• A subsampled double bootstrap for massive data
The bootstrap is a popular and powerful method for assessing precision of estimators and inferential methods. However, for massive datasets which are increasingly prevalent, the bootstrap becomes prohibitively costly in computation and its feasibility is questionable even with modern parallel computing platforms. Recently Kleiner, Talwalkar, Sarkar, and Jordan (2014) proposed a method called BLB (Bag of Little Bootstraps) for massive data which is more computationally scalable with little sacrifice of statistical accuracy. Building on BLB and the idea of fast double bootstrap, we propose a new resampling method, the subsampled double bootstrap, for both independent data and time series data. We establish consistency of the subsampled double bootstrap under mild conditions for both independent and dependent cases. Methodologically, the subsampled double bootstrap is superior to BLB in terms of running time, more sample coverage and automatic implementation with less tuning parameters for a given time budget. Its advantage relative to BLB and bootstrap is also demonstrated in numerical simulations and a data illustration.
• Dimension Reduction with Non-degrading Generalization
Visualizing high dimensional data by projecting them into two or three dimensional space is one of the most effective ways to intuitively understand the data’s underlying characteristics, for example their class neighborhood structure. While data visualization in low dimensional space can be efficient for revealing the data’s underlying characteristics, classifying a new sample in the reduced-dimensional space is not always beneficial because of the loss of information in expressing the data. It is possible to classify the data in the high dimensional space, while visualizing them in the low dimensional space, but in this case, the visualization is often meaningless because it fails to illustrate the underlying characteristics that are crucial for the classification process. In this paper, the performance-preserving property of the previously proposed Restricted Radial Basis Function Network in reducing the dimension of labeled data is explained. Here, it is argued through empirical experiments that the internal representation of the Restricted Radial Basis Function Network, which during the supervised learning process organizes a visualizable two dimensional map, does not only preserve the topographical structure of high dimensional data but also captures their class neighborhood structures that are important for classifying them. Hence, unlike many of the existing dimension reduction methods, the Restricted Radial Basis Function Network offers two dimensional visualization that is strongly correlated with the classification process.
• Direct Estimation of the Derivative of Quadratic Mutual Information with Application in Supervised Dimension Reduction
A typical goal of supervised dimension reduction is to find a low-dimensional subspace of the input space such that the projected input variables preserve maximal information about the output variables. The dependence maximization approach solves the supervised dimension reduction problem through maximizing a statistical dependence between projected input variables and output variables. A well-known statistical dependence measure is mutual information (MI) which is based on the Kullback-Leibler (KL) divergence. However, it is known that the KL divergence is sensitive to outliers. On the other hand, quadratic MI (QMI) is a variant of MI based on the
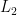
distance which is more robust against outliers than the KL divergence, and a computationally efficient method to estimate QMI from data, called least-squares QMI (LSQMI), has been proposed recently. For these reasons, developing a supervised dimension reduction method based on LSQMI seems promising. However, not QMI itself, but the derivative of QMI is needed for subspace search in supervised dimension reduction, and the derivative of an accurate QMI estimator is not necessarily a good estimator of the derivative of QMI. In this paper, we propose to directly estimate the derivative of QMI without estimating QMI itself. We show that the direct estimation of the derivative of QMI is more accurate than the derivative of the estimated QMI. Finally, we develop a supervised dimension reduction algorithm which efficiently uses the proposed derivative estimator, and demonstrate through experiments that the proposed method is more robust against outliers than existing methods.
• Learning from LDA using Deep Neural Networks
Latent Dirichlet Allocation (LDA) is a three-level hierarchical Bayesian model for topic inference. In spite of its great success, inferring the latent topic distribution with LDA is time-consuming. Motivated by the transfer learning approach proposed by~\newcite{hinton2015distilling}, we present a novel method that uses LDA to supervise the training of a deep neural network (DNN), so that the DNN can approximate the costly LDA inference with less computation. Our experiments on a document classification task show that a simple DNN can learn the LDA behavior pretty well, while the inference is speeded up tens or hundreds of times.
• MCMC-Based Inference in the Era of Big Data: A Fundamental Analysis of the Convergence Complexity of High-Dimensional Chains
Markov chain Monte Carlo (MCMC) lies at the core of modern Bayesian methodology, much of which would be impossible without it. Thus, the convergence properties of Markov chains have received significant attention, and in particular, proving (geometric) ergodicity is of critical interest. In the current era of ‘Big Data,’ a question unique to the Bayesian paradigm is how the ability to sample from the posterior via MCMC changes in a high-dimensional context. Many of the current methods for ascertaining the behavior of Markov chains typically proceed as if the dimension of the parameter, p, and the sample size, n, are fixed, but what happens as these grow, i.e., what is the convergence complexity? We demonstrate theoretically the precise nature and severity of the convergence problems that occur in some of the commonly used Markov chains when they are implemented in high dimensions. We show that these convergence problems effectively eliminate the apparent safeguard of geometric ergodicity. We then set forth a formal framework for understanding and diagnosing such convergence problems. In particular, we theoretically characterize phase transitions in the convergence behavior of popular MCMC schemes in various n and p regimes. Moreover, we also show that certain standard diagnostic tests can be misleading in high-dimensional settings. We then proceed to demonstrate theoretical principles by which MCMCs can be constructed and analyzed to yfield bounded geometric convergence rates even as the dimension p grows without bound, effectively recovering geometric ergodicity. We also show a universality result for the convergence rate of MCMCs across an entire spectrum of models. Additionally, we propose a diagnostic tool for establishing convergence (or the lack thereof) for high-dimensional MCMC schemes.
• Measuring Inequality and Segregation
In this paper, I introduce the Divergence Index, a conceptually intuitive and methodologically rigorous measure of inequality and segregation. The index measures the difference between a distribution of interest and another empirical, theoretical, or normative distribution. The Divergence Index provides flexibility in specifying a theoretically meaningful basis for evaluating inequality. It evaluates how surprising an empirical distribution is given a theoretical distribution that represents equality. I demonstrate the unique features of the new measure, as well as deriving its mathematical equivalence with Theil’s Inequality Index and the Information Theory Index. I compare the dynamics of the measures using simulated data, and an empirical analysis of racial residential segregation in the Detroit, MI, metro area. The Information Theory Index has become the gold standard for decomposition analyses of segregation. I show that although the Information Theory Index can be decomposed for subareas, it is misleading to interpret the results as segregation. The Divergence Index addresses the limitations of existing measures and accurately decomposes segregation across contexts and nested levels of geography. By creating an alternative measure, I provide a distinct lens, which enables richer, deeper, more accurate understandings of inequality and segregation.
• Ontology Bulding vs Data Harvesting and Cleaning for Smart-city Services
Presently, a very large number of public and private data sets are available around the local governments. In most cases, they are not semantically interoperable and a huge human effort is needed to create integrated ontologies and knowledge base for smart city. Smart City ontology is not yet standardized, and a lot of research work is needed to identify models that can easily support the data reconciliation, the management of the complexity and reasoning. In this paper, a system for data ingestion and reconciliation smart cities related aspects as road graph, services available on the roads, traffic sensors etc., is proposed. The system allows managing a big volume of data coming from a variety of sources considering both static and dynamic data. These data are mapped to smart-city ontology and stored into an RDF-Store where they are available for applications via SPARQL queries to providefinew services to the users. The paper presents the process adopted to produce the ontology and the knowledge base and the mechanisms adopted for the verification, reconciliation and validation. Some examples about the possible usage of the coherent knowledge base produced are also offered and are accessible from the RDF-Store.
• Parallel Adaptive Importance Sampling
Markov chain Monte Carlo methods are a commonly used and powerful family of numerical methods for sampling from complex probability distributions. As the applications that these methods are being applied to increase in size and complexity, the need for efficient methods which can exploit the parallel architectures which are prevalent in high performance computing increases. In this paper, we aim to develop a framework for scalable parallel MCMC algorithms. At each iteration, an importance sampling proposal distribution is formed using the current states of all of the chains within an ensemble. Once weighted samples have been produced from this, a state-of-the-art resampling method is then used to create an evenly weighted sample ready for the next iteration. We demonstrate that this parallel adaptive importance sampling (PAIS) method outperforms naive parallelisation of serial MCMC methods using the same number of processors, for low dimensional problems, and in fact shows better than linear improvements in convergence rates with respect to the number of processors used.
• Progressive EM for Latent Tree Models and Hierarchical Topic Detection
Hierarchical latent tree analysis (HLTA) is recently proposed as a new method for topic detection. It differs fundamentally from the LDA-based methods in terms of topic definition, topic-document relationship, and learning method. It has been shown to discover significantly more coherent topics and better topic hierarchies. However, HLTA relies on the Expectation-Maximization (EM) algorithm for parameter estimation and hence is not efficient enough to deal with large datasets. In this paper, we propose a method to drastically speed up HLTA using a technique inspired by recent advances in the moments method. Empirical experiments show that our method greatly improves the efficiency of HLTA. It is as efficient as the state-of-the-art LDA-based method for hierarchical topic detection and finds substantially better topics and topic hierarchies.
• Relation Classification via Recurrent Neural Network
Deep learning has gained much success in sentence-level relation classification. For example, convolutional neural networks (CNN) have delivered state-of-the-art performance without much effort on feature engineering as the conventional pattern-based methods. A key issue that has not been well addressed by the existing research is the lack of capability to learn %in modeling temporal features, especially long-distance dependency between nominal pairs. In this paper, we propose a novel framework based on recurrent neural networks (RNN) to tackle the problem, and present several modifications to enhance the model, including a max-pooling approach and a bi-directional architecture. Our experiment on the SemEval-2010 Task-8 dataset shows that the RNN model can deliver state-of-the-art performance on relation classification, and it is particularly capable of learning long-distance relation patterns. This makes it suitable for real-world applications where complicated expressions are often involved.
• Signal extraction approach for sparse multivariate response regression
In this paper, we consider multivariate response regression models with high dimensional predictor variables. One way to model the correlation among the response variables is through the low rank decomposition of the coefficient matrix, which has been considered by several papers for the high dimensional predictors. However, all these papers focus on the singular value decomposition of the coefficient matrix. Our target is the decomposition of the coefficient matrix which leads to the best lower rank approximation to the regression function, the signal part in the response. Given any rank, this decomposition has nearly the smallest expected prediction error among all approximations to the the coefficient matrix with the same rank. To estimate the decomposition, we formulate a penalized generalized eigenvalue problem to obtain the first matrix in the decomposition and then obtain the second one by a least squares method. In the high-dimensional setting, we establish the oracle inequalities for the estimates. Compared to the existing theoretical results, we have less restrictions on the distribution of the noise vector in each observation and allow correlations among its coordinates. Our theoretical results do not depend on the dimension of the multivariate response. Therefore, the dimension is arbitrary and can be larger than the sample size and the dimension of the predictor. Simulation studies and application to real data show that the proposed method has good prediction performance and is efficient in dimension reduction for various reduced rank models.
• Structured Prediction: From Gaussian Perturbations to Linear-Time Principled Algorithms
Margin-based structured prediction commonly uses a maximum loss over all possible structured outputs \cite{Altun03,Collins04b,Taskar03}. In natural language processing, recent work \cite{Zhang14} has proposed the use of the maximum loss over random structured outputs sampled independently from some proposal distribution. This method is linear-time in the number of random structured outputs and trivially parallelizable. We study this family of loss functions in the PAC-Bayes framework under Gaussian perturbations \cite{McAllester07}. Under some technical conditions and up to statistical accuracy, we show that this family of loss functions produces a tighter upper bound of the Gibbs decoder distortion than commonly used methods. Thus, using the maximum loss over random structured outputs is a principled way of learning the parameter of structured prediction models.
• Symmetries of matrix multiplication algorithms. I
In this work the algorithms of fast multiplication of matrices are considered. To any algorithm there associated a certain group of automorphisms. These automorphism groups are found for some well-known algorithms, including algorithms of Hopcroft, Laderman, and Pan. The automorphism group is isomorphic to
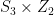
and

for Hopcroft anf Laderman algorithms, respectively. The studying of symmetry of algorithms may be a fruitful idea for finding fast algorithms, by an analogy with well-known optimization problems for codes, lattices, and graphs. {\em Keywords}: Strassen algorithm, symmetry, fast matrix multiplication.
• The Continuous Cold Start Problem in e-Commerce Recommender Systems
Many e-commerce websites use recommender systems to recommend items to users. When a user or item is new, the system may fail because not enough information is available on this user or item. Various solutions to this `cold-start problem’ have been proposed in the literature. However, many real-life e-commerce applications suffer from an aggravated, recurring version of cold-start even for known users or items, since many users visit the website rarely, change their interests over time, or exhibit different personas. This paper exposes the `Continuous Cold Start’ (CoCoS) problem and its consequences for content- and context-based recommendation from the viewpoint of typical e-commerce applications, illustrated with examples from a major travel recommendation website, Booking.com.
• A different perspective on a scale for pairwise comparisons
• A MAP approach for $\ell_q$-norm regularized sparse parameter estimation using the EM algorithm
• A Multiscale Analysis of Traveling Waves in Stochastic Neural Fields
• A quantum framework for likelihood ratios
• A review of heterogeneous data mining for brain disorders
• Adaptive Multiple Importance Sampling for Gaussian Processes
• Admissibility in Partial Conjunction Testing
• Asymptotic optimality of sparse linear discriminant analysis with arbitrary number of classes
• Asymptotically optimal neighbour sum distinguishing total colourings of graphs
• Deep Convolutional Networks are Hierarchical Kernel Machines
• INsight: A Neuromorphic Computing System for Evaluation of Large Neural Networks
• Invariant subsets of scattered trees. An application to the tree alternative property of Bonato and Tardif
• Inversions of Semistandard Young Tableaux
• Km4City Ontology Building vs Data Harvesting and Cleaning for Smart-city Services
• MAP Support Detection for Greedy Sparse Signal Recovery Algorithms in Compressive Sensing
• Meta-MapReduce: A Technique for Reducing Communication in MapReduce Computations
• Minimizing the CDF Path Length: A Novel Perspective on Uniformity and Uncertainty of Bounded Distributions
• Mining for Causal Relationships: A Data-Driven Study of the Islamic State
• Offline and Online Models of Budget Allocation for Maximizing Influence Spread
• On Bivariate Generalized Linear Failure Rate-Power Series Class of Distributions
• On decomposing graphs of large minimum degree into locally irregular subgraphs
• On Maximal and Minimal Linear Matching Property
• On Ryser’s Conjecture for Linear Intersecting Multipartite Hypergraphs
• On the Linear Belief Compression of POMDPs: A re-examination of current methods
• On the weak limit law of the maximal uniform k-spacing
• Partial clones containing all Boolean monotone self-dual partial functions
• Screening and transport in 2D semiconductor systems at low temperatures
• SEARS: Space Efficient And Reliable Storage System in the Cloud
• Signal Prediction by Anticipatory Relaxation Dynamics
• Slowing time: Markov-modulated Brownian motion with a sticky boundary
• Sparse Fisher’s discriminant analysis with thresholded linear constraints
• S-positivity of interval hypergraphs
• Topic Stability over Noisy Sources
• Truncation map estimation for the truncated bigaussian model based on bivariate unit-lag probabilities
• Variational View to Optimal Stopping Problems for Diffusion Processes and Threshold Strategies
• Weak convergence of the empirical spectral distribution of high-dimensional banded sample covariance matrices
Like this:
Like Loading...