, the discovery of adversarial examples has raised serious safety concerns. Most existing approaches for crafting adversarial examples necessitate some knowledge (architecture, parameters, etc) of the network at hand. In this paper, we focus on image classifiers and propose a feature-guided black-box approach to test the safety of deep neural networks that requires no such knowledge. Our algorithm employs object detection techniques such as SIFT (Scale Invariant Feature Transform) to extract features from an image. These features are converted into a mutable saliency distribution, where high probability is assigned to pixels that affect com- position of the image with respect to the human visual system. We formulate the crafting of adversarial examples as a two-player turn-based stochastic game, where the first player’s objective is to find an adversarial example by manipulating the features, and the second player can be cooperative, adversarial, or random. We show that, theoretically, the two-player game can converge to the optimal strategy, and that the optimal strategy represents a globally minimal adversarial image. Using Monte Carlo tree search we gradually explore the game state space to search for adversarial examples. Our experiments show that, despite the black- box setting, manipulations guided by a perception-based saliency distribution are competitive with state-of-the-art methods that rely on white-box saliency matrices or sophisticated optimization procedures. Finally, we show how our method can be used to evaluate robustness of neural networks in safety-critical applications such as traffic sign recognition in self-driving cars.
Natural Language Aggregate Query over RDF Data
Natural language question-answering over RDF data has received widespread attention. Although there have been several studies that have dealt with a small number of aggregate queries, they have many restrictions (i.e., interactive information, controlled question or query template). Thus far, there has been no natural language querying mechanism that can process general aggregate queries over RDF data. Therefore, we propose a framework called NLAQ (Natural Language Aggregate Query). First, we propose a novel algorithm to automatically understand a users query intention, which mainly contains semantic relations and aggregations. Second, to build a better bridge between the query intention and RDF data, we propose an extended paraphrase dictionary ED to obtain more candidate mappings for semantic relations, and we introduce a predicate-type adjacent set PT to filter out inappropriate candidate mapping combinations in semantic relations and basic graph patterns. Third, we design a suitable translation plan for each aggregate category and effectively distinguish whether an aggregate item is numeric or not, which will greatly affect the aggregate result. Finally, we conduct extensive experiments over real datasets (QALD benchmark and DBpedia), and the experimental results demonstrate that our solution is effective.
A Novel Bayesian Cluster Enumeration Criterion for Unsupervised Learning
The Bayesian Information Criterion (BIC) has been widely used for estimating the number of data clusters in an observed data set for decades. The original derivation, referred to as classic BIC, does not include information about the specific model selection problem at hand, which renders it generic. However, very little effort has been made to check its appropriateness for cluster analysis. In this paper we derive BIC from first principle by formulating the problem of estimating the number of clusters in a data set as maximization of the posterior probability of candidate models given observations. We provide a general BIC expression which is independent of the data distribution given some mild assumptions are satisfied. This serves as an important milestone when deriving BIC for specific data distributions. Along this line, we provide a closed-form BIC expression for multivariate Gaussian distributed observations. We show that incorporating the clustering problem during the derivation of BIC results in an expression whose penalty term is different from the penalty term of the classic BIC. We propose a two-step cluster enumeration algorithm that utilizes a model-based unsupervised learning algorithm to partition the observed data according to each candidate model and the proposed BIC for selecting the model with the optimal number of clusters. The performance of the proposed criterion is tested using synthetic and real-data examples. Simulation results show that our proposed criterion outperforms the existing BIC-based cluster enumeration methods. Our proposed criterion is particularly powerful in estimating the number of data clusters when the observations have unbalanced and overlapping clusters.
Twin Sort Technique
The objective behind the Twin Sort technique is to sort the list of unordered data elements efficiently and to allow efficient and simple arrangement of data elements within the data structure with optimization of comparisons and iterations in the sorting method. This sorting technique effectively terminates the iterations when there is no need of comparison if the elements are all sorted in between the iterations. Unlike Quick sort, Merge sorting technique, this new sorting technique is based on the iterative method of sorting elements within the data structure. So it will be advantageous for optimization of iterations when there is no need for sorting elements. Finally, the Twin Sort technique is more efficient and simple method of arranging elements within a data structure and it is easy to implement when comparing to the other sorting technique. By the introduction of optimization of comparison and iterations, it will never allow the arranging task on the ordered elements.
Smart ‘Predict, then Optimize’
Many real-world analytics problems involve two significant challenges: prediction and optimization. Due to the typically complex nature of each challenge, the standard paradigm is to predict, then optimize. By and large, machine learning tools are intended to minimize prediction error and do not account for how the predictions will be used in a downstream optimization problem. In contrast, we propose a new and very general framework, called Smart ‘Predict, then Optimize’ (SPO), which directly leverages the optimization problem structure, i.e., its objective and constraints, for designing successful analytics tools. A key component of our framework is the SPO loss function, which measures the quality of a prediction by comparing the objective values of the solutions generated using the predicted and observed parameters, respectively. Training a model with respect to the SPO loss is computationally challenging, and therefore we also develop a surrogate loss function, called the SPO+ loss, which upper bounds the SPO loss, has desirable convexity properties, and is statistically consistent under mild conditions. We also propose a stochastic gradient descent algorithm which allows for situations in which the number of training samples is large, model regularization is desired, and/or the optimization problem of interest is nonlinear or integer. Finally, we perform computational experiments to empirically verify the success of our SPO framework in comparison to the standard predict-then-optimize approach.
Sequential Matrix Completion
We propose a novel algorithm for sequential matrix completion in a recommender system setting, where the
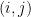
th entry of the matrix corresponds to a user

‘s rating of product

. The objective of the algorithm is to provide a sequential policy for user-product pair recommendation which will yield the highest possible ratings after a finite time horizon. The algorithm uses a Gamma process factor model with two posterior-focused bandit policies, Thompson Sampling and Information-Directed Sampling. While Thompson Sampling shows competitive performance in simulations, state-of-the-art performance is obtained from Information-Directed Sampling, which makes its recommendations based off a ratio between the expected reward and a measure of information gain. To our knowledge, this is the first implementation of Information Directed Sampling on large real datasets. This approach contributes to a recent line of research on bandit approaches to collaborative filtering including Kawale et al. (2015), Li et al. (2010), Bresler et al. (2014), Li et al. (2016), Deshpande & Montanari (2012), and Zhao et al. (2013). The setting of this paper, as has been noted in Kawale et al. (2015) and Zhao et al. (2013), presents significant challenges to bounding regret after finite horizons. We discuss these challenges in relation to simpler models for bandits with side information, such as linear or gaussian process bandits, and hope the experiments presented here motivate further research toward theoretical guarantees.
Consilience: A Holistic Measure of Goodness-of-Fit
We describe an apparently new measure of multivariate goodness-of-fit between sets of quantitative results from a model (simulation, analytical, or multiple regression), paired with those observed under corresponding conditions from the system being modeled. Our approach returns a single, integrative measure, even though it can accommodate complex systems that produce responses of M types. For each response-type, the goodness-of-fit measure, which we label ‘Consilience’ (C), is maximally 1, for perfect fit; near 0 for the large-sample case (number of pairs, N, more than about 25) in which the modeled series is a random sample from a quasi-normal distribution with the same mean and variance as that of the observed series (null model); and, less than 0, toward minus-infinity, for progressively worse fit. In addition, lack-of-fit for each response-type can be apportioned between systematic and non-systematic (unexplained) components of error. Finally, for statistical assessment of models relative to the equivalent null model, we offer provisional estimates of critical C vs. N, and of critical joint-C vs. N and M, at various levels of Pr(type-I error). Application of our proposed methodology requires only MS Excel (2003 or later); we provide Excel XLS and XLSX templates that afford semi-automatic computation for systems involving up to M = 5 response types, each represented by up to N = 1000 observed-and-modeled result pairs. N need not be equal, nor response pairs in complete overlap, over M.
Accelerated Reinforcement Learning
Policy gradient methods are widely used in reinforcement learning algorithms to search for better policies in the parameterized policy space. They do gradient search in the policy space and are known to converge very slowly. Nesterov developed an accelerated gradient search algorithm for convex optimization problems. This has been recently extended for non-convex and also stochastic optimization. We use Nesterov’s acceleration for policy gradient search in the well-known actor-critic algorithm and show the convergence using ODE method. We tested this algorithm on a scheduling problem. Here an incoming job is scheduled into one of the four queues based on the queue lengths. We see from experimental results that algorithm using Nesterov’s acceleration has significantly better performance compared to algorithm which do not use acceleration. To the best of our knowledge this is the first time Nesterov’s acceleration has been used with actor-critic algorithm.
Global Sensitivity Analysis via Multi-Fidelity Polynomial Chaos Expansion
The presence of uncertainties are inevitable in engineering design and analysis, where failure in understanding their effects might lead to the structural or functional failure of the systems. The role of global sensitivity analysis in this aspect is to quantify and rank the effects of input random variables and their combinations to the variance of the random output. In problems where the use of expensive computer simulations are required, metamodels are widely used to speed up the process of global sensitivity analysis. In this paper, a multi-fidelity framework for global sensitivity analysis using polynomial chaos expansion (PCE) is presented. The goal is to accelerate the computation of Sobol sensitivity indices when the deterministic simulation is expensive and simulations with multiple levels of fidelity are available. This is especially useful in cases where a partial differential equation solver computer code is utilized to solve engineering problems. The multi-fidelity PCE is constructed by combining the low-fidelity and correction PCE. Following this step, the Sobol indices are computed using this combined PCE. The PCE coefficients for both low-fidelity and correction PCE are computed with spectral projection technique and sparse grid integration. In order to demonstrate the capability of the proposed method for sensitivity analysis, several simulations are conducted. On the aerodynamic example, the multi-fidelity approach is able to obtain an accurate value of Sobol indices with 36.66% computational cost compared to the standard single-fidelity PCE for a nearly similar accuracy.
Online Boosting Algorithms for Multi-label Ranking
We consider the multi-label ranking approach to multi-label learning. Boosting is a natural method for multi-label ranking as it aggregates weak predictions through majority votes, which can be directly used as scores to produce a ranking of the labels. We design online boosting algorithms with provable loss bounds for multi-label ranking. We show that our first algorithm is optimal in terms of the number of learners required to attain a desired accuracy, but it requires knowledge of the edge of the weak learners. We also design an adaptive algorithm that does not require this knowledge and is hence more practical. Experimental results on real data sets demonstrate that our algorithms are at least as good as existing batch boosting algorithms.
Aggregating Algorithm for Prediction of Packs
This paper formulates the protocol for prediction of packs, which a special case of prediction under delayed feedback. Under this protocol, the learner must make a few predictions without seeing the outcomes and then the outcomes are revealed. We develop the theory of prediction with expert advice for packs. By applying Vovk’s Aggregating Algorithm to this problem we obtain a number of algorithms with tight upper bounds. We carry out empirical experiments on housing data.
SMSSVD – SubMatrix Selection Singular Value Decomposition
High throughput biomedical measurements normally capture multiple overlaid biologically relevant signals and often also signals representing different types of technical artefacts like e.g. batch effects. Signal identification and decomposition are accordingly main objectives in statistical biomedical modeling and data analysis. Existing methods, aimed at signal reconstruction and deconvolution, in general, are either supervised, contain parameters that need to be estimated or present other types of ad hoc features. We here introduce SubMatrix Selection SingularValue Decomposition (SMSSVD), a parameter-free unsupervised signal decomposition and dimension reduction method, designed to reduce noise, adaptively for each low-rank-signal in a given data matrix, and represent the signals in the data in a way that enable unbiased exploratory analysis and reconstruction of multiple overlaid signals, including identifying groups of variables that drive different signals. The Submatrix Selection Singular Value Decomposition (SMSSVD) method produces a denoised signal decomposition from a given data matrix. The SMSSVD method guarantees orthogonality between signal components in a straightforward manner and it is designed to make automation possible. We illustrate SMSSVD by applying it to several real and synthetic datasets and compare its performance to golden standard methods like PCA (Principal Component Analysis) and SPC (Sparse Principal Components, using Lasso constraints). The SMSSVD is computationally efficient and despite being a parameter-free method, in general, outperforms existing statistical learning methods. A Julia implementation of SMSSVD is openly available on GitHub (
https://…/SMSSVD.jl ).
Interactive Visual Data Exploration with Subjective Feedback: An Information-Theoretic Approach
Visual exploration of high-dimensional real-valued datasets is a fundamental task in exploratory data analysis (EDA). Existing methods use predefined criteria to choose the representation of data. There is a lack of methods that (i) elicit from the user what she has learned from the data and (ii) show patterns that she does not know yet. We construct a theoretical model where identified patterns can be input as knowledge to the system. The knowledge syntax here is intuitive, such as ‘this set of points forms a cluster’, and requires no knowledge of maths. This background knowledge is used to find a Maximum Entropy distribution of the data, after which the system provides the user data projections in which the data and the Maximum Entropy distribution differ the most, hence showing the user aspects of the data that are maximally informative given the user’s current knowledge. We provide an open source EDA system with tailored interactive visualizations to demonstrate these concepts. We study the performance of the system and present use cases on both synthetic and real data. We find that the model and the prototype system allow the user to learn information efficiently from various data sources and the system works sufficiently fast in practice. We conclude that the information theoretic approach to exploratory data analysis where patterns observed by a user are formalized as constraints provides a principled, intuitive, and efficient basis for constructing an EDA system.
Human-in-the-loop Artificial Intelligence
Little by little, newspapers are revealing the bright future that Artificial Intelligence (AI) is building. Intelligent machines will help everywhere. However, this bright future has a dark side: a dramatic job market contraction before its unpredictable transformation. Hence, in a near future, large numbers of job seekers will need financial support while catching up with these novel unpredictable jobs. This possible job market crisis has an antidote inside. In fact, the rise of AI is sustained by the biggest knowledge theft of the recent years. Learning AI machines are extracting knowledge from unaware skilled or unskilled workers by analyzing their interactions. By passionately doing their jobs, these workers are digging their own graves. In this paper, we propose Human-in-the-loop Artificial Intelligence (HIT-AI) as a fairer paradigm for Artificial Intelligence systems. HIT-AI will reward aware and unaware knowledge producers with a different scheme: decisions of AI systems generating revenues will repay the legitimate owners of the knowledge used for taking those decisions. As modern Robin Hoods, HIT-AI researchers should fight for a fairer Artificial Intelligence that gives back what it steals.
Communication Efficient Checking of Big Data Operations
We propose fast probabilistic algorithms with low (i.e., sublinear in the input size) communication volume to check the correctness of operations in Big Data processing frameworks and distributed databases. Our checkers cover many of the commonly used operations, including sum, average, median, and minimum aggregation, as well as sorting, union, merge, and zip. An experimental evaluation of our implementation in Thrill (Bingmann et al., 2016) confirms the low overhead and high failure detection rate predicted by theoretical analysis.
Autoencoder Feature Selector
High-dimensional data in many areas such as computer vision and machine learning brings in computational and analytical difficulty. Feature selection which select a subset of features from original ones has been proven to be effective and efficient to deal with high-dimensional data. In this paper, we propose a novel AutoEncoder Feature Selector (AEFS) for unsupervised feature selection. AEFS is based on the autoencoder and the group lasso regularization. Compared to traditional feature selection methods, AEFS can select the most important features in spite of nonlinear and complex correlation among features. It can be viewed as a nonlinear extension of the linear method regularized self-representation (RSR) for unsupervised feature selection. In order to deal with noise and corruption, we also propose robust AEFS. An efficient iterative algorithm is designed for model optimization and experimental results verify the effectiveness and superiority of the proposed method.
Content Based Document Recommender using Deep Learning
With the recent advancements in information technology there has been a huge surge in amount of data available. But information retrieval technology has not been able to keep up with this pace of information generation resulting in over spending of time for retrieving relevant information. Even though systems exist for assisting users to search a database along with filtering and recommending relevant information, but recommendation system which uses content of documents for recommendation still have a long way to mature. Here we present a Deep Learning based supervised approach to recommend similar documents based on the similarity of content. We combine the C-DSSM model with Word2Vec distributed representations of words to create a novel model to classify a document pair as relevant/irrelavant by assigning a score to it. Using our model retrieval of documents can be done in O(1) time and the memory complexity is O(n), where n is number of documents.
Stability and Generalization of Learning Algorithms that Converge to Global Optima
We establish novel generalization bounds for learning algorithms that converge to global minima. We do so by deriving black-box stability results that only depend on the convergence of a learning algorithm and the geometry around the minimizers of the loss function. The results are shown for nonconvex loss functions satisfying the Polyak-{\L}ojasiewicz (PL) and the quadratic growth (QG) conditions. We further show that these conditions arise for some neural networks with linear activations. We use our black-box results to establish the stability of optimization algorithms such as stochastic gradient descent (SGD), gradient descent (GD), randomized coordinate descent (RCD), and the stochastic variance reduced gradient method (SVRG), in both the PL and the strongly convex setting. Our results match or improve state-of-the-art generalization bounds and can easily be extended to similar optimization algorithms. Finally, we show that although our results imply comparable stability for SGD and GD in the PL setting, there exist simple neural networks with multiple local minima where SGD is stable but GD is not.
• Deep Voice 3: 2000-Speaker Neural Text-to-Speech
• Point Neurons with Conductance-Based Synapses in the Neural Engineering Framework
• Employing Fusion of Learned and Handcrafted Features for Unconstrained Ear Recognition
• On the Turán number of some ordered even cycles
• Optimal cutting planes from the group relaxations
• Nonparametrically estimating dynamic bivariate correlation using visibility graph algorithm
• Zero Variance and Hamiltonian Monte Carlo Methods in GARCH Models
• Verb Pattern: A Probabilistic Semantic Representation on Verbs
• On the Consistency of Graph-based Bayesian Learning and the Scalability of Sampling Algorithms
• Low Precision RNNs: Quantizing RNNs Without Losing Accuracy
• A Statistical Characterization of Localization Performance in Wireless Networks
• Uniformly bounded regret in the multi-secretary problem
• Colorful coverings of polytopes and piercing numbers of colorful d-intervals
• Generalized linear mixing model accounting for endmember variability
• A Computational Framework for Multi-Modal Social Action Identification
• Is space a word, too?
• A Tight Excess Risk Bound via a Unified PAC-Bayesian-Rademacher-Shtarkov-MDL Complexity
• Adversarially Optimizing Intersection over Union for Object Localization Tasks
• Dynamic mode decomposition for compressive system identification
• High Performance Canny Edge Detector using Parallel Patterns for Scalability on Modern Multicore Processors
• Localization for MCMC: sampling high-dimensional posterior distributions with banded structure
• On the Kőnig-Egerváry Theorem for $k$-Paths
• An efficient deep learning hashing neural network for mobile visual search
• A path integral approach to Bayesian inference in Markov processes
• Modeling the Annual Growth Rate of Electricity Consumption of China in the 21st Century: Trends and Prediction
• On the Ambiguity of Differentially Uniform Functions
• A Novel Partitioning Method for Accelerating the Block Cimmino Algorithm
• Constrained Optimisation of Rational Functions for Accelerating Subspace Iteration
• A Unified PTAS for Prize Collecting TSP and Steiner Tree Problem in Doubling Metrics
• Functional data analysis in the Banach space of continuous functions
• Image camouflage based on Generate Model
• Skew cyclic codes and skew(1+u2+v3+uv4)-constacyclic codes over Fq + uFq + vFq + uvFq
• Loss Induced Maximum Power Transfer in Distribution Networks
• Joint functional convergence of partial sum and maxima for linear processes
• Construction of skew cyclic and skew constacyclic codes over Fq+uFq+vFq
• Cointegrated Density-Valued Linear Processes
• Estimates of heat kernels of non-symmetric Lévy processes
• Optimal Rates for Learning with Nyström Stochastic Gradient Methods
• Zeroth-Order Online Alternating Direction Method of Multipliers: Convergence Analysis and Applications
• A classification of small operators using graph theory
• Downlink Power Control in User-Centric and Cell-Free Massive MIMO Wireless Networks
• Cell-Free and User-Centric Massive MIMO at Millimeter Wave Frequencies
• A Learning-to-Infer Method for Real-Time Power Grid Topology Identification
• Superposed Episodic and Semantic Memory via Sparse Distributed Representation
• Incomplete Dot Products for Dynamic Computation Scaling in Neural Network Inference
• On Universality of Classical Probability with Contextually Labeled Random Variables
• Heat Kernel Smoothing in Irregular Image Domains
• Simple maps, Hurwitz numbers, and Topological Recursion
• Insulin Regimen ML-based control for T2DM patients
• Gradient flows, second order gradient systems and convexity
• Relaxations of AC Minimal Load-Shedding for Severe Contingency Analysis
• The Price of Anarchy for Transportation Networks with Mixed Autonomy
• Deep Triphone Embedding Improves Phoneme Recognition
• Super Fast Beam Tracking in Phased Antenna Arrays
• Optimal transport for Gaussian mixture models
• A test for k sample Behrens-Fisher problem in high dimensional data
• Stable Blind Deconvolution over the Reals from Additional Autocorrelations
• Bayesian uncertainty quantification for epidemic spread on networks
• The Number of $k$-Cycles In a Family of Restricted Permutations
• Iteratively reweighted $\ell_1$ algorithms with extrapolation
• Strategic Classification from Revealed Preferences
• Linked system of symmetric group divisible designs of type II
• On the quadratic variation of the model-free price paths with jumps
• Asymptotic Analysis for a Stochastic Chemostat Model in Wastewater Treatment
• Meta-Key: A Secure Data-Sharing Protocol under Blockchain-Based Decentralised Storage Architecture
• Analysis of Discrete-Time MIMO OFDM-Based Orthogonal Time Frequency Space Modulation
• Exponential Mixing for SDEs under the total variation
• The Complexity of Graph-Based Reductions for Reachability in Markov Decision Processes
• Communication Dualism in Distributed Systems with Petri Net Interpretation
• On the Duality of Fractional Repetition Codes
• Computational Methods for Martingale Optimal Transport problems
• Moderate Environmental Variation Promotes Adaptation in Artificial Evolution
• Joint Pilot Allocation and Robust Transmission Design for Ultra-dense User-centric TDD C-RAN with Imperfect CSI
• Invariance principle for biased Boostrap Random Walk
• Searching for effective and efficient way of knowledge transfer within an organization
• On the rates of convergence of Parallelized Averaged Stochastic Gradient Algorithms
• Disorder-driven quantum transition in relativistic semimetals: functional renormalization via the porous medium equation
• Order-disorder transitions in lattice gases with annealed reactive constraints
• Numerical evidences of universal trap-like aging dynamics
• Elliptical modeling and pattern analysis for perturbation models and classfication
• WristAuthen: A Dynamic Time Wrapping Approach for User Authentication by Hand-Interaction through Wrist-Worn Devices
• Further factorization of $x^n-1$ over a finite field
• How big is big enough? Unsupervised word sense disambiguation using a very large corpus
• Backtracking Regression Forests for Accurate Camera Relocalization
• An Approach to One-Bit Compressed Sensing Based on Probably Approximately Correct Learning Theory
• Discrete Distribution for a Wiener Process Range and its Properties
• Nonlinear Filtering for Periodic, Time-Varying Parameter Estimation
• Safety-Aware Apprenticeship Learning
• Hierarchical State Abstractions for Decision-Making Problems with Computational Constraints
• Rethinking Convolutional Semantic Segmentation Learning
• FDD Massive MIMO: Efficient Downlink Probing and Uplink Feedback via Active Channel Sparsification
• On fluctuations of cycles in a finite CW complex
• Timed Concurrent State Machines
• Level 2.5 large deviations for continuous time Markov chains with time periodic rates
• Number of thermodynamic states in the three-dimensional Edwards-Anderson spin glass
• ActivityNet Challenge 2017 Summary
• Exploiting generalization in the subspaces for faster model-based learning
• Deep Cropping via Attention Box Prediction and Aesthetics Assessment
• Bringing Semantic Structures to User Intent Detection in Online Medical Queries
• Adaptive Bayesian nonparametric regression using kernel mixture of polynomials with application to partial linear model
• A Brief Comparison of Two Enterprise-Class RDBMSs
• Rainbow saturation of graphs
• Lightweight MPI Communicators with Applications to Perfectly Balanced Schizophrenic Quicksort
• Characterizing and Enumerating Walsh-Hadamard Transform Algorithms
• Ultrafast Synchronization via Local Observation
• On the Coordinator’s Rule for Fast Paxos
• A First Step in Combining Cognitive Event Features and Natural Language Representations to Predict Emotions
• Feedback-prop: Convolutional Neural Network Inference under Partial Evidence
• On Asymptotic Standard Normality of the Two Sample Pivot
• From infinite urn schemes to self-similar stable processes
• Cluster algebras and Jones polynomials
• A new class of $L_q$-norm zonoid depths
• Regularized calibrated estimation of propensity scores with model misspecification and high-dimensional data
• 3D ab initio modeling in cryo-EM by autocorrelation analysis
• Generalized High-Dimensional Trace Regression via Nuclear Norm Regularization
• VGGFace2: A dataset for recognising faces across pose and age
• On the Navier-Stokes equation perturbed by rough transport noise
• Directory Service Provided by DSCloud Platform
• Intertwinings, second-order Brascamp-Lieb inequalities and spectral estimates
• Probabilistic Pursuits on Graphs
• Spatial rational expectations equilibria in the Ramsey model of optimal growth
• Conjugacy of one-dimensional one-sided cellular automata is undecidable
• Modeling rainfalls using a seasonal hidden markov model
• Distributed Constrained Optimization over Networked Systems via A Singular Perturbation Method
• A semi-parametric estimation for max-mixture spatial process
• Accelerating GMM-based patch priors for image restoration: Three ingredients for a 100$\times$ speed-up
• Self-Stabilizing Supervised Publish-Subscribe Systems
• A semigroup approach to nonlinear Lévy processes
• An iterative closest point method for measuring the level of similarity of 3d log scans in wood industry
• The distinguishing index of graphs with at least one cycle is not more than its distinguishing number
• A 3D Human Body Blockage Model for Outdoor Millimeter-Wave Cellular Communication
• Image segmentation and classification for sickle cell disease using deformable U-Net
• Correlations between Soft Modes and Dynamics in Colloidal Supercooled Liquids and Glasses
• Brown measure and asymptotic freeness of elliptic and related matrices
• bridgesampling: An R Package for Estimating Normalizing Constants
• Satisfiability in multi-valued circuits
• The seed bank diffusion, and its relation to the two-island model
• Fast MCMC sampling algorithms on polytopes
• A hierarchical Bayesian model for measuring individual-level and group-level numerical representations
• On the transmission-based graph topological indices
• Progressive Learning for Systematic Design of Large Neural Networks
• Investigating the feature collection for semantic segmentation via single skip connection
• Asymptotic behavior of local times related statistics for fractional Brownian motion
• Lines of descent under selection
• Parametric channel estimation for massive MIMO
• Chimera states in brain networks: empirical neural vs. modular fractal connectivity
• Learning With Errors and Extrapolated Dihedral Cosets
• Symbolic Computations of First Integrals for Polynomial Vector Fields
• Algorithms Based on Unions of Nonexpansive Maps
• Extremal problems on the hypercube and the codegree Turán density of complete $r$-graphs
• High-Quality Shared-Memory Graph Partitioning
• Generalized incompressible flows, multi-marginal transport and Sinkhorn algorithm
• On some hard and some tractable cases of the maximum acyclic matching problem
• Lower bounds on the number of realizations of rigid graphs
• Large time Unimodality for classical and free Brownian motions with initial distributions
• Testing the limits of unsupervised learning for semantic similarity
• Generic 3D Representation via Pose Estimation and Matching
• A short proof of the middle levels theorem
• A General Method for Finding the Optimal Threshold in Discrete Time
• Differential posets and restriction in critical groups
• A Framework for Efficient Adaptively Secure Composable Oblivious Transfer in the ROM
• On a non-linear 2D fractional wave equation
• Almost 2-perfect 8-cycle systems
• A shortcut for Hommel’s procedure in linearithmic time
• A JSON Token-Based Authentication and Access Management Schema for Cloud SaaS Applications
• Tensor Matched Subspace Detection
• Attending to All Mention Pairs for Full Abstract Biological Relation Extraction
• Fast and Flexible Software Polar List Decoders
• BENCHIP: Benchmarking Intelligence Processors
• Strongly correlated non-equilibrium steady states with currents — quantum and classical picture
• Combined Stochastic Optimization of Frequency Control and Self-Consumption with a Battery
• Strategy Preserving Compilation for Parallel Functional Code
• Constrained Bayesian Active Learning of Interference Channels in Cognitive Radio Networks
• Improving One-Shot Learning through Fusing Side Information
• Linear regression model with a randomly censored predictor:Estimation procedures
• Maximum number of sum-free colorings in finite abelian groups
• When is an automatic set an additive basis?
• Tail measure and tail spectral process of regularly varying time series
• On the maximum size of connected hypergraphs without a path of given length
• Decoupling phenomena and replica symmetry breaking of binary mixtures
• Listening to the World Improves Speech Command Recognition
• Fractional Schrödinger operators
• Performance Bounds of Concatenated Polar Coding Schemes
• Near-Optimal Clustering in the $k$-machine model
• Entangled multi-component 4D quantum Hall states from photonic crystal defects
• A Test for Separability in Covariance Operators of Random Surfaces
• An Empirical Investigation On Search Engine Ad Disclosure
• Fixed Price Approximability of the Optimal Gain From Trade
• Deep Health Care Text Classification
• Optimal potentials for problems with changing sing data
Like this:
Like Loading...