Critical Behavior from Deep Dynamics: A Hidden Dimension in Natural Language
We show that although many important data sequences – from texts in different languages to melodies and genomes – exhibit critical behavior, where the mutual information between symbols decays roughly like a power law with separation, Markov processes generically do not, their mutual information instead decaying exponentially. This explains why natural languages are very poorly approximated by Markov processes. We also present a broad class of models that naturally produce critical behavior. They all involve deep dynamics of a recursive nature, as can be implemented by tree-like or recurrent deep neural networks. This model class captures the essence of recursive universal grammar as well as recursive self-reproduction in physical phenomena such as turbulence and cosmological inflation. We derive an analytic formula for the asymptotic power law and elucidate our results in a statistical physics context: 1-dimensional models (such as a Markov models) will always fail to model natural language, because they cannot exhibit phase transitions, whereas models with one or more ‘hidden’ dimensions representing levels of abstraction or scale can potentially succeed.
Scalable Support Vector Machine for Semi-supervised Learning
Owing to the prevalence of unlabeled data, semisupervised learning has recently drawn significant attention and has found applicable in many real-world applications. In this paper, we present the so-called Graph-based Semi-supervised Support Vector Machine (gS3VM), a method that leverages the excellent generalization ability of kernel-based method with the geometrical and distributive information carried in a spectral graph for semi-supervised learning purpose. The proposed gS3VM can be solved directly in the primal form using the Stochastic Gradient Descent method with the ideal convergence rate

. Besides, our gS3VM allows the combinations of a wide spectrum of loss functions (e.g., Hinge, smooth Hinge, Logistic, L1, and {\epsilon}-insensitive) and smoothness functions (i.e.,
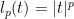
with

). We note that the well-known Laplacian Support Vector Machine falls into the spectrum of gS3VM corresponding to the combination of the Hinge loss and the smoothness function

. We further validate our proposed method on several benchmark datasets to demonstrate that gS3VM is appropriate for the large-scale datasets since it is optimal in memory used and yields superior classification accuracy whilst simultaneously achieving a significant computation speedup in comparison with the state-of-the-art baselines.
Link Prediction via Matrix Completion
Inspired by practical importance of social networks, economic networks, biological networks and so on, studies on large and complex networks have attracted a surge of attentions in the recent years. Link prediction is a fundamental issue to understand the mechanisms by which new links are added to the networks. We introduce the method of robust principal component analysis (robust PCA) into link prediction, and estimate the missing entries of the adjacency matrix. On one hand, our algorithm is based on the sparsity and low rank property of the matrix, on the other hand, it also performs very well when the network is dense. This is because a relatively dense real network is also sparse in comparison to the complete graph. According to extensive experiments on real networks from disparate fields, when the target network is connected and sufficiently dense, whatever it is weighted or unweighted, our method is demonstrated to be very effective and with prediction accuracy being considerably improved comparing with many state-of-the-art algorithms.
An Approach for Parallel Genetic Algorithms in the Cloud using Software Containers
Genetic Algorithms (GAs) are a powerful technique to address hard optimisation problems. However, scalability issues might prevent them from being applied to real-world problems. Exploiting parallel GAs in the cloud might be an affordable approach to get time efficient solutions that benefit of the appealing features of the cloud, such as scalability, reliability, fault-tolerance and cost-effectiveness. Nevertheless, distributed computation is very prone to cause considerable overhead for communication and making GAs distributed in an on-demand fashion is not trivial. Aiming to keep under control the communication overhead and support GAs developers in the construction and deployment of parallel GAs in the cloud, in this paper we propose an approach to distribute GAs using the global parallelisation model, exploiting software containers and their cloud orchestration. We also devised a conceptual workflow covering each cloud GAs distribution phase, from resources allocation to actual deployment and execution, in a DevOps fashion.
Robust Identifiability in Sparse Dictionary Learning
Sparse coding or sparse dictionary learning methods have exposed underlying sparse structure in many kinds of natural data. Here, we generalize previous results guaranteeing when the learned dictionary and sparse codes are unique up to inherent permutation and scaling ambiguities. We show that these solutions are robust to the addition of measurement noise provided the data samples are sufficiently diverse. Central to our proofs is a useful lemma in combinatorial matrix theory which allows us to derive bounds on the number of samples necessary to guarantee uniqueness. We also provide probabilistic extensions to our robust identifiability theorem and an extension to the case where only an upper bound on the number of dictionary elements is known a priori. Our results help to inform the interpretation of sparse structure learned from data; whenever the conditions to one of our robust identifiability theorems are met, any sparsity-constrained algorithm that succeeds in approximately reconstructing the data well enough recovers the original dictionary and sparse codes up to an error commensurate with the noise. We discuss applications of this result to smoothed analysis, communication theory, and applied physics and engineering.
Efficient Attack Graph Analysis through Approximate Inference
Attack graphs provide compact representations of the attack paths that an attacker can follow to compromise network resources by analysing network vulnerabilities and topology. These representations are a powerful tool for security risk assessment. Bayesian inference on attack graphs enables the estimation of the risk of compromise to the system’s components given their vulnerabilities and interconnections, and accounts for multi-step attacks spreading through the system. Whilst static analysis considers the risk posture at rest, dynamic analysis also accounts for evidence of compromise, e.g. from SIEM software or forensic investigation. However, in this context, exact Bayesian inference techniques do not scale well. In this paper we show how Loopy Belief Propagation – an approximate inference technique – can be applied to attack graphs, and that it scales linearly in the number of nodes for both static and dynamic analysis, making such analyses viable for larger networks. We experiment with different topologies and network clustering on synthetic Bayesian attack graphs with thousands of nodes to show that the algorithm’s accuracy is acceptable and converge to a stable solution. We compare sequential and parallel versions of Loopy Belief Propagation with exact inference techniques for both static and dynamic analysis, showing the advantages of approximate inference techniques to scale to larger attack graphs.
• Approximate Recovery in Changepoint Problems, from $\ell_2$ Estimation Error Rates
• Comparing cosmic web classifiers using information theory
• Discrete Capacity and Higher-order Differences of Two-state Markov Chains
• Modification of the MDR-EFE method for stratified samples
• On Linial’s Conjecture for Spine Digraphs
• A Stackelberg Game Perspective on the Conflict Between Machine Learning and Data Obfuscation
• An autoregressive process with correlated random coefficients
• A construction of distance cospectral graphs
• Étude de Problèmes d’Optimisation Combinatoire à Multiples Composantes Interdépendantes
• On the number of cliques in graphs with a forbidden subdivision or immersion
• Learning Optimal Card Ranking from Query Reformulation
• Evolutionary computation for multicomponent problems: opportunities and future directions
• A New Twist on Wythoff’s Game
• Divergent Discourse Between Protests and Counter-Protests: #BlackLivesMatter and #AllLivesMatter
• Note on Terminal-Pairability in Complete Grid Graphs
• Model-based clustering based on sparse finite Gaussian mixtures
• Lagrangian calculus for non-symmetric diffusion operators
• Probabilistic Integration and Intractable Distributions
• Competitive Equilibria for Non-quasilinear Bidders in Combinatorial Auctions
• A Curriculum Learning Method for Improved Noise Robustness in Automatic Speech Recognition
• A Comprehensive Study of Deep Bidirectional LSTM RNNs for Acoustic Modeling in Speech Recognition
• A Moran coefficient-based mixed effects approach to investigate spatially varying relationships
• Structure in the Value Function of Two-Player Zero-Sum Games of Incomplete Information
• Finite-Size Effects on Traveling Wave Solutions to Neural Field Equations
• Inferring Logical Forms From Denotations
• Complete graphical characterization and construction of adjustment sets in Markov equivalence classes of ancestral graphs
• Learning text representation using recurrent convolutional neural network with highway layers
• Spatial Bayesian Latent Factor Regression Modeling of Coordinate-based Meta-analysis Data
• Towards Strong Reverse Minkowski-type Inequalities for Lattices
• Think Eternally: Improved Algorithms for the Temp Secretary Problem and Extensions
• Semidefinite bounds for mixed binary/ternary codes
• Estimation for stochastic damping Hamiltonian systems under partial observation. III. Diffusion term
• On the abelian complexity of the Rudin-Shapiro sequence
• Disordered double Weyl node: Comparison of transport and density-of-states calculations
• Quasisymmetric (k,l)-hook Schur functions
• A segmental framework for fully-unsupervised large-vocabulary speech recognition
• Statistics of topological RNA structures
• Matching polytons
• Dealing with a large number of classes — Likelihood, Discrimination or Ranking?
• Towards stationary time-vertex signal processing
• Computing hypergeometric functions rigorously
• Simultaneous Control and Human Feedback in the Training of a Robotic Agent with Actor-Critic Reinforcement Learning
• Recursive kernel density estimators under missing data
• Toward Word Embedding for Personalized Information Retrieval
• Exact mean integrated squared error of kernel distribution function estimators
• The word entropy of natural languages
• Second order behavior of the block counting process of beta coalescents
• Using Word Embeddings in Twitter Election Classification
• Stochastic solutions of Conformable fractional Cauchy problems
• Extremes of $α(t)$-Locally stationary Gaussian processes with non-constant variances
• Moment convergence of balanced Pólya processes
• The log-Sobolev inequality with quadratic interactions
• Ancestral Causal Inference
• Toward Interpretable Topic Discovery via Anchored Correlation Explanation
• Semantic Parsing to Probabilistic Programs for Situated Question Answering
• Dimension of the SLE light cone, the SLE fan, and SLE$_κ(ρ)$ for $κ\in (0,4)$ and $ρ\in [\tfracκ{2}-4,-2)$
• Emulating Human Conversations using Convolutional Neural Network-based IR
Like this:
Like Loading...