OpenNMT: Open-Source Toolkit for Neural Machine Translation
We describe an open-source toolkit for neural machine translation (NMT). The toolkit prioritizes efficiency, modularity, and extensibility with the goal of supporting NMT research into model architectures, feature representations, and source modalities, while maintaining competitive performance and reasonable training requirements. The toolkit consists of modeling and translation support, as well as detailed pedagogical documentation about the underlying techniques.
Stochastic Generative Hashing
Learning to hash plays a fundamentally important role in the efficient image and video retrieval and many other computer vision problems. However, due to the binary outputs of the hash functions, the learning of hash functions is very challenging. In this paper, we propose a novel approach to learn stochastic hash functions such that the learned hashing codes can be used to regenerate the inputs. We develop an efficient stochastic gradient learning algorithm which can avoid the notorious difficulty caused by binary output constraint, and directly optimize the parameters of the hash functions and the associated generative model jointly. The proposed method can be applied to both

approximate nearest neighbor search (L2NNS) and maximum inner product search (MIPS). Extensive experiments on a variety of large-scale datasets show that the proposed method achieves significantly better retrieval results than previous state-of-the-arts.
Feature Screening in Large Scale Cluster Analysis
We propose a novel methodology for feature screening in clustering massive datasets, in which both the number of features and the number of observations can potentially be very large. Taking advantage of a fusion penalization based convex clustering criterion, we propose a very fast screening procedure that efficiently discards non-informative features by first computing a clustering score corresponding to the clustering tree constructed for each feature, and then thresholding the resulting values. We provide theoretical support for our approach by establishing uniform non-asymptotic bounds on the clustering scores of the ‘noise’ features. These bounds imply perfect screening of non-informative features with high probability and are derived via careful analysis of the empirical processes corresponding to the clustering trees that are constructed for each of the features by the associated clustering procedure. Through extensive simulation experiments we compare the performance of our proposed method with other screening approaches, popularly used in cluster analysis, and obtain encouraging results. We demonstrate empirically that our method is applicable to cluster analysis of big datasets arising in single-cell gene expression studies.
Generalisation in Named Entity Recognition: A Quantitative Analysis
Named Entity Recognition (NER) is a key NLP task, which is all the more challenging on Web and user-generated content with their diverse and continuously changing language. This paper aims to quantify how this diversity impacts state-of-the-art NER methods, by measuring named entity (NE) and context variability, feature sparsity, and their effects on precision and recall. In particular, our findings indicate that NER approaches struggle to generalise in diverse genres with limited training data. Unseen NEs, in particular, play an important role, which have a higher incidence in diverse genres such as social media than in more regular genres such as newswire. Coupled with a higher incidence of unseen features more generally and the lack of large training corpora, this leads to significantly lower F1 scores for diverse genres as compared to more regular ones. We also find that leading systems rely heavily on surface forms found in training data, having problems generalising beyond these, and offer explanations for this observation.
Slow mixing for Latent Dirichlet allocation
Markov chain Monte Carlo (MCMC) algorithms are ubiquitous in probability theory in general and in machine learning in particular. A Markov chain is devised so that its stationary distribution is some probability distribution of interest. Then one samples from the given distribution by running the Markov chain for a ‘long time’ until it appears to be stationary and then collects the sample. However these chains are often very complex and there are no theoretical guarantees that stationarity is actually reached. In this paper we study the Gibbs sampler of the posterior distribution of a very simple case of Latent Dirichlet Allocation, an attractive Bayesian unsupervised learning model for text generation and text classification. It turns out that in some situations, the mixing time of the Gibbs sampler is exponential in the length of documents and so it is practically impossible to properly sample from the posterior when documents are sufficiently long.
A Large Dimensional Analysis of Least Squares Support Vector Machines
In this article, a large dimensional performance analysis of kernel least squares support vector machines (LS-SVMs) is provided under the assumption of a two-class Gaussian mixture model for the input data. Building upon recent random matrix advances, when both the dimension of data

and their number

grow large at the same rate, we show that the LS-SVM decision function converges to a normal-distributed variable, the mean and variance of which depend explicitly on a local behavior of the kernel function. This theoretical result is then applied to the MNIST data sets which, despite their non-Gaussianity, exhibit a surprisingly similar behavior. Our analysis provides a deeper understanding of the mechanism into play in SVM-type methods and in particular of the impact on the choice of the kernel function as well as some of their theoretical limits.
Reachability in Augmented Interval Markov Chains
In this paper we propose augmented interval Markov chains (AIMCs): a generalisation of the familiar interval Markov chains (IMCs) where uncertain transition probabilities are in addition allowed to depend on one another. This new model preserves the flexibility afforded by IMCs for describing stochastic systems where the parameters are unclear, for example due to measurement error, but also allows us to specify transitions with probabilities known to be identical, thereby lending further expressivity. The focus of this paper is reachability in AIMCs. We study the qualitative, exact quantitative and approximate reachability problem, as well as natural subproblems thereof, and establish several upper and lower bounds for their complexity. We prove the exact reachability problem is at least as hard as the famous square-root sum problem, but, encouragingly, the approximate version lies in

if the underlying graph is known, whilst the restriction of the exact problem to a constant number of uncertain edges is in
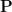
. Finally, we show that uncertainty in the graph structure affects complexity by proving
-completeness for the qualitative subproblem, in contrast with an easily-obtained upper bound of
for the same subproblem with known graph structure.
A Framework for Knowledge Management and Automated Reasoning Applied on Intelligent Transport Systems
Cyber-Physical Systems in general, and Intelligent Transport Systems (ITS) in particular use heterogeneous data sources combined with problem solving expertise in order to make critical decisions that may lead to some form of actions e.g., driver notifications, change of traffic light signals and braking to prevent an accident. Currently, a major part of the decision process is done by human domain experts, which is time-consuming, tedious and error-prone. Additionally, due to the intrinsic nature of knowledge possession this decision process cannot be easily replicated or reused. Therefore, there is a need for automating the reasoning processes by providing computational systems a formal representation of the domain knowledge and a set of methods to process that knowledge. In this paper, we propose a knowledge model that can be used to express both declarative knowledge about the systems’ components, their relations and their current state, as well as procedural knowledge representing possible system behavior. In addition, we introduce a framework for knowledge management and automated reasoning (KMARF). The idea behind KMARF is to automatically select an appropriate problem solver based on formalized reasoning expertise in the knowledge base, and convert a problem definition to the corresponding format. This approach automates reasoning, thus reducing operational costs, and enables reusability of knowledge and methods across different domains. We illustrate the approach on a transportation planning use case.
Compressive Sensing via Convolutional Factor Analysis
We solve the compressive sensing problem via convolutional factor analysis, where the convolutional dictionaries are learned {\em in situ} from the compressed measurements. An alternating direction method of multipliers (ADMM) paradigm for compressive sensing inversion based on convolutional factor analysis is developed. The proposed algorithm provides reconstructed images as well as features, which can be directly used for recognition (
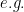
, classification) tasks. When a deep (multilayer) model is constructed, a stochastic unpooling process is employed to build a generative model. During reconstruction and testing, we project the upper layer dictionary to the data level and only a single layer deconvolution is required. We demonstrate that using
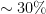
(relative to pixel numbers) compressed measurements, the proposed model achieves the classification accuracy comparable to the original data on MNIST. We also observe that when the compressed measurements are very limited (
,

), the upper layer dictionary can provide better reconstruction results than the bottom layer.
RUBER: An Unsupervised Method for Automatic Evaluation of Open-Domain Dialog Systems
Open-domain human-computer conversation has been attracting increasing attention over the past few years. However, there does not exist a standard automatic evaluation metric for open-domain dialog systems; researchers usually resort to human annotation for model evaluation, which is time- and labor-intensive. In this paper, we propose RUBER, a Referenced metric and Unreferenced metric Blended Evaluation Routine, which evaluates a reply by taking into consideration both a groundtruth reply and a query (previous user utterance). Our metric is learnable, but its training does not require labels of human satisfaction. Hence, RUBER is flexible and extensible to different datasets and languages. Experiments on both retrieval and generative dialog systems show that RUBER has high correlation with human annotation.
Job Detection in Twitter
In this report, we propose a new application for twitter data called \textit{job detection}. We identify people’s job category based on their tweets. As a preliminary work, we limited our task to identify only IT workers from other job holders. We have used and compared both simple bag of words model and a document representation based on Skip-gram model. Our results show that the model based on Skip-gram, achieves a 76\% precision and 82\% recall.
Digital Advertising Traffic Operation: Flow Management Analysis
In a Web Advertising Traffic Operation the Trafficking Routing Problem (TRP) consists in scheduling the management of Web Advertising (Adv) campaign between Trafficking campaigns in the most efficient way to oversee and manage relationship with partners and internal teams, managing expectations through integration and post-launch in order to ensure success for every stakeholders involved. For our own interest we did that independent research projects also through specific innovative tasks validate towards average working time declared on ‘specification required’ by the main worldwide industry leading Advertising Agency. We present a Mixed Integer Linear Programming (MILP) formulation for end-to-end management of campaign workflow along a predetermined path and generalize it to include alternative path to oversee and manage detail-oriented relationship with partners and internal teams to achieve the goals above mentioned. To meet clients’ KPIs, we consider an objective function that includes the punctuality indicators (the average waiting time and completion times) but also the main punctuality indicators (the average delay and the on time performance). Then we investigate their analytical relationships in the advertising domain through experiments based on real data from a Traffic Office. We show that the classic punctuality indicators are in contradiction with the task of reducing waiting times. We propose new indicators used for a synthesize analysis on projects or process changes for the wider team that are more sustainable, but also more relevant for stakeholders. We also show that the flow of a campaign (adv-ways) is the main bottleneck of a Traffic Office and that alternate paths cannot improve the performance indicators.
• Uncovering the Spatiotemporal Patterns of Collective Social Activity
• Non-interacting central site model: localization and logarithmic entanglement growth
• Column subset selection is NP-complete
• A Generalization of the Chu-Vandermonde Convolution and some Harmonic Number Identities
• Governing singularities of symmetric orbit closures
• Universal Joint Image Clustering and Registration using Partition Information
• The Design of Order-of-Addition Experiments
• Disorder-enhanced topological protection and universal quantum criticality in a spin-3/2 topological superconductor
• Causal Best Intervention Identification via Importance Sampling
• Bidirectional American Sign Language to English Translation
• Full-reference image quality assessment-based B-mode ultrasound image similarity measure
• Equations and tropicalization of Enriques surfaces
• Recurrence of the frog model on the 3,2-alternating tree
• Kelly betting on horse races with uncertainty in probability estimates
• Tetris Hypergraphs and Combinations of Impartial Games
• Schur P-positivity and involution Stanley symmetric functions
• Strong Functional Representation Lemma and Applications to Coding Theorems
• A Unified RGB-T Saliency Detection Benchmark: Dataset, Baselines, Analysis and A Novel Approach
• On the Uniqueness of FROG Methods
• Linear Quadratic Stochastic Optimal Control Problems with Operator Coefficients: Open-Loop Solutions
• Computing Abelian regularities on RLE strings
• Selecting optimal minimum spanning trees that share a topological correspondence with phylogenetic trees
• Outer limits of subdifferentials for min-max type functions
• On finding highly connected spanning subgraphs
• Decoding as Continuous Optimization in Neural Machine Translation
• Bayesian Non-Homogeneous Markov Models via Polya-Gamma Data Augmentation with Applications to Rainfall Modeling
• Predicting some physicochemical properties of octane isomers: A topological approach using ev-degree and ve-degree Zagreb indices
• The bottom of the spectrum of time-changed processes and the maximum principle of Schrödinger operators
• $k$-shellable simplicial complexes and graphs
• Context-aware Captions from Context-agnostic Supervision
• Pollaczek contour integrals for the fixed-cycle traffic-light queue
• The Method of Pairwise Variations with Tolerances for Linearly Constrained Optimization Problems
• An axiomatic basis for Veinott’s average overtaking criterion
• The Secrecy Capacity of Gaussian MIMO Channels with Finite Memory – Full Version
• The empirical Christoffel function in Statistics and Machine Learning
• A multi-scale area-interaction model for spatio-temporal point patterns
• Multivariate Regression with Grossly Corrupted Observations: A Robust Approach and its Applications
• A note on dual demodulator continuous transmission frequency modulation technique
• Modeling Retinal Ganglion Cell Population Activity with Restricted Boltzmann Machines
• Backward Stochastic Differential Equations with no driving martingale, Markov processes and associated Pseudo Partial Differential Equations
• Optimal Compression for Two-Field Entries in Fixed-Width Memories
• A Multifaceted Evaluation of Neural versus Phrase-Based Machine Translation for 9 Language Directions
• Transactive Control of Air Conditioning Loads for Mitigating Microgrid Tie-line Power Fluctuations
• On Delay and Regret Determinization of Max-Plus Automata
• On semi-Markov processes and their Kolmogorov’s integro-differential equations
• Quantum Stabilizer Codes Can Realize Access Structures Impossible by Classical Secret Sharing
• Different Non-extensive Models for heavy-ion collisions
• A sequent calculus for the Tamari order
• Greedy Sparse Signal Reconstruction Using Matching Pursuit Based on Hope-tree
• Question Analysis for Arabic Question Answering Systems
• Robust Guaranteed-Cost Adaptive Quantum Phase Estimation
• Exponent for classical-quantum multiple access channel
• Cell Coverage Extension with Orthogonal Random Precoding for Massive MIMO Systems
• Reply to Slotnick (2017), ‘Resting-state fMRI data reflects default network activity rather than null data: A defense of commonly employed methods to correct for multiple comparisons’
• Cross-lingual RST Discourse Parsing
• Convex Mixture Regression for Quantitative Risk Assessment
• Sphere-Packing Bound for Symmetric Classical-Quantum Channels
• Distinguishing Antonyms and Synonyms in a Pattern-based Neural Network
• Revisiting Deep Image Smoothing and Intrinsic Image Decomposition
• Stein’s method for dynamical systems
• Logit stick-breaking priors for Bayesian density regression
• On the Impact of Transposition Errors in Diffusion-Based Channels
• Multi-Antenna Coded Caching
• Bivariate Rician shadowed fading model
• A General Approximation Method for Bicriteria Minimization Problems
• Node-Independent Spanning Trees in Gaussian Networks
• A support and density theorem for Markovian rough paths
• Parallel mining of time-faded heavy hitters
• Decomposing edge-colored graphs under color degree constraints
• The Saturation Number of Induced Subposets of the Boolean Lattice
• On the Tradeoff Region of Secure Exact-Repair Regenerating Codes
• Decoding with Finite-State Transducers on GPUs
• On Critical Independent Sets of a Graph and Structure of Unicyclic Non-König-Egerváry Graphs
• Modeling Grasp Motor Imagery through Deep Conditional Generative Models
• Robust Group LASSO Over Decentralized Networks
• Linear Search with Terrain-Dependent Speeds
• Efficient Twitter Sentiment Classification using Subjective Distant Supervision
• Proceedings of the Workshop on High Performance Energy Efficient Embedded Systems (HIP3ES) 2017
• Apartments preserving transformations of Grassmannians of infinite-dimensional vector spaces
• CNN-based Segmentation of Medical Imaging Data
• Robust Distributed Control of DC Microgrids with Time-Varying Power Sharing
• Model Spaces of Regularity Structures for Space-Fractional SPDEs
• A More General Robust Loss Function
• On Stein’s method and mod-* convergence
• Bayesian estimation of Differential Transcript Usage from RNA-seq data
• On the Azuma inequality in spaces of subgaussian of rank $p$ random variables
Like this:
Like Loading...