ALAN: Adaptive Learning for Multi-Agent Navigation
Deep Learning in Multiple Multistep Time Series Prediction
 . We provide sufficient conditions for the tractability of SPQNs that generalize and relax the decomposable and complete tractability conditions of SPNs. These relaxed conditions give rise to an exponential boost to the expressive efficiency of our model, i.e. we prove that there are distributions which SPQNs can compute efficiently but require SPNs to be of exponential size. Thus, we narrow the gap in expressivity between tractable graphical models and other Neural Network-based generative models.
. We provide sufficient conditions for the tractability of SPQNs that generalize and relax the decomposable and complete tractability conditions of SPNs. These relaxed conditions give rise to an exponential boost to the expressive efficiency of our model, i.e. we prove that there are distributions which SPQNs can compute efficiently but require SPNs to be of exponential size. Thus, we narrow the gap in expressivity between tractable graphical models and other Neural Network-based generative models.
Querying Best Paths in Graph Databases
Self-Taught Support Vector Machine
New efficient algorithms for multiple change-point detection with kernels
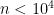 ). This computational issue is addressed by first describing a new efficient and exact algorithm for kernel multiple change-point detection with an improved worst-case complexity that is quadratic in time and linear in space. It allows dealing with medium size signals (up to
). This computational issue is addressed by first describing a new efficient and exact algorithm for kernel multiple change-point detection with an improved worst-case complexity that is quadratic in time and linear in space. It allows dealing with medium size signals (up to  ). Second, a faster but approximation algorithm is described. It is based on a low-rank approximation to the Gram matrix. It is linear in time and space. This approximation algorithm can be applied to large-scale signals (
). Second, a faster but approximation algorithm is described. It is based on a low-rank approximation to the Gram matrix. It is linear in time and space. This approximation algorithm can be applied to large-scale signals (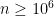 ). These exact and approximation algorithms have been implemented in \texttt{R} and \texttt{C} for various kernels. The computational and statistical performances of these new algorithms have been assessed through empirical experiments. The runtime of the new algorithms is observed to be faster than that of other considered procedures. Finally, simulations confirmed the higher statistical accuracy of kernel-based approaches to detect changes that are not only in the mean. These simulations also illustrate the flexibility of kernel-based approaches to analyze complex biological profiles made of DNA copy number and allele B frequencies. An R package implementing the approach will be made available on github.
). These exact and approximation algorithms have been implemented in \texttt{R} and \texttt{C} for various kernels. The computational and statistical performances of these new algorithms have been assessed through empirical experiments. The runtime of the new algorithms is observed to be faster than that of other considered procedures. Finally, simulations confirmed the higher statistical accuracy of kernel-based approaches to detect changes that are not only in the mean. These simulations also illustrate the flexibility of kernel-based approaches to analyze complex biological profiles made of DNA copy number and allele B frequencies. An R package implementing the approach will be made available on github.
Is Epicurus the father of Reinforcement Learning?
• Joint Image Filtering with Deep Convolutional Networks
• Subsampling large graphs and invariance in networks
• Machine Learning Bell Nonlocality in Quantum Many-body Systems
• Gapless insulating edges of dirty interacting topological insulators
• Regression-aware decompositions
• Universal layered permutations
• Monotonicity axioms in approval-based multi-winner voting rules
• Local Convergence of Proximal Splitting Methods for Rank Constrained Problems
• Multipoint Estimates for Radial and Whole-plane SLE
• Solutions of Quadratic First-Order ODEs applied to Computer Vision Problems
• Stochastic Gradient Descent in Continuous Time: A Central Limit Theorem
• Short and Long Ranged Impurities in Fractional Quantum Hall Systems
• Physical-Layer Network Coding with Multiple Antennas: An Enabling Technology for Smart Cities
• On the local stability of semidefinite relaxations
• What can spin glass theory and analogies tell us about ferroic glasses?
• Modeling and sensitivity analysis methodology for hybrid dynamical systems
• Recurrence sequences connected with the $m$–ary partition function and their divisibility properties
• Measurement Context Extraction from Text: Discovering Opportunities and Gaps in Earth Science
• Harvested Power Maximization in QoS-Constrained MIMO SWIPT with Generic RF Harvesting Model
• Explaining Trained Neural Networks with Semantic Web Technologies: First Steps
• Improved Coresets for Kernel Density Estimates
• Efficient Data-Driven Geologic Feature Detection from Pre-stack Seismic Measurements using Randomized Machine-Learning Algorithm
• Modular decomposition of transitive graphs and transitively orienting their complements
• DisSent: Sentence Representation Learning from Explicit Discourse Relations
• One-sided solutions for optimal stopping problems with logconcave reward functions
• Learning Koopman Invariant Subspaces for Dynamic Mode Decomposition
• Using Context Events in Neural Network Models for Event Temporal Status Identification
• A Finite Element Computational Framework for Active Contours on Graphs
• Asymptotic theory for maximum likelihood estimates in reduced-rank multivariate generalised linear models
• A Unified Neural Network Approach for Estimating Travel Time and Distance for a Taxi Trip
• Enhanced Mobile Computing Experience with Cloud Offloading
• Designing Low-Complexity Heavy-Traffic Delay-Optimal Load Balancing Schemes: Theory to Algorithms
• Fast initial guess estimation for digital image correlation
• Linear Programming Bounds for Distributed Storage Codes
• Utility maximization problem under transaction costs: optimal dual processes and stability
• The Inverse Gamma-Gamma Prior for Optimal Posterior Contraction and Multiple Hypothesis Testing
• Fast, Accurate and Fully Parallelizable Digital Image Correlation
• On the Power of Tree-Depth for Fully Polynomial FPT Algorithms
• Evaluating discriminatory accuracy of models using partial risk-scores in two-phase studies
• Sign-Constrained Regularized Loss Minimization
• An Augmented Nonlinear Complex LMS for Digital Self-Interference Cancellation in Full-Duplex Direct-Conversion Transceivers
• Marginal sequential Monte Carlo for doubly intractable models
• Securing UAV Communications Via Trajectory Optimization
• Provably Fair Representations
• The Sierpiński gasket as the Martin boundary of a non-isotropic Markov chain
• Multi-Batch Experience Replay for Fast Convergence of Continuous Action Control
• The Location-Allocation Model for Multi-Classification-Yard Location Problem in a Railway Network
• Revisiting the Design Issues of Local Models for Japanese Predicate-Argument Structure Analysis
• Non-abelian finite groups whose character sums are invariant but are not Cayley isomorphism
• Robust Parameter Estimation of Regression Model with AR(p) Error Terms
• Arguing Machines: Perception-Control System Redundancy and Edge Case Discovery in Real-World Autonomous Driving
• Geometry of large Boltzmann outerplanar maps
• An Improved Naive Bayes Classifier-based Noise Detection Technique for Classifying User Phone Call Behavior
• Effects of Images with Different Levels of Familiarity on EEG
• Markerless visual servoing on unknown objects for humanoid robot platforms
• Pure Operation-Based Replicated Data Types
• V1: A Visual Query Language for Property Graphs
• Risk assessment using suprema data
• VOIDD: automatic vessel of intervention dynamic detection in PCI procedures
• Multimodal Observation and Interpretation of Subjects Engaged in Problem Solving
• Clusters of Driving Behavior from Observational Smartphone Data
• Convolutional Attention-based Seq2Seq Neural Network for End-to-End ASR
• Supersaturated sparse graphs and hypergraphs
• Optimal Control of PDEs using Occupation Measures and SDP Relaxations
• Subjectively Interesting Subgroup Discovery on Real-valued Targets
• The co-Pieri rule for Kronecker coefficients
• Wild Bootstrapping Rank-Based Procedures: Multiple Testing in Nonparametric Split-Plot Designs
• On the Containment Problem for Linear Sets
• Hierarchical Convolutional-Deconvolutional Neural Networks for Automatic Liver and Tumor Segmentation
• Measuring the spatial balance of a sample: A new measure based on the Moran’s I index
• The Trees of Hanoi
• Lattice point visibility on generalized lines of sight
• On a Generalization of the Arcsine Law
• Bayesian Modeling of the Structural Connectome for Studying Alzheimer Disease
• Inference for partial correlation when data are missing not at random
• On free Generalized Inverse Gaussian distributions
• A probabilistic view on the deterministic mutation-selection equation: dynamics, equilibria, and ancestry via individual lines of descent
• Balancing expression dags for more efficient lazy adaptive evaluation
• Additivity of Information in Multilayer Networks via Additive Gaussian Noise Transforms
• Towards Scalable Spectral Clustering via Spectrum-Preserving Sparsification
• Particle Filtering for Stochastic Navier-Stokes Signal Observed with Linear Additive Noise
• Throughput Region of Spatially Correlated Interference Packet Networks
• Constructing Directed Cayley Graphs of Small Diameter: A Potent Solovay-Kitaev Procedure
• Auto Analysis of Customer Feedback using CNN and GRU Network
• Riordan graphs I: Structural properties
• Finite size corrections to the Parisi overlap function in the GREM
• On the resolution of l0 minimization problems via alternating Lagrangian schemes
• Deep Imitation Learning for Complex Manipulation Tasks from Virtual Reality Teleoperation
• Analysis of planar ornament patterns via motif asymmetry assumption and local connections
• A generalization of Erdős’ matching conjecture
• Hard and Easy Instances of L-Tromino Tilings
• Secret-Key Generation in Many-to-One Networks: An Integrated Game-Theoretic and Information-Theoretic Approach
• Progressive Representation Adaptation for Weakly Supervised Object Localization