Robust mixture regression modeling based on the Generalized M (GM)-estimation method
Bai (2010) and Bai et al. (2012) proposed robust mixture regression method based on the M regression estimation. However, the M-estimators are robust against the outliers in response variables, but they are not robust against the outliers in explanatory variables (leverage points). In this paper, we propose a robust mixture regression procedure to handle the outliers and the leverage points, simultaneously. Our proposed mixture regression method is based on the GM regression estimation. We give an Expectation Maximization (EM) type algorithm to compute estimates for the parameters of interest. We provide a simulation study and a real data example to assess the robustness performance of the proposed method against the outliers and the leverage points.
Modular Autoencoders for Ensemble Feature Extraction
We introduce the concept of a Modular Autoencoder (MAE), capable of learning a set of diverse but complementary representations from unlabelled data, that can later be used for supervised tasks. The learning of the representations is controlled by a trade off parameter, and we show on six benchmark datasets the optimum lies between two extremes: a set of smaller, independent autoencoders each with low capacity, versus a single monolithic encoding, outperforming an appropriate baseline. In the present paper we explore the special case of linear MAE, and derive an SVD-based algorithm which converges several orders of magnitude faster than gradient descent.
Learning Simple Algorithms from Examples
We present an approach for learning simple algorithms such as copying, multi-digit addition and single digit multiplication directly from examples. Our framework consists of a set of interfaces, accessed by a controller. Typical interfaces are 1-D tapes or 2-D grids that hold the input and output data. For the controller, we explore a range of neural network-based models which vary in their ability to abstract the underlying algorithm from training instances and generalize to test examples with many thousands of digits. The controller is trained using

-learning with several enhancements and we show that the bottleneck is in the capabilities of the controller rather than in the search incurred by
-learning.
Bayesian Minimal Description Lengths for Multiple Changepoint Detection
This paper develops a minimum description length (MDL) multiple changepoint detection procedure that allows for prior distributions. MDL methods, which are penalized likelihood techniques with penalties based on data description-length information principles, have been successfully applied to many recent multiple changepoint problems. This work shows how to modify the MDL penalty to account for various prior knowledge. Our motivation lies in climatology. Here, a metadata record, which is a file listing times when a recording station physically moved, instrumentation was changed, etc., sometimes exists. While metadata records are notoriously incomplete, they permit the construction of a prior distribution that helps detect changepoints. This allows both documented and undocumented changepoints to be analyzed in tandem. Our time series methods allow for autocorrelation, seasonal means, and multivariate aspects. Asymptotically, our estimated multiple changepoint configuration is shown to be consistent. The methods are illustrated in the analysis of 114 years of monthly temperatures from Tuscaloosa, Alabama. The multivariate aspect of the methods allow maximum and minimum temperatures to be jointly studied.
Predicting Relevance based on Assessor Disagreement: Analysis and Practical Applications for Search Evaluation
Evaluation of search engines relies on assessments of search results for selected test queries, from which we would ideally like to draw conclusions in terms of relevance of the results for general (e.g., future, unknown) users. In practice however, most evaluation scenarios only allow us to conclusively determine the relevance towards the particular assessor that provided the judgments. A factor that cannot be ignored when extending conclusions made from assessors towards users, is the possible disagreement on relevance, assuming that a single gold truth label does not exist. This paper presents and analyzes the Predicted Relevance Model (PRM), which allows predicting a particular result’s relevance for a random user, based on an observed assessment and knowledge on the average disagreement between assessors. With the PRM, existing evaluation metrics designed to measure binary assessor relevance, can be transformed into more robust and effectively graded measures that evaluate relevance towards a random user. It also leads to a principled way of quantifying multiple graded or categorical relevance levels for use as gains in established graded relevance measures, such as normalized discounted cumulative gain (nDCG), which nowadays often use heuristic and data-independent gain values. Given a set of test topics with graded relevance judgments, the PRM allows evaluating systems on different scenarios, such as their capability of retrieving top results, or how well they are able to filter out non-relevant ones. Its use in actual evaluation scenarios is illustrated on several information retrieval test collections.
Improving the performance of the linear systems solvers using CUDA
Parallel computing can offer an enormous advantage regarding the performance for very large applications in almost any field: scientific computing, computer vision, databases, data mining, and economics. GPUs are high performance many-core processors that can obtain very high FLOP rates. Since the first idea of using GPU for general purpose computing, things have evolved and now there are several approaches to GPU programming: CUDA from NVIDIA and Stream from AMD. CUDA is now a popular programming model for general purpose computations on GPU for C/C++ programmers. A great number of applications were ported to CUDA programming model and they obtain speedups of orders of magnitude comparing to optimized CPU implementations. In this paper we present an implementation of a library for solving linear systems using the CCUDA framework. We present the results of performance tests and show that using GPU one can obtain speedups of about of approximately 80 times comparing with a CPU implementation.
Medusa: An Efficient Cloud Fault-Tolerant MapReduce
Applications such as web search and social networking have been moving from centralized to decentralized cloud architectures to improve their scalability. MapReduce, a programming framework for processing large amounts of data using thousands of machines in a single cloud, also needs to be scaled out to multiple clouds to adapt to this evolution. The challenge of building a multi-cloud distributed architecture is substantial. Notwithstanding, the ability to deal with the new types of faults introduced by such setting, such as the outage of a whole datacenter or an arbitrary fault caused by a malicious cloud insider, increases the endeavor considerably. In this paper we propose Medusa, a platform that allows MapReduce computations to scale out to multiple clouds and tolerate several types of faults. Our solution fulfills four objectives. First, it is transparent to the user, who writes her typical MapReduce application without modification. Second, it does not require any modification to the widely used Hadoop framework. Third, the proposed system goes well beyond the fault-tolerance offered by MapReduce to tolerate arbitrary faults, cloud outages, and even malicious faults caused by corrupt cloud insiders. Fourth, it achieves this increased level of fault tolerance at reasonable cost. We performed an extensive experimental evaluation in the ExoGENI testbed, demonstrating that our solution significantly reduces execution time when compared to traditional methods that achieve the same level of resilience.
NearBucket-LSH: Efficient Similarity Search in P2P Networks
We present NearBucket-LSH, an effective algorithm for similarity search in large-scale distributed online social networks organized as peer-to-peer overlays. As communication is a dominant consideration in distributed systems, we focus on minimizing the network cost while guaranteeing good search quality. Our algorithm is based on Locality Sensitive Hashing (LSH), which limits the search to collections of objects, called buckets, that have a high probability to be similar to the query. More specifically, NearBucket-LSH employs an LSH extension that searches in near buckets, and improves search quality but also significantly increases the network cost. We decrease the network cost by considering the internals of both LSH and the P2P overlay, and harnessing their properties to our needs. We show that our NearBucket-LSH increases search quality for a given network cost compared to previous art. In many cases, the search quality increases by more than 50%.
A PAC Approach to Application-Specific Algorithm Selection
The best algorithm for a computational problem generally depends on the ‘relevant inputs,’ a concept that depends on the application domain and often defies formal articulation. While there is a large literature on empirical approaches to selecting the best algorithm for a given application domain, there has been surprisingly little theoretical analysis of the problem. This paper adapts concepts from statistical and online learning theory to reason about application-specific algorithm selection. Our models capture several state-of-the-art empirical and theoretical approaches to the problem, ranging from self-improving algorithms to empirical performance models, and our results identify conditions under which these approaches are guaranteed to perform well. We present one framework that models algorithm selection as a statistical learning problem, and our work here shows that dimension notions from statistical learning theory, historically used to measure the complexity of classes of binary- and real-valued functions, are relevant in a much broader algorithmic context. We also study the online version of the algorithm selection problem, and give possibility and impossibility results for the existence of no-regret learning algorithms.
Parallel Predictive Entropy Search for Batch Global Optimization of Expensive Objective Functions
We develop parallel predictive entropy search (PPES), a novel algorithm for Bayesian optimization of expensive black-box objective functions. At each iteration, PPES aims to select a batch of points which will maximize the information gain about the global maximizer of the objective. Well known strategies exist for suggesting a single evaluation point based on previous observations, while far fewer are known for selecting batches of points to evaluate in parallel. The few batch selection schemes that have been studied all resort to greedy methods to compute an optimal batch. To the best of our knowledge, PPES is the first non-greedy batch Bayesian optimization strategy. We demonstrate the benefit of this approach in optimization performance on both synthetic and real world applications, including problems in machine learning, rocket science and robotics.
Visual Word2Vec (vis-w2v): Learning Visually Grounded Word Embeddings Using Abstract Scenes
We propose a model to learn visually grounded word embeddings (vis-w2v) to capture visual notions of semantic relatedness. While word embeddings trained using text have been extremely successful, they cannot uncover notions of semantic relatedness implicit in our visual world. For instance, visual grounding can help us realize that concepts like eating and staring at are related, since when people are eating something, they also tend to stare at the food. Grounding a rich variety of relations like eating and stare at in vision is a challenging task, despite recent progress in vision. We realize the visual grounding for words depends on the semantics of our visual world, and not the literal pixels. We thus use abstract scenes created from clipart to provide the visual grounding. We find that the embeddings we learn capture fine-grained visually grounded notions of semantic relatedness. We show improvements over text only word embeddings (word2vec) on three tasks: common-sense assertion classification, visual paraphrasing and text-based image retrieval. Our code and datasets will be available online.
Anvaya: An Algorithm and Case-Study on Improving the Goodness of Software Process Models generated by Mining Event-Log Data in Issue Tracking System
Issue Tracking Systems (ITS) such as Bugzilla can be viewed as Process Aware Information Systems (PAIS) generating event-logs during the life-cycle of a bug report. Process Mining consists of mining event logs generated from PAIS for process model discovery, conformance and enhancement. We apply process map discovery techniques to mine event trace data generated from ITS of open source Firefox browser project to generate and study process models. Bug life-cycle consists of diversity and variance. Therefore, the process models generated from the event-logs are spaghetti-like with large number of edges, inter-connections and nodes. Such models are complex to analyse and difficult to comprehend by a process analyst. We improve the Goodness (fitness and structural complexity) of the process models by splitting the event-log into homogeneous subsets by clustering structurally similar traces. We adapt the K-Medoid clustering algorithm with two different distance metrics: Longest Common Subsequence (LCS) and Dynamic Time Warping (DTW). We evaluate the goodness of the process models generated from the clusters using complexity and fitness metrics. We study back-forth \& self-loops, bug reopening, and bottleneck in the clusters obtained and show that clustering enables better analysis. We also propose an algorithm to automate the clustering process -the algorithm takes as input the event log and returns the best cluster set.
Performance Analysis of Apriori Algorithm with Different Data Structures on Hadoop Cluster
Mining frequent itemsets from massive datasets is always being a most important problem of data mining. Apriori is the most popular and simplest algorithm for frequent itemset mining. To enhance the efficiency and scalability of Apriori, a number of algorithms have been proposed addressing the design of efficient data structures, minimizing database scan and parallel and distributed processing. MapReduce is the emerging parallel and distributed technology to process big datasets on Hadoop Cluster. To mine big datasets it is essential to re-design the data mining algorithm on this new paradigm. In this paper, we implement three variations of Apriori algorithm using data structures hash tree, trie and hash table trie i.e. trie with hash technique on MapReduce paradigm. We emphasize and investigate the significance of these three data structures for Apriori algorithm on Hadoop cluster, which has not been given attention yet. Experiments are carried out on both real life and synthetic datasets which shows that hash table trie data structures performs far better than trie and hash tree in terms of execution time. Moreover the performance in case of hash tree becomes worst.
Analysis of a Play by Means of CHAPLIN, the Characters and Places Interaction Network Software
Recently, we have developed a software able of gathering information on social networks from written texts. This software, the CHAracters and PLaces Interaction Network (CHAPLIN) tool, is implemented in Visual Basic. By means of it, characters and places of a literary work can be extracted from a list of raw words. The software interface helps users to select their names out of this list. Setting some parameters, CHAPLIN creates a network where nodes represent characters/places and edges give their interactions. Nodes and edges are labelled by performances. In this paper, we propose to use CHAPLIN for the analysis a William Shakespeare’s play, the famous ‘Tragedy of Hamlet, Prince of Denmark’. Performances of characters in the play as a whole and in each act of it are given by graphs.
Evolutionary algorithms
This manuscript contains an outline of lectures course ‘Evolutionary Algorithms’ read by the author in Omsk State University n.a. F.M.Dostoevsky. The course covers Canonic Genetic Algorithm and various other genetic algorithms as well as evolutioanry algorithms in general. Some facts, such as the Rotation Property of crossover, the Schemata Theorem, GA performance as a local search and ‘almost surely’ convergence of evolutionary algorithms are given with complete proofs. The text is in Russian.
An Integrated Framework to Recommend Personalized Retention Actions to Control B2C E-Commerce Customer Churn
Considering the level of competition prevailing in Business-to-Consumer (B2C) E-Commerce domain and the huge investments required to attract new customers, firms are now giving more focus to reduce their customer churn rate. Churn rate is the ratio of customers who part away with the firm in a specific time period. One of the best mechanism to retain current customers is to identify any potential churn and respond fast to prevent it. Detecting early signs of a potential churn, recognizing what the customer is looking for by the movement and automating personalized win back campaigns are essential to sustain business in this era of competition. E-Commerce firms normally possess large volume of data pertaining to their existing customers like transaction history, search history, periodicity of purchases, etc. Data mining techniques can be applied to analyse customer behaviour and to predict the potential customer attrition so that special marketing strategies can be adopted to retain them. This paper proposes an integrated model that can predict customer churn and also recommend personalized win back actions.
Enumerating Periodic Points of Certain Sequential Dynamical Systems
A sequential dynamical system (SDS) consists of an undirected simple graph

with vertices

, a collection of vertex functions

, a permutation
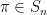
, and a collection of states

. In this system, vertices update their states in a sequential order specified by

using the vertex functions
. Any sequential dynamical system gives rise to an SDS-map
![[Y,\{f_{v_i}\}_{i=1}^n,\pi]](https://s0.wp.com/latex.php?latex=%5BY%2C%5C%7Bf_%7Bv_i%7D%5C%7D_%7Bi%3D1%7D%5En%2C%5Cpi%5D&bg=ffffff&fg=000&s=0&c=20201002)
, which maps each initial configuration of vertex states to the new configuration of states obtained after each vertex updates. Consider the two SDS-maps
![[C_n,\text{parity}_3,\text{id}]](https://s0.wp.com/latex.php?latex=%5BC_n%2C%5Ctext%7Bparity%7D_3%2C%5Ctext%7Bid%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
and
![[C_n,(1+\text{parity})_3,\text{id}]](https://s0.wp.com/latex.php?latex=%5BC_n%2C%281%2B%5Ctext%7Bparity%7D%29_3%2C%5Ctext%7Bid%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
. Let
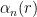
and

denote the number of periodic points of period

of the maps
and
, respectively. We give explicit formulas for
and
for any

with
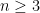
. Surprisingly, if we fix
and vary

, then we find that there are only two possible nonzero values of
and one possible nonzero value of
.
On the Linear Algebraic Structure of Distributed Word Representations
In this work, we leverage the linear algebraic structure of distributed word representations to automatically extend knowledge bases and allow a machine to learn new facts about the world. Our goal is to extract structured facts from corpora in a simpler manner, without applying classifiers or patterns, and using only the co-occurrence statistics of words. We demonstrate that the linear algebraic structure of word embeddings can be used to reduce data requirements for methods of learning facts. In particular, we demonstrate that words belonging to a common category, or pairs of words satisfying a certain relation, form a low-rank subspace in the projected space. We compute a basis for this low-rank subspace using singular value decomposition (SVD), then use this basis to discover new facts and to fit vectors for less frequent words which we do not yet have vectors for.
Session-based Recommendations with Recurrent Neural Networks
We apply recurrent neural networks (RNN) on a new domain, namely recommendation system. Real-life recommender systems often face the problem of having to base recommendations only on short session-based data (e.g. a small sportsware website) instead of long user histories (as in the case of Netflix). In this situation the frequently praised matrix factorization approaches are not accurate. This problem is usually overcome in practice by resorting to item-to-item recommendations, i.e. recommending similar items. We argue that by modeling the whole session, more accurate recommendations can be provided. We therefore propose an RNN-based approach for session-based recommendations. Our approach also considers practical aspects of the task and introduces several modifications to classic RNNs such as a ranking loss function that make it more viable for this specific problem. Experimental results on two data-sets show marked improvements over widely used approaches.
BlackOut: Speeding up Recurrent Neural Network Language Models With Very Large Vocabularies
We propose BlackOut, an approximation algorithm to efficiently train massive recurrent neural network language models (RNNLMs) with million word vocabularies. BlackOut is motivated by using a discriminative loss, and we describe a new sampling strategy which significantly reduces computation while improving stability, sample efficiency, and rate of convergence. One way to understand BlackOut is to view it as an extension of the DropOut strategy to the output layer, wherein we use a discriminative training loss and a weighted sampling scheme. We also establish close connections between BlackOut, importance sampling, and noise contrastive estimation (NCE). Our experiments, on the recently released one billion word language modeling benchmark, demonstrate scalability and accuracy of BlackOut; we outperform the state-of-the art, and achieve the lowest perplexity scores on this dataset. Moreover, unlike other established methods which typically require GPUs or CPU clusters, we show that a carefully implemented version of BlackOut requires only 1-10 days on a single machine to train a RNNLM with a million word vocabulary and billions of parameters on one billion of words.
Online Sequence Training of Recurrent Neural Networks with Connectionist Temporal Classification
Connectionist temporal classification (CTC) based supervised sequence training of recurrent neural networks (RNNs) has shown great success in many machine learning areas including end-to-end speech and handwritten character recognition. For the CTC training, however, it is required to unroll the RNN by the length of an input sequence. This unrolling requires a lot of memory and hinders a small footprint implementation of online learning or adaptation. Furthermore, the length of training sequences is usually not uniform, which makes parallel training with multiple sequences inefficient on shared memory models such as graphics processing units (GPUs). In this work, we introduce an expectation-maximization (EM) based online CTC algorithm that enables unidirectional RNNs to learn sequences that are longer than the amount of unrolling. The RNNs can also be trained to process an infinitely long input sequence without pre-segmentation or external reset. Moreover, the proposed approach allows efficient parallel training on GPUs. For evaluation, end-to-end speech recognition examples are presented on the Wall Street Journal (WSJ) corpus.
GradNets: Dynamic Interpolation Between Neural Architectures
In machine learning, there is a fundamental trade-off between ease of optimization and expressive power. Neural Networks, in particular, have enormous expressive power and yet are notoriously challenging to train. The nature of that optimization challenge changes over the course of learning. Traditionally in deep learning, one makes a static trade-off between the needs of early and late optimization. In this paper, we investigate a novel framework, GradNets, for dynamically adapting architectures during training to get the benefits of both. For example, we can gradually transition from linear to non-linear networks, deterministic to stochastic computation, shallow to deep architectures, or even simple downsampling to fully differentiable attention mechanisms. Benefits include increased accuracy, easier convergence with more complex architectures, solutions to test-time execution of batch normalization, and the ability to train networks of up to 200 layers.
Kernel Additive Principal Components
Additive principal components (APCs for short) are a nonlinear generalization of linear principal components. We focus on smallest APCs to describe additive nonlinear constraints that are approximately satisfied by the data. Thus APCs fit data with implicit equations that treat the variables symmetrically, as opposed to regression analyses which fit data with explicit equations that treat the data asymmetrically by singling out a response variable. We propose a regularized data-analytic procedure for APC estimation using kernel methods. In contrast to existing approaches to APCs that are based on regularization through subspace restriction, kernel methods achieve regularization through shrinkage and therefore grant distinctive flexibility in APC estimation by allowing the use of infinite-dimensional functions spaces for searching APC transformation while retaining computational feasibility. To connect population APCs and kernelized finite-sample APCs, we study kernelized population APCs and their associated eigenproblems, which eventually lead to the establishment of consistency of the estimated APCs. Lastly, we discuss an iterative algorithm for computing kernelized finite-sample APCs.
An Empirical Comparison of the Summarization Power of Graph Clustering Methods
How do graph clustering techniques compare with respect to their summarization power? How well can they summarize a million-node graph with a few representative structures? Graph clustering or community detection algorithms can summarize a graph in terms of coherent and tightly connected clusters. In this paper, we compare and contrast different techniques: METIS, Louvain, spectral clustering, SlashBurn and KCBC, our proposed k-core-based clustering method. Unlike prior work that focuses on various measures of cluster quality, we use vocabulary structures that often appear in real graphs and the Minimum Description Length (MDL) principle to obtain a graph summary per clustering method. Our main contributions are: (i) Formulation: We propose a summarization-based evaluation of clustering methods. Our method, VOG-OVERLAP, concisely summarizes graphs in terms of their important structures which lead to small edge overlap, and large node/edge coverage; (ii) Algorithm: we introduce KCBC, a graph decomposition technique, in the heart of which lies the k-core algorithm (iii) Evaluation: We compare the summarization power of five clustering techniques on large real graphs, and analyze their compression performance, summary statistics and runtimes.
Bayesian SPLDA
In this document we are going to derive the equations needed to implement a Variational Bayes estimation of the parameters of the simplified probabilistic linear discriminant analysis (SPLDA) model. This can be used to adapt SPLDA from one database to another with few development data or to implement the fully Bayesian recipe. Our approach is similar to Bishop’s VB PPCA.
• Sustainability in the Stochastic Ramsey Model
• Anomalous Hall effect in 2D Rashba ferromagnet
• Approximation Algorithms for Route Planning with Nonlinear Objectives
• Convolutional Pseudo-Prior for Structured Labeling
• Right-handed bialgebras and the Prelie forest formula
• MazeBase: A Sandbox for Learning from Games
• Maximum of the characteristic polynomial of random unitary matrices
• 2D phononic crystals: Disorder matters
• Approximation of stochastic processes by non-expansive flows and coming down from infinity
• Cache Miss Estimation for Non-Stationary Request Processes
• Surpassing Humans in Boundary Detection using Deep Learning
• Equivalence of the Brownian and energy representations
• GPU-based Acceleration of Deep Convolutional Neural Networks on Mobile Platforms
• What is the plausibility of probability?(revised 2003, 2015)
• Black box variational inference for state space models
• Interpretable Two-level Boolean Rule Learning for Classification
• Switched Dynamical Latent Force Models for Modelling Transcriptional Regulation
• Directed random polymers via nested contour integrals
• Asymptotics for some polynomial patterns in the primes
• 1-perfectly orientable graphs and graph products
• Adapting the serial Alpgen event generator to simulate LHC collisions on millions of parallel threads
• The arithmetical rank of the edge ideals of graphs with pairwise disjoint cycles
• Spatial coherence of thermal photons favors photosynthetic life
• Ramsey numbers of trees and unicyclic graphs versus fans
• Block Matrix Formulations for Evolving Networks
• Convergence Results for a Class of Time-Varying Simulated Annealing Algorithms
• On Partitioning the Edges of 1-Planar Graphs
• Stochastic Parallel Block Coordinate Descent for Large-scale Saddle Point Problems
• Sparse Recovery via Partial Regularization: Models, Theory and Algorithms
• Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs)
• Cyclic groups are CI-groups for balanced configurations
• Sparse Linear Models applied to Power Quality Disturbance Classification
• The number of trees in a graph
• Automorphism groups of Cayley graphs generated by block transpositions and regular Cayley maps
• Ridge Leverage Scores for Low-Rank Approximation
• A Python Extension for the Massively Parallel Multiphysics Simulation Framework waLBerla
• New results on maximal partial line spreads in PG(5,q)
• On the total $(k,r)$-domination number of random graphs
• Theta characteristics of hyperelliptic graphs
• Robust hedging of options on local time
• On sums of binomial coefficients modulo $p^2$
• Different kinds of chimera death states in nonlocally coupled oscillators
• Positive Discrete Spectrum of the Evolutionary Operator of Supercritical Branching Walks with Heavy Tails
• Noisy Submodular Maximization via Adaptive Sampling with Applications to Crowdsourced Image Collection Summarization
• Multi-Agent Continuous Transportation with Online Balanced Partitioning
• Hölder-type inequalities and their applications to concentration and correlation bounds
• Longest Gapped Repeats and Palindromes
• Detection of Uniform and Non-Uniform Differential Item Functioning by Item Focussed Trees
• Developing a High Performance Software Library with MPI and CUDA for Matrix Computations
• Associativity and non-associativity of some hypergraph products
• A supersymmetric approach to martingales related to the vertex-reinforced jump process
• Increasing the minimum distance of codes by twisting
• The Kuramoto model in complex networks
• Trajectories entropy in dynamical graphs with memory
• An integral inequality for the invariant measure of a stochastic reaction–diffusion equation
• What Happened to My Dog in That Network: Unraveling Top-down Generators in Convolutional Neural Networks
• Cascading Denoising Auto-Encoder as a Deep Directed Generative Model
• On the Generalization Error Bounds of Neural Networks under Diversity-Inducing Mutual Angular Regularization
• Modelling latent individual heterogeneity in mark-recapture data with Dirichlet process priors
• Efficient MCMC implementation of multi-state mark-recapture models
• Metric Entropy estimation using o-minimality Theory
• Exponential decay rate of partial autocorrelation coefficients of ARMA and short-memory processes
• Multiple–Instance Learning: Christoffel Function Approach to Distribution Regression Problem
• Constructions in Ramsey theory
• Site and bond percolation thresholds in $K_{n,n}$-based lattices: Vulnerability of quantum annealers to random qubit and coupler failures on Chimera topologies
• Max-sum diversity via convex programming
• A Plausible Memristor Implementation of Deep Learning Neural Networks
• Which Regular Expression Patterns are Hard to Match?
• ReSeg: A Recurrent Neural Network for Object Segmentation
• The False Discovery Rate (FDR) of Multiple Tests in a Class Room Lecture
• Constant Factor Approximation for ATSP with Two Edge Weights
• Another Generalization of Unimodality
• Detecting Road Surface Wetness from Audio: A Deep Learning Approach
• Partial Coherence Estimation via Spectral Matrix Shrinkage under Quadratic Loss
• Pattern Recognition on Oriented Matroids: Symmetric Cycles in the Hypercube Graphs
• On a Natural Dynamics for Linear Programming
• Convergence of Stochastic Interacting Particle Systems in Probability under a Sobolev Norm
• Understanding Music Playlists
• Non-Sentential Utterances in Dialogue: Experiments in Classification and Interpretation
• Standardness as an invariant formulation of independence
• End-to-end Learning of Action Detection from Frame Glimpses in Videos
• On the quasi-depth of squarefree monomial ideals and the sdepth of the monomial ideal of independent sets of a graph
• Generating Configurable Hardware from Parallel Patterns
• Online Semi-Supervised Learning with Deep Hybrid Boltzmann Machines and Denoising Autoencoders
• Gradual DropIn of Layers to Train Very Deep Neural Networks
• Discretisations of rough stochastic PDEs
• First passage percolation on the exponential of two-dimensional branching random walk
• Evaluating Prerequisite Qualities for Learning End-to-End Dialog Systems
• Large deviations for empirical measures generated by Gibbs measures with singular energy functionals
• Recycling intermediate steps to improve Hamiltonian Monte Carlo
• ICU Patient Deterioration prediction: a Data-Mining Approach
• A Simple Algorithm For Replacement Paths Problem
• On a conjecture for the signless Laplacian spectral radius of cacti with given matching number
• Bayesian binary quantile regression for the analysis of Bachelor-Master transition
• Near-Optimal Active Learning of Multi-Output Gaussian Processes
• Gaussian Process Planning with Lipschitz Continuous Reward Functions: Towards Unifying Bayesian Optimization, Active Learning, and Beyond
• The UIPQ seen from a point at infinity along its geodesic ray
• Zoom Better to See Clearer: Huamn Part Segmentation with Auto Zoom Net
• The a-graph coloring problem
• Data-dependent Initializations of Convolutional Neural Networks
• Discovering Internal Representations from Object-CNNs Using Population Encoding
• Reconstructing complex networks with binary-state dynamics
• Practical survival analysis tools for heterogeneous cohorts and informative censoring
• A State Calculus for Graph Coloring
• Mapping Images to Sentiment Adjective Noun Pairs with Factorized Neural Nets
• Expected Number and Height Distribution of Critical Points of Smooth Isotropic Gaussian Random Fields
• Semi-supervised Bootstrapping approach for Named Entity Recognition
• EMinRET: Heuristic for Energy-Aware VM Placement with Fixed Intervals and Non-preemption
• Smooth, identifiable supermodels of discrete DAG models with latent variables
• Learning visual groups from co-occurrences in space and time
• Optimal control of branching diffusion processes: a finite horizon problem
• Levi’s Lemma, pseudolinear drawings of $K_n$, and empty triangles
• Adding Gradient Noise Improves Learning for Very Deep Networks
• Conducting sparse feature selection on arbitrarily long phrases in text corpora with a focus on interpretability
• The 4-Regular Edge-Transitive Graphs of Girth 4
• Computerizing the Andrews-Fraenkel-Sellers Proofs on the Number of m-ary partitions mod m (and doing MUCH more!)
• Pseudoachromatic and connected-pseudoachromatic indices of the complete graph
• Burning a Graph is Hard
• Unifying and Strengthening Hardness for Dynamic Problems via the Online Matrix-Vector Multiplication Conjecture
• PLDA with Two Sources of Inter-session Variability
Like this:
Like Loading...